在PAI子產品(DLC或DSW)中,您可以使用JindoFuse組件(由阿里云EMR提供)將對象存儲OSS類型的數據集掛載到容器的指定路徑,也可以通過阿里云對象存儲OSS提供的OSS Pytorch Connector和OSS SDK來讀取OSS數據。根據不同的應用場景,您可以選擇合適的OSS數據讀取方法。
背景信息
在AI開發過程中,通常將源數據存儲在對象存儲OSS中,然后將其從OSS下載至訓練環境進行模型開發和訓練等。然而,這種方法常常伴隨著一系列挑戰:
數據集的下載時間過長造成GPU等待。
每次訓練任務都需要重復下載數據。
為了實現數據的隨機采樣,不得不在每個訓練節點上下載完整數據集。
為了解決上述問題,您可以參考以下建議,選擇合適的OSS數據讀取方法:
OSS數據讀取方法 | 描述 |
利用JindoFuse組件將OSS數據集掛載到容器的指定路徑,便于直接讀寫數據。適用場景如下:
| |
PAI平臺集成了OSS Pytorch Connector,利用在PyTorch代碼中直接流式讀取OSS文件實現簡易高效的數據讀取。
| |
利用OSS2來實現OSS數據的流式訪問。OSS2是一個靈活高效的解決方案,它可以顯著減少請求OSS數據的時間,提升訓練效率。適用場景如下: 如果您只需要通過非掛載的方式臨時訪問OSS數據,或者根據業務邏輯來決定是否訪問OSS,可采用OSS Python SDK或OSS Python API的方式。 |
JindoFuse
DLC和DSW支持使用JindoFuse組件將對象存儲OSS類型的數據集掛載到容器的指定路徑,方便您在訓練過程中直接讀寫存儲在OSS中的數據。掛載方法如下:
在DLC中掛載OSS
在創建分布式訓練(DLC)任務時,掛載OSS數據。支持以下幾種掛載類型,具體配置方法,請參見創建訓練任務。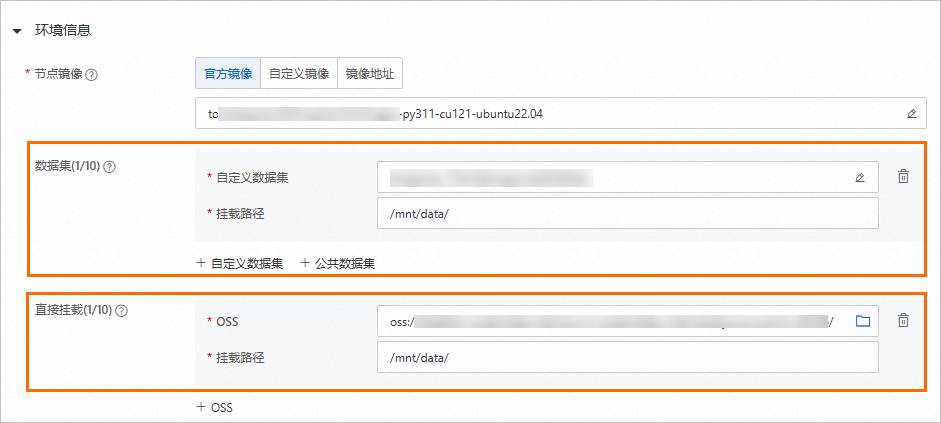
掛載類型 | 描述 |
數據集 | 通過數據集(自定義數據集和公共數據集)進行掛載,其中公共數據集只支持只讀掛載模式。選擇對象存儲OSS類型的數據集,并配置掛載路徑,當執行DLC任務時,系統會按照該路徑來訪問OSS中的數據。 |
直接掛載 | 直接掛載OSS Bucket存儲路徑。 |
使用該方式掛載OSS,默認配置有如下限制,并不適合所有的場景:
為了快速讀取OSS文件,掛載OSS時會有元數據(目錄與文件列表)的緩存。
在分布式任務中,如果有多個節點需要創建同一個目錄并檢查目錄是否存在,元數據的Cache會導致每個節點都嘗試進行創建。實際只有一個節點能成功創建目錄,其它節點會報錯。
默認使用OSS的MultiPart API來創建文件,在寫文件的過程中,在OSS上看不到該對象。當所有寫操作完成后,才能在OSS頁面上查看。
不支持同時進行文件的寫入和讀取操作。
不支持對文件進行隨機寫入操作。
您可以參照以下操作步驟,通過調整底層參數來適配具體的場景。
完成以下準備工作。
安裝工作空間的SDK。
!pip install alibabacloud-aiworkspace20210204配置環境變量。具體操作,請參見安裝Credentials工具和在Linux、macOS和Windows系統配置環境變量。
調整底層參數,適配以下場景。
如何選擇不同的JindoFuse版本
示例代碼如下:
import json from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest def change_version(): # 使用DLC任務所在地域。例如華東1(杭州)配置為cn-hangzhou。 region_id = 'cn-hangzhou' # 阿里云賬號AccessKey擁有所有API的訪問權限,建議您使用RAM用戶進行API訪問或日常運維。 # 強烈建議不要把AccessKey ID和AccessKey Secret保存到工程代碼里,否則可能導致AccessKey泄露,威脅您賬號下所有資源的安全。 # 本示例通過Credentials SDK默認從環境變量中讀取AccessKey,來實現身份驗證。您需要先安裝Credentials工具和配置環境變量。 cred = CredClient() dataset_id = '** 數據集的ID **' workspace_client = AIWorkspaceClient( config=Config( credential=cred, region_id=region_id, endpoint="aiworkspace.{}.aliyuncs.com".format(region_id), ) ) # 1、get the content of dataset get_dataset_resp = workspace_client.get_dataset(dataset_id) options = json.loads(get_dataset_resp.body.options) # 配置jindo-fuse的版本,可以配置為6.4.4, 6.7.0,6.6.0,release note詳見:https://aliyun.github.io/alibabacloud-jindodata/releases/ options['fs.jindo.fuse.pod.image.tag'] = "6.7.0" update_request = UpdateDatasetRequest( options=json.dumps(options) ) # 2、update options workspace_client.update_dataset(dataset_id, update_request) print('new options is: {}'.format(update_request.options)) change_version()如何關掉元數據Cache
當執行分布式任務且多個節點同時嘗試向同一目錄寫文件時,Cache可能會引起部分節點的寫入操作失敗。您可以通過修改fuse的命令行參數,增加
-oattr_timeout=0-oentry_timeout=0-onegative_timeout=0來解決該問題。示例代碼如下。import json from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest def turnOffMetaCache(): region_id = 'cn-hangzhou' # 阿里云賬號AccessKey擁有所有API的訪問權限,建議您使用RAM用戶進行API訪問或日常運維。 # 強烈建議不要把AccessKey ID和AccessKey Secret保存到工程代碼里,否則可能導致AccessKey泄露,威脅您賬號下所有資源的安全。 # 本示例通過Credentials SDK默認從環境變量中讀取AccessKey,來實現身份驗證。您需要先安裝Credentials工具和配置環境變量。 cred = CredClient() dataset_id = '** 數據集的ID **' workspace_client = AIWorkspaceClient( config=Config( credential=cred, region_id=region_id, endpoint="aiworkspace.{}.aliyuncs.com".format(region_id), ) ) # 1、get the content of dataset get_dataset_resp = workspace_client.get_dataset(dataset_id) options = json.loads(get_dataset_resp.body.options) options['fs.jindo.args'] = '-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0' update_request = UpdateDatasetRequest( options=json.dumps(options) ) # 2、update options workspace_client.update_dataset(dataset_id, update_request) print('new options is: {}'.format(update_request.options)) turnOffMetaCache()如何調整上傳(下載)數據的線程數目
通過配置以下參數來調整線程數據:
fs.oss.upload.thread.concurrency:32fs.oss.download.thread.concurrency:32fs.oss.read.readahead.buffer.count:64fs.oss.read.readahead.buffer.size:4194304
示例代碼如下:
import json from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest def adjustThreadNum(): # 使用DLC任務所在地域。例如華東1(杭州)配置為cn-hangzhou。 region_id = 'cn-hangzhou' # 阿里云賬號AccessKey擁有所有API的訪問權限,建議您使用RAM用戶進行API訪問或日常運維。 # 強烈建議不要把AccessKey ID和AccessKey Secret保存到工程代碼里,否則可能導致AccessKey泄露,威脅您賬號下所有資源的安全。 # 本示例通過Credentials SDK默認從環境變量中讀取AccessKey,來實現身份驗證。您需要先安裝Credentials工具和配置環境變量。 cred = CredClient() dataset_id = '** 數據集的ID **' workspace_client = AIWorkspaceClient( config=Config( credential=cred, region_id=region_id, endpoint="aiworkspace.{}.aliyuncs.com".format(region_id), ) ) # 1、get the content of dataset get_dataset_resp = workspace_client.get_dataset(dataset_id) options = json.loads(get_dataset_resp.body.options) options['fs.oss.upload.thread.concurrency'] = 32 options['fs.oss.download.thread.concurrency'] = 32 options['fs.oss.read.readahead.buffer.count'] = 32 update_request = UpdateDatasetRequest( options=json.dumps(options) ) # 2、update options workspace_client.update_dataset(dataset_id, update_request) print('new options is: {}'.format(update_request.options)) adjustThreadNum()如何使用AppendObject方式掛載OSS文件
所有在本地OSS創建的文件,都會調用OSS的AppendObject接口來創建Object(文件)。通過AppendObject方式最后生成的Object大小不得超過5 GB,關于AppendObject的更多使用限制,請參見AppendObject。示例代碼如下:
import json from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest def useAppendObject(): # 使用DLC任務所在地域。例如華東1(杭州)配置為cn-hangzhou。 region_id = 'cn-hangzhou' # 阿里云賬號AccessKey擁有所有API的訪問權限,建議您使用RAM用戶進行API訪問或日常運維。 # 強烈建議不要把AccessKey ID和AccessKey Secret保存到工程代碼里,否則可能導致AccessKey泄露,威脅您賬號下所有資源的安全。 # 本示例通過Credentials SDK默認從環境變量中讀取AccessKey,來實現身份驗證。您需要先安裝Credentials工具和配置環境變量。 cred = CredClient() dataset_id = '** 數據集的ID **' workspace_client = AIWorkspaceClient( config=Config( credential=cred, region_id=region_id, endpoint="aiworkspace.{}.aliyuncs.com".format(region_id), ) ) # 1、get the content of dataset get_dataset_resp = workspace_client.get_dataset(dataset_id) options = json.loads(get_dataset_resp.body.options) options['fs.jindo.args'] = '-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0' options['fs.oss.append.enable'] = "true" options['fs.oss.flush.interval.millisecond'] = "1000" options['fs.oss.read.buffer.size'] = "262144" options['fs.oss.write.buffer.size'] = "262144" update_request = UpdateDatasetRequest( options=json.dumps(options) ) # 2、update options workspace_client.update_dataset(dataset_id, update_request) print('new options is: {}'.format(update_request.options)) useAppendObject()如何掛載OSS-HDFS
如何開通OSS-HDFS,請參見什么是OSS-HDFS服務。使用OSS-HDFS的Endpoint來創建數據集的示例代碼如下:
import json from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient from alibabacloud_aiworkspace20210204.models import CreateDatasetRequest def createOssHdfsDataset(): # 使用DLC任務所在地域。例如華東1(杭州)配置為cn-hangzhou。 region_id = 'cn-hangzhou' # 阿里云賬號AccessKey擁有所有API的訪問權限,建議您使用RAM用戶進行API訪問或日常運維。 # 強烈建議不要把AccessKey ID和AccessKey Secret保存到工程代碼里,否則可能導致AccessKey泄露,威脅您賬號下所有資源的安全。 # 本示例通過Credentials SDK默認從環境變量中讀取AccessKey,來實現身份驗證。您需要先安裝Credentials工具和配置環境變量。 cred = CredClient() workspace_id = '** DLC任務所在工作空間ID **' oss_bucket = '** OSS-Bucket **' # 使用OSS-HDFS的Endpoint。 oss_endpoint = f'{region_id}.oss-dls.aliyuncs.com' # 需要掛載的OSS-HDFS路徑。 oss_path = '/' # 本地掛載路徑。 mount_path = '/mnt/data/' workspace_client = AIWorkspaceClient( config=Config( credential=cred, region_id=region_id, endpoint="aiworkspace.{}.aliyuncs.com".format(region_id), ) ) response = workspace_client.create_dataset(CreateDatasetRequest( workspace_id=workspace_id, name="** 數據集的名字 **", data_type='COMMON', data_source_type='OSS', property='DIRECTORY', uri=f'oss://{oss_bucket}.{oss_endpoint}{oss_path}', accessibility='PRIVATE', source_type='USER', options=json.dumps({ 'mountPath': mount_path, # 在分布式訓練的場景下建議增加以下參數。 'fs.jindo.args': '-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -ono_symlink -ono_xattr -ono_flock -odirect_io', 'fs.oss.flush.interval.millisecond': "10000", 'fs.oss.randomwrite.sync.interval.millisecond': "10000", }) )) print(f'datasetId: {response.body.dataset_id}') createOssHdfsDataset()如何配置內存資源
通過配置fs.jindo.fuse.pod.mem.limit參數來調整內存資源,示例代碼如下:
import json from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_aiworkspace20210204.client import Client as AIWorkspaceClient from alibabacloud_aiworkspace20210204.models import UpdateDatasetRequest def adjustResource(): # 使用DLC任務所在地域。例如華東1(杭州)配置為cn-hangzhou。 region_id = 'cn-hangzhou' # 阿里云賬號AccessKey擁有所有API的訪問權限,建議您使用RAM用戶進行API訪問或日常運維。 # 強烈建議不要把AccessKey ID和AccessKey Secret保存到工程代碼里,否則可能導致AccessKey泄露,威脅您賬號下所有資源的安全。 # 本示例通過Credentials SDK默認從環境變量中讀取AccessKey,來實現身份驗證。您需要先安裝Credentials工具和配置環境變量。 cred = CredClient() dataset_id = '** 數據集的ID **' workspace_client = AIWorkspaceClient( config=Config( credential=cred, region_id=region_id, endpoint="aiworkspace.{}.aliyuncs.com".format(region_id), ) ) # 1、get the content of dataset get_dataset_resp = workspace_client.get_dataset(dataset_id) options = json.loads(get_dataset_resp.body.options) # 需要配置的內存資源。 options['fs.jindo.fuse.pod.mem.limit'] = "10Gi" update_request = UpdateDatasetRequest( options=json.dumps(options) ) # 2、update options workspace_client.update_dataset(dataset_id, update_request) print('new options is: {}'.format(update_request.options)) adjustResource()
在DSW中掛載OSS
在創建DSW實例時,掛載OSS數據。支持以下幾種掛載類型,具體配置方法,請參見創建DSW實例。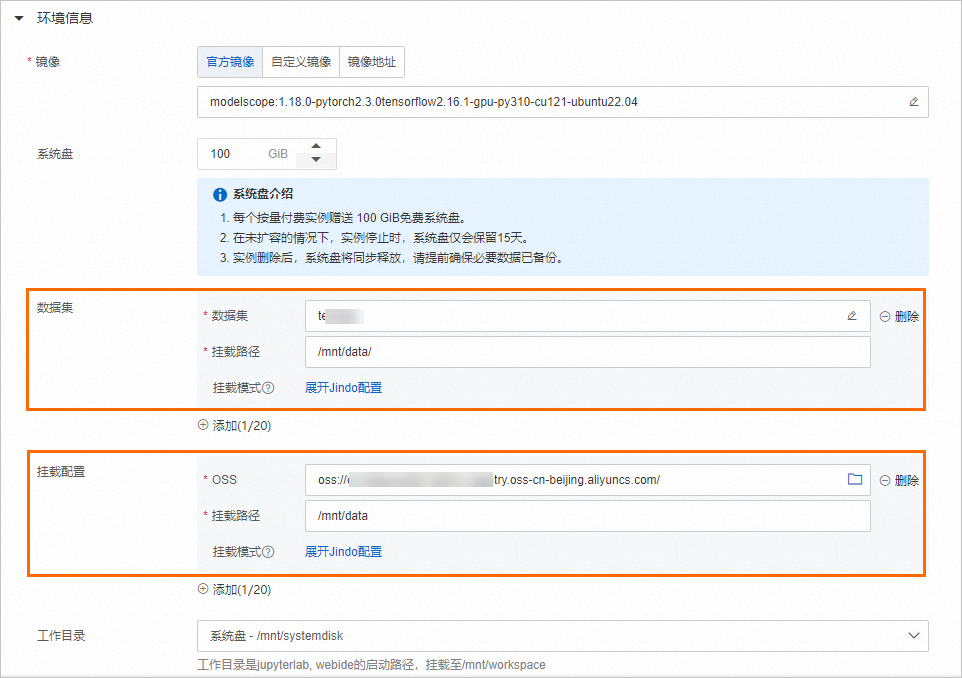
掛載項 | 支持的掛載模式 | |
非OSS類型數據集 | 無掛載模式。 | |
OSS類型數據集 | 支持默認配置和自定義配置。
| |
本文提供部分場景的Jindo配置建議,并未覆蓋所有場景下的最優性能。更靈活的配置,請參見JindoFuse使用指南。
快速讀寫:允許用戶讀寫,讀取速度快,但并發讀寫可能會出現數據不一致的問題,適合掛載訓練數據和模型,不適合作為工作目錄。
{ "fs.oss.download.thread.concurrency": "cpu核數2倍", "fs.oss.upload.thread.concurrency": "cpu核數2倍", "fs.jindo.args": "-oattr_timeout=3 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }增量讀寫:在增量寫入時能夠保證數據一致性,覆蓋原有數據會有一致性問題。讀取速度略慢,適合保存訓練的模型權重文件。
{ "fs.oss.upload.thread.concurrency": "cpu核數2倍", "fs.jindo.args": "-oattr_timeout=3 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }讀寫一致:在并發讀寫中能保持數據一致性,適用于對數據一致性要求高,可以容忍讀取速度慢的場景,適合保存代碼項目。
{ "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }只讀:僅允許讀取,不允許寫入,適合掛載公共數據集。
{ "fs.oss.download.thread.concurrency": "cpu核數2倍", "fs.jindo.args": "-oro -oattr_timeout=7200 -oentry_timeout=7200 -onegative_timeout=7200 -okernel_cache -ono_symlink" }
OSS Pytorch Connector
OSS Pytorch Connector是阿里云OSS團隊專為人工智能和機器學習場景設計的客戶端庫,能在大規模Pytorch框架訓練場景下提供便捷的數據加載體驗,顯著減少數據傳輸時間和復雜度,加速模型訓練,提高效率,從而避免不必要的步驟和數據加載瓶頸。為優化PAI用戶體驗并加速數據訪問流程,PAI平臺集成了OSS Pytorch Connector,可在PyTorch代碼中直接流式讀取OSS文件,實現簡易高效的數據讀取。
使用限制
官方鏡像:僅在分布式訓練(DLC)任務或DSW實例中選擇Pytorch 2.0及其以上版本的鏡像時,才能使用OSS Pytorch Connector模塊。
自定義鏡像:僅支持Pytorch 2.0及其以上版本,對于滿足版本要求的鏡像,您可以通過下述指令安裝OSS Pytorch Connector模塊。
pip install -i http://yum.tbsite.net/aliyun-pypi/simple/ --extra-index-url http://yum.tbsite.net/pypi/simple/ --trusted-host=yum.tbsite.net osstorchconnectorPython版本:僅支持Python 3.8~3.12版本。
準備工作
配置credential文件。
您可以使用以下任意一種方式配置credential:
您可以參考配置DLC RAM角色,為分布式訓練(DLC)任務配置免密訪問OSS的credential。通過這種方式,DLC任務將獲取STS臨時訪問憑證,能夠安全地訪問OSS或其他云資源,無需顯式配置認證信息,從而降低密鑰泄露的風險。
在代碼項目中配置credential文件,管理認證信息。配置示例如下:
說明明文配置AK信息存在安全風險,建議您使用角色配置在DLC實例內自動配置credential,詳情請參見配置DLC RAM角色。
在使用OSS Pytorch Connector接口時,您可以通過指定credential文件的路徑,自動獲取認證信息,以便進行OSS數據請求的認證。
{ "AccessKeyId": "<Access-key-id>", "AccessKeySecret": "<Access-key-secret>", "SecurityToken": "<Security-Token>", "Expiration": "2024-08-20T00:00:00Z" }具體配置項說明如下:
配置項
是否必填
說明
示例值
AccessKeyId
是
阿里云賬號或者RAM用戶的AccessKey ID和AccessKey Secret。
說明當使用從STS獲取的臨時訪問憑證訪問OSS時,請設置為臨時訪問憑證的AccessKey ID和AccessKey Secret。
NTS****
AccessKeySecret
是
7NR2****
SecurityToken
否
臨時訪問令牌。當使用從STS獲取的臨時訪問憑證訪問OSS時,需要設置此參數。
STS.6MC2****
Expiration
否
鑒權信息過期時間,Expiration為空表示永不過期,鑒權時間過期后OSS Connector會重新讀取鑒權信息。
2024-08-20T00:00:00Z
配置config.json文件,內容示例如下:
在代碼項目中配置config.json文件,管理諸如并發處理數量、預取參數以及其他核心參數,同時定義日志文件的存儲位置等重要信息。使用OSS Pytorch Connector接口時,通過指定config.json文件的路徑,系統可以自動獲取到讀取時并發處理量、預取值,并將請求OSS數據的相關日志輸出到指定的日志文件中。
{ "logLevel": 1, "logPath": "/var/log/oss-connector/connector.log", "auditPath": "/var/log/oss-connector/audit.log", "datasetConfig": { "prefetchConcurrency": 24, "prefetchWorker": 2 }, "checkpointConfig": { "prefetchConcurrency": 24, "prefetchWorker": 4, "uploadConcurrency": 64 } }具體配置項說明如下:
配置項
是否必填
說明
示例值
logLevel
是
日志記錄級別。默認為INFO級別。取值如下:
0:表示Debug。
1:表示INFO。
2:表示WARN。
3:表示ERROR。
1
logPath
是
connector日志路徑。默認路徑為
/var/log/oss-connector/connector.log。/var/log/oss-connector/connector.log
auditPath
是
connector IO的審計日志,記錄延遲大于100毫秒的讀寫請求。默認路徑為
/var/log/oss-connector/audit.log。/var/log/oss-connector/audit.log
DatasetConfig
prefetchConcurrency
是
使用Dataset從OSS預取數據時的并發數,默認為24。
24
prefetchWorker
是
使用Dataset從OSS預取可使用vCPU數,默認為4。
2
checkpointConfig
prefetchConcurrency
是
使用checkpoint read從OSS預取數據時的并發數,默認為24。
24
prefetchWorker
是
使用checkpoint read從OSS預取可使用vCPU數,默認為4。
4
uploadConcurrency
是
使用checkpoint write上傳數據時的并發數,默認為64。
64
使用方式
OSS Pytorch Connector提供了OssMapDataset和OssIterableDataset兩種數據集訪問接口,分別是對Dataset和IterableDataset接口的擴展。OssIterableDataset進行了預取優化,因此訓練效率相對較高。OssMapDataset的數據讀取順序由DataLoader決定,支持shuffle操作。因此,您可以參考以下建議選擇數據集訪問接口:
如果內存較小或數據量較大,只需要順序讀取且對并行處理的要求不高,建議您使用OssIterableDataset來構建Dataset。
相反,如果內存充足、數據量較小,并且需要隨機操作和并行處理,建議您使用OssMapDataset來構建Dataset。
同時,OSS Pytorch Connector也提供了OssCheckpoint接口以支持模型加載和保存。當前,OssCheckpoint功能僅限于在通用資源環境下使用。
以下內容為您介紹這三種接口的使用方式:
OssMapDataset
支持以下三種數據集訪問模式:
根據OSS路徑前綴訪問文件夾
您只需指定文件夾名稱,無需配置索引文件,更簡單直觀,便于維護和擴展。如果您的OSS文件夾結構如下,則可以選擇采用該方式訪問數據集:
dataset_folder/ ├── class1/ │ ├── image1.JPEG │ └── ... ├── class2/ │ ├── image2.JPEG │ └── ...在使用時需要指定OSS路徑前綴,并自定義文件流的解析方式。以下是解析和轉換圖片文件的方法:
def read_and_transform(data): normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) transform = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), normalize, ]) try: img = accimage.Image((data.read())) val = transform(img) label = data.label # 文件名 except Exception as e: print("read failed", e) return None, 0 return val, label dataset = OssMapDataset.from_prefix("{oss_data_folder_uri}", endpoint="{oss_endpoint}", transform=read_and_transform, cred_path=cred_path, config_path=config_path)根據manifest_file獲取文件
支持訪問多個OSS Bucket的數據,提供更靈活的數據管理方式。如果您的OSS文件夾結構如下,并且存在一個管理文件名和Label對應關系的manifest_file,則可以選擇采用manifest_file的方式訪問數據集。
dataset_folder/ ├── class1/ │ ├── image1.JPEG │ └── ... ├── class2/ │ ├── image2.JPEG │ └── ... └── .manifest其中manifest_file格式如下:
{'data': {'source': 'oss://examplebucket.oss-cn-wulanchabu.aliyuncs.com/dataset_folder/class1/image1.JPEG'}} {'data': {'source': ''}}在使用時,您需要自定義manifest_file的解析方式,使用示例如下:
def transform_oss_path(input_path): pattern = r'oss://(.*?)\.(.*?)/(.*)' match = re.match(pattern, input_path) if match: return f'oss://{match.group(1)}/{match.group(3)}' else: return input_path def manifest_parser(reader: io.IOBase) -> Iterable[Tuple[str, str, int]]: lines = reader.read().decode("utf-8").strip().split("\n") data_list = [] for i, line in enumerate(lines): data = json.loads(line) yield transform_oss_path(data["data"]["source"]), "" dataset = OssMapDataset.from_manifest_file("{manifest_file_path}", manifest_parser, "", endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path)根據OSS_URI列表的方式獲取文件
您只需指定OSS_URI,無需配置索引文件,即可訪問OSS文件。使用示例如下:
uris =["oss://examplebucket.oss-cn-wulanchabu.aliyuncs.com/dataset_folder/class1/image1.JPEG", "oss://examplebucket.oss-cn-wulanchabu.aliyuncs.com/dataset_folder/class2/image2.JPEG"] dataset = OssMapDataset.from_objects(uris, endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path)
OssIterableDataset
OssIterableDataset也支持三種數據集訪問方式,與OssMapDataset相同。以下內容為您介紹如何使用這三種數據集訪問方式:
根據OSS路徑前綴訪問文件夾
dataset = OssIterableDataset.from_prefix("{oss_data_folder_uri}", endpoint="{oss_endpoint}", transform=read_and_transform, cred_path=cred_path, config_path=config_path)根據manifest_file獲取文件
dataset = OssIterableDataset.from_manifest_file("{manifest_file_path}", manifest_parser, "", endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path)根據OSS_URI列表的方式獲取文件
dataset = OssIterableDataset.from_objects(uris, endpoint=endpoint, transform=read_and_trans, cred_path=cred_path, config_path=config_path)
OssCheckpoint
當前,OssCheckpoint功能僅支持在通用計算資源環境下使用。OSS Pytorch Connector支持通過OssCheckpoint訪問OSS模型文件,以及將模型文件保存到OSS中,接口使用方法如下:
checkpoint = OssCheckpoint(endpoint="{oss_endpoint}", cred_path=cred_path, config_path=config_path)
checkpoint_read_uri = "{checkpoint_path}"
checkpoint_write_uri = "{checkpoint_path}"
with checkpoint.reader(checkpoint_read_uri) as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
with checkpoint.writer(checkpoint_write_uri) as writer:
torch.save(model.state_dict(), writer)代碼示例
以下是OSS Pytorch Connector的示例代碼,您可以使用該示例代碼訪問OSS數據:
from osstorchconnector import OssMapDataset, OssCheckpoint
import torchvision.transforms as transforms
import accimage
import torchvision.models as models
import torch
cred_path = "/mnt/.alibabacloud/credentials" # 為DLC任務和DSW實例配置角色信息之后credential的默認路徑。
config_path = "config.json"
checkpoint = OssCheckpoint(endpoint="{oss_endpoint}", cred_path=cred_path, config_path=config_path)
model = models.__dict__["resnet18"]()
epochs = 100 # 指定epoch
checkpoint_read_uri = "{checkpoint_path}"
checkpoint_write_uri = "{checkpoint_path}"
with checkpoint.reader(checkpoint_read_uri) as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
def read_and_transform(data):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
try:
img = accimage.Image((data.read()))
value = transform(img)
except Exception as e:
print("read failed", e)
return None, 0
return value, 0
dataset = OssMapDataset.from_prefix("{oss_data_folder_uri}", endpoint="{oss_endpoint}", transform=read_and_transform, cred_path=cred_path, config_path=config_path)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size="{batch_size}",num_workers="{num_workers"}, pin_memory=True)
for epoch in range(args.epochs):
for step, (images, target) in enumerate(data_loader):
# batch processing
# model training
# save model
with checkpoint.writer(checkpoint_write_uri) as writer:
torch.save(model.state_dict(), writer)上述代碼的關鍵實現說明如下:
使用OssMapDataset直接基于給定的OSS URI,構建一個與Pytorch Dataloader使用范式一致的dataset。
使用該dataset,構建Torch的標準Dataloader,并通過loop dataloader進行標準的訓練流程,如對當前batch的處理、模型訓練與保存等。
同時,這一過程無需將數據集掛載到容器環境中,也無需事先將數據存儲至本地,實現了數據的按需加載。
OSS SDK
OSS Python SDK
您可以直接使用OSS Python SDK讀寫OSS中的數據,具體操作步驟如下:
安裝OSS Python SDK。詳情請參見安裝。
為OSS Python SDK配置訪問憑證,詳情請參見配置訪問憑證。
讀寫OSS數據。
# -*- coding: utf-8 -*- import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider # 使用環境變量中獲取的RAM用戶訪問密鑰配置訪問憑證 auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) bucket = oss2.Bucket(auth, '<Endpoint>', '<your_bucket_name>') # 讀取一個完整文件。 result = bucket.get_object('<your_file_path/your_file>') print(result.read()) # 按Range讀取數據。 result = bucket.get_object('<your_file_path/your_file>', byte_range=(0, 99)) # 寫數據至OSS。 bucket.put_object('<your_file_path/your_file>', '<your_object_content>') # 對Appendable類型文件進行Append。 result = bucket.append_object('<your_file_path/your_file>', 0, '<your_object_content>') result = bucket.append_object('<your_file_path/your_file>', result.next_position, '<your_object_content>')您需要根據實際需要修改以下配置項:
配置項
描述
<Endpoint>
填寫Bucket所在地域對應的Endpoint。以華東1(杭州)為例,Endpoint填寫為https://oss-cn-hangzhou.aliyuncs.com。關于獲取Endpoint的更多信息,請參見OSS地域和訪問域名。
<your_bucket_name>
填寫存儲空間名稱。
<your_file_path/your_file>
表示待讀寫的文件路徑。填寫不包含Bucket名稱在內的Object完整路徑,例如
testfolder/exampleobject.txt。<your_object_content>
表示待Append的內容,需要根據實際情況修改。
OSS Python API
使用OSS Python API,您可以方便地在OSS中存儲訓練數據和模型。在開始操作之前,請確保已安裝OSS Python SDK,并正確設置訪問憑據,詳情請參見安裝和配置訪問憑證。
加載訓練數據
您可以將數據存放在一個OSS Bucket中,且將數據路徑和對應的Label存儲在同一個OSS Bucket的索引文件中。通過自定義DataSet,在PyTorch中使用
DataLoaderAPI多進程并行讀取數據,示例如下。import io import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider import PIL import torch class OSSDataset(torch.utils.data.dataset.Dataset): def __init__(self, endpoint, bucket, auth, index_file): self._bucket = oss2.Bucket(auth, endpoint, bucket) self._indices = self._bucket.get_object(index_file).read().split(',') def __len__(self): return len(self._indices) def __getitem__(self, index): img_path, label = self._indices(index).strip().split(':') img_str = self._bucket.get_object(img_path) img_buf = io.BytesIO() img_buf.write(img_str.read()) img_buf.seek(0) img = Image.open(img_buf).convert('RGB') img_buf.close() return img, label # 從環境變量中獲取訪問憑證。運行本代碼示例之前,請確保已設置環境變量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。 auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) dataset = OSSDataset(endpoint, bucket, auth, index_file) data_loader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, num_workers=num_loaders, pin_memory=True)其中關鍵配置說明如下:
關鍵配置
描述
endpoint
填寫Bucket所在地域對應的Endpoint。以華東1(杭州)為例,Endpoint填寫為https://oss-cn-hangzhou.aliyuncs.com。關于獲取Endpoint的更多信息,請參見OSS地域和訪問域名。
bucket
填寫存儲空間名稱。
index_file
索引文件的路徑。
說明示例中,索引文件格式為每條樣本使用英文逗號(,)分隔,樣本路徑與Label之間使用英文冒號(:)分隔。
Save或Load模型
您可以使用OSS Python API Save或Load PyTorch模型(關于PyTorch如何Save或Load模型,詳情請參見PyTorch),示例如下:
Save模型
from io import BytesIO import torch import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) # bucket_name bucket_name = "<your_bucket_name>" bucket = oss2.Bucket(auth, endpoint, bucket_name) buffer = BytesIO() torch.save(model.state_dict(), buffer) bucket.put_object("<your_model_path>", buffer.getvalue())其中
endpoint為Bucket所在地域對應的Endpoint。以華東1(杭州)為例,Endpoint填寫為https://oss-cn-hangzhou.aliyuncs.com。
<your_bucket_name>為OSS Bucket名稱,且開頭不帶oss://。
<your_model_path>為模型路徑,都需要根據實際情況修改。
Load模型
from io import BytesIO import torch import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) bucket_name = "<your_bucket_name>" bucket = oss2.Bucket(auth, endpoint, bucket_name) buffer = BytesIO(bucket.get_object("<your_model_path>").read()) model.load_state_dict(torch.load(buffer))其中
endpoint為Bucket所在地域對應的Endpoint。以華東1(杭州)為例,Endpoint填寫為https://oss-cn-hangzhou.aliyuncs.com。
<your_bucket_name>為OSS Bucket名稱,且開頭不帶oss://。
<your_model_path>為模型路徑,都需要根據實際情況修改。