PyAlink腳本支持通過編寫代碼的方式來調用Alink的所有算法。您可以使用PyAlink腳本調用Alink的分類算法做分類、 調用回歸算法做回歸、調用推薦算法做推薦等。PyAlink腳本也支持與其他Designer的算法組件無縫銜接, 完成業務鏈路的搭建及效果驗證。本文為您介紹如何使用PyAlink腳本。
背景信息
PyAlink腳本支持兩種使用方式(方式一:單獨使用PyAlink腳本、方式二:PyAlink腳本與其他Designer的算法組件組合使用),可以使用上百種Alink組件,且支持通過編寫代碼的方式讀入和寫出多種類型的數據(PyAlink腳本不同數據類型的讀入和寫出方式)。后續您可以將PyAlink腳本生成的PipelineModel模型部署為EAS服務,詳情請參見使用示例:將PyAlink腳本生成的模型部署為EAS服務。
相關材料下載
基本概念
在使用PyAlink腳本之前,請先了解以下基本概念。
功能模塊 | 基本概念 |
Operator | 在Alink里,每個算法功能都是一個Operator。分為批式Operator和流式Operator。例如:邏輯回歸包含以下Operator:
Operator之間使用Link或LinkFrom連接,具體使用示例如下。 每個Operator都有參數。例如:邏輯回歸包含以下參數。
配置參數的方式為set+參數名稱,具體使用示例如下。 數據導入(Source)和數據導出(Sink)是一類特殊的Operator,定義好之后,可以通過Link或LinkFrom和算法組件連接,具體實現如下圖所示。  Alink包含常用的流式數據源和批式數據源,詳情請參見算法文檔(相關材料下載)中的數據導入和數據導出部分,具體使用示例如下。 |
Pipeline | Alink算法支持的另外一種使用方式。可以將數據處理、特征生成、模型訓練放在一起,進行訓練、預測及在線服務,具體使用示例如下。 |
Vector | Alink的一種自定義數據類型,支持以下兩種格式。
說明 在Alink里,如果列是Vector類型,則參數名稱一般為vectorColName。 |
PyAlink腳本支持的Alink組件
您可以在PyAlink腳本中使用上百種Alink組件,包括數據處理、特征工程、模型訓練等組件。具體支持的組件列表,詳情請參見PyAlink 產品版組件文檔。
PyAlink腳本當前僅支持Pipeline組件和批組件,暫時不支持流組件。
方式一:單獨使用PyAlink腳本
以ItemCf模型對movielens數據集進行打分為例,介紹如何在Designer平臺使用阿里云資源運行使用PyAlink腳本實現的業務流程。具體操作步驟如下所示。
進入Designer頁面,并創建空白工作流,具體操作請參見操作步驟。
在工作流列表,選擇已創建的空白工作流,單擊進入工作流。
在左側組件列表的搜索框中,搜索PyAlink腳本,并將PyAlink腳本拖入右側畫布中,畫布中自動生成一個名稱為PyAlink腳本-1的工作流節點。
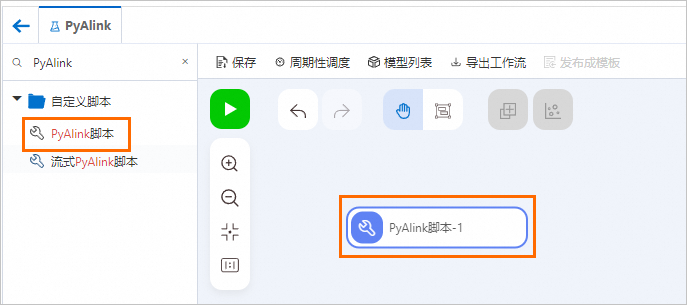
在畫布中選中PyAlink腳本-1節點,在右側參數設置和執行調優頁簽配置相關參數。
在參數設置頁簽編寫代碼,代碼腳本內容如下所示。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") result = itemCF.transform(predictData) result.link(sinks[0]) BatchOperator.execute()PyAlink腳本支持4個輸出樁,代碼腳本中通過
result.link(sinks[0])將輸出的數據寫出到第一個輸出樁,下游可以通過連接PyAlink腳本的第一個輸出樁來讀取該腳本輸出的數據。PyAlink腳本具體支持的不同數據類型的讀入和寫出方式請參見PyAlink腳本不同數據類型的讀入和寫出方式。在執行調優頁簽設置運行模型和節點規格。
參數
描述
選擇作業的運行模式
支持以下兩種模式:
DLC(單機多并發):建議在任務數據規模小且在調試驗證階段時使用。
MaxCompute(分布式):建議在任務數據規模大或在實際生產任務時使用。
Flink全托管(分布式):表示使用當前工作空間綁定的Flink集群資源進行分布式執行。
節點個數
僅當選擇作業的運行模式為MaxCompute(分布式)或Flink全托管(分布式)時,才需要配置該參數。執行節點的個數,為空時系統根據任務數據自動分配,默認為空。
每個節點的內存大小,單位MB
僅當選擇作業的運行模式為MaxCompute(分布式)或Flink全托管(分布式)時,才需要配置該參數。單個節點的內存大小,單位MB。取值為正整數,默認為8192。
每個節點的CPU核心數目
僅當選擇作業的運行模式為MaxCompute(分布式)或Flink全托管(分布式)時,才需要配置該參數。單個節點的CPU核心數目,取值為正整數,默認為空。
選擇腳本運行的節點規格
DLC節點的資源類型配置,默認為2vCPU+8GB Mem-ecs.g6.large。
在畫布上方單擊保存按鈕,然后單擊運行按鈕
 ,運行PyAlink腳本。
,運行PyAlink腳本。任務運行結束后,右鍵單擊畫布中的PyAlink腳本-1,在快捷菜單中,單擊,查看運行結果。
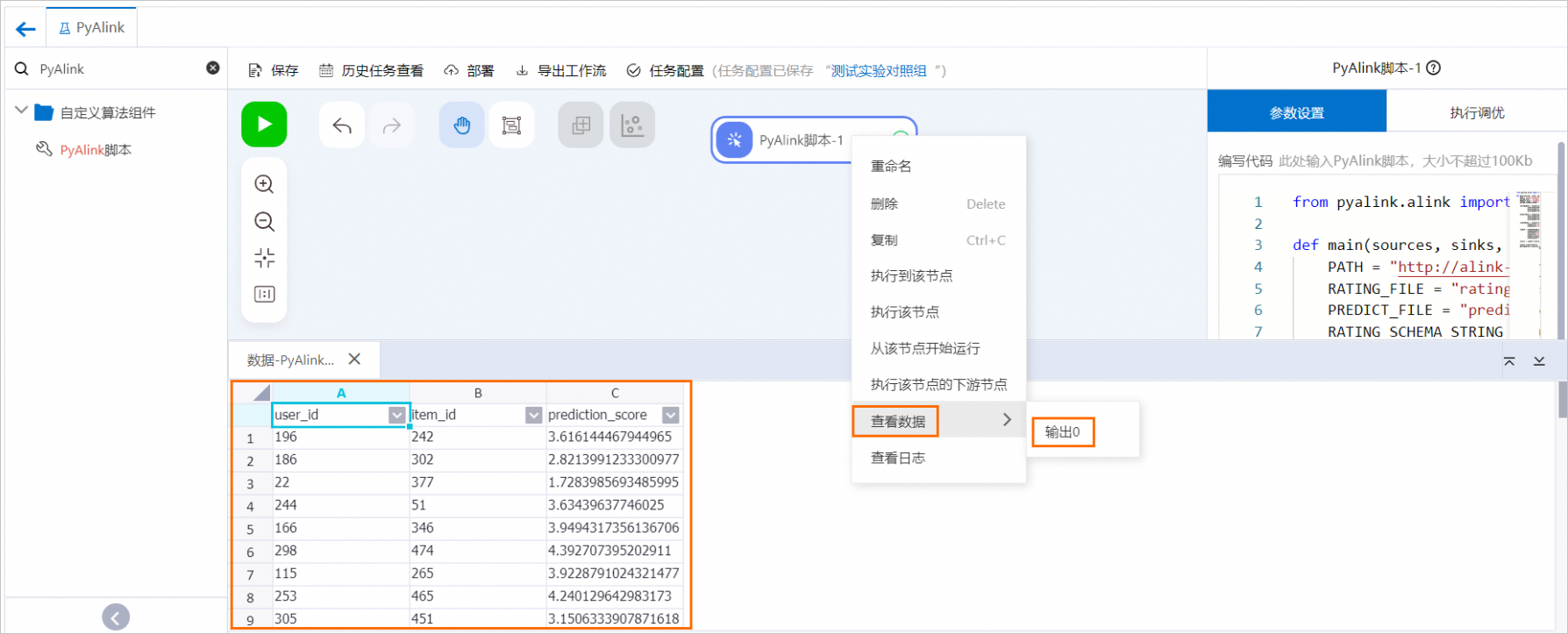
列名
描述
user_id
用戶ID。
item_id
電影ID。
prediction_score
用來表示用戶對電影的喜歡程度,作為電影推薦的參考指標。
方式二:PyAlink腳本與其他Designer的算法組件組合使用
PyAlink腳本的輸入樁、輸出樁與其他Designer的算法組件無任何差別,可以相互連接共同使用。具體使用方式如下圖所示。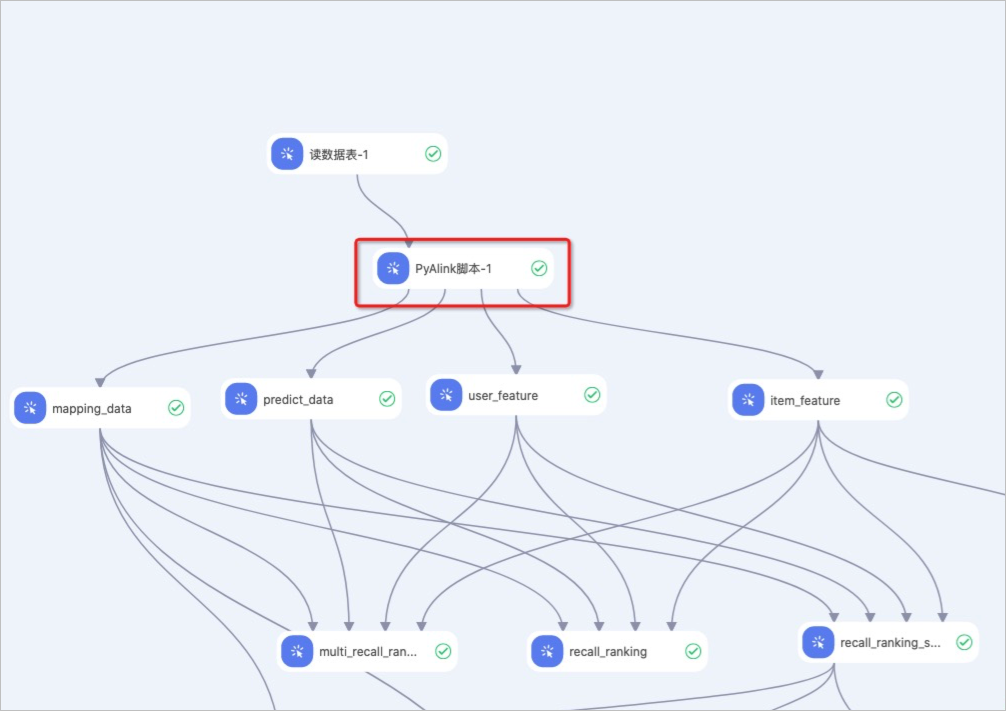
PyAlink腳本不同數據類型的讀入和寫出方式
讀入數據方式。
讀取MaxCompute表,通過輸入樁的方式從上游傳入,代碼示例如下。
train_data = sources[0] test_data = sources[1]代碼中sources[0]表示第一個輸入樁對應的MaxCompute表,sources[1]表示第二個輸入樁對應的MaxCompute表,依此類推,最多支持4個輸入樁。
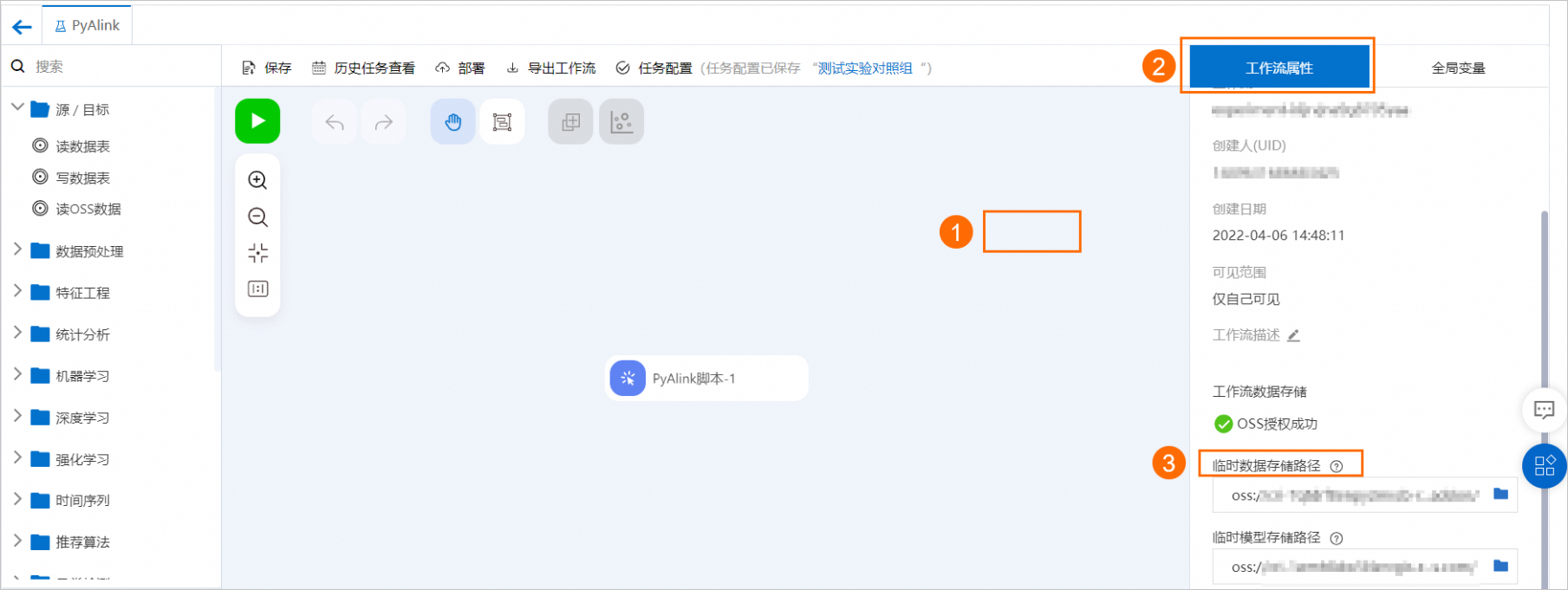
讀取網絡文件系統的數據,通過Alink的Source組件(CsvSourceBatchOp,AkSourceBatchOp)在代碼中實現數據的讀入。支持讀入以下兩種類型的文件:
讀入HTTP格式的網絡共享文件,代碼示例如下所示:
ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING)讀取OSS網絡文件,需要按照下圖操作指引,設置數據讀取路徑。
 代碼示例如下。
代碼示例如下。model_data = AkSourceBatchOp().setFilePath("oss://xxxxxxxx/model_20220323.ak")
寫出數據方式。
寫出MaxCompute表,通過輸出樁的方式寫出到下游,代碼示例如下所示。
result0.link(sinks[0]) result1.link(sinks[1]) BatchOperator.execute()result0.link(sinks[0]),該行表示將數據寫出,并支持輸出樁訪問。該行表示第一個輸出樁輸出結果表,依此類推最多支持輸出4個結果表。
寫出OSS網絡文件,需要按照下圖操作指引,設置數據寫出路徑。
 代碼示例如下。
代碼示例如下。result.link(AkSinkBatchOp() \ .setFilePath("oss://xxxxxxxx/model_20220323.ak") \ .setOverwriteSink(True)) BatchOperator.execute()
使用示例:將PyAlink腳本生成的模型部署為EAS服務
生成待部署的模型。
當PyAlink腳本生成的模型為PipelineModel時,才能將模型部署為EAS服務。按照以下代碼示例生成PipelineModel模型文件,具體操作方法請參見方式一:單獨使用PyAlink腳本。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") model = PipelineModel(itemCF) model.save().link(AkSinkBatchOp() \ .setFilePath("oss://<your_bucket_name>/model.ak") \ .setOverwriteSink(True)) BatchOperator.execute()其中,
<your_bucket_name>為OSS Bucket名稱。重要請確認您對PATH中配置的數據集路徑有讀權限,否則組件將運行失敗。
生成EAS配置文件。
執行以下腳本,將輸出結果寫入config.json文件。
# EAS的配置文件 import json # 生成 EAS 模型配置 model_config = {} # EAS接收數據的schema。 model_config['inputDataSchema'] = "id long, movieid long" model_config['modelVersion'] = "v0.2" eas_config = { "name": "recomm_demo", "model_path": "http://xxxxxxxx/model.ak", "processor": "alink_outer_processor", "metadata": { "instance": 1, "memory": 2048, "region":"cn-beijing" }, "model_config": model_config } print(json.dumps(eas_config, indent=4))config.json文件中的關鍵參數解釋:
name:部署模型服務的名稱。
model_path:存儲PipelineModel模型文件的OSS路徑,需要修改為實際存放模型文件的OSS路徑。
config.json文件中的其他參數解釋,詳情請參見命令使用說明。
將模型部署為EAS服務。
您可以登錄eascmd客戶端部署模型服務。如何登錄eascmd客戶端,請參見下載并認證客戶端。以Windows 64版本為例,使用以下命令部署模型服務。
eascmdwin64.exe create config.json