LLM大語言模型部署
EAS提供了場景化部署方式,您只需配置幾個參數,即可一鍵部署流行的開源LLM大語言模型服務應用,以獲得大模型的推理能力。本文為您介紹如何通過EAS一鍵部署和調用LLM大語言模型服務,以及常見的問題和解決方法。
背景信息
隨著ChatGPT和通義千問等大模型在業界的廣泛應用,基于LLM大語言模型的推理應用成為當前熱門的應用之一。EAS能夠輕松部署包括Llama3、Qwen、Llama2、ChatGLM、Baichuan、Yi-6B、Mistral-7B及Falcon-7B在內的多種開源大模型服務應用。此外,部署在EAS上的LLM大語言模型服務不僅支持WebUI和API調用方式,還支持通過LangChain集成企業自有業務數據,從而生成基于本地知識庫的定制答案。
LangChain功能介紹:
LangChain是一個開源的框架,可以讓AI開發人員將像GPT-4這樣的大語言模型(LLM)和外部數據結合起來,從而在盡可能少消耗計算資源的情況下,獲得更好的性能和效果。
LangChain工作原理:
將一個大的數據源,比如一個20頁的PDF文件,分成各個區塊,并通過嵌入模型(比如BGE、text2vec等)將它們轉換為數值向量,然后把這些向量存儲到一個專門的向量數據庫里。
LangChain首先將用戶上傳的知識庫進行自然語言處理,并作為大模型的知識庫存儲在本地。每次推理時,會首先在本地知識庫中查找與輸入問題相近的文本塊(chunk),并將知識庫答案與用戶輸入的問題一起輸入大模型,生成基于本地知識庫的定制答案。
前提條件
如果您有部署自定義模型的需求,您需要完成以下準備工作:
準備自定義模型文件及相關配置文件,需要準備的模型文件樣例如下:
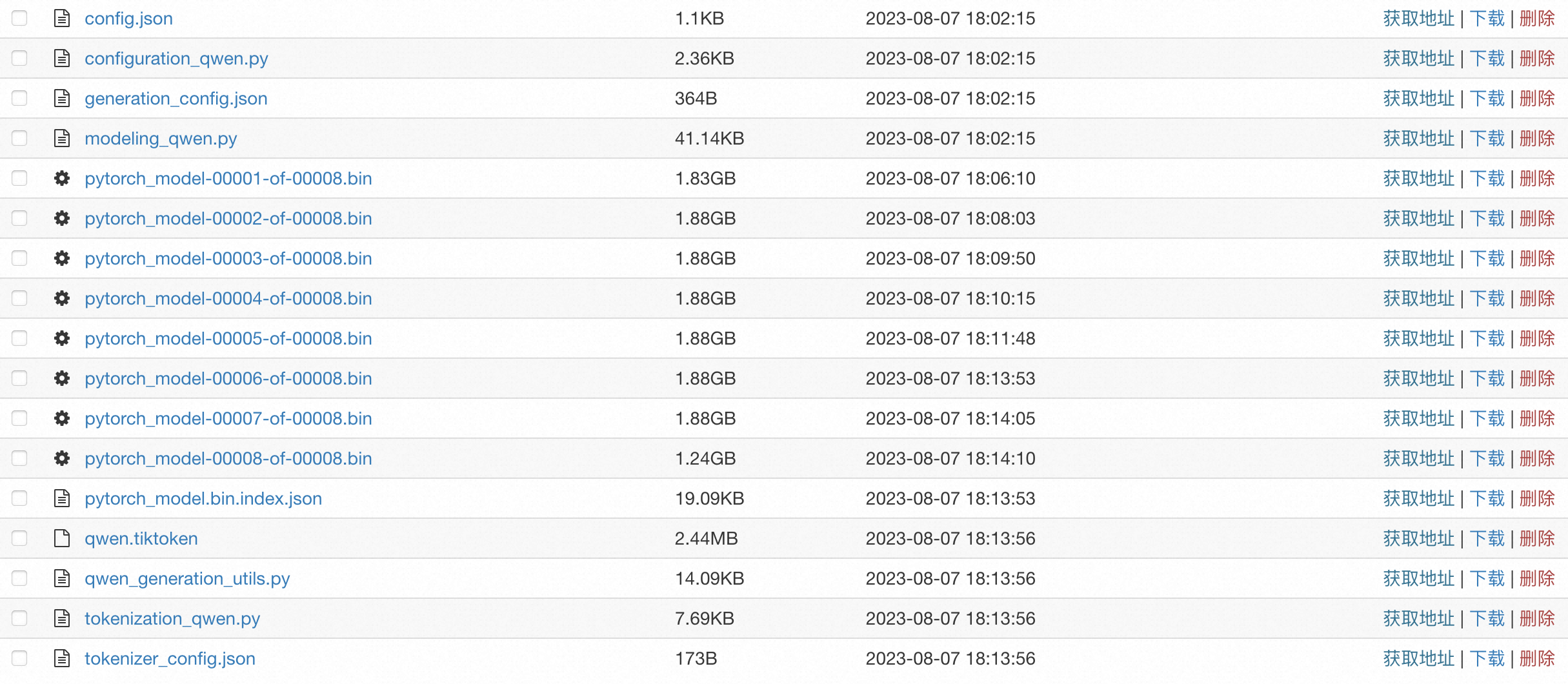
其中配置文件中必須包含config.json文件,您需要按照Huggingface或Modelscope的模型格式配置Config文件。示例文件詳情,請參見config.json。
創建對象存儲OSS存儲空間(Bucket)或NAS文件系統,用來存放自定義模型文件,您也可以將模型文件注冊為PAI的AI資產,方便管理和維護。以OSS為例,具體操作,請參見控制臺快速入門。
將自定義模型文件及相關配置文件上傳到OSS存儲空間(Bucket)中。具體操作,請參見控制臺快速入門。
使用限制
目前,推理加速引擎僅支持Qwen2-7b、Qwen1.5-1.8b、Qwen1.5-7b、Qwen1.5-14b、llama3-8b、llama2-7b、llama2-13b、chatglm3-6b、baichuan2-7b、baichuan2-13b、falcon-7b、yi-6b、mistral-7b-instruct-v0.2、gemma-2b-it、gemma-7b-it、deepseek-coder-7b-instruct-v1.5模型。
僅無推理加速的EAS服務支持使用Langchain功能。
部署EAS服務
支持以下兩種部署方式:
方式一:場景化模型部署(推薦)
登錄PAI控制臺,在頁面上方選擇目標地域,并在右側選擇目標工作空間,然后單擊進入EAS。
在模型在線服務(EAS)頁面,單擊部署服務,然后在場景化模型部署區域,單擊LLM大語言模型部署。
在部署LLM大語言模型頁面,配置以下關鍵參數。
參數
描述
基本信息
服務名稱
自定義模型服務名稱。
模型來源
支持配置以下兩種模型:
開源公共模型
自持微調模型
模型類別
當模型來源選擇開源公共模型時,支持使用的模型類別包括Qwen、Llama、ChatGLM、Baichuan、Falcon、Yi、Mistral、Gemma以及DeepSeek等。
當模型來源選擇自持微調模型時,您需要選擇與模型相匹配的大模型類別、參數量和精度。
模型配置
當模型來源選擇自持微調模型時,您需要選擇模型存儲位置。以對象存儲OSS為例,配置類型選擇對象存儲(OSS),并配置模型文件所在的OSS存儲路徑。
資源配置
資源配置選擇
當使用開源公共模型時,選擇模型類別后,系統會自動推薦適合的資源規格。
當使用自持微調模型時,模型類別配置完成后,系統將自動配置資源規格。您也可以根據模型參數量,自行選擇相匹配的資源規格,詳情請參見如何切換其他的開源大模型。
推理加速
當模型類別選擇Qwen2-7b、Qwen1.5-1.8b、Qwen1.5-7b、Qwen1.5-14b、llama3-8b、llama2-7b、llama2-13b、chatglm3-6b、baichuan2-7b、baichuan2-13b、falcon-7b、yi-6b、mistral-7b-instruct-v0.2、gemma-2b-it、gemma-7b-it、deepseek-coder-7b-instruct-v1.5時,支持使用推理加速功能。取值如下:
無加速
PAI-BladeLLM自定推理加速
開源框架vllm推理加速
說明使用推理加速功能時,部署好的EAS服務將不能使用LangChain功能。
單擊部署。
方式二:自定義模型部署
登錄PAI控制臺,在頁面上方選擇目標地域,并在右側選擇目標工作空間,然后單擊進入EAS。
單擊部署服務,然后在自定義模型部署區域,單擊自定義部署。
在自定義部署頁面,配置以下關鍵參數,其他參數配置說明,請參見服務部署:控制臺。
參數
描述
基本信息
服務名稱
自定義模型服務名稱。
環境信息
部署方式
選擇鏡像部署,并選中開啟Web應用復選框。
鏡像配置
在官方鏡像列表中選擇chat-llm-webui>chat-llm-webui:3.0。
說明由于版本迭代迅速,部署時鏡像版本選擇最高版本即可。
如果您想使用推理加速功能,鏡像版本配置如下:
說明使用推理加速功能時,部署好的EAS服務將不能使用LangChain功能。
chat-llm-webui:3.0-vllm:使用vLLM推理加速引擎。
chat-llm-webui:3.0-blade:使用BladeLLM推理加速引擎。
模型配置
如果您有掛載自定義模型的需求,需要進行模型配置。以OSS掛載為例,配置以下參數:
OSS:選擇自定義模型文件所在的對象存儲OSS路徑。例如:
oss://bucket-test/data-oss/。掛載路徑:配置為
/data。是否只讀:開關關閉。
運行命令
配置鏡像版本后,系統會自動配置運行命令
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-7B-Chat和端口號,該命令默認拉起通義千問-7B參數量的大模型。請參閱更多參數配置說明,以了解在運行命令中可支持的配置選項。如果您需要一鍵拉起其他更多開源大模型,可以替換為指定開源大模型的運行命令,詳情請參見如何切換其他的開源大模型。
如果部署自定義模型,您需要在運行命令中增加以下參數:
--model-path:配置為
/data。需要與模型配置中的掛載路徑保持一致。--model-type:模型類型。
不同類型的模型的運行命令配置示例,請參見運行命令。
資源部署
資源類型
選擇公共資源。
部署資源
資源規格必須選擇GPU類型,默認拉起通義千問-7B參數量的大模型時,資源規格推薦使用ml.gu7i.c16m60.1-gu30(性價比最高)。
在部署其他開源大模型時,您需要選擇與模型參數量相匹配的資源規格,如何選擇資源規格,請參見如何切換其他的開源大模型。
參數
描述
默認值
--model-path
設置預置模型名或自定義模型路徑。
示例1:加載預置模型,您可以使用EAS預置的meta-llama/Llama-2-*系列模型(包括:7b-hf,7b-chat-hf,13b-hf,13b-chat-hf等)。例如
python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf。示例2:加載本地自定義模型,例如
python webui/webui_server.py --port=8000 --model-path=/llama2-7b-chat。
服務的默認模型為meta-llama/Llama-2-7b-chat-hf。
--cpu
如需使用CPU完成模型推理可使用此命令行參數。
例如:
python webui/webui_server.py --port=8000 --cpu。默認使用GPU做模型推理。
--precision
設置llama2模型的精度:支持使用fp32、fp16等精度,例如
python webui/webui_server.py --port=8000 --precision=fp32。系統根據GPU顯存大小自動配置7b模型使用的精度。
--port
指定WebUI服務的監聽端口。
示例:
python webui/webui_server.py --port=8000。8000
--api-only
僅使用API方式啟動服務。默認情況下,部署服務會同時啟動WebUI與API Server。
示例:
python webui/webui_server.py --api-only。False
--no-api
僅使用WebUI方式啟動服務。默認情況下,部署服務會同時啟動WebUI與API Server。
示例:
python webui/webui_server.py --no-api。False
--max-new-tokens
生成輸出token的最大長度,單位為個。
示例:
python api/api_server.py --port=8000 --max-new-tokens=1024。2048
--temperature
用于調節模型輸出結果的隨機性,值越大隨機性越強,0值為固定輸出。Float類型,區間為0~1。
示例:
python api/api_server.py --port=8000 --max_length=0.8。0.95
--max_round
推理時可支持的歷史對話輪數。
示例:
python api/api_server.py --port=8000 --max_round=10。5
--top_k
從生成結果中選擇候選輸出的數量,正整數。
示例:
python api/api_server.py --port=8000 --top_k=10。None
--top_p
從生成結果中按百分比選擇輸出結果。Float類型,區間為0~1。
示例:
python api/api_server.py --port=8000 --top_p=0.9。None
--no-template
Llama2、Falcon等模型會提供默認的Prompt模板,如果不設置該參數,會使用默認的Prompt模板,如果設置了該參數,您需要指定自己的模板。
示例:
python api/api_server.py --port=8000 --no-template。使用默認的Prompt模板
--log-level
選擇日志輸出等級,日志等級分為DEBUG、INFO、WARNING和ERROR。
示例:
python api/api_server.py --port=8000 --log-level=DEBUG。INFO
--export-history-path
EAS LLM服務支持后臺導出對話記錄。啟動服務時,需要通過命令行參數指定導出路徑。通常情況下,該路徑是一個OSS的掛載路徑。EAS服務會將1小時內的對話記錄導出到一個文件中。
示例:
python api/api_server.py --port=8000 --export-history-path=/your_mount_path。默認不開啟
--export-interval
設置倒數記錄的時間周期,單位為秒。例如,設置
--export-interval=3600時,表示將最近1小時的對話記錄導入到一個文件中。3600
--backend為EAS配置推理加速引擎,取值如下:
PAI-BladeLLM自動推理加速:配置為
--backend=blade。開源框架vllm推理加速:配置為
--backend=vllm。
說明僅模型類別選擇Qwen2-7b、Qwen1.5-1.8b、Qwen1.5-7b、Qwen1.5-14b、llama3-8b、llama2-7b、llama2-13b、chatglm3-6b、baichuan2-7b、baichuan2-13b、falcon-7b、yi-6b、mistral-7b-instruct-v0.2、gemma-2b-it、gemma-7b-it、deepseek-coder-7b-instruct-v1.5時,支持使用推理加速功能。
默認無加速
模型類型
運行命令
Llama2
python webui/webui_server.py --port=8000 --model-path=/data --model-type=llama2ChatGLM2
python webui/webui_server.py --port=8000 --model-path=/data --model-type=chatglm2ChatGLM3
python webui/webui_server.py --port=8000 --model-path=/data --model-type=chatglm3Qwen(通義千問)
python webui/webui_server.py --port=8000 --model-path=/data --model-type=qwenChatGLM
python webui/webui_server.py --port=8000 --model-path=/data --model-type=chatglmFalcon-7B
python webui/webui_server.py --port=8000 --model-path=/data --model-type=falcon單擊部署。
調用EAS服務
通過WebUI調用EAS服務
單擊目標服務服務方式列下的查看Web應用。

在WebUI頁面,進行模型推理驗證。
在ChatLLM-WebUI頁面的文本框中輸入對話內容,例如
請提供一個理財學習計劃,單擊Send,即可開始對話。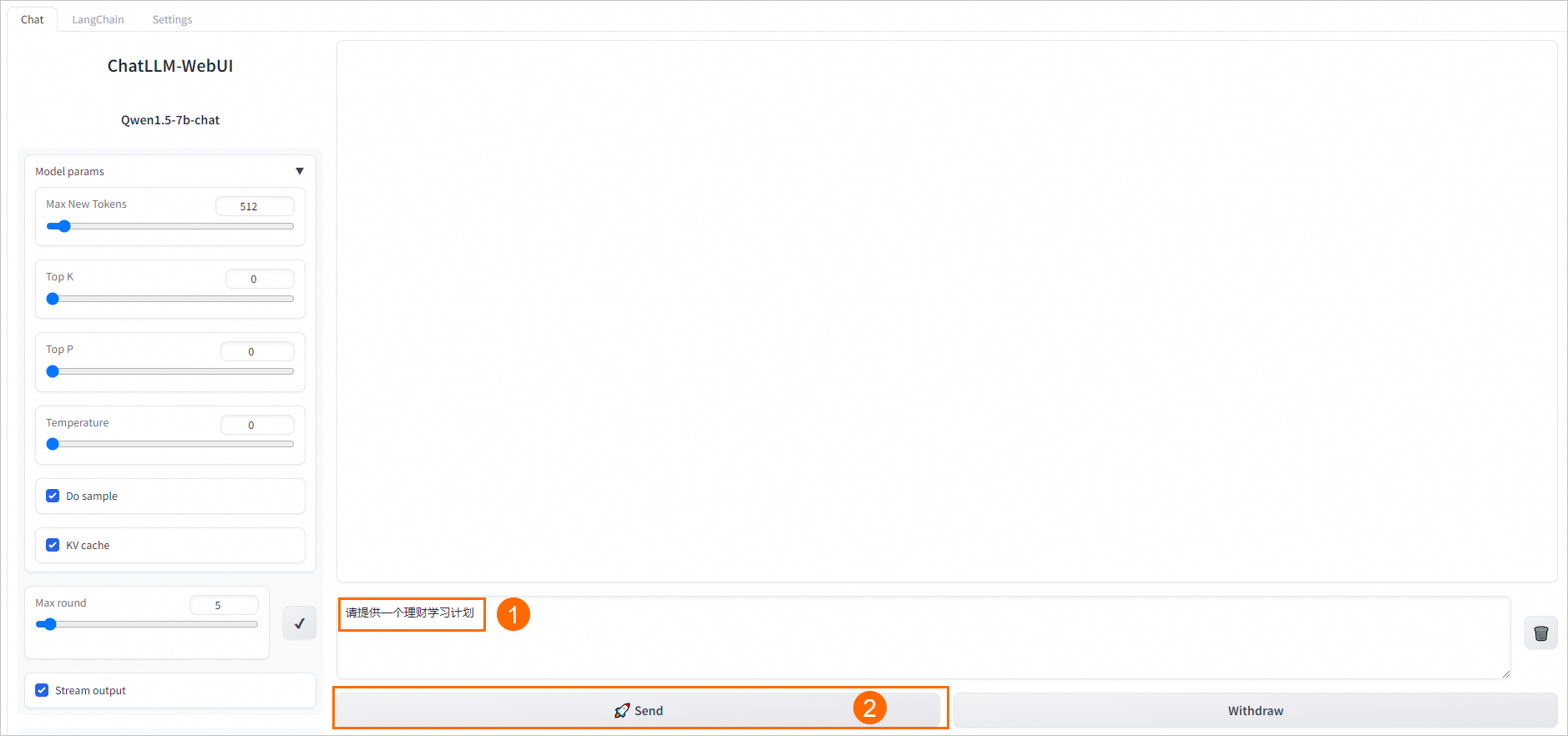
使用LangChain集成您自己的業務數據,生成基于本地知識庫的定制答案。
在WebUI頁面上方的Tab頁選擇LangChain。
在WebUI頁面左下角,按照界面操作指引拉取自定義數據,支持配置.txt、.md、.docx、.pdf格式的文件。
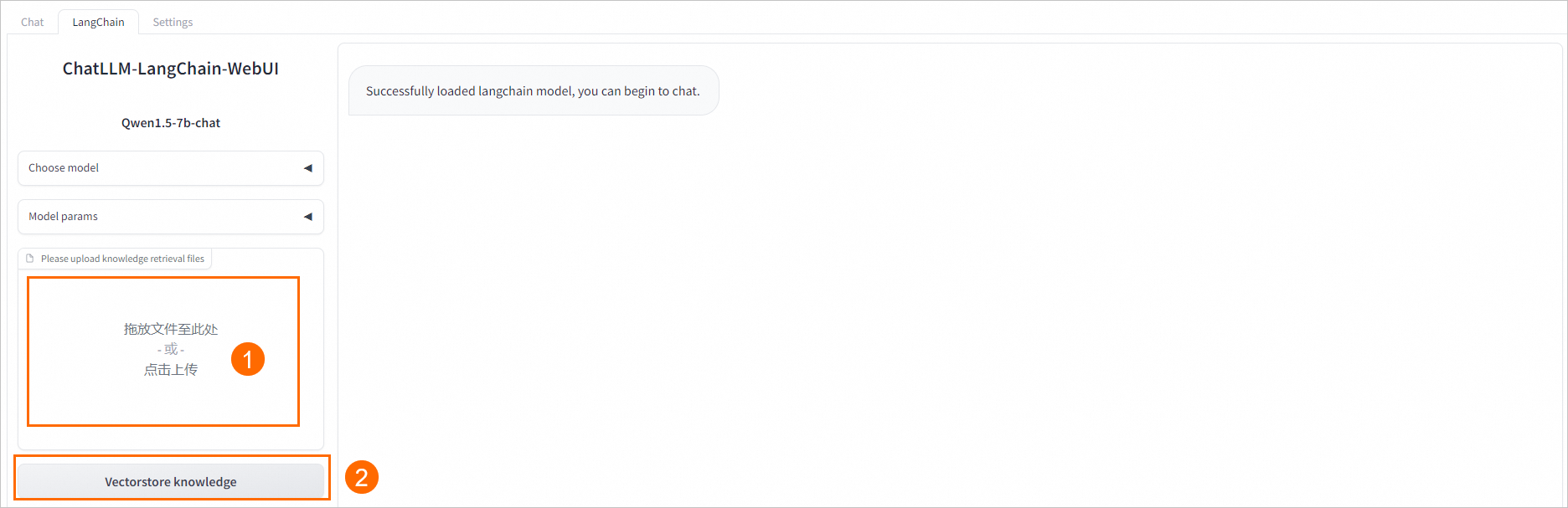
例如上傳README.md文件,單擊左下角的Vectorstore knowledge,返回如下結果表明自定義數據加載成功。
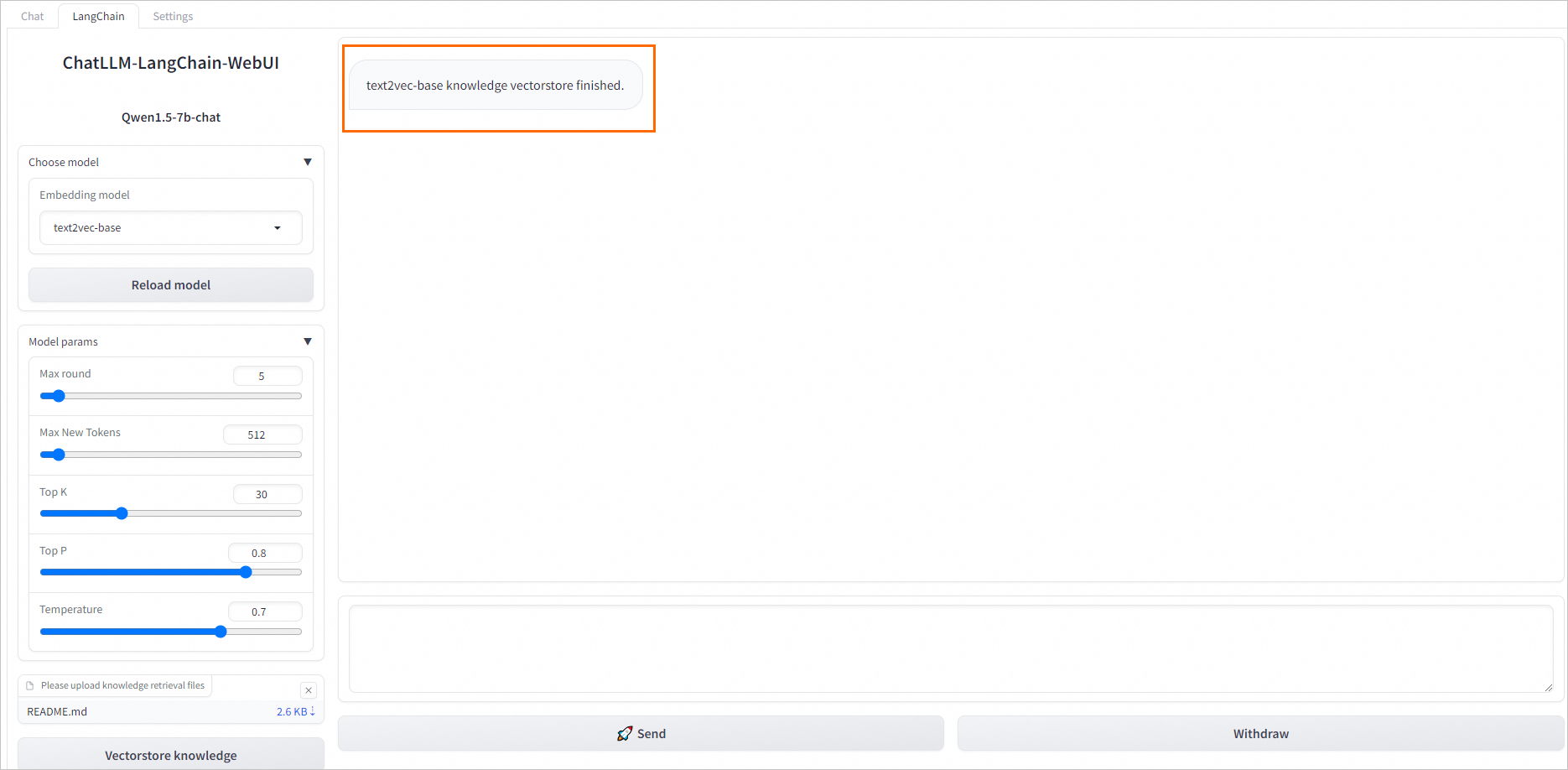
在WebUI頁面底部輸入框中,輸入業務數據相關的問題進行對話即可。
例如在輸入框中輸入
如何安裝deepspeed,單擊Send,即可開始對話。
通過API調用EAS服務
獲取服務訪問地址和Token。
進入模型在線服務(EAS)頁面,詳情請參見部署EAS服務。
在該頁面中,單擊目標服務名稱進入服務詳情頁面。
在基本信息區域單擊查看調用信息,在公網地址調用頁簽獲取服務Token和訪問地址。
啟動API進行模型推理。
使用HTTP方式調用服務
非流式調用
客戶端使用標準的HTTP格式,使用curl命令調用時,支持發送以下兩種類型的請求:
發送String類型的請求
curl $host -H 'Authorization: $authorization' --data-binary @chatllm_data.txt -v其中:$authorization需替換為服務Token,$host:需替換為服務訪問地址,chatllm_data.txt:該文件為包含問題的純文本文件。
發送結構化類型的請求
curl $host -H 'Authorization: $authorization' -H "Content-type: application/json" --data-binary @chatllm_data.json -v -H "Connection: close"使用chatllm_data.json文件來設置推理參數,chatllm_data.json文件的內容格式如下:
{ "max_new_tokens": 4096, "use_stream_chat": false, "prompt": "How to install it?", "system_prompt": "Act like you are programmer with 5+ years of experience.", "history": [ [ "Can you tell me what's the bladellm?", "BladeLLM is an framework for LLM serving, integrated with acceleration techniques like quantization, ai compilation, etc. , and supporting popular LLMs like OPT, Bloom, LLaMA, etc." ] ], "temperature": 0.8, "top_k": 10, "top_p": 0.8, "do_sample": true, "use_cache": true }參數說明如下,請酌情添加或刪除。
參數
描述
默認值
max_new_tokens
生成輸出token的最大長度,單位為個。
2048
use_stream_chat
是否使用流式輸出形式。
true
prompt
用戶的Prompt。
""
system_prompt
系統Prompt。
""
history
對話的歷史記錄,類型為List[Tuple(str, str)]。
[()]
temperature
用于調節模型輸出結果的隨機性,值越大隨機性越強,0值為固定輸出。Float類型,區間為0~1。
0.95
top_k
從生成結果中選擇候選輸出的數量。
30
top_p
從生成結果中按百分比選擇輸出結果。Float類型,區間為0~1。
0.8
do_sample
開啟輸出采樣。
true
use_cache
開啟KV Cache。
true
您也可以基于Python的requests包實現自己的客戶端,示例代碼如下:
import argparse import json from typing import Iterable, List import requests def post_http_request(prompt: str, system_prompt: str, history: list, host: str, authorization: str, max_new_tokens: int = 2048, temperature: float = 0.95, top_k: int = 1, top_p: float = 0.8, langchain: bool = False, use_stream_chat: bool = False) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } if not history: history = [ ( "San Francisco is a", "city located in the state of California in the United States. \ It is known for its iconic landmarks, such as the Golden Gate Bridge \ and Alcatraz Island, as well as its vibrant culture, diverse population, \ and tech industry. The city is also home to many famous companies and \ startups, including Google, Apple, and Twitter." ) ] pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "use_stream_chat": use_stream_chat, "history": history } if langchain: pload["langchain"] = langchain response = requests.post(host, headers=headers, json=pload, stream=use_stream_chat) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=4) parser.add_argument("--top-p", type=float, default=0.8) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.95) parser.add_argument("--prompt", type=str, default="How can I get there?") parser.add_argument("--langchain", action="store_true") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p use_stream_chat = False temperature = args.temperature langchain = args.langchain max_new_tokens = args.max_new_tokens host = "EAS服務公網地址" authorization = "EAS服務公網Token" print(f"Prompt: {prompt!r}\n", flush=True) # 在客戶端請求中可設置語言模型的system prompt。 system_prompt = "Act like you are programmer with \ 5+ years of experience." # 客戶端請求中可設置對話的歷史信息,客戶端維護當前用戶的對話記錄,用于實現多輪對話。通常情況下可以使用上一輪對話返回的histroy信息,history格式為List[Tuple(str, str)]。 history = [] response = post_http_request( prompt, system_prompt, history, host, authorization, max_new_tokens, temperature, top_k, top_p, langchain=langchain, use_stream_chat=use_stream_chat) output, history = get_response(response) print(f" --- output: {output} \n --- history: {history}", flush=True) # 服務端返回JSON格式的響應結果,包含推理結果與對話歷史。 def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history其中:
host:配置為服務訪問地址。
authorization:配置為服務Token。
流式調用
流式調用使用HTTP SSE方式,其他設置方式與非流式相同,代碼參考如下:
import argparse import json from typing import Iterable, List import requests def clear_line(n: int = 1) -> None: LINE_UP = '\033[1A' LINE_CLEAR = '\x1b[2K' for _ in range(n): print(LINE_UP, end=LINE_CLEAR, flush=True) def post_http_request(prompt: str, system_prompt: str, history: list, host: str, authorization: str, max_new_tokens: int = 2048, temperature: float = 0.95, top_k: int = 1, top_p: float = 0.8, langchain: bool = False, use_stream_chat: bool = False) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } if not history: history = [ ( "San Francisco is a", "city located in the state of California in the United States. \ It is known for its iconic landmarks, such as the Golden Gate Bridge \ and Alcatraz Island, as well as its vibrant culture, diverse population, \ and tech industry. The city is also home to many famous companies and \ startups, including Google, Apple, and Twitter." ) ] pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "use_stream_chat": use_stream_chat, "history": history } if langchain: pload["langchain"] = langchain response = requests.post(host, headers=headers, json=pload, stream=use_stream_chat) return response def get_streaming_response(response: requests.Response) -> Iterable[List[str]]: for chunk in response.iter_lines(chunk_size=8192, decode_unicode=False, delimiter=b"\0"): if chunk: data = json.loads(chunk.decode("utf-8")) output = data["response"] history = data["history"] yield output, history if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=4) parser.add_argument("--top-p", type=float, default=0.8) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.95) parser.add_argument("--prompt", type=str, default="How can I get there?") parser.add_argument("--langchain", action="store_true") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p use_stream_chat = True temperature = args.temperature langchain = args.langchain max_new_tokens = args.max_new_tokens host = "" authorization = "" print(f"Prompt: {prompt!r}\n", flush=True) system_prompt = "Act like you are programmer with \ 5+ years of experience." history = [] response = post_http_request( prompt, system_prompt, history, host, authorization, max_new_tokens, temperature, top_k, top_p, langchain=langchain, use_stream_chat=use_stream_chat) for h, history in get_streaming_response(response): print( f" --- stream line: {h} \n --- history: {history}", flush=True)其中:
host:配置為服務訪問地址。
authorization:配置為服務Token。
使用WebSocket方式調用服務
為了更好地維護用戶對話信息,您也可以使用WebSocket方式保持與服務的連接完成單輪或多輪對話,代碼示例如下:
import os import time import json import struct from multiprocessing import Process import websocket round = 5 questions = 0 def on_message_1(ws, message): if message == "<EOS>": print('pid-{} timestamp-({}) receives end message: {}'.format(os.getpid(), time.time(), message), flush=True) ws.send(struct.pack('!H', 1000), websocket.ABNF.OPCODE_CLOSE) else: print("{}".format(time.time())) print('pid-{} timestamp-({}) --- message received: {}'.format(os.getpid(), time.time(), message), flush=True) def on_message_2(ws, message): global questions print('pid-{} --- message received: {}'.format(os.getpid(), message)) # end the client-side streaming if message == "<EOS>": questions = questions + 1 if questions == 5: ws.send(struct.pack('!H', 1000), websocket.ABNF.OPCODE_CLOSE) def on_message_3(ws, message): print('pid-{} --- message received: {}'.format(os.getpid(), message)) # end the client-side streaming ws.send(struct.pack('!H', 1000), websocket.ABNF.OPCODE_CLOSE) def on_error(ws, error): print('error happened: ', str(error)) def on_close(ws, a, b): print("### closed ###", a, b) def on_pong(ws, pong): print('pong:', pong) # stream chat validation test def on_open_1(ws): print('Opening Websocket connection to the server ... ') params_dict = {} params_dict['prompt'] = """Show me a golang code example: """ params_dict['temperature'] = 0.9 params_dict['top_p'] = 0.1 params_dict['top_k'] = 30 params_dict['max_new_tokens'] = 2048 params_dict['do_sample'] = True raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') # raw_req = f"""To open a Websocket connection to the server: """ ws.send(raw_req) # end the client-side streaming # multi-round query validation test def on_open_2(ws): global round print('Opening Websocket connection to the server ... ') params_dict = {"max_new_tokens": 6144} params_dict['temperature'] = 0.9 params_dict['top_p'] = 0.1 params_dict['top_k'] = 30 params_dict['use_stream_chat'] = True params_dict['prompt'] = "您好!" params_dict = { "system_prompt": "Act like you are programmer with 5+ years of experience." } raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') ws.send(raw_req) params_dict['prompt'] = "請使用Python,編寫一個排序算法" raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') ws.send(raw_req) params_dict['prompt'] = "請轉寫成java語言的實現" raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') ws.send(raw_req) params_dict['prompt'] = "請介紹一下你自己?" raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') ws.send(raw_req) params_dict['prompt'] = "請總結上述對話" raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') ws.send(raw_req) # Langchain validation test. def on_open_3(ws): global round print('Opening Websocket connection to the server ... ') params_dict = {} # params_dict['prompt'] = """To open a Websocket connection to the server: """ params_dict['prompt'] = """Can you tell me what's the MNN?""" params_dict['temperature'] = 0.9 params_dict['top_p'] = 0.1 params_dict['top_k'] = 30 params_dict['max_new_tokens'] = 2048 params_dict['use_stream_chat'] = False params_dict['langchain'] = True raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8') ws.send(raw_req) authorization = "" host = "ws://" + "" def single_call(on_open_func, on_message_func, on_clonse_func=on_close): ws = websocket.WebSocketApp( host, on_open=on_open_func, on_message=on_message_func, on_error=on_error, on_pong=on_pong, on_close=on_clonse_func, header=[ 'Authorization: ' + authorization], ) # setup ping interval to keep long connection. ws.run_forever(ping_interval=2) if __name__ == "__main__": for i in range(5): p1 = Process(target=single_call, args=(on_open_1, on_message_1)) p2 = Process(target=single_call, args=(on_open_2, on_message_2)) p3 = Process(target=single_call, args=(on_open_3, on_message_3)) p1.start() p2.start() p3.start() p1.join() p2.join() p3.join()其中:
authorization:配置為服務Token。
host:配置為服務訪問地址。并將訪問地址中前端的http替換為ws。
use_stream_chat:通過該請求參數來控制客戶端是否為流式輸出。默認值為True,表示服務端返回流式數據。
參考上述示例代碼中的on_open_2函數的實現方法實現多輪對話。
常見問題及解決方法
如何切換其他的開源大模型
具體操作步驟如下:
單擊目標服務操作列下的更新。
切換其他的開源大模型。
場景化模型部署
在部署LLM大語言模型頁面,更新模型類別為其他開源大模型,然后單擊更新。
自定義模型部署
在更新服務頁面,參考下表內容,根據需要部署的模型來更新運行命令和資源規格,然后單擊更新。
模型名稱
運行命令
推薦機型
Qwen2-7b(通義千問2版本-7B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen2-7B-Instruct單卡GU30
單卡A10
單卡V100(32 G)
Qwen2-72b(通義千問2版本-72B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen2-72B-Instruct兩卡A100(80 G)
四卡A100(40 G)
八卡V100(32 G)
Qwen2-57b-A14b
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen2-57B-A14B-Instruct兩卡A100(80 G)
四卡A100(40 G)
四卡V100(32 G)
Qwen1.5-1.8b(通義千問1.5版本-1.8B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-1.8B-Chat單卡T4
單卡V100(16 G)
單卡GU30
單卡A10
Qwen1.5-7b(通義千問1.5版本-7B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-7B-Chat單卡GU30
單卡A10
Qwen1.5-14b(通義千問1.5版本-14B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-14B-Chat單卡V100(32 G)
單卡A100(40 G)
單卡A100(80 G)
2卡GU30
2卡A10
Qwen1.5-32b(通義千問1.5版本-32B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-32B-Chat單卡A100(80 G)
四卡V100(32 G)
Qwen1.5-72b(通義千問1.5版本-72B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-72B-Chat8卡V100(32 G)
2卡A100(80 G)
4卡A100(40 G)
Qwen1.5-110b(通義千問1.5版本-110B參數量)
python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen1.5-110B-Chat8卡A100(40 G)
4卡A100(80 G)
llama3-8b
python webui/webui_server.py --port=8000 --model-path=/huggingface/meta-Llama-3-8B-Instruct/ --model-type=llama3單卡GU30
單卡A10
單卡V100(32 G)
llama3-70b
python webui/webui_server.py --port=8000 --model-path=/huggingface/meta-Llama-3-70B-Instruct/ --model-type=llama3兩卡A100(80 G)
四卡A100(40 G)
八卡V100(32 G)
Llama2-7b
python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf單卡GU30
單卡A10
單卡V100(32 G)
Llama2-13b
python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-13b-chat-hf單卡V100(32 G)
2卡GU30
2卡A10
llama2-70b
python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-70b-chat-hf8卡V100(32 G)
2卡A100(80 G)
4卡A100(40 G)
chatglm3-6b
python webui/webui_server.py --port=8000 --model-path=THUDM/chatglm3-6b單卡GU30
單卡A10
單卡V100(16 G)
單卡V100(32 G)
baichuan2-7b
python webui/webui_server.py --port=8000 --model-path=baichuan-inc/Baichuan2-7B-Chat單卡GU30
單卡A10
單卡V100(32 G)
baichuan2-13b
python webui/webui_server.py --port=8000 --model-path=baichuan-inc/Baichuan2-13B-Chat2卡GU30
2卡A10
單卡V100(32 G)
falcon-7b
python webui/webui_server.py --port=8000 --model-path=tiiuae/falcon-7b-instruct單卡GU30
單卡A10
單卡V100(32 G)
falcon-40b
python webui/webui_server.py --port=8000 --model-path=tiiuae/falcon-40b-instruct8卡V100(32 G)
2卡A100(80 G)
4卡A100(40 G)
falcon-180b
python webui/webui_server.py --port=8000 --model-path=tiiuae/falcon-180B-chat8卡A100(80 G)
Yi-6b
python webui/webui_server.py --port=8000 --model-path=01-ai/Yi-6B-Chat單卡GU30
單卡A10
單卡V100(16 G)
單卡V100(32 G)
Yi-34b
python webui/webui_server.py --port=8000 --model-path=01-ai/Yi-34B-Chat4卡V100(16 G)
單卡A100(80 G)
4卡A10
mistral-7b-instruct-v0.2
python webui/webui_server.py --port=8000 --model-path=mistralai/Mistral-7B-Instruct-v0.2單卡GU30
單卡A10
單卡V100(32 G)
mixtral-8x7b-instruct-v0.1
python webui/webui_server.py --port=8000 --model-path=mistralai/Mixtral-8x7B-Instruct-v0.14卡A100(80G)
gemma-2b-it
python webui/webui_server.py --port=8000 --model-path=google/gemma-2b-it單卡T4
單卡V100(16 G)
單卡GU30
單卡A10
gemma-7b-it
python webui/webui_server.py --port=8000 --model-path=google/gemma-7b-it單卡GU30
單卡A10
單卡V100(32 G)
deepseek-coder-7b-instruct-v1.5
python webui/webui_server.py --port=8000 --model-path=deepseek-ai/deepseek-coder-7b-instruct-v1.5單卡GU30
單卡A10
單卡V100(32 G)
deepseek-coder-33b-instruct
python webui/webui_server.py --port=8000 --model-path=deepseek-ai/deepseek-coder-33b-instruct單卡A100(80 G)
2卡A100(40 G)
4卡V100(32 G)
deepseek-v2-lite
python webui/webui_server.py --port=8000 --model-path=deepseek-ai/DeepSeek-V2-Lite-Chat單卡A10
單卡A100(40 G)
相關文檔
您可以通過EAS一鍵部署集成了大語言模型(LLM)和檢索增強生成(RAG)技術的對話系統服務,該服務支持使用本地知識庫進行信息檢索。在WebUI界面中集成了LangChain業務數據后,您可以通過WebUI或API接口進行模型推理功能驗證,詳情請參見大模型RAG對話系統。