通過數據視圖組件,您可以可視化地了解特征與標簽列的分布情況及特征的特點,以便后續進行數據分析。該組件支持稀疏和稠密數據格式。本文為您介紹Designer提供的數據視圖算法的參數配置方式及使用示例。
組件配置
您可以使用以下任意一種方式,配置數據視圖組件參數。
方式一:可視化方式
在Designer工作流頁面配置組件參數。
頁簽 | 參數 | 描述 |
字段設置 | 選擇特征列 | 用來表現訓練樣本數據特征的列。 |
選擇目標列 | 用來進行訓練樣本數據的目標列。 | |
枚舉特征 | 勾選的特征將被視作枚舉特征處理。 | |
k:v,k:v稀疏數據格式 | 是否采用KV格式的稀疏數據。 | |
參數設置 | 連續特征離散區間數 | 連續性特征等距離劃分最大區間數。 |
執行調優 | 計算核心數 | 計算的核心數,取值范圍為正整數。 |
每個核心內存 | 每個核心的內存,取值范圍為1 MB~65536 MB。 |
方式二:PAI命令方式
使用PAI命令方式,配置該組件參數。您可以使用SQL腳本組件進行PAI命令調用,詳情請參見SQL腳本。
PAI
-name fe_meta_runner
-project algo_public
-DinputTable="pai_dense_10_10"
-DoutputTable="pai_temp_2263_20384_1"
-DmapTable="pai_temp_2263_20384_2"
-DselectedCols="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
-DlabelCol="y"
-DcategoryCols="previous"
-Dlifecycle="28"-DmaxBins="5" ;參數名稱 | 是否必選 | 描述 | 默認值 |
inputTable | 是 | 輸入表的名稱。 | 無 |
inputTablePartitions | 否 | 輸入表中,參與訓練的分區。系統支持以下格式:
說明 指定多個分區時,分區之間使用英文逗號(,)分隔,例如name1=value1,value2。 | 無 |
outputTable | 是 | 輸出表名稱。 | 無 |
mapTable | 是 | 輸出映射表,數據視圖對String類字符串會做一個統計,映射成數字(轉換成Int方便機器學習識別和訓練) | 無 |
selectedCols | 是 | 輸入表選擇列名類型。 | 無 |
labelCol | 否 | 標簽列。 | 無 |
categoryCols | 否 | 把Int或者Double字段當做枚舉特征。 | 無 |
maxBins | 否 | 連續性特征等距離劃分最大區間數。 | 100 |
isSparse | 否 | 輸入數據是否為稀疏格式,取值范圍為{true,false}。 | false |
itemSpliter | 否 | 當輸入表數據為稀疏格式時,KV對之間的分隔符。 | 英文逗號(,) |
kvSpliter | 否 | 當輸入表數據為稀疏格式時,key和value之間的分隔符。 | 英文冒號(:) |
lifecycle | 否 | 表的生命周期。 | 28 |
coreNum | 否 | 計算的核心數,取值范圍為正整數。取值范圍[1, 9999]。 | 系統自動分配 |
memSizePerCore | 否 | 每個核心的內存,取值范圍為1 MB~65536 MB。 | 系統自動分配 |
示例
輸入數據
age
workclass
fwlght
edu
edu_num
married
c
family
race
sex
gail
loss
work_year
country
income
39
State-gov
77516
Bachelors
13
Never-married
Adm-clerical
Not-in-family
White
Male
2174.0
0.0
40.0
United-States
<=50K
50
Self-emp-not-inc
83311
Bachelors
13
Married-civ-spouse
Exec-managerial
Husband
White
Male
0.0
0.0
13.0
United-States
<=50K
38
Private
215646
HS-grad
9
Divorced
Handlers-cleaners
Not-in-family
White
Male
0.0
0.0
40.0
United-States
<=50K
53
Private
234721
11th
7
Married-civ-spouse
Handlers-cleaners
Husband
Black
Male
0.0
0.0
40.0
United-States
<=50K
28
Private
338409
Bachelors
13
Married-civ-spouse
Prof-specialty
Wife
Black
Female
0.0
0.0
40.0
Other
<=50K
37
Private
284582
Masters
14
Married-civ-spouse
Exec-managerial
Wife
White
Female
0.0
0.0
40.0
United-States
<=50K
49
Private
160187
9th
5
Married-spouse-absent
Other-service
Not-in-family
Black
Female
0.0
0.0
16.0
Jamaica
<=50K
52
Self-emp-not-inc
209642
HS-grad
9
Married-civ-spouse
Exec-managerial
Husband
White
Male
0.0
0.0
45.0
United-States
>50K
31
Private
45781
Masters
14
Never-married
Prof-specialty
Not-in-family
White
Female
14084.0
0.0
50.0
United-States
>50K
42
Private
159449
Bachelors
13
Married-civ-spouse
Exec-managerial
Husband
White
Male
5178.0
0.0
40.0
United-States
>50K
建模DAG
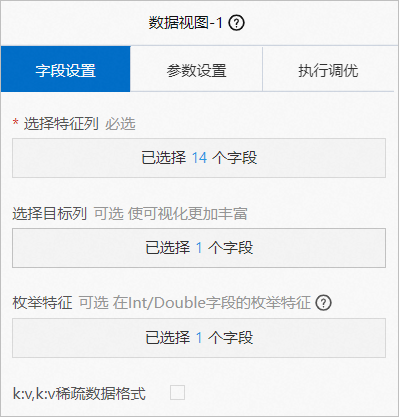
在數據視圖的字段設置頁簽,選擇income為目標列,其他14個字段為特征列,其中BIGINT類型的edu_num字段作為枚舉值處理。
建模效果
右鍵單擊數據視圖,選擇,為了方便數據被機器學習算法訓練,將STRING字段的family、race、sex及income等映射成數值(某種程度有數據格式轉換的功能)。
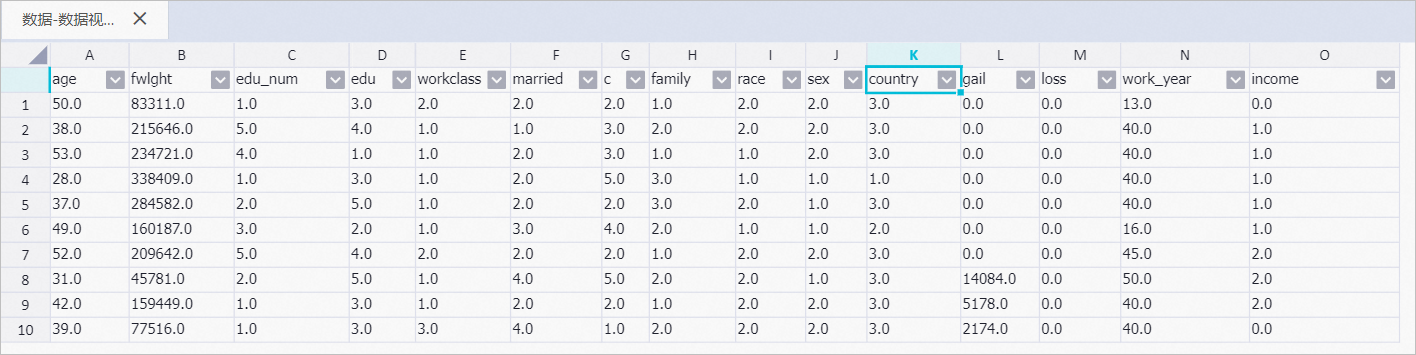
右鍵單擊數據視圖,選擇。
說明如果沒有選擇STRING類型的特征列,則輸出結果中String字段特征值映射表內容為空。
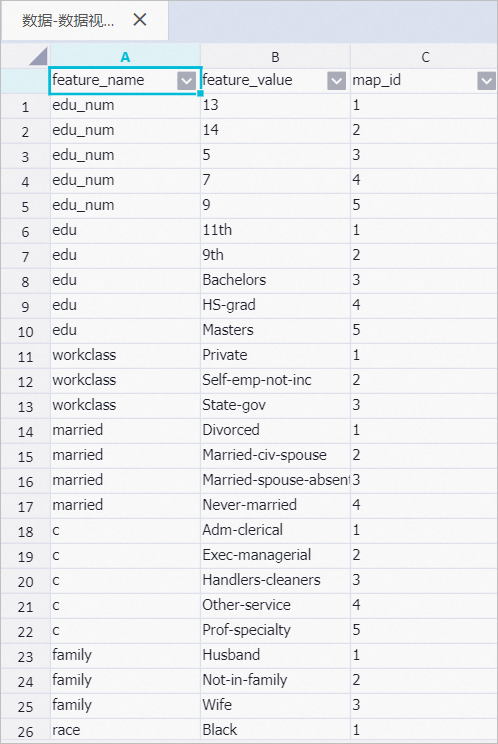
右鍵單擊數據視圖,選擇。
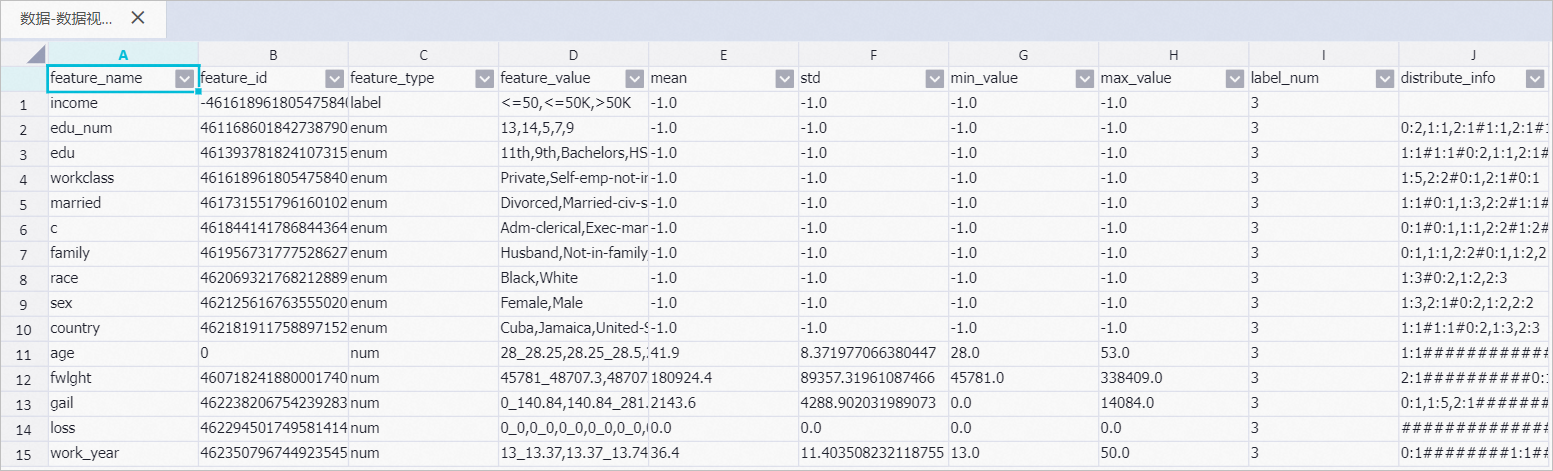 其中:distribute_info表示將最大值和最小值區間等距劃分,然后統計每個區間里的數據條數。
其中:distribute_info表示將最大值和最小值區間等距劃分,然后統計每個區間里的數據條數。