部署異步推理服務(wù)
在AIGC、視頻處理等復雜的模型推理場景中,由于推理耗時較長,存在長連接超時導致請求失敗或?qū)嵗撦d不均衡等問題,不適用于同步推理場景。為了解決這些問題,PAI提供了異步推理服務(wù),支持通過訂閱或輪詢的方式來獲取推理結(jié)果。本文為您介紹如何使用異步推理服務(wù)。
背景信息
功能介紹
異步推理
對于實時性要求比較高的在線推理場景,通常使用同步推理,即客戶端發(fā)送一個請求,同步等待結(jié)果返回。
對于推理耗時比較長或者推理時間無法確定的場景,同步等待結(jié)果會帶來HTTP長連接斷開、客戶端超時等諸多問題。通常需要使用異步推理來解決上述問題,即請求發(fā)送至服務(wù)端,客戶端不再同步等待結(jié)果,而是選擇定期去查詢結(jié)果,或通過訂閱的方式在請求計算完成后等待服務(wù)端的結(jié)果推送。
隊列服務(wù)
對于準實時推理場景,比如短視頻、視頻流或語音流的處理或計算復雜度很高的圖像處理等場景,不需要實時返回結(jié)果,但需要在指定時間內(nèi)獲取推理結(jié)果,該場景存在以下幾類問題:
負載均衡算法不能選擇round robin算法,需要根據(jù)各個實例的實際負載情況進行請求的分發(fā)。
實例異常,該實例尚未完成計算的任務(wù)需要重新分配給其他實例進行計算。
PAI推出了一套獨立的隊列服務(wù)框架,用來解決以上請求分發(fā)的問題。
實現(xiàn)原理

在創(chuàng)建異步推理服務(wù)時,會在服務(wù)內(nèi)部集成兩個子服務(wù),分別是推理子服務(wù)和隊列子服務(wù)。隊列子服務(wù)擁有兩個內(nèi)置的消息隊列,即輸入(input)隊列和輸出(sink)隊列。服務(wù)請求會先發(fā)送到隊列子服務(wù)的輸入隊列中,推理子服務(wù)實例中的EAS服務(wù)框架會自動訂閱隊列以流式地方式獲取請求數(shù)據(jù),調(diào)用推理子服務(wù)中的接口對收到的請求數(shù)據(jù)進行推理,并將響應結(jié)果寫入到輸出隊列中。
當輸出隊列滿時,即無法向輸出隊列中寫入數(shù)據(jù)時,服務(wù)框架也會停止從輸入隊列中接收數(shù)據(jù),避免無法將推理結(jié)果輸出到輸出隊列。
如果您不需要輸出隊列,例如將推理結(jié)果直接輸出到OSS或者您自己的消息中間件中,則可以在同步的HTTP推理接口中返回空,此時輸出隊列會被忽略。
創(chuàng)建一個高可用的隊列子服務(wù),用于接收客戶端發(fā)送的請求。推理子服務(wù)的實例根據(jù)自己所能承受的并發(fā)度來訂閱指定個數(shù)的請求,隊列子服務(wù)會保證每個推理子服務(wù)實例上處理的請求不會超過訂閱的窗口大小,通過該方式來保證不會存在實例過載,最終將訂閱或查詢的數(shù)據(jù)返回給客戶端。
說明比如每個推理子服務(wù)實例只能處理5路語音流,則從隊里子服務(wù)中訂閱消息時,將window size配置為5。當推理子服務(wù)實例處理完一路語音流后將結(jié)果commit,隊列子服務(wù)會為推理子服務(wù)實例重新推送一路新的語音流,保證該實例上處理的語音流最多不超過5路。
隊列子服務(wù)通過檢測推理子服務(wù)實例的連接狀態(tài),對其進行健康檢查,如果因該實例異常導致連接斷開,隊列子服務(wù)會將該實例標記為異常,已經(jīng)分發(fā)給該實例進行處理的請求會重新推送給其他正常實例進行處理,以此來保證在異常情況下請求數(shù)據(jù)不會丟失。
創(chuàng)建異步推理服務(wù)
在創(chuàng)建異步推理服務(wù)時,為了方便您的使用和理解,系統(tǒng)會自動創(chuàng)建和異步推理服務(wù)同名的服務(wù)群組。同時,隊列子服務(wù)會隨異步推理服務(wù)自動創(chuàng)建,并集成到異步推理服務(wù)內(nèi)。隊列子服務(wù)默認啟動1個實例,并根據(jù)推理子服務(wù)的實例數(shù)量動態(tài)伸縮,但最多不超過2個實例,每個實例默認配置為1核和4 GB內(nèi)存。如果隊列子服務(wù)的實例數(shù)的默認配置不能滿足您的需求,請參照隊列子服務(wù)參數(shù)配置及說明進行配置。
EAS的異步推理服務(wù)可以實現(xiàn)同步推理邏輯到異步推理的轉(zhuǎn)換,支持以下兩種部署方式:
通過控制臺部署服務(wù)
進入自定義部署頁面,并配置以下關(guān)鍵參數(shù),其他參數(shù)配置詳情,請參見服務(wù)部署:控制臺。
部署方式:選擇鏡像部署或processor部署。
異步服務(wù):選中異步服務(wù)。
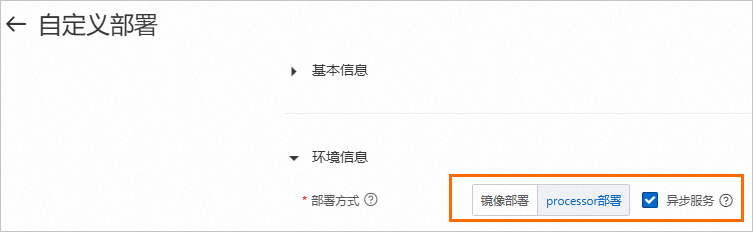
參數(shù)配置完成后,單擊部署。
通過eascmd客戶端部署服務(wù)
準備服務(wù)的配置文件service.json。
部署方式為模型+processor部署服務(wù)。
{ "processor": "pmml", "model_path": "http://example.oss-cn-shanghai.aliyuncs.com/models/lr.pmml", "metadata": { "name": "pmmlasync", "type": "Async", "cpu": 4, "instance": 1, "memory": 8000 } }其中關(guān)鍵參數(shù)說明如下。其他參數(shù)配置說明,請參見服務(wù)模型所有相關(guān)參數(shù)說明。
type:配置為Async,即可創(chuàng)建異步推理服務(wù)。
model_path:替換為您的模型的地址。
部署方式為鏡像部署服務(wù)。
{ "metadata": { "name": "image_async", "instance": 1, "rpc.worker_threads": 4, "type": "Async" }, "cloud": { "computing": { "instance_type": "ecs.gn6i-c16g1.4xlarge" } }, "queue": { "cpu": 1, "min_replica": 1, "memory": 4000, "resource": "" }, "containers": [ { "image": "eas-registry-vpc.cn-beijing.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.1", "script": "python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat", "port": 8000 } ] }其中關(guān)鍵參數(shù)說明如下。其他參數(shù)配置說明,請參見服務(wù)模型所有相關(guān)參數(shù)說明。
type:配置該參數(shù)為Async,即可創(chuàng)建異步推理服務(wù)。
instance:推理子服務(wù)的實例數(shù)量,不包含隊列子服務(wù)的實例。
rpc.worker_threads:為異步推理服務(wù)中EAS服務(wù)框架的線程數(shù),該參數(shù)與訂閱隊列數(shù)據(jù)的窗口大小一致。線程數(shù)設(shè)置為4,即一次最多只能從隊列中訂閱4條數(shù)據(jù),在這4條數(shù)據(jù)處理完成前,隊列子服務(wù)不會給推理子服務(wù)推送新數(shù)據(jù)。
例如:某視頻流處理服務(wù),單個推理子服務(wù)實例一次只能處理2條視頻流,則該參數(shù)可以設(shè)置為2,隊列子服務(wù)最多將2個視頻流的地址推送給推理子服務(wù),在推理子服務(wù)返回結(jié)果前,不會再推送新的視頻流地址。如果推理子服務(wù)完成了其中一個視頻流的處理并返回結(jié)果,則隊列子服務(wù)會繼續(xù)再推送一個新的視頻流地址給該推理子服務(wù)的實例,保證一個推理子服務(wù)的實例最多同時處理不超過2路視頻流。
創(chuàng)建服務(wù)。
您可以登錄eascmd客戶端后使用create命令創(chuàng)建異步推理服務(wù),如何登錄eascmd客戶端,請參見下載并認證客戶端,使用示例如下。
eascmd create service.json
訪問異步推理服務(wù)
如上文介紹,系統(tǒng)會默認為您創(chuàng)建和異步推理服務(wù)同名的服務(wù)群組,因群組內(nèi)的隊列子服務(wù)擁有群組流量入口,您可以直接通過下述路徑訪問隊列子服務(wù),詳情請參見訪問隊列服務(wù)。
地址類型 | 地址格式 | 示例 |
輸入隊列地址 |
|
|
輸出隊列地址 |
|
|
管理異步推理服務(wù)
您可以像管理普通服務(wù)一樣管理異步推理服務(wù),該服務(wù)的子服務(wù)會由系統(tǒng)自動管理。比如,當您刪除異步推理服務(wù)時,隊列子服務(wù)和推理子服務(wù)都將被同時刪除。或者當您更新推理子服務(wù)時,隊列子服務(wù)維持不變以獲取最大的可用性。
由于采用了子服務(wù)架構(gòu),雖然您為異步推理子服務(wù)配置了1個實例,實例列表中仍會額外顯示一個隊列子服務(wù)實例。

異步推理服務(wù)的實例數(shù)量指的是推理子服務(wù)實例的數(shù)量,隊列子服務(wù)的實例數(shù)量會隨著推理子服務(wù)的實例數(shù)量自動變化。比如,當您將推理子服務(wù)實例數(shù)量擴容到3時,隊列子服務(wù)的實例數(shù)量擴容到了2。
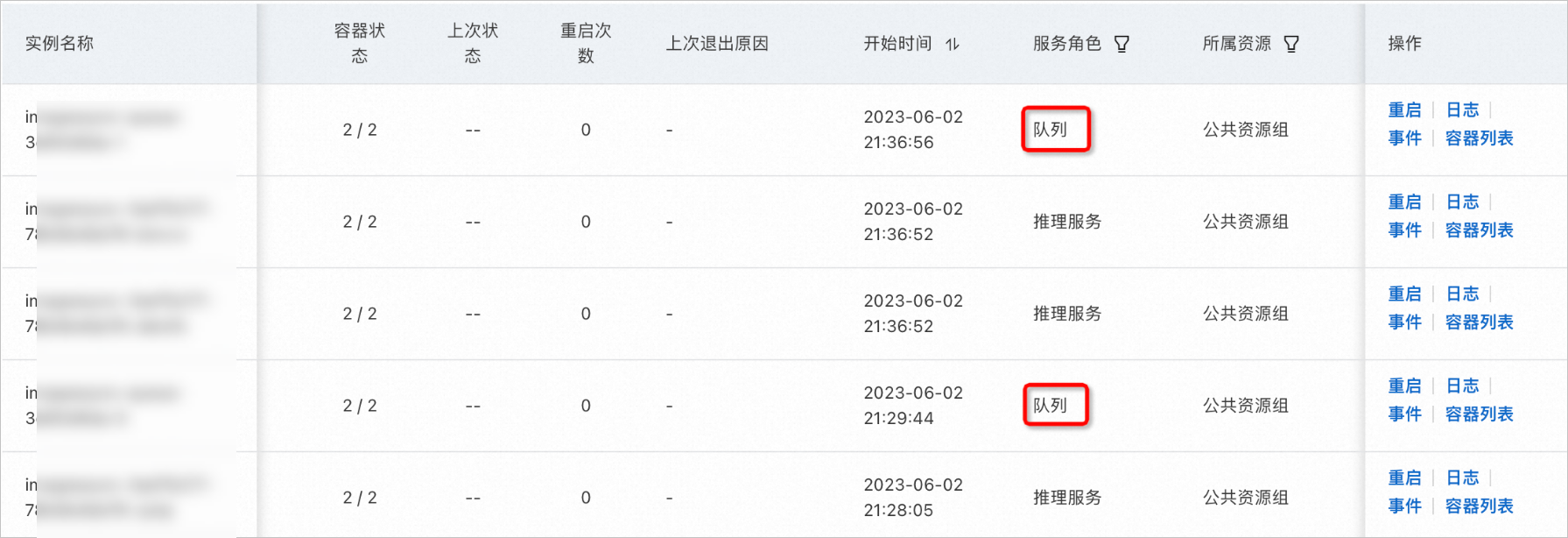
兩個子服務(wù)間的實例數(shù)量配比規(guī)則如下:
當異步推理服務(wù)被停止,則隊列子服務(wù)和推理子服務(wù)的實例數(shù)量均會縮容到0,這時看到的實例列表為空。
當推理子服務(wù)的實例數(shù)量為1時,隊列子服務(wù)的實例數(shù)量也將為1,除非您配置了隊列子服務(wù)的參數(shù)。
當推理子服務(wù)的實例數(shù)量超過2時,隊列子服務(wù)的實例數(shù)量將保持為2,除非您配置了隊列子服務(wù)的參數(shù)。
當您為異步推理服務(wù)配置了自動擴縮容功能,且配置了最小的實例數(shù)量為0,則當推理子服務(wù)縮容到0時,隊列子服務(wù)將保持1個實例待命。
隊列子服務(wù)參數(shù)配置及說明
大多數(shù)情況下,隊列子服務(wù)使用默認配置即可正常使用。如果有特殊需求,您可以通過在JSON文件中最外層的queue配置塊來配置隊列實例。示例如下:
{
"queue": {
"sink": {
"memory_ratio": 0.3
},
"source": {
"auto_evict": true,
}
}下面介紹具體的配置項。
配置隊列子服務(wù)資源
隊列子服務(wù)的資源會默認按照metadata中的字段進行配置,但是在有些使用場景下,您需要參考本章節(jié),對隊列子服務(wù)的資源進行單獨配置。
通過queue.resource聲明隊列子服務(wù)所使用的資源組。
{ "queue": { "resource": eas-r-slzkbq4tw0p6xd**** # 默認跟隨推理子服務(wù)資源組。 } }隊列子服務(wù)默認跟隨推理子服務(wù)的資源組。
當您需要使用公共資源組部署隊列子服務(wù)時,可以聲明resource為空字符串(""),這在您的專屬資源組CPU和內(nèi)存不充足時非常有用。
說明推薦使用公共資源組部署隊列子服務(wù)。
通過queue.cpu和queue.memory聲明每個隊列子服務(wù)實例所使用的CPU(單位:核數(shù))和內(nèi)存大小(單位:MB)。
{ "queue": { "cpu": 2, # 默認值為1。 "memory": 8000 # 默認值為4000。 } }如果您沒有進行資源配置,隊列子服務(wù)將按照1 CPU核、4 GB內(nèi)存進行默認配置。這可以滿足大多數(shù)場景的需求。
重要如果您的訂閱者(比如推理子服務(wù)實例的數(shù)量)數(shù)量超過200時,建議將CPU核數(shù)配置為2核以上。
不建議在生產(chǎn)環(huán)境中縮小隊列子服務(wù)的內(nèi)存配置。
通過queue.min_replica配置隊列子服務(wù)實例的最小數(shù)量。
{ "queue": { "min_replica": 3 # 默認為1。 } }在使用異步推理服務(wù)時,隊列子服務(wù)實例的數(shù)量將根據(jù)推理子服務(wù)實例的運行時數(shù)量自動調(diào)整,默認的調(diào)整區(qū)間為
[1, min{2, 推理子服務(wù)實例的數(shù)量}]。特殊情況下,如果配置異步推理服務(wù)的自動擴縮容規(guī)則并允許將實例數(shù)量縮小到0時,將自動保留1個隊列子服務(wù)實例。您也可以通過queue.min_replica調(diào)整最小保留的隊列子服務(wù)實例數(shù)量。說明增加隊列子服務(wù)實例的數(shù)量可以提高可用性,但不能提高隊列子服務(wù)的性能。
配置隊列子服務(wù)功能
隊列子服務(wù)擁有多項可配置的功能,您可以通過以下配置方法進行調(diào)整。
通過queue.sink.auto_evict或者queue.source.auto_evict分別配置輸出/輸入隊列自動數(shù)據(jù)驅(qū)逐功能。
{ "queue": { "sink": { "auto_evict": true # 輸出隊列打開自動驅(qū)逐,默認為false。 }, "source": { "auto_evict": true # 輸入隊列打開自動驅(qū)逐,默認為false。 } } }默認情況下隊列子服務(wù)的自動數(shù)據(jù)驅(qū)逐功能處于關(guān)閉狀態(tài),如果您的隊列已滿將無法繼續(xù)輸入數(shù)據(jù)。在某些場景下,如果您允許數(shù)據(jù)在隊列中溢出,可以選擇打開自動數(shù)據(jù)驅(qū)逐功能,隊列將自動驅(qū)逐最老的數(shù)據(jù)以允許新數(shù)據(jù)寫入。
通過queue.max_delivery配置最大投遞次數(shù)。
{ "queue": { "max_delivery": 10 # 最大投遞次數(shù)為10,默認值:5。當配置為0時,最大投遞次數(shù)關(guān)閉, 數(shù)據(jù)可以被無限次投遞。 } }當單條數(shù)據(jù)的嘗試投遞次數(shù)超過設(shè)定閾值時,該數(shù)據(jù)將被視為無法處理,并將其標記為死信。詳情請參見隊列實例的死信策略。
通過queue.max_idle配置數(shù)據(jù)的最大處理時間。
{ "queue": { "max_idle": "1m" # 配置單條數(shù)據(jù)最大處理時長為1分鐘,如果超過該時間將被投遞給其它訂閱者, 投遞完畢后投遞次數(shù)+1。默認值為0,即沒有最大處理時長。 } }示例中配置的時間長度為1分鐘,支持多種時間單位,如h(小時)、m(分鐘)、s(秒)。如果單條數(shù)據(jù)處理的時間超過了這里配置的時長,則有兩種可能:
如果未超過queue.max_delivery設(shè)定的閾值,該條數(shù)據(jù)會被投遞給其他訂閱者。
如果已超過queue.max_delivery設(shè)定的閾值,該條數(shù)據(jù)將會被執(zhí)行死信策略。
通過queue.dead_message_policy配置死信策略。
{ "queue": { "dead_message_policy": "Rear" # 枚舉值為Rear(默認值)或者Drop, Rear即為放入隊列末尾,Drop將該條數(shù)據(jù)刪除。 } }
配置隊列最大長度或最大數(shù)據(jù)體積
隊列子服務(wù)的最大長度和最大數(shù)據(jù)體積是此消彼長的關(guān)系,計算關(guān)系如下所示:

隊列子服務(wù)實例內(nèi)存是固定的,因此如果調(diào)整單條數(shù)據(jù)最大體積,則會導致該隊列最大長度減小。
在4 GB內(nèi)存的默認配置下,由于最大數(shù)據(jù)體積默認為8 KB,則輸入輸出隊列均可以存放230399條數(shù)據(jù),如果您需要在隊列子服務(wù)中存放更多數(shù)據(jù)項,可以參考上文中的內(nèi)存配置,將內(nèi)存大小按照需要提高。系統(tǒng)將占用總內(nèi)存的10%。
對于同一個隊列,不能同時配置最大長度和最大數(shù)據(jù)體積。
通過queue.sink.max_length或者queue.source.max_length分別配置輸出隊列/輸入隊列的最大長度。
{ "queue": { "sink": { "max_length": 8000 # 配置輸出隊列最大長度為8000條數(shù)據(jù)。 }, "source": { "max_length": 2000 # 配置輸入隊列最大長度為2000條數(shù)據(jù)。 } } }通過queue.sink.max_payload_size_kb或者queue.source.max_payload_size_kb分別配置輸出隊列/輸入隊列單條數(shù)據(jù)最大數(shù)據(jù)體積。
{ "queue": { "sink": { "max_payload_size_kb": 10 # 配置輸出隊列單條數(shù)據(jù)最大體積是10 KB, 默認8 kB。 }, "source": { "max_payload_size_kb": 1024 # 配置輸入隊列單條數(shù)據(jù)最大體積是1024 KB(1MB), 默認是8 kB。 } } }
配置內(nèi)存分配傾斜
通過queue.sink.memory_ratio來調(diào)整輸入輸出兩個隊列占用的內(nèi)存大小。
{ "queue": { "sink": { "memory_ratio": 0.9 # 配置輸出隊列內(nèi)存占比,默認值為0.5。 } } }說明默認配置下,輸入隊列和輸出隊列均分隊列子服務(wù)實例的內(nèi)存。如果您的服務(wù)需要輸入文本、輸出圖片,并期望在輸出隊列存放更多數(shù)據(jù),則可以將queue.sink.memory_ratio相應提高;相反,如果您期望輸入圖片、輸出文本,則可以將queue.sink.memory_ratio相應減小。
配置水平自動擴縮容
異步推理服務(wù)水平自動擴縮容配置方法,請參見自動擴縮容。