SimRank++相似度計(jì)算算法
本文介紹了推薦系統(tǒng)中一個(gè)常用的協(xié)同過(guò)濾算法SimRank,包括它的算法原理,及其應(yīng)用在個(gè)性化推薦場(chǎng)景時(shí)的改進(jìn)。同時(shí),本文還描述了如何在生產(chǎn)環(huán)境部署SimRank++算法。
算法簡(jiǎn)介
SimRank算法是一種用于衡量結(jié)構(gòu)上下文中個(gè)體相似度的方法,其基本思想是:如果兩個(gè)對(duì)象a和b分別與另外兩個(gè)對(duì)象c和d關(guān)聯(lián),且已知c與d是相似的,則a與b也是相似的;并且任意節(jié)點(diǎn)與其自身?yè)碛凶畲蟮南嗨贫戎禐?span id="z68uejxpaoma" class="help-letter-space">1。SimRank算法的主要出發(fā)點(diǎn)是利用已有個(gè)體的相似度來(lái)推算其他與之有關(guān)聯(lián)個(gè)體的相似度。
SimRank算法基于一個(gè)簡(jiǎn)單和直觀的圖論模型,它把對(duì)象和對(duì)象之間的關(guān)系建模為一個(gè)有向圖G = (V, E),其中V是有向圖的節(jié)點(diǎn)集合,代表應(yīng)用領(lǐng)域中的所有對(duì)象;E是有向圖的邊的集合,表示對(duì)象間的關(guān)系。對(duì)于圖中的一個(gè)節(jié)點(diǎn) ,與其所有入邊關(guān)聯(lián)的鄰節(jié)點(diǎn)集合(in-neighbors)記為
,與其所有入邊關(guān)聯(lián)的鄰節(jié)點(diǎn)集合(in-neighbors)記為 ,同時(shí),其出邊對(duì)應(yīng)的鄰節(jié)點(diǎn)集合(out-neighbors)集合記為
,同時(shí),其出邊對(duì)應(yīng)的鄰節(jié)點(diǎn)集合(out-neighbors)集合記為 。用
。用 表示對(duì)象
表示對(duì)象 和對(duì)象
和對(duì)象 之間的相似性,其計(jì)算公式為:
之間的相似性,其計(jì)算公式為:

從該計(jì)算公式可以看出,個(gè)體 ,
,  的相似度取決于所有與
的相似度取決于所有與 ,
,  相連節(jié)點(diǎn)的相似度。式中
相連節(jié)點(diǎn)的相似度。式中 是一個(gè)常量衰減因子。
是一個(gè)常量衰減因子。
上述公式可以用矩陣的形式表示出來(lái)。假設(shè)S表示有向圖G的SimRank分?jǐn)?shù)矩陣,其中 表示對(duì)象
表示對(duì)象 和
和 之間的相似性分?jǐn)?shù); P表示G的連接矩陣,其中
之間的相似性分?jǐn)?shù); P表示G的連接矩陣,其中 表示從頂點(diǎn)
表示從頂點(diǎn) 到頂點(diǎn)
到頂點(diǎn) 的邊數(shù),則
的邊數(shù),則

用矩陣的符號(hào)表示,即為:

其中,矩陣 表示按列歸一化的
表示按列歸一化的 矩陣,
矩陣,  是
是 的單位矩陣。
的單位矩陣。 的作用是把矩陣
的作用是把矩陣  的主對(duì)角線元素設(shè)為1。
的主對(duì)角線元素設(shè)為1。
SimRank++算法在SimRank算法的基礎(chǔ)上引入一個(gè)新的函數(shù) 表示二部圖中節(jié)點(diǎn)間的轉(zhuǎn)移概率:
表示二部圖中節(jié)點(diǎn)間的轉(zhuǎn)移概率:

從而,新的算法迭代公式如下:


其中, 和
和 表示任意兩個(gè)查詢(xún),
表示任意兩個(gè)查詢(xún), 和
和 表示任意兩個(gè)廣告,因子
表示任意兩個(gè)廣告,因子 和
和 的定義如下:
的定義如下:


對(duì)SimRank算法進(jìn)行上述兩個(gè)方面的擴(kuò)展,即通過(guò)“權(quán)值”和“證據(jù)值”對(duì)原始計(jì)算結(jié)果進(jìn)行校正,所得的新算法就是SimRank++算法。
SimRank++算法由Antonellis等人于2008年專(zhuān)門(mén)針對(duì)贊助商廣告檢索領(lǐng)域的查詢(xún)重寫(xiě)應(yīng)用提出的。
在推薦系統(tǒng)中的應(yīng)用
原始的SimRank++算法是在計(jì)算廣告領(lǐng)域做Query Rewrite的,一般會(huì)用最近一段時(shí)間的累計(jì)點(diǎn)擊行為數(shù)據(jù)來(lái)計(jì)算Query-Query、Ad-Ad之間的相關(guān)性。
由于Query所表達(dá)的查詢(xún)意圖短期內(nèi)能夠保持穩(wěn)定,所以用多天的行為數(shù)據(jù)來(lái)計(jì)算相似度是合理的。
在推薦系統(tǒng)中,沒(méi)有意圖明確的Query數(shù)據(jù),一般用User-Item的點(diǎn)擊或其他行為二部圖作為SimRank++算法的輸入。
在沒(méi)有Query相關(guān)性的限制下,用戶(hù)在推薦場(chǎng)景的行為意圖相對(duì)來(lái)說(shuō)不是很明確,同一用戶(hù)在同一時(shí)期可能會(huì)有多個(gè)興趣,并且用戶(hù)的興趣也會(huì)隨時(shí)間發(fā)生演化。
另一方面,用戶(hù)的量級(jí)通常比Query的量級(jí)大很多,從百萬(wàn)到數(shù)十億不等,這給SimRank++算法的實(shí)現(xiàn)帶來(lái)了不小的挑戰(zhàn)。
基于以上原因,我們推薦使用Session-Based的行為二部圖計(jì)算item-item的相似度。因?yàn)樵谕粋€(gè)session內(nèi)用戶(hù)的興趣點(diǎn)比較集中,一般不會(huì)分手到多個(gè)類(lèi)目的item上。在沒(méi)有明確session id埋點(diǎn)的場(chǎng)景,可以使用 concat(user_id, date) 作為session_id。
增量計(jì)算
由于session id的量級(jí)非常大,為了計(jì)算的可行性,不推薦合并多天的數(shù)據(jù)作為算法輸入。
由此帶來(lái)的覆蓋率問(wèn)題,我們提出了增量計(jì)算的方案。即SimRank++算法工具包會(huì)保留多天的item-item相似度數(shù)據(jù),計(jì)算第T天的相似度時(shí)使用T-1天的物品相似度初始化item-item相似度矩陣。工具包不會(huì)保留session與session之間的相似度數(shù)據(jù)。
最終,累加多天的物品相似度分?jǐn)?shù)作為最終的i2i相似度分  。
。

其中, 是一個(gè)折扣因子,即過(guò)去的相似度分累加到當(dāng)前時(shí)刻時(shí)需要打一個(gè)折扣,時(shí)間越久折扣越大。
是一個(gè)折扣因子,即過(guò)去的相似度分累加到當(dāng)前時(shí)刻時(shí)需要打一個(gè)折扣,時(shí)間越久折扣越大。
注意:我們不保證多天累加的相似度分?jǐn)?shù),如有需要請(qǐng)自行歸一化。
改進(jìn)點(diǎn)1:熱門(mén)打壓
在推薦場(chǎng)景很容易發(fā)生"哈利波特"效應(yīng),即因?yàn)闊衢T(mén)item會(huì)得到更多的曝光機(jī)會(huì),因而算法在不加干預(yù)時(shí)很可能認(rèn)為熱門(mén)item與很多其他item之間都存在相似關(guān)系,這樣會(huì)導(dǎo)致"富者越富"的馬太效應(yīng)。為了緩解這一問(wèn)題,本SimRank算法工具包引入了一個(gè)熱門(mén)打壓機(jī)制。
具體來(lái)說(shuō),我們首先從輸入的行為二部圖中匯總item對(duì)應(yīng)的邊的權(quán)重(求和),以便發(fā)現(xiàn)熱門(mén)的item。然后,對(duì)Item的熱度(記為  )做一個(gè)
)做一個(gè)z-score變換:

接著,再把  轉(zhuǎn)換為值域在(0, 1) 區(qū)間內(nèi)的一個(gè)單調(diào)遞減函數(shù):
轉(zhuǎn)換為值域在(0, 1) 區(qū)間內(nèi)的一個(gè)單調(diào)遞減函數(shù):

最后,用  乘上原來(lái)的邊的權(quán)重作為新的權(quán)重。這就相當(dāng)于在隨機(jī)游走時(shí)增加了往熱門(mén)item游走的阻力。
乘上原來(lái)的邊的權(quán)重作為新的權(quán)重。這就相當(dāng)于在隨機(jī)游走時(shí)增加了往熱門(mén)item游走的阻力。
改進(jìn)點(diǎn)2:Reweight by prefer category
推薦場(chǎng)景下用戶(hù)的點(diǎn)擊行為可能有噪聲,比如誤點(diǎn)的情況;為了消除噪聲的干擾,我們通過(guò)計(jì)算用戶(hù)對(duì)item類(lèi)目的偏好來(lái)調(diào)整行為二部圖的權(quán)重。
給定一個(gè)用戶(hù),其對(duì)類(lèi)目  的偏好分如下:
的偏好分如下:

Ta 對(duì)物品  的權(quán)重從原來(lái)的
的權(quán)重從原來(lái)的  調(diào)整為
調(diào)整為  ,其中物品
,其中物品  屬于類(lèi)目
屬于類(lèi)目  。
。
輸入輸出格式
輸入表(支持分區(qū)表)包含四列:
user_id: 用戶(hù)ID、session_id、Query等 (類(lèi)型不限)
item_id: 物品ID(類(lèi)型不限)
weight: double類(lèi)型的權(quán)重
category: [可選] item的類(lèi)目,設(shè)置該字段可提高精度(類(lèi)型不限)
輸入表中不可有重復(fù)的
<user_id, item_id>二元組,請(qǐng)預(yù)先合并權(quán)重當(dāng)使用category數(shù)據(jù)增強(qiáng)算法效果時(shí),該field為空值的記錄將會(huì)被刪除;注意檢查category列是否存在空值
注意:需要控制同一Query對(duì)應(yīng)的weight的方差在一定范圍內(nèi),太大會(huì)導(dǎo)致權(quán)重轉(zhuǎn)移矩陣的元素值為0,召回率嚴(yán)重下降。
建議為weight列提前做好歸一化或者標(biāo)準(zhǔn)化,比如施加 "min-max", "z-score", "log", "sigmoid"等變換。
也可以配置
input_weight_normalizer參數(shù)。
合理設(shè)置二部圖邊的權(quán)重,會(huì)顯著提升算法效果
用
ctr作為權(quán)重時(shí)容易引入噪聲數(shù)據(jù),因?yàn)?span id="z68uejxpaoma" class="help-letter-space">ctr高的record的曝光次數(shù)(pv)可能很低可以考慮用
log(1+click)作為邊的權(quán)重
建議做好數(shù)據(jù)清洗,過(guò)濾掉一些噪聲數(shù)據(jù)
給定一個(gè)Query,可以過(guò)濾掉
click/sum(click) < threshold的數(shù)據(jù);例如,threshold=3e-5
Item相似度(i2i)輸出表格式(支持分區(qū)列):
item1:物品ID
item2:相似物品ID
cumulative_score:多天數(shù)據(jù)計(jì)算出的累計(jì)相似度分?jǐn)?shù)(使用該字段作為最后的結(jié)果)
score: 當(dāng)天數(shù)據(jù)計(jì)算出的相似度分?jǐn)?shù),可能為空
備注:
Query相似度(q2q)輸出表格式(支持分區(qū)列):
query1:原始query
query2:相似query
score: 相似度分?jǐn)?shù)
提交任務(wù)
下載 simrank_plus_plus-1.0.jar 算法包。
作為資源上傳到MaxCompute項(xiàng)目空間。
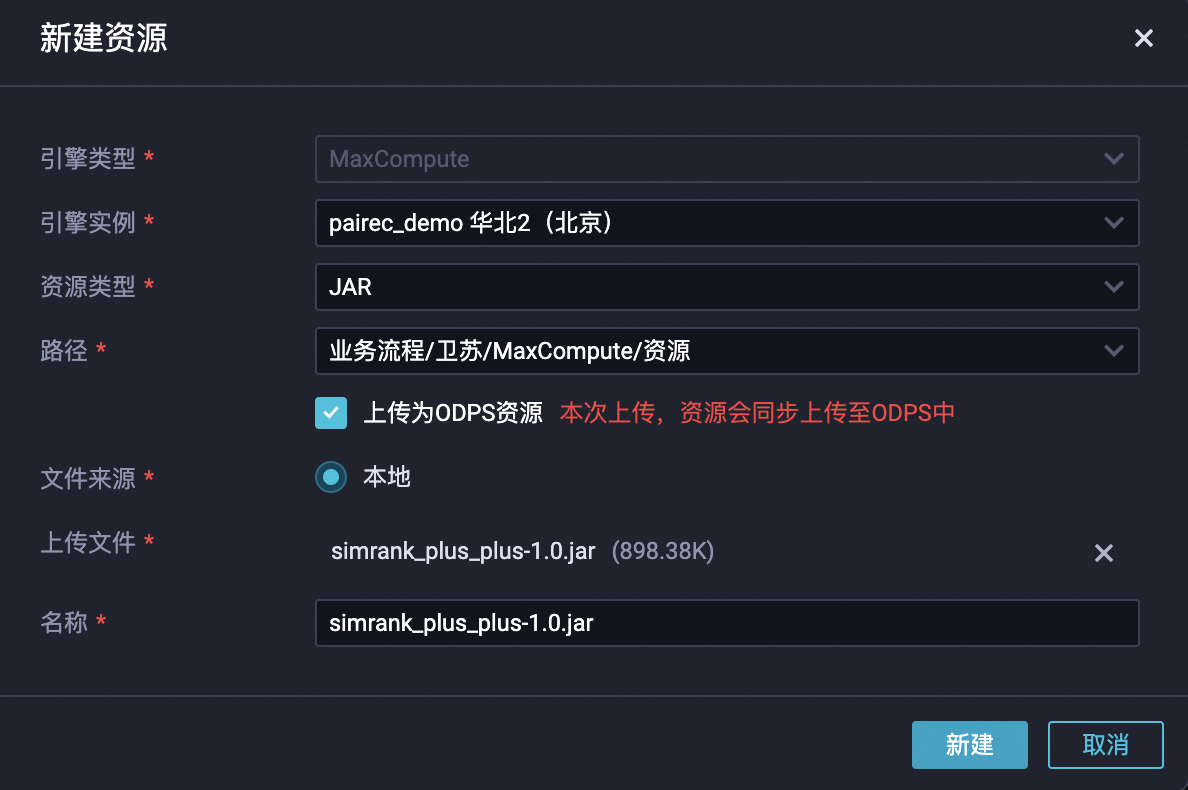
在DataWorks上新建 ODPS MR 節(jié)點(diǎn)(ODPS SQL類(lèi)型的節(jié)點(diǎn)可能會(huì)報(bào)錯(cuò)),使用如下命令提交Job。
--@resource_reference{"simrank_plus_plus-1.0.jar"} jar -resources simrank_plus_plus-1.0.jar -classpath simrank_plus_plus-1.0.jar com.aliyun.pai.simrank.SimRankDriver -project ${max_compute_project} -end_point http://service.cn-hangzhou.maxcompute.aliyun.com/api -access_id ${access_id} -access_key ${access_key} -input_table simrank_i2i_input -input_table_partition ds=${bizdate} -output_table simrank_i2i_output -output_table_partition ds=${bizdate} -init_partition ds=${yesterday} -session_column device_id -item_column item_id -category_column cate_lv3_id -num_matmul_reducer 2000 ;
參數(shù)說(shuō)明
參數(shù) | 類(lèi)型 | 說(shuō)明 | 默認(rèn)值 |
access_id | string | 阿里云賬號(hào)access_id | 無(wú) |
access_key | string | 阿里云賬號(hào)access_key | 無(wú) |
end_point | string | MaxCompute的服務(wù)地址. 公有云Endpoint | 無(wú) |
project | string | default odps project | 無(wú) |
input_table | string | 輸入table name | 無(wú) |
input_table_partition | string | 輸入table的partition | 無(wú) |
init_partition | string | item相似度輸出table的用于初始化的partition | 無(wú),一般使用前一天的 |
output_table | string | item相似度輸出table | 無(wú) |
output_table_partition | string | 輸出table的partition | 無(wú) |
session_output_table | string | query相似度輸出table | 無(wú) |
session_output_table_partition | string | query相似度輸出table的partition | 無(wú) |
session_column | string | 輸入table表示query的列名 | user_id |
item_column | string | 輸入table表示item的列名 | item_id |
category_column | string | 輸入table表示item的類(lèi)目的列名 | 無(wú) |
job_name | string | 任務(wù)名,中間表的前綴,設(shè)置該參數(shù)可以續(xù)跑中斷的任務(wù); 必須要保證和別人的任務(wù)不同名 | 自動(dòng)生成一串uuid |
debug | bool | 是否開(kāi)啟調(diào)試模式 | false |
iter_times | int | SimRank算法的迭代次數(shù) | 3 |
decay_factor | float | SimRank算法的衰減因子參數(shù)C, 范圍:(0, 1) | 0.8 |
discount_factor | float | 相似度分?jǐn)?shù)隨時(shí)間衰減因子, 范圍:(0, 1];僅用于增量計(jì)算 | 0.95 |
sim_threshold | float | SimRank算法迭代過(guò)程中使用的相似度過(guò)濾閾值 | 0.000001 |
weight_threshold | float | 行為二部圖邊的權(quán)重的過(guò)濾閾值 | 1e-6 |
input_weight_normalizer | string | 輸入權(quán)重的歸一化函數(shù),例如 | 無(wú) |
zero_spread_weight_cnt | int | 權(quán)重轉(zhuǎn)移矩陣score的零值報(bào)錯(cuò)閾值(零值表示input的weight方差過(guò)大) | 100 |
default_evidence | float | SimRank++算法使用的默認(rèn)證據(jù)權(quán)重,范圍:(0, 0.5) | 0.25 |
evidence_amplifier | float | 證件權(quán)重的放大因子,放大后的evidence范圍:[default_evidence, evidence_amplifier] | 1/decay_factor |
anti_popular | bool | 是否開(kāi)啟熱門(mén)物品打壓,解決"哈利波特效應(yīng)" | true |
item_block_size | int | Item矩陣分塊大小,性能相關(guān),不建議修改(輸入數(shù)據(jù)較小是不會(huì)觸發(fā)矩陣分塊) | 50000 |
session_block_size | int | Query矩陣分塊大小,性能相關(guān),不建議修改(輸入數(shù)據(jù)較小是不會(huì)觸發(fā)矩陣分塊) | 50000 |
matmul_strategy | int | 矩陣分塊乘法策略,可選值:2、3、4(輸入數(shù)據(jù)較小時(shí)不會(huì)觸發(fā)矩陣分塊) | 4 |
matmul_reducer_memory | int | 矩陣乘法Job1的Reducer內(nèi)存,單位為M | 觸發(fā)分塊:12288;不觸發(fā)分塊:3072 |
matmul_split_size | int | 矩陣乘法Mapper的切片大小,單位為M | 觸發(fā)分塊:16;不觸發(fā)分塊:256 |
num_matmul_reducer | int | 矩陣乘法Job1的Reducer數(shù)量 | 觸發(fā)分塊:自動(dòng)計(jì)算;不觸發(fā)分塊:無(wú) |
num_matmul_reducer2 | int | 矩陣乘法Job2的Reducer數(shù)量(不觸發(fā)分塊時(shí)不需要Reducer2) | 無(wú) |
evidence_split_size | int | 計(jì)算證據(jù)矩陣Mapper的切片大小,單位為M | 16 |
num_evidence_reducer1 | int | 計(jì)算證據(jù)矩陣Job1的Reducer數(shù)量 | 無(wú) |
num_evidence_reducer2 | int | 計(jì)算證據(jù)矩陣Job2的Reducer數(shù)量 | 無(wú) |
priority | int | Job優(yōu)先級(jí) | 1 |
搜索場(chǎng)景,如Query Rewrite,可以把anti_popular置為false;推薦場(chǎng)景則置為true。
案例分析
某搜索場(chǎng)景,輸入數(shù)據(jù)約1700萬(wàn),query量級(jí)為120萬(wàn),item量級(jí)為150萬(wàn),使用如下參數(shù)跑通整個(gè)流程耗時(shí)約87分鐘。
--@resource_reference{"simrank_plus_plus-1.0.jar"}
jar -resources simrank_plus_plus-1.0.jar
-classpath simrank_plus_plus-1.0.jar
com.aliyun.pai.simrank.SimRankDriver
-project ${project}
-end_point http://service.cn-shanghai.maxcompute.aliyun.com/api
-access_id ${access_id}
-access_key ${access_key}
-input_table ${input_table}
-input_table_partition dt=20240512
-output_table simrank_i2i_score
-output_table_partition dt=20240512
-session_output_table simrank_q2q_score
-session_output_table_partition dt=20240512
-output_table_lifecycle 7
-session_column query_word
-item_column item_id
-category_column category
-anti_popular false
-num_matmul_reducer 2000
-num_evidence_reducer1 1000
-num_evidence_reducer2 200