相對于傳統應用程序,開發云端應用雖然降低了用戶在基礎設施搭建、運維等方面的成本,但卻增大了監控、診斷和故障排查的難度。OSS存儲服務為您提供了豐富的監控和日志信息,幫助您深刻洞察程序行為,及時發現并快速定位問題。
本文主要描述如何使用OSS監控服務、日志記錄功能以及其他第三方工具來監控、診斷和排查應用業務使用OSS存儲服務時遇到的相關問題,幫助您達到如下目標:
實時監控OSS存儲服務的運行狀況和性能,并及時報警通知。
獲取有效的方法和工具來定位問題。
根據相關問題的處理和操作指南,快速解決與OSS相關的問題。
本文包括如下內容:
服務監控
監視總體運行狀況
可用性和有效請求率
可用性和有效請求率是有關系統穩定性和用戶是否正確使用系統的最重要指標,指標小于100%說明某些請求失敗。
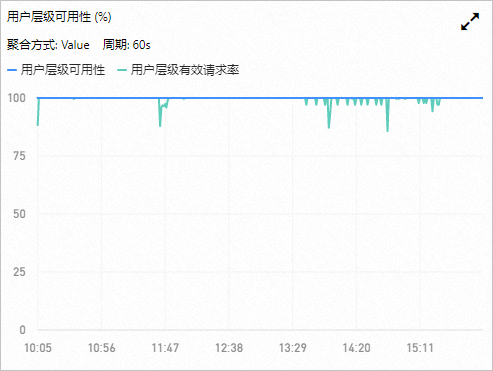
可能因為一些系統優化因素出現暫時性的低于100%,例如為了負載均衡而出現分區遷移,此時OSS的SDK能夠提供相關的重試機制無縫處理這類間歇性的失敗情況,使得業務端無感知。
對于有效請求率低于100%的情況,您需要根據自己的使用情況進行分析,可以通過請求分布統計或者請求狀態詳情確定錯誤請求的具體類型、原因,并排除故障。
對于某些業務場景,出現有效請求率低于100%是符合預期的。例如,用戶需要先檢查訪問的Object是否存在,然后根據Object的存在性采取一定的操作,如果Object不存在,檢測Object存在性的讀取請求會收到404錯誤(資源不存在錯誤),導致該指標項低于100%。
對于系統可用性指標要求較高的業務,可以對其設置報警規則,當低于預期閾值時,進行報警。
總請求數和有效請求數
該指標從總訪問量角度來反應系統運行狀態,當有效請求數不等于總請求數時表明某些請求失敗。
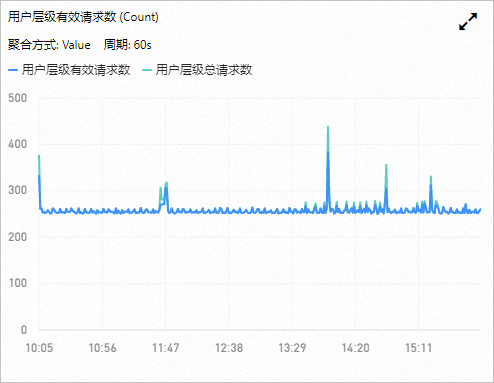
您可以關注總請求數或者有效請求數的波動狀況,特別是突然上升或者下降的情況,需要進行跟進調查,可以通過設置報警規則進行及時通知。具體操作,請參見報警服務使用指南。
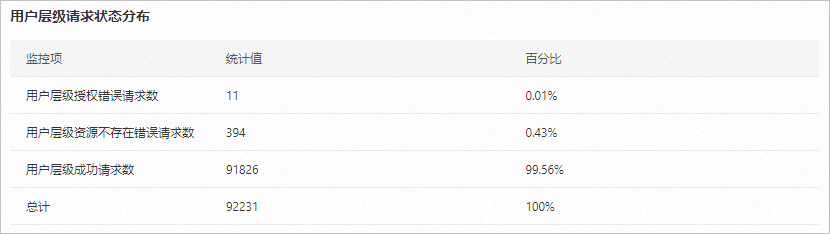
請求狀態分布統計
當可用性或者有效請求率低于100%(或者有效請求數不等于總請求數時),可以通過查看請求狀態分布統計快速確定請求的錯誤類型。有關該統計監控指標的更多信息,請參見OSS監控指標參考手冊。
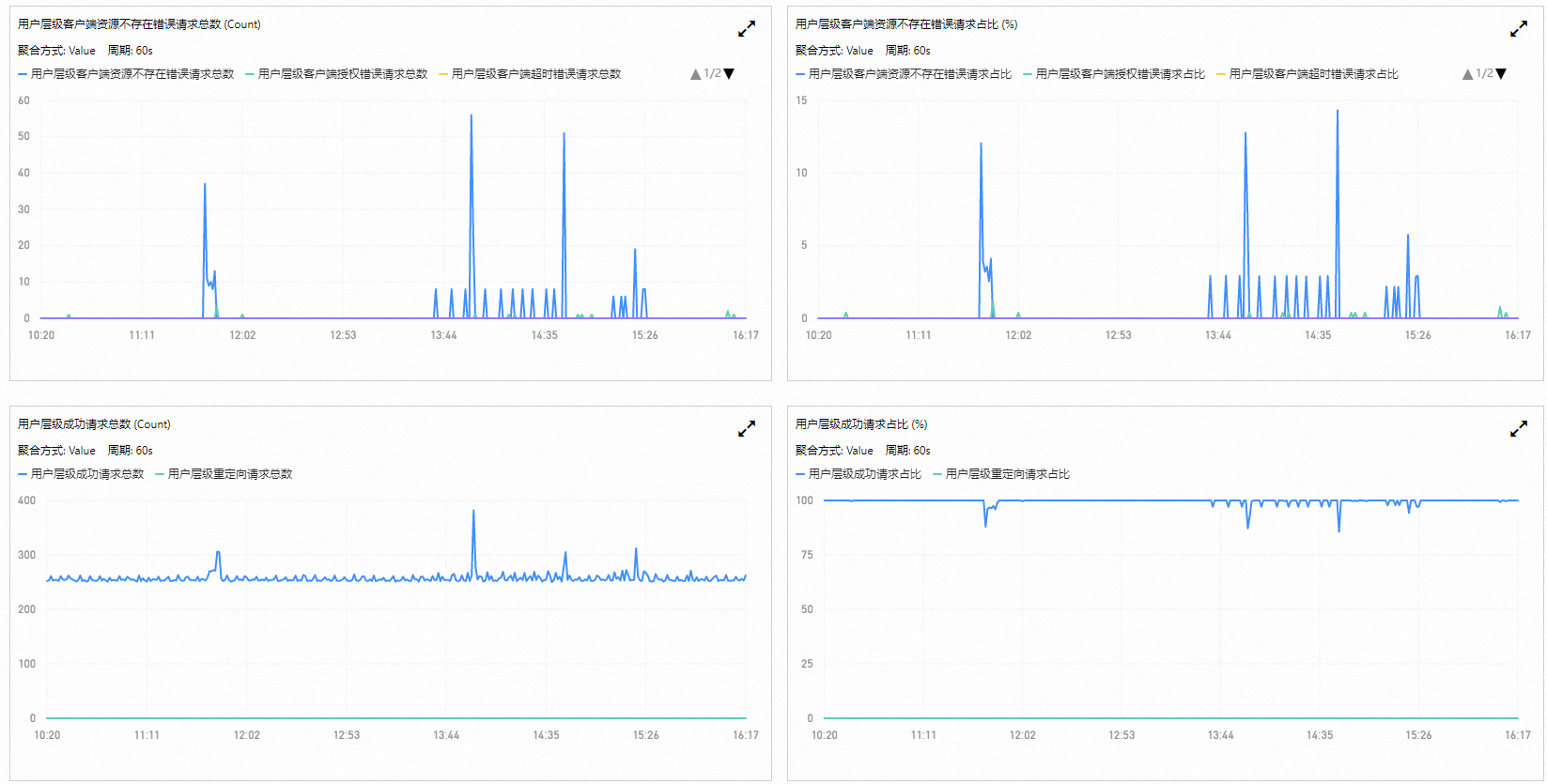
監視請求狀態詳情
請求狀態詳情是在請求狀態分布統計的基礎上進一步細化請求監控狀態,可以更加深入、具體地監視某類請求。
監視性能
監控服務提供了以下監控項來監控性能相關的指標:
平均延時,包括E2E平均延時和服務器平均延時
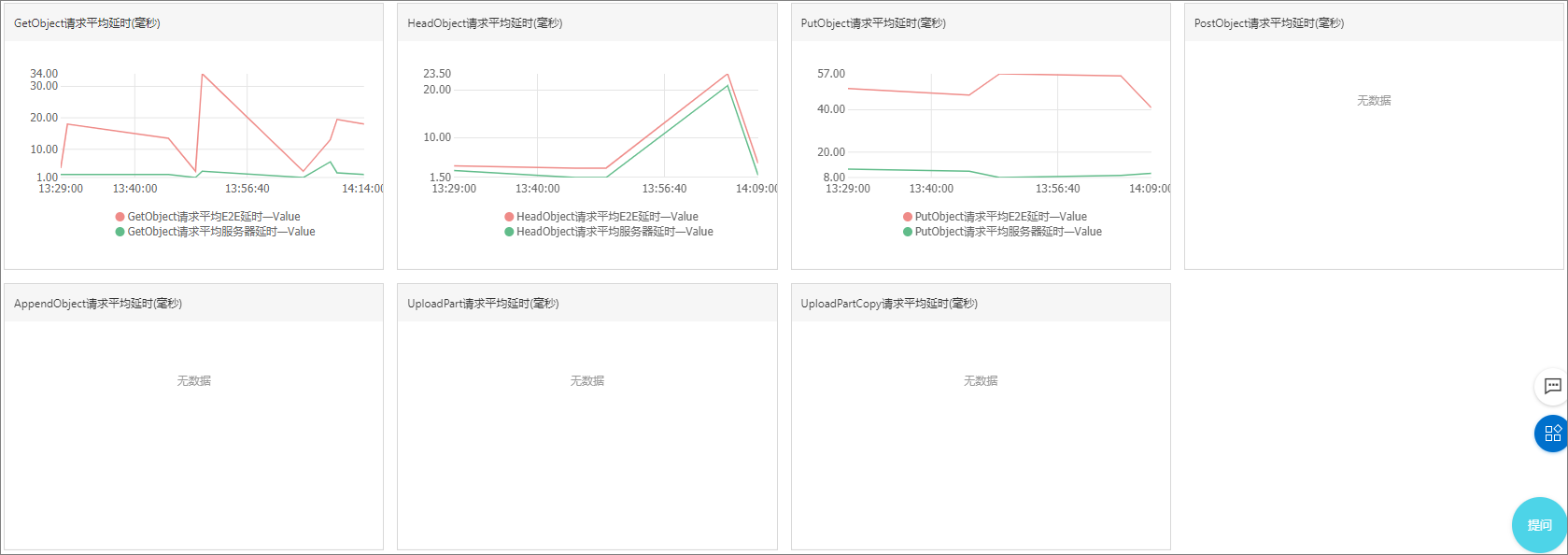
延時指標顯示API操作類型處理請求所需的平均和最大時間。其中E2E延時是端到端延遲指標,除了包括處理請求所需的時間外,還包括讀取請求和發送響應所需的時間以及請求在網絡上傳輸的延時;而服務器延時只是請求在服務器端被處理的時間,不包括與客戶端通信的網絡延時。所以當出現E2E延時突然升高的情況下,如果服務器延時并沒有很大的變化,那么可以判定是網絡的不穩定因素造成的性能問題,排除OSS系統內部故障。
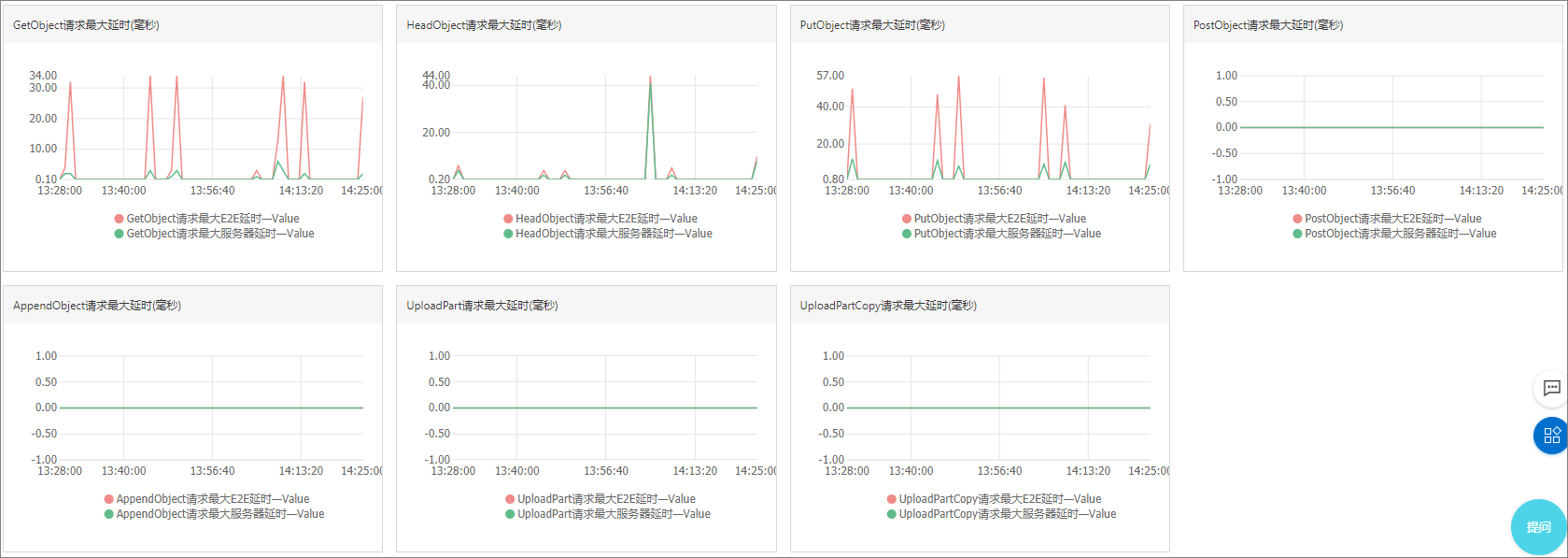
最大延時,包括E2E最大延時和服務器最大延時
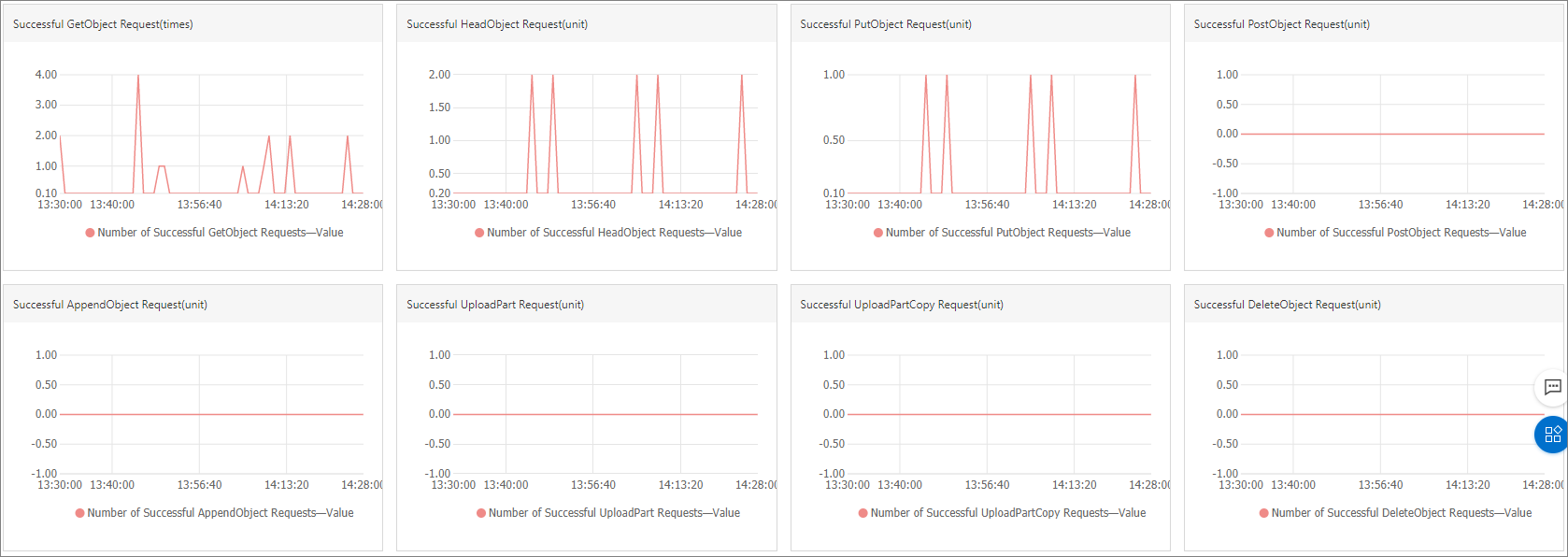
成功請求操作分類
流量
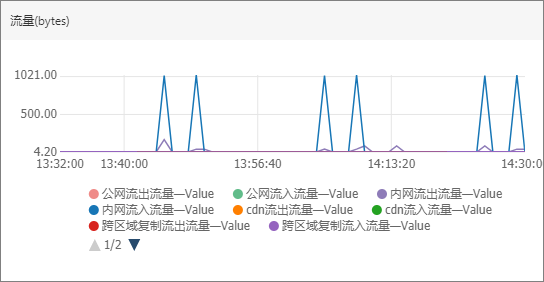
流量指標從用戶或者具體的Bucket層級的總體情況進行監控,關注公網、內網、CDN回源以及跨域復制等場景中的網絡資源占用狀況。
以上各個監控項(除流量)都分別從API操作類型進行分類監控,包括:
GetObject
HeadObject
PutObject
PostObject
AppendObject
UploadPart
UploadPartCopy
成功請求操作分類除了以上提到的API之外,還提供以下兩個API操作類型請求數量的監控:
DeleteObject
DeleteObjects
對于性能類指標項,您需要重點關注其突發的異常變化。例如,平均延時突然出現尖峰,或者長時間處于高出正常請求延時的基線上方等。您可以通過對性能指標設置對應的報警規則,當指標低于或者超過閾值時及時通知到相關人員。
監視計量
目前,OSS監控服務只支持監控存儲空間大小、公網流出流量、Put類請求數和Get類請求數(不包括跨區域復制流出流量和CDN流出流量),不支持對計量數據的報警設置和OpenAPI的讀取。
OSS監控服務對Bucket層級的計量監控數據進行小時級別的粒度采集,可以在具體的Bucket監控視圖中查看其持續的監控趨勢圖。您可以根據監控視圖分析其業務的存儲服務資源使用趨勢并且進行成本的預估等。

OSS監控服務還提供了用戶層級和Bucket層級兩個不同維度的當月消費的資源數統計。即統計阿里云賬戶或者某個Bucket當月消耗的OSS資源總量,每小時更新一次,幫助您了解本月資源的使用情況并計算消費。
有關OSS的計費項和計費方式的更多信息,請參見計量項和計費項。
說明監控服務中提供的計量數據是盡最大可能推送的,可能會與實際消費賬單不一致,請以費用中心的數據為準。
跟蹤診斷
問題診斷
診斷性能
對于應用程序的性能判斷多帶有主觀因素,您需要根據具體的業務場景確定滿足業務需求的基準線,來判定性能問題。另外,從客戶端發起的請求,能引起性能問題的因素貫穿整個請求鏈路。例如OSS存儲服務負載過大、客戶端TCP配置問題或網絡基礎結構中存在的流量瓶頸等。
因此診斷性能問題首先需要設置合理的基準線,然后通過監控服務提供的性能指標確定性能問題可能的根源位置,然后根據日志查到詳細的信息以便進一步診斷并且排除故障。
診斷錯誤
客戶端應用程序會在請求發生錯誤時接收到服務端返回的相關錯誤信息,監控服務也會記錄并顯示各種錯誤類型請求的計數和占比。您也可以通過檢查服務器端日志、客戶端日志和網絡日志來獲取相關單個請求的詳細信息。通常,響應中返回的HTTP狀態代碼和OSS錯誤碼以及OSS錯誤信息都指示請求失敗的原因。
有關錯誤響應的更多信息,請參見 OSS錯誤響應。
使用日志功能
OSS存儲服務為用戶的請求提供服務端日志記錄功能,能幫助用戶記錄端到端的詳細請求日志跟蹤。
有關如何開啟并使用日志功能,請參見設置日志。
有關日志服務的命名規則以及記錄格式的更多信息,請參見設置訪問日志記錄。
使用網絡日志記錄工具
在大多數情況下,通過日志服務記錄的存儲日志和客戶端應用程序的日志數據已足以診斷問題,但在某些情況下,可能需要更詳細的信息,這時需要使用網絡日志記錄工具捕獲客戶端和服務器之間的流量,可以更詳細地獲取客戶端和服務器之間交換的數據以及底層網絡狀況的詳細信息,幫助問題的調查。例如,在某些情況下,用戶請求可能會報告一個錯誤,而服務器端日志中卻看不到任何該請求的訪問情況,這時就可以使用OSS的日志服務功能記錄的日志來調查該問題的原因是否出在客戶端上,或者使用網絡監視工具來調查網絡問題。
最常用的網絡日志分析工具之一是Wireshark。該免費的協議分析器運行在數據包級別,能夠查看各種網絡協議的詳細數據包信息,從而可以排查丟失的數據包和連接問題。
有關如何安裝WireShark的具體步驟,請參見WireShark安裝使用。
有關如何使用WireShark的詳情,請參見WireShark用戶指南。
E2E跟蹤診斷
請求從客戶端應用進程發起,通過網絡環境,進入OSS服務端被處理,然后響應從服務端回到網絡環境,被客戶端接收。整個過程,是一個端到端的跟蹤過程。關聯客戶端應用程序日志、網絡跟蹤日志和服務端日志,有助于排查問題的詳細信息根源,發現潛在的問題。
在OSS存儲服務中,提供了RequestID作為關聯各處日志信息的標識符。另外,通過日志的時間戳,不僅可以迅速查找和定位日志范圍,還能夠了解在請求發生時間點范圍內,客戶端應用、網絡或者服務系統發生的其他事件,有利于問題的分析和調查。
RequestID
OSS服務會為接收的每個請求分配唯一的服務器請求ID,即RequestID。在不同的日志中,RequestID位于不同的字段中:
在OSS日志功能記錄的服務端日志記錄中,RequestID出現在“Request ID”列中。
在網絡跟蹤(如WireShark捕獲的數據流)中,RequestID作為x-oss-request-id標頭值出現在響應消息中。
在客戶端應用中,需要客戶端code實現的時候將請求的RequestID自行打印到客戶端日志中。最新版本的Java SDK已經支持打印正常請求的RequestID信息,可以通過各個API接口返回的Result結果的getRequestId這個方法獲取。OSS的各個版本SDK都支持打印出異常請求的RequestID,可以通過調用OSSException的getRequestId方法獲取。
時間戳
使用時間戳來查找相關日志項,需要注意客戶端和服務器之間可能存在的時間偏差。在客戶端上基于時間戳搜索日志功能記錄的服務器端日志條目時,應加上或減去15分鐘。
故障排除
性能相關常見問題
平均E2E延時高,而平均服務端延時低
前面介紹了平均E2E延時與平均服務器延時的區別。所以產生高E2E延時、低服務器延時可能的原因有兩個:
客戶端應用程序響應慢
可用連接數或可用線程數有限
對于可用連接數問題,可以使用相關命令確定系統是否存在大量TIME_WAIT狀態的連接。如果是,可以通過調整內核參數解決。
對于可用線程數有限,可以先查看客戶端CPU、內存、網絡等資源是否已經存在瓶頸,如果沒有,適當調大并發線程數。
如果還不能解決問題,那么就需要通過優化客戶端代碼。例如,使用異步訪問方式等。也可以使用性能分析功能分析客戶端應用程序熱點,然后具體優化。
CPU、內存或網絡帶寬等資源不足
對于這類問題,需要先使用相關系統的資源監控查看客戶端具體的資源瓶頸在哪里,然后通過優化代碼使其對資源的使用更為合理,或者擴容客戶端資源(使用更多的內核或者內存)。
網絡原因導致
通常,因網絡導致的端到端高延遲是由暫時狀況導致的。可以使用Wireshark調查臨時和持久網絡問題,例如數據包丟失問題。
平均E2E延時低,平均服務端延時低,但客戶端請求延時高
客戶端出現請求延時高的情況,最可能的原因是請求還未達到服務端就出現了延時。所以應該調查來自客戶端的請求為什么未到達服務器。
對于客戶端延遲發送請求,可能的客戶端的原因有兩個:
可用連接數或可用線程數有限
對于可用連接數問題,可以使用相關命令確定系統是否存在大量TIME_WAIT狀態的連接。如果是,可以通過調整內核參數解決。
對于可用線程數有限,可以先查看客戶端CPU、內存、網絡等資源是否已經存在瓶頸,如果沒有,適當調大并發線程數。
如果還不能解決問題,那么就需要通過優化客戶端代碼。例如,使用異步訪問方式等。也可以使用性能分析功能分析客戶端應用程序熱點,然后具體優化。
客戶端請求出現多次重試,如果遇到這種情況,需要根據重試信息具體調查重試的原因再解決。可以通過下面方式確定客戶端是否出現重試:
檢查客戶端日志,詳細日志記錄會指示重試已發生過。以OSS的Java SDK為例,可以搜索如下日志提示,warn或者info的級別。如果存在該日志,說明可能出現了重試。
[Server]Unable to execute HTTP request: 或者 [Client]Unable to execute HTTP request:如果客戶端的日志級別為debug,以OSS的Java SDK為例,可以搜索如下日志,如果存在,那么肯定出現過重試。
Retrying on
如果客戶端沒有問題,則應調查潛在的網絡問題,例如數據包丟失。可以使用工具(如Wireshark )調查網絡問題。
平均服務端延時高
對于下載或者上傳出現服務端高延時的情況,可能的原因有2個:
大量客戶端頻繁訪問同一個小Object
這種情況,可以通過查看日志功能記錄的服務端日志信息來確定是否在一段時間內,某個或某組Object被頻繁訪問。
對于下載場景,建議用戶為該Bucket開通CDN服務,利用CDN來提升性能,并且可以節約流量費用;對于上傳場景,用戶可以考慮在不影響業務需求的情況下,收回Object或Bucket的寫訪問權限。
系統內部因素
對于系統內部問題或者不能通過優化方式解決的問題,請提供客戶端日志或者日志功能記錄的日志信息中的RequestID,聯系售后技術人員協助解決。
服務端錯誤問題
對于服務端錯誤的增加,可以分為兩個場景考慮:
暫時性的增加
對于這一類問題,您需要調整客戶端程序中的重試策略,采用合理的退讓機制,例如指數退避。這樣不僅可以有效避免因為優化或者升級等系統操作(如為了系統負載均衡進行分區遷移等)暫時導致的服務不可用問題,還可以避開業務峰值的壓力。
永久性的增加
如果服務端錯誤持續在一個較高的水平,那么請提供客戶端日志或者日志功能記錄的RequestID,聯系售后技術人員協助調查。
網絡錯誤問題
網絡錯誤是指服務端正在處理請求時,連接在非服務器端斷開而來不及返回HTTP請求頭的情況。此時系統會記錄該請求的HTTP狀態碼為499。以下幾種情況會導致服務器記錄請求的狀態碼變為499:
服務器在收到讀寫請求處理之前,會檢查連接是否可用,不可用則為499。
服務器正在處理請求時,客戶端提前關閉了連接,此時請求被記錄為499。
在請求過程中,客戶端主動關閉請求或者客戶端網絡斷掉都會產生網絡錯誤。對于客戶端主動關閉請求的情況,需要調查客戶端中的代碼,了解客戶端斷開與存儲服務連接的原因和時間。對于客戶端網絡斷掉的情況,用戶可以使用工具(如Wireshark)調查網絡連接問題。
客戶端錯誤問題
客戶端授權錯誤請求增加
當監控中的客戶端授權錯誤請求數增加,或者客戶端程序接收到大量的403請求錯誤,那么最常見的可能原因有以下幾個:
用戶訪問的Bucket域名不正確
如果用戶直接用三級域名或者二級域名訪問,那么可能的原因就是用戶的Bucket并不屬于該域名所指示的region內,例如,用戶創建的Bucket的地域為杭州,但是訪問的域名卻為Bucket.oss-cn-shanghai.aliyuncs.com。這時需要確認Bucket的所屬區域,然后更正域名信息。
如果用戶開啟了CDN加速服務,那么可能的原因是CDN綁定的回源域名錯了,請檢查CDN回源域名是否為用戶Bucket的三級域名。
如果用戶使用JavaScript客戶端遇到403錯誤,可能的原因就是CORS(跨域資源共享)的設置問題,因為Web瀏覽器實施了“同源策略”的安全限制。用戶需要先檢查所屬Bucket的CORS設置是否正確,并進行相應的更正。有關設置CORS的具體步驟,請參見跨域資源共享。
訪問控制問題
用戶使用主AK訪問,那么用戶需要檢查是否AK設置出錯,使用了無效AK。
用戶使用RAM子賬號訪問,那么用戶需要確定RAM子賬號是否使用了正確的子AK,或者對應子賬號的相關操作是否已經授權。
用戶使用STS臨時Token訪問,那么用戶需要確認一下這個臨時Token是否已經過期。如果過期,需要重新申請。
如果Bucket或者Object設置了訪問控制,這個時候需要查看用戶所訪問的Bucket或者Object是否支持相關的操作。
URL過期
授權第三方下載,即用戶使用簽名URL進行OSS資源訪問,如果之前訪問正常而突然遇到403錯誤,最大可能的原因是URL已經過期。
RAM子賬號使用OSS周邊工具的情況也會出現403錯誤。這類周邊工具如ossftp、ossbrowser、OSS控制臺客戶端等,在填寫相關的AK信息登入時就拋出錯誤,此時如果您的AK是正確填寫的,那么您需要查看使用的AK是否為子賬號AK,該子賬號是否有GetService等操作的授權等。
客戶端資源不存在錯誤請求增加
客戶端收到404錯誤說明用戶試圖訪問不存在的資源信息。當看到監控服務上資源不存在錯誤請求增加,那么最大可能是以下問題導致的:
用戶的業務使用方式。例如用戶需要先檢查Object是否存在來進行下一步動作,可以調用doesObjectExist(以JAVA SDK為例)方法,如果Object不存在,在客戶端則收到false值,但是這時在服務器端實際上會產生一個404的請求信息。所以,這種業務場景下,出現404是正常的業務行為。
客戶端或其他進程以前刪除了該對象。這種情況可以通過搜索logging功能記錄的服務端日志信息中的相關對象操作即可確認。
網絡故障引起丟包重試。例如客戶端發起一個刪除操作刪除某個Object,此時請求達到服務端,執行刪除成功,但是響應在網絡環境中丟包,然后客戶端發起重試,第二次的刪除操作可能就會遇到404錯誤。這種由于網絡問題引起的404錯誤可以通過客戶端日志和服務端日志確定:
查看客戶端應用日志是否出現重試請求。
查看服務端日志是否對該Object有兩次刪除操作,前一次的刪除操作HTTP Status為2xx。
有效請求率低且客戶端其他錯誤請求數高
有效請求率為請求返回的HTTP狀態碼為2xx/3xx的請求數占總請求的比例。狀態碼為4XX和5XX范圍內的請求將計為失敗并降低該比例。客戶端其他錯誤請求是指除服務端錯誤請求(5xx)、網絡錯誤請求(499)、客戶端授權錯誤請求(403)、客戶端資源不存在錯誤請求(404)和客戶端超時錯誤請求(408或者OSS錯誤碼為RequestTimeout的400請求)這些錯誤請求之外的請求。
您可以通過查看日志功能記錄的服務端日志確定這些錯誤的具體類型,之后根據OSS錯誤響應碼在客戶端代碼中查找具體原因進行解決。詳情請參見OSS錯誤響應。
存儲容量異常增加
存儲容量異常增加,如果不是上傳類請求量增多,常見的原因應該是清理操作出現了問題,可以根據下面兩個方面進行調查:
客戶端應用使用特定的進程定期清理來釋放空間。針對這種請求的調查步驟是:
查看有效請求率指標是否下降,因為失敗的刪除請求會導致清理操作沒能按預期完成。
定位請求有效率降低的具體原因,查看具體是什么錯誤類型的請求導致。然后還可以結合具體的客戶端日志定位更詳細的錯誤信息(例如,用于釋放空間的STS臨時Token已過期)。
客戶端通過設置LifeCycle來清理空間:針對這種請求,需要通過控制臺或者API接口查看目前Bucket的LifeCycle是否為之前設置的預期值。如果不是,可以直接更正目前配置;進一步的調查可以通過Logging功能記錄的服務端日志記錄查詢以前修改的具體信息。如果LifeCycle是正常的,但是卻沒有生效,請聯系OSS系統管理員協助調查。
其他存儲服務問題
如果前面的故障排除章節未包括您遇到的存儲服務問題,則可以采用以下方法來診斷和排查您的問題:
查看OSS監控服務,了解與預期的基準行為相比是否存在任何更改。監控視圖可能能夠確定此問題是暫時的還是永久性的,并可確定此問題影響哪些存儲操作。
使用監控信息來幫助您搜索日志功能記錄的服務端日志數據,獲取相關時間點發生的任何錯誤信息。此信息可能會幫助您排查和解決該問題。
如果服務器端日志中的信息不足以成功排查此問題,則可以使用客戶端日志來調查客戶端應用程序,或者配合使用網絡工具(Wireshark等)調查您的網絡問題。