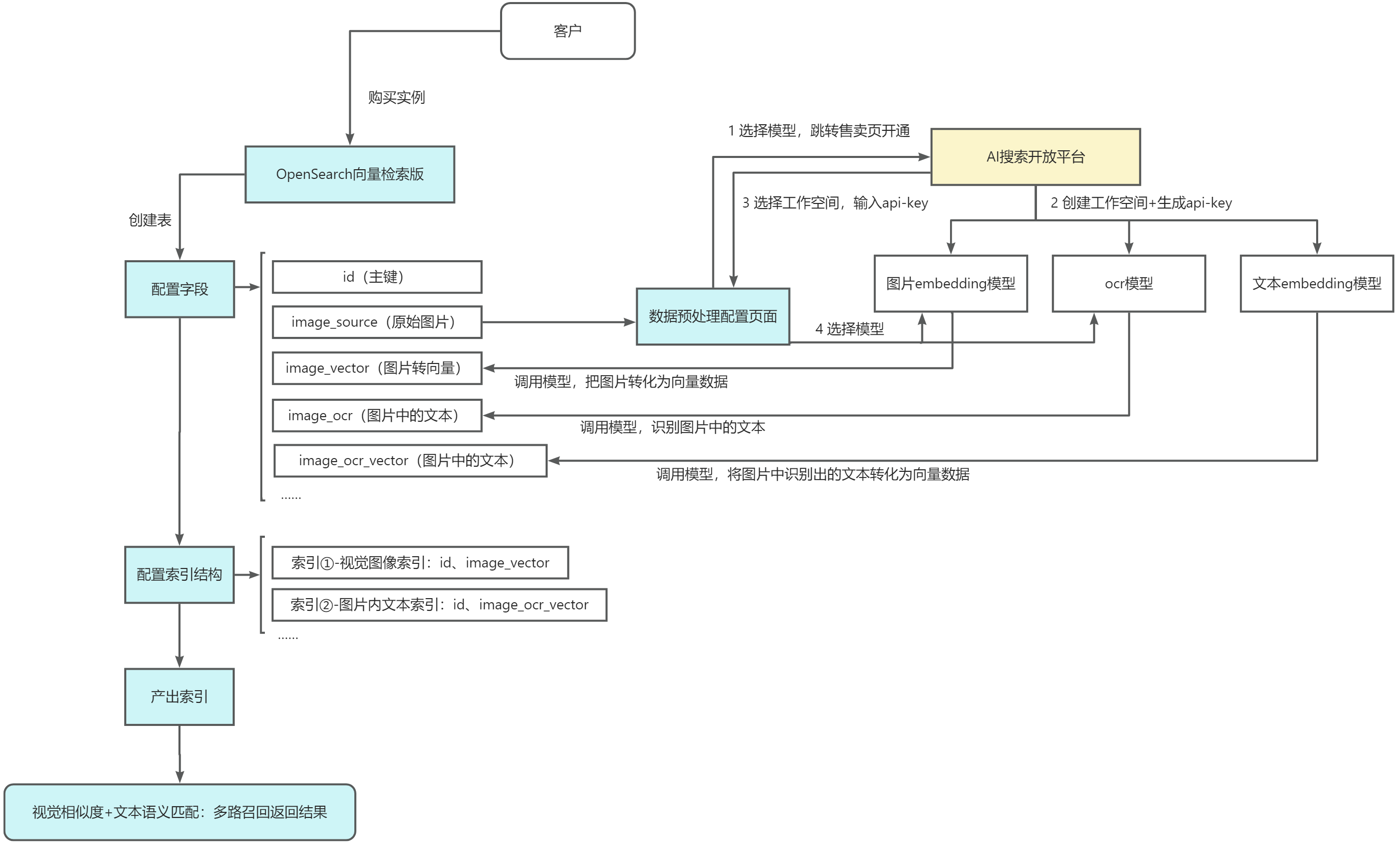
本文介紹如何調用AI搜索開放平臺模型進行數據預處理。此方案適用所有需要將原始圖片或文本進行處理并實現文本搜圖、圖搜圖及語義搜索的場景。
鏈路示意
下面以某個從事裝卸搬運和倉儲業為主的企業案例為例,只有各倉庫工人拍攝的貨品照片(貨品外包裝圖片,圖片中含有貨品品牌型號等文本信息)和貨品ID,需要以圖搜圖來快速查詢相似貨品,即可參照示意圖中的鏈路快速搭建圖搜服務。
購買實例
購買實例可參考購買OpenSearch向量檢索版實例。
配置實例
新購買的實例,在其詳情頁中,實例狀態為“待配置”,并且會自動部署一個與購買的查詢節點和數據節點的個數及規格一致的空實例,之后需要為該實例配置表信息>數據同步>字段配置>索引結構,之后等待索引重建完成即可正常搜索。

1. 表基礎信息
表管理點擊“添加表",輸入表名稱,設置數據分片數和數據更新資源數,選擇場景模板后點擊下一步:
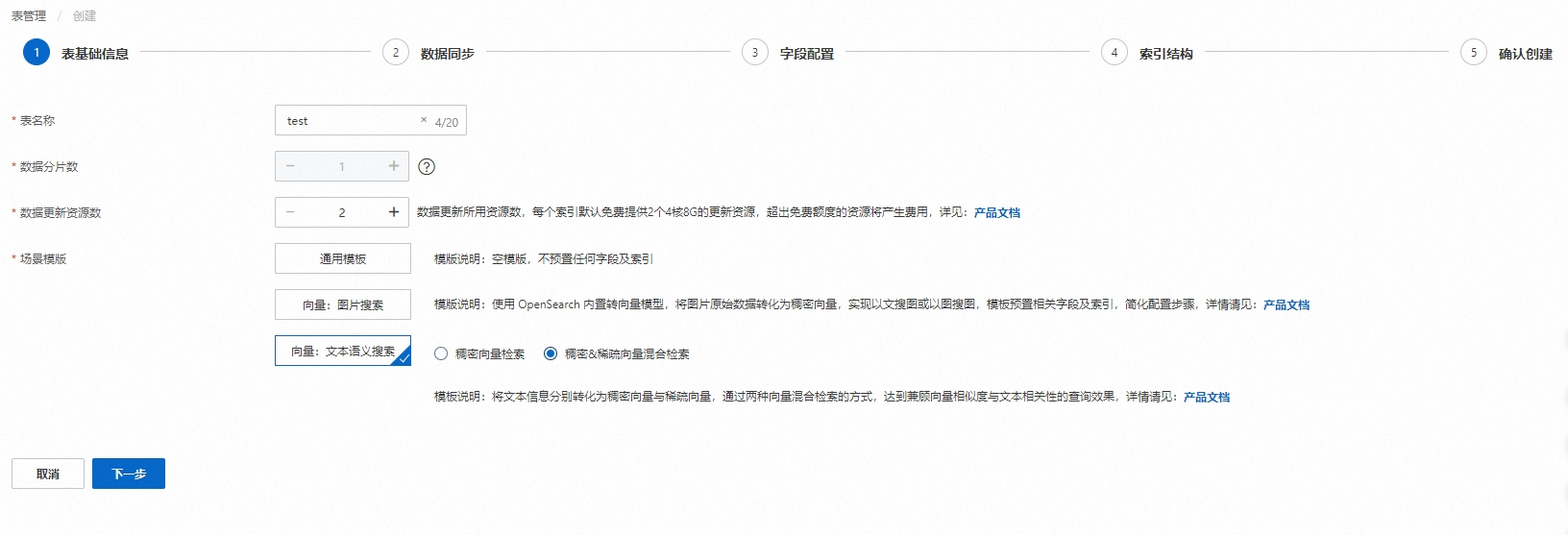
配置說明:
表名稱:可自定義
數據分片數:分片數設置時,請填寫不超過256的正整數, 用于提升全量構建速度、單次查詢性能。(部分存量實例,仍需各索引表分片數保持一致;或至少一個索引表分片數為1,其余索引表分片數一致)
數據更新資源數:數據更新所用資源數,每個索引默認免費提供2個4核8G的更新資源,超出免費額度的資源將產生費用,詳情可參考向量檢索版計費概述
場景模板:可選擇通用模板、向量:圖片搜索或向量:文本語義搜索。
2.數據同步
配置數據源,校驗通過后,點擊下一步。
3.字段配置
待轉向量的原始數據勾選需數據預處理,校驗字段類型為STRING,然后點擊去配置,進入數據預處理配置頁。
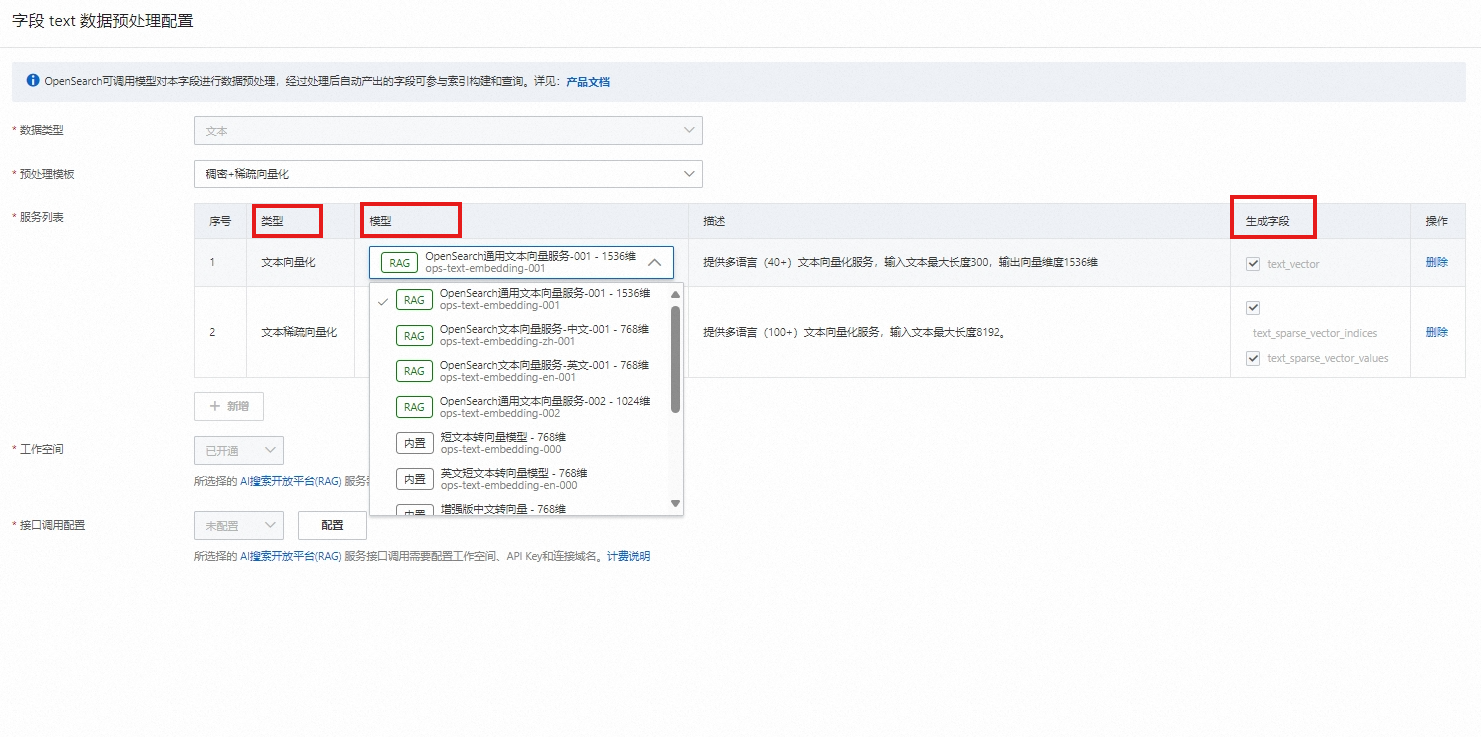
數據預處理配置說明:
數據類型:場景模板的預設字段數據類型固定,手動增加的字段可選類型(文本或圖片)。
數據來源:圖片類型需選擇來源(base64或OSS),其他類型無此字段。
預處理模板:每種數據類型支持的模板。
服務列表:
類型:
選定預處理模板后,自動出現模板下的服務列表。
可刪除服務,但需保障刪除后,服務列表滿足模板最少服務要求(如OCR+圖片向量化模板,需保留至少1個OCR服務,1個圖片向量化服務,1個OCR文本向量化服務)。
手動新增服務,當刪除服務后才可手動新增,但可選范圍在對應預處理模板限制內。
模型:
選擇內置模型或AI搜索開放平臺模型。
- 說明
選擇內置模型可以免費調用,選擇AI搜索開放平臺模型需付費,計費詳情參見計費方式和計費項。
AI搜索開放平臺的調用計費單獨出賬單,與向量版檢索版賬單分開計費。
選擇AI搜索開放平臺的模型,您需開通AI搜索開放平臺工作空間并創建API Key。
生成字段:
embedding處理類的服務,默認必須生成字段。
ocr服務可選是否生成字段。
同一字段,同類服務目前只支持處理一次。
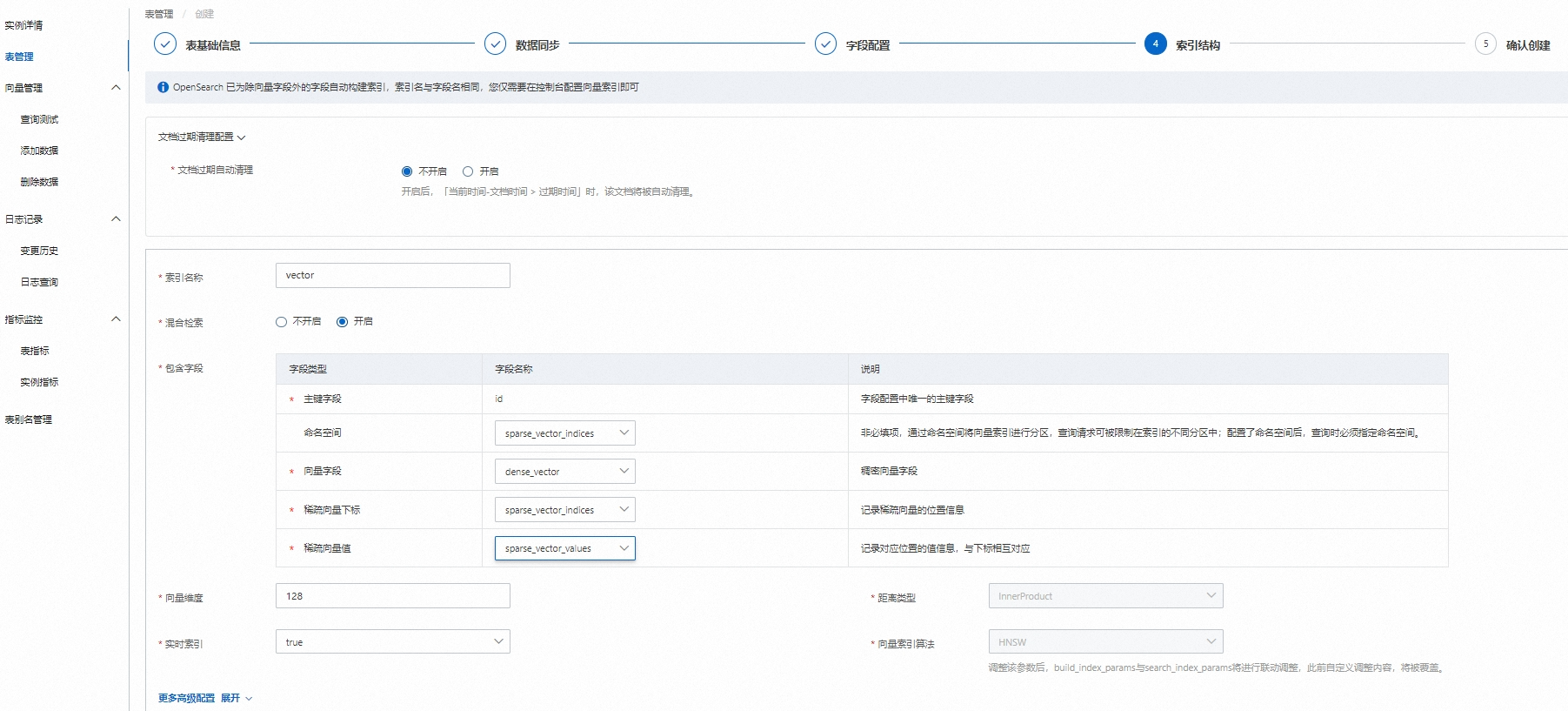
4.索引結構
配置完成后點擊下一步:
5.確認創建
配置完成后,點擊確認創建。
6.變更歷史
可在變更歷史中查看表的創建進度。