召回引擎版介紹
召回引擎版簡介
OpenSearch-召回引擎版是阿里巴巴自主研發(fā)的大規(guī)模分布式搜索引擎,支持了淘寶、天貓、菜鳥、優(yōu)酷乃至海外電商在內(nèi)整個集團(tuán)的搜索業(yè)務(wù),同時也支撐了阿里云上的開放搜索業(yè)務(wù)。OpenSearch-召回引擎版經(jīng)過多年的發(fā)展,在滿足業(yè)務(wù)高可用、高時效性、低成本等需求的同時,也沉淀出一套自動化運(yùn)維系統(tǒng),使用它用戶可以根據(jù)自己的業(yè)務(wù)特點(diǎn)方便的構(gòu)建自己的搜索服務(wù)。
OpenSearch-召回引擎版架構(gòu)
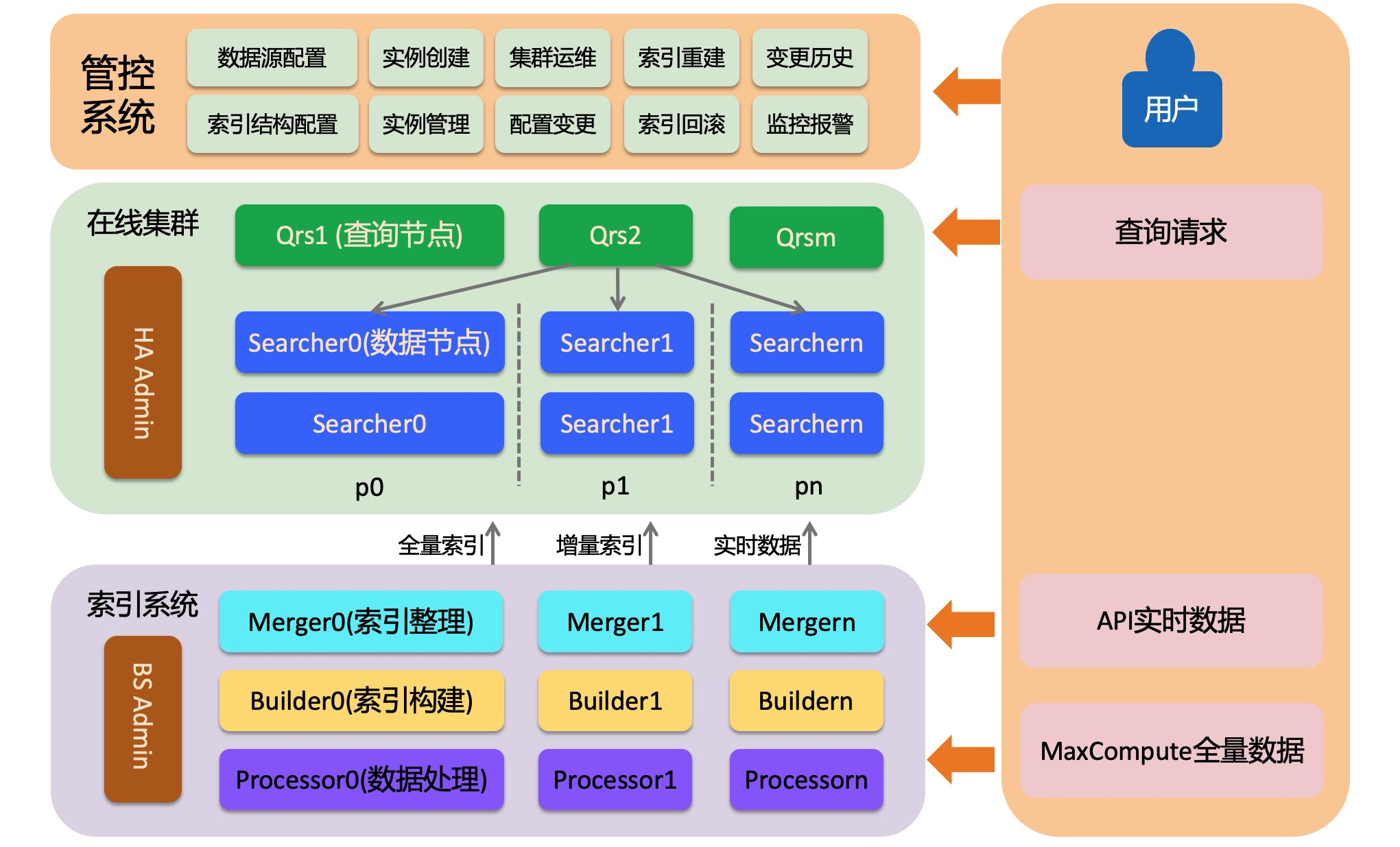
OpenSearch-召回引擎版主要有三部分構(gòu)成,在線系統(tǒng)、離線索引構(gòu)建系統(tǒng)、管控系統(tǒng)。在線系統(tǒng)加載索引,并提供檢索服務(wù);離線索引構(gòu)建系統(tǒng)將用戶的數(shù)據(jù)構(gòu)建成索引,包括全量索引、批次增量索引、實(shí)時索引;管控系統(tǒng)為用戶提供自動化運(yùn)維服務(wù),方便用戶創(chuàng)建集群并對集群進(jìn)行各種運(yùn)維操作。
?
在線系統(tǒng)
在線系統(tǒng)是一個分布式檢索系統(tǒng),由三個角色構(gòu)成:admin、qrs和searcher,下面分別介紹:
HA Admin
HA Admin是在線系統(tǒng)的大腦,每個物理集群都會有最少一個admin。HA admin負(fù)載接受管控系統(tǒng)的命令,并根據(jù)命令向Qrs和Searcher發(fā)送各種運(yùn)維指令。另外admin還會實(shí)時監(jiān)控Qrs和Searcher節(jié)點(diǎn)的運(yùn)行情況,對于心跳異常的節(jié)點(diǎn)admin會自動替換。
?
Qrs(查詢節(jié)點(diǎn))
Qrs也叫查詢節(jié)點(diǎn)或者查詢與結(jié)果處理節(jié)點(diǎn),它對輸入的查詢請求進(jìn)行解析、校驗(yàn)或者改寫,并將解析之后的請求轉(zhuǎn)發(fā)給Searcher執(zhí)行,收集并合并Searcher返回的結(jié)果,加工之后返回給用戶。查詢節(jié)點(diǎn)是一個計算型節(jié)點(diǎn),不加載用戶的數(shù)據(jù),一般不需要太多的內(nèi)存,但是當(dāng)返回的文檔個數(shù)較多或者統(tǒng)計產(chǎn)出的條目過多時才會消耗大量內(nèi)存。如果查詢節(jié)點(diǎn)的處理能力達(dá)到瓶頸,可以擴(kuò)充查詢節(jié)點(diǎn)的備份數(shù)或者擴(kuò)查詢節(jié)點(diǎn)的規(guī)格。
?
Searcher(數(shù)據(jù)節(jié)點(diǎn))
Searcher加載用戶的索引數(shù)據(jù)并根據(jù)查詢檢索文檔、對文檔進(jìn)行過濾、統(tǒng)計、排序等操作。Searcher上的索引是可以分片的,分片的含義是對分片字段哈希到[0,65535]之間,將這個區(qū)間分成指定的片數(shù)(構(gòu)建索引時指定)。這樣對于數(shù)據(jù)量較大或者對查詢性能有要求的集群,就可以通過分片提高單次請求的處理性能。如果想提高整個集群的處理能力(比如從支持1000 qps提升到10000 qps)可以通過擴(kuò)備份的方式進(jìn)行。擴(kuò)備份不是只擴(kuò)一個Searcher節(jié)點(diǎn),而是擴(kuò)承載所有數(shù)據(jù)的多個Searcher節(jié)點(diǎn)(多個分片要做成完整的[0,65535]區(qū)間)。
?
離線索引構(gòu)建系統(tǒng)
OpenSearch-召回引擎版是一個讀寫分離的搜索引擎,數(shù)據(jù)的寫入不影響在線檢索服務(wù),所以能夠在支撐大批量數(shù)據(jù)實(shí)時寫入的同時,也能保證查詢服務(wù)足夠穩(wěn)定。索引構(gòu)建系統(tǒng)主要包括兩個流程(全量和增量),每個流程中都會有三個角色來處理數(shù)據(jù)、構(gòu)建索引。
全量流程
OpenSearch-召回引擎版的索引是支持多版本的,每個索引版本都會基于一份原始數(shù)據(jù)來構(gòu)建(API數(shù)據(jù)源默認(rèn)為空數(shù)據(jù)),在第一次構(gòu)建時啟動的就是全量流程。全量流程是一個非常駐任務(wù),數(shù)據(jù)處理完成,產(chǎn)出一份全量索引,全量流程結(jié)束。產(chǎn)出的全量索引通過全量切換,切換到在線集群提供檢索服務(wù),后續(xù)的增量數(shù)據(jù)更新都是更新到新產(chǎn)出的全量版本中。目前全量任務(wù)僅支持從MaxCompute數(shù)據(jù)源或者HDFS數(shù)據(jù)源中讀取全量數(shù)據(jù)。
多索引版本的支持可以保證數(shù)據(jù)變更的穩(wěn)定性,當(dāng)索引結(jié)構(gòu)變化或者數(shù)據(jù)結(jié)構(gòu)發(fā)生變化時,通過全量產(chǎn)出新的索引是和老版本的索引完全隔離的,如果變更有問題可以及時回滾。
全量索引的產(chǎn)出需要經(jīng)過數(shù)據(jù)處理,索引構(gòu)建,索引合并等流程,在各個階段可以通過設(shè)置索引處理的并發(fā)度提高全量索引的產(chǎn)出速度。
增量流程
全量索引產(chǎn)出之后,后續(xù)數(shù)據(jù)的更新都需要通過API推送完成。API推送的數(shù)據(jù)有兩條處理鏈路:經(jīng)過Processor處理之后直接推送到數(shù)據(jù)節(jié)點(diǎn)在內(nèi)存中構(gòu)建實(shí)時索引;處理之后的數(shù)據(jù)經(jīng)過Builder和Merger構(gòu)建出增量索引,通過增量切換的形式切換到數(shù)據(jù)節(jié)點(diǎn)。增量切換時會清理內(nèi)存中的實(shí)時索引,將增量中已經(jīng)包含的數(shù)據(jù)從實(shí)時內(nèi)存中刪除,減輕數(shù)據(jù)節(jié)點(diǎn)內(nèi)存壓力。
增量流程是一個常駐任務(wù),每一個索引表都會對應(yīng)一個增量流程,可以通過控制增量流程各個節(jié)點(diǎn)的并發(fā)度來提高實(shí)時數(shù)據(jù)的處理能力。
Processor
Processor處理原始文檔,主要包括分詞或者根據(jù)業(yè)務(wù)邏輯對字段內(nèi)容進(jìn)行改寫。Processor在增量流程中是一個常駐的分布式服務(wù),可以通過配置調(diào)節(jié)Processor的并發(fā)度來提高數(shù)據(jù)處理能力。Processor中支持配置多個數(shù)據(jù)處理插件,目前還未對外開放,如果有需求可以聯(lián)系我們。
Builder
Builder將處理之后的文檔構(gòu)建成索引。Builder不是一個常駐任務(wù),它和Merger交替執(zhí)行,每次Build完一次數(shù)據(jù)就會啟動依賴Merger任務(wù)對索引進(jìn)行整理,整理之后的索引才會切換到數(shù)據(jù)節(jié)點(diǎn)。
Merger
Merger將Builder產(chǎn)出的索引數(shù)據(jù)作合并整理,使產(chǎn)出的索引更加的整齊緊湊。隨著數(shù)據(jù)更新,老的索引中必然會有很多被標(biāo)記刪除的數(shù)據(jù),Merger會按照指定的索引合并策略將這些數(shù)據(jù)進(jìn)行清理合并。
召回引擎版索引結(jié)構(gòu)
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary結(jié)構(gòu)名稱 | 說明 |
generation | generation_x是引擎區(qū)分不同版本全量索引的標(biāo)識。 |
partition | partition是searcher加載索引的基本單位。如果一個partition中數(shù)據(jù)過多,會導(dǎo)致searcher性能降低。線上數(shù)據(jù)一般通過劃分多個partition的方式來保證每個searcher的檢索效率。 |
schema.json | 索引配置文件。主要記錄fields,index, attribute 和summary等信息。引擎通過該文件來加載索引。 |
version.0 | version文件。主要記錄當(dāng)前partition中引擎需要加載的segment和最新doc的時間戳。在實(shí)時build中,引擎會根據(jù)增量version的時間戳過濾舊的原始文檔。 |
segment | segment是索引組成的基本單位。segment中包含了文檔的倒排和正排結(jié)構(gòu)。index builder每次dump都會生成一個segment。多個segment可以通過merge策略進(jìn)行合并。一個partition中可用的segment在version文件中指明。 |
segment_info | segment信息摘要。記錄了當(dāng)前segment中文檔數(shù)目,當(dāng)前segment是否merge過,locator信息和最新doc時間戳信息。 |
index | 倒排索引目錄。 |
attribute | 正排索引目錄。 |
deletionmap | 刪除的doc記錄。 |
summary | 摘要索引目錄。 |
管控系統(tǒng)
管控系統(tǒng)是一個OpenSearch-召回引擎版實(shí)例的運(yùn)維平臺,這個平臺大大節(jié)省了我們的運(yùn)維成本,關(guān)于這個運(yùn)維平臺的介紹請參考召回引擎版產(chǎn)品文檔。
召回引擎版特性
穩(wěn)定
召回引擎版底層采用c++實(shí)現(xiàn),經(jīng)過十多年的發(fā)展,支撐了多個核心業(yè)務(wù),非常穩(wěn)定,非常適用于對穩(wěn)定性要求較高的核心搜索場景。
高效
OpenSearch-召回引擎版是一個分布式搜索引擎,可以高效的支持海量數(shù)據(jù)的檢索,同時也支持?jǐn)?shù)據(jù)的實(shí)時更新(秒級生效),非常適用于對查詢耗時敏感、時效性要求高的搜索場景。
低成本
OpenSearch-召回引擎版支持多種索引壓縮策略,同時支持多值索引加載測試,能夠以較低的成本滿足用戶的查詢需求。
功能豐富
OpenSearch-召回引擎版支持多種分析器類型、多種索引類型、強(qiáng)大的查詢語法,能夠很好的滿足用戶的檢索需求。同時我們還提供插件機(jī)制,方便用戶定制自己的業(yè)務(wù)處理邏輯。
SQL查詢
OpenSearch-召回引擎版支持SQL查詢語法,支持多表在線join,提供豐富的內(nèi)置UDF函數(shù)和UDF函數(shù)定制機(jī)制,以滿足不同用戶的檢索需求。在運(yùn)維系統(tǒng)中我們即將集成SQL studio,方便用戶進(jìn)行SQL開發(fā)和測試。