簡介
Opensearch-LLM智能問答版提供了向量模型、稀疏向量模型、多種切片方式和圖片內容識別的向量模型可供客戶根據實際需求自由選擇。
操作步驟
1、點擊實例管理下的數據配置->變更配置。
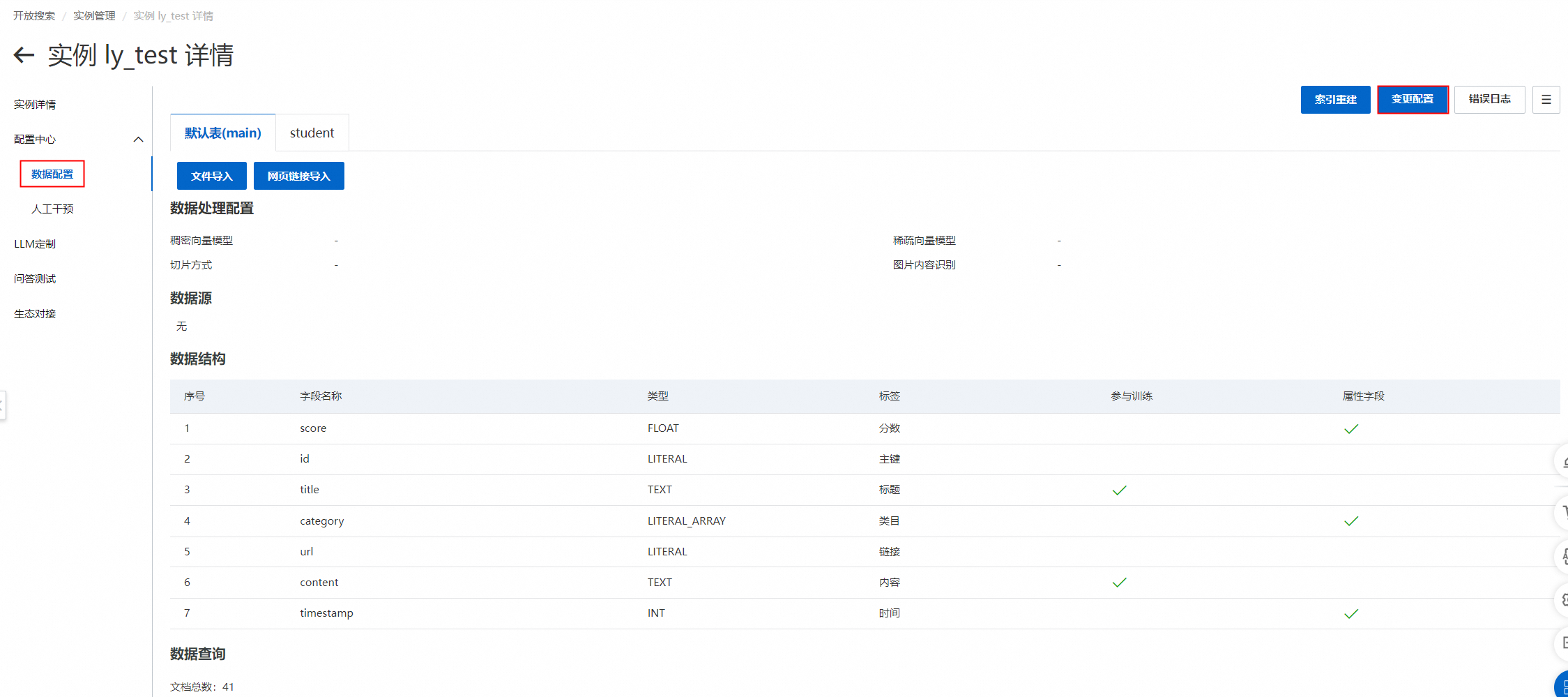
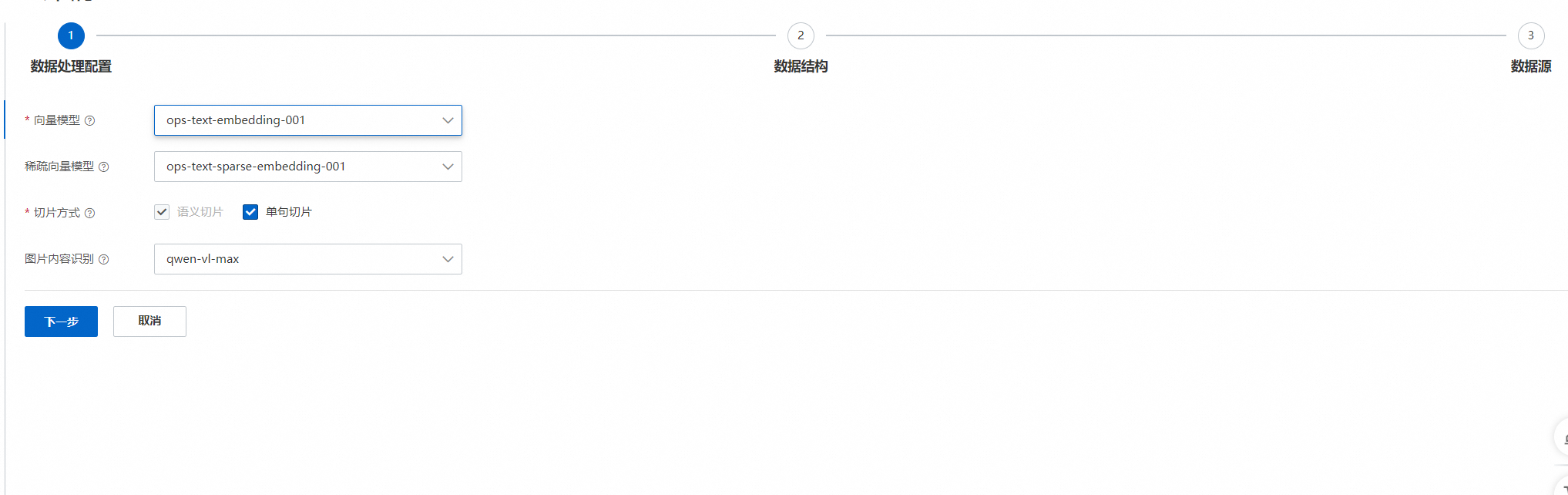
2、根據實際需求選擇對應的向量模型、稀疏向量模型、切片方式和圖片內容識別,然后點擊下一步。
說明
向量模型:用于生產文本的稠密向量表示,理解長文本和語義化描述,優化檢索效果。
稀疏向量模型:用于生成文本的稀疏向量表示,優化包含過濾、篩選條件下的檢索效果。需要和稠密向量同時使用,通常情況下效果優于純稠密向量,建議開啟。
切片方式:
語義切片:根據文本語義進行切片,默認開啟。
單句切片:根據每個單句進行切片,開啟后可提升長文檔匹配的精準度。請注意:選擇單句切片后,單個文檔所占用的存儲容量將擴展約6倍。
圖片內容識別:使用多模態模型理解圖片內容,開啟后可提升參考圖片的準確率。請注意:開啟圖片內容識別后,上傳文檔時,將按照圖片內容識別模型所需要的計算資源付費。
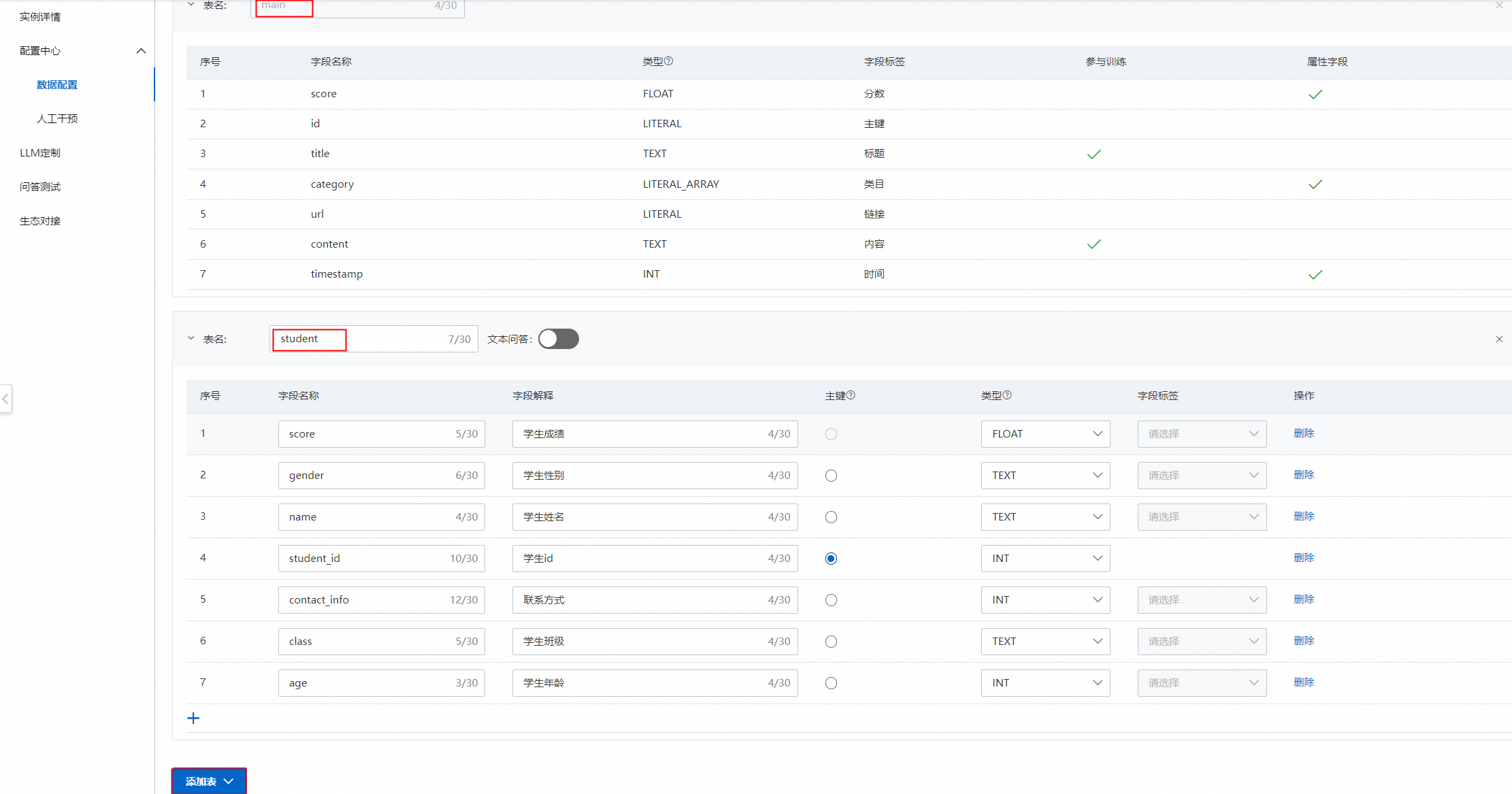
2、根據實際的業務需要,添加刪除或者修改自定義表字段,然后點擊下一步。
說明
主表(main表)中的七個字段為系統必要字段,不可更改。
添加自定義表可參考表格問答。
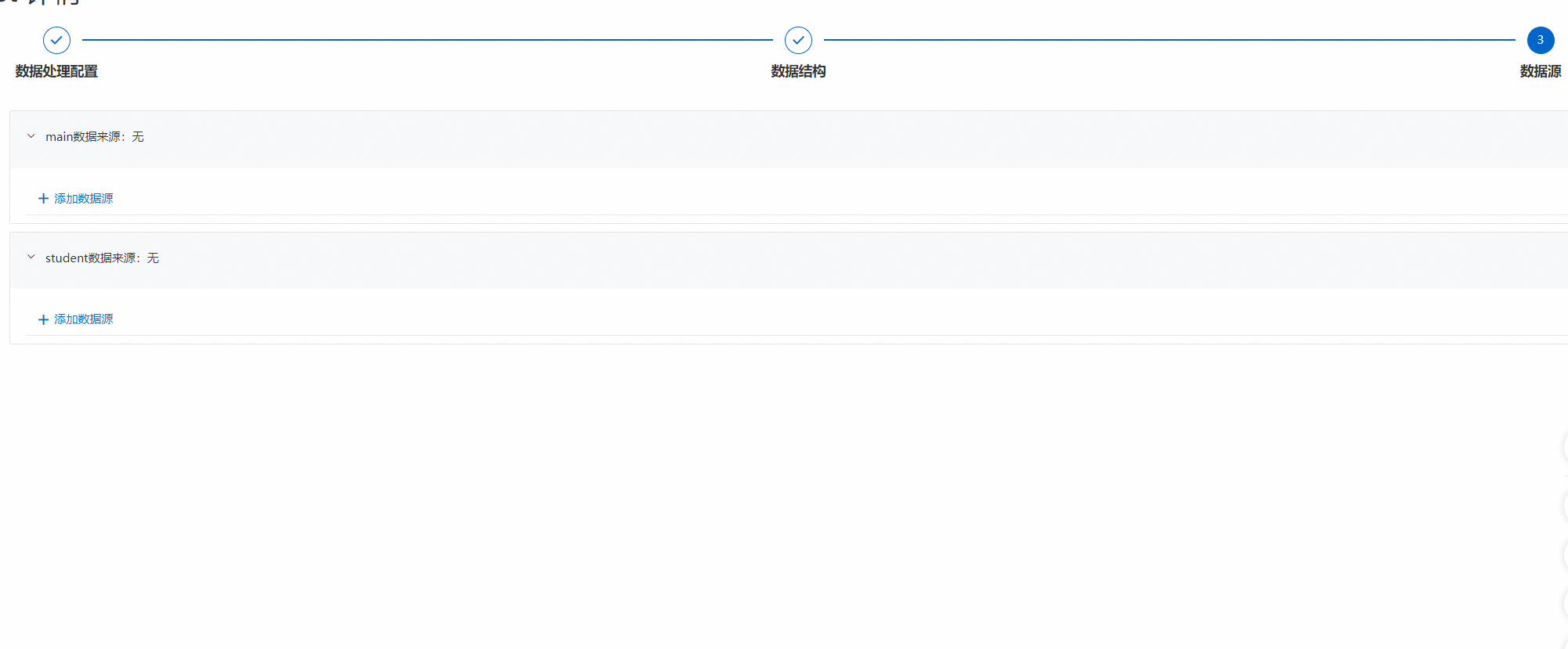
3、對應表如需添加數據源可點擊添加數據源,操作步驟可參考表格問答,如無需添加數據源點擊完成即可。
4、等待新版本構建完成即可。
文檔內容是否對您有幫助?