OpenSearch文檔排序?qū)嵺`
用戶對于搜索引擎最關(guān)注的兩方面一是召回,即滿足條件的doc全部可以被召回;二是排序,即在滿足條件的文檔中將相關(guān)度最高的文檔優(yōu)先召回。其中,二往往是需要根據(jù)用戶的實(shí)際業(yè)務(wù)需求進(jìn)行調(diào)整,因此就需要用戶對OpenSearch在排序方面提供的能力有一定的了解,本文將詳細(xì)介紹OpenSearch在排序方面的能力,并且列舉一些常見場景如何通過OpenSearch的排序能力實(shí)現(xiàn)。
sort子句與排序策略的關(guān)系
簡單來說sort子句在OpenSearch中代表全局排序,而排序策略可以理解為sort子句中的一個層級的排序,排序策略是通過系統(tǒng)內(nèi)置的函數(shù)結(jié)合表達(dá)式形成一種復(fù)雜的文檔算分邏輯來實(shí)現(xiàn)用戶復(fù)雜的業(yè)務(wù)場景,但最終參與排序的還是排序策略中表達(dá)式算出的最終得分。舉個例子,某個業(yè)務(wù)希望通過文檔的新舊程度進(jìn)行排序,同時新舊程度相同的文檔,可以根據(jù)文檔的相似程度進(jìn)行二級排序,此時實(shí)現(xiàn)用戶上述需求,就需要通過sort子句同時結(jié)合排序策略,假設(shè)用戶業(yè)務(wù)表中有一個字段為create_time,同時檢索的字段為name,則可以在sort子句中加入:
sort=-create_time;-RANK同時在基礎(chǔ)排序設(shè)置static_bm25() 函數(shù),在業(yè)務(wù)排序中設(shè)置text_relevance(name)函數(shù)即可。(排序策略的配置步驟參考排序策略配置)。
這里的RANK就表示獲取排序策略的得分,而“-” 表示倒序,“+”表示正序。
系統(tǒng)默認(rèn)在不配置sort子句的情況下用-RANK作為排序條件,而如果配置了sort子句,在需要排序策略分排序的時候需要顯示的寫入-RANK,否則系統(tǒng)將不會自動引入排序策略分作為排序條件。
為了更形象的表達(dá)sort子句和排序策略的關(guān)系,這里以一個案例的方式說明:
假設(shè)OpenSearch有一個應(yīng)用,應(yīng)用結(jié)構(gòu)為:
字段 | 類型 | 索引 |
id | int | 關(guān)鍵字 |
name | text | 中文通用 |
age | int | 關(guān)鍵字 |
為name設(shè)置了一個基礎(chǔ)排序,表達(dá)式內(nèi)容如下:

為name設(shè)置了一個業(yè)務(wù)排序,表達(dá)式內(nèi)容如下:

同時在檢索時,配置sort子句為:
sort=age;-RANK打開排序明細(xì)查看算分詳情:
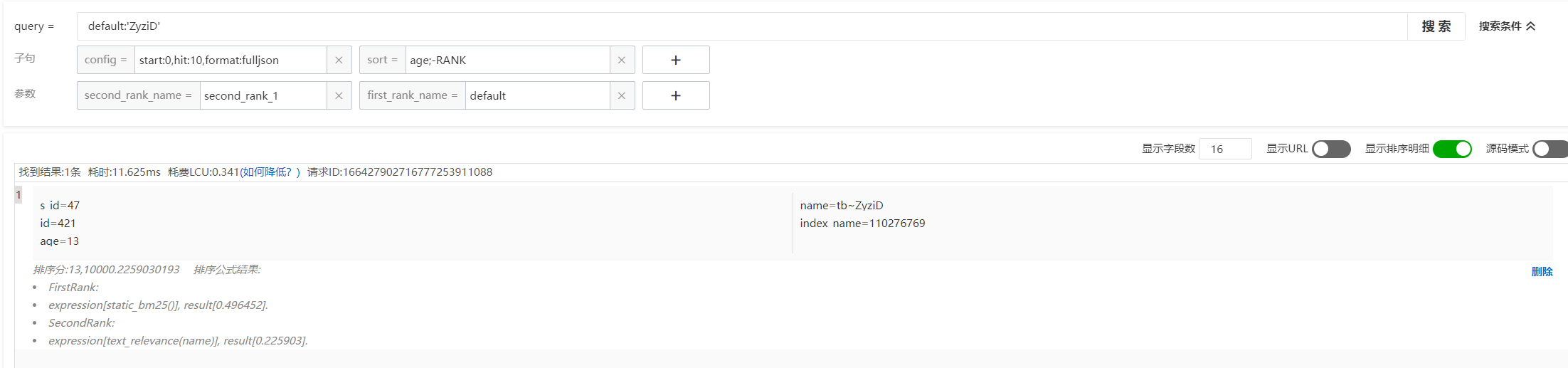
首先可以看到排序分為13,10000.2259030193,因?yàn)閟ort子句設(shè)置的是age;-RANK,因此13表示文檔字段age的值,而10000.2259030193表示排序策略的最終得分,OpenSearch會先根據(jù)age的值進(jìn)行正序排序,age值相同的文檔再根據(jù)排序策略的最終得分倒序排序。
再看排序公式:
FirstRank:
expression[static_bm25()], result[0.496452].
SecondRank:
expression[text_relevance(name)], result[0.225903].FirstRank表示基礎(chǔ)排序得分,SecondRank表示業(yè)務(wù)排序得分,最終的排序分為10000.2259030193,為什么最終排序策略得分為10000.2259030193而不是[0.496452+0.225903] 在下一節(jié)會詳細(xì)說明。
由上述現(xiàn)象,可以得出結(jié)論:在OpenSearch中sort子句類似于SQL中order by的功能,可以直接通過文檔中的屬性字段進(jìn)行排序,也支持復(fù)雜的排序策略進(jìn)行算分,而排序策略又有著特有的函數(shù)支持和算分規(guī)則,最終根據(jù)sort子句的“+”,“-”,以及排序字段控制文檔排序方式以及文檔得分。
排序策略說明
排序策略打分原理
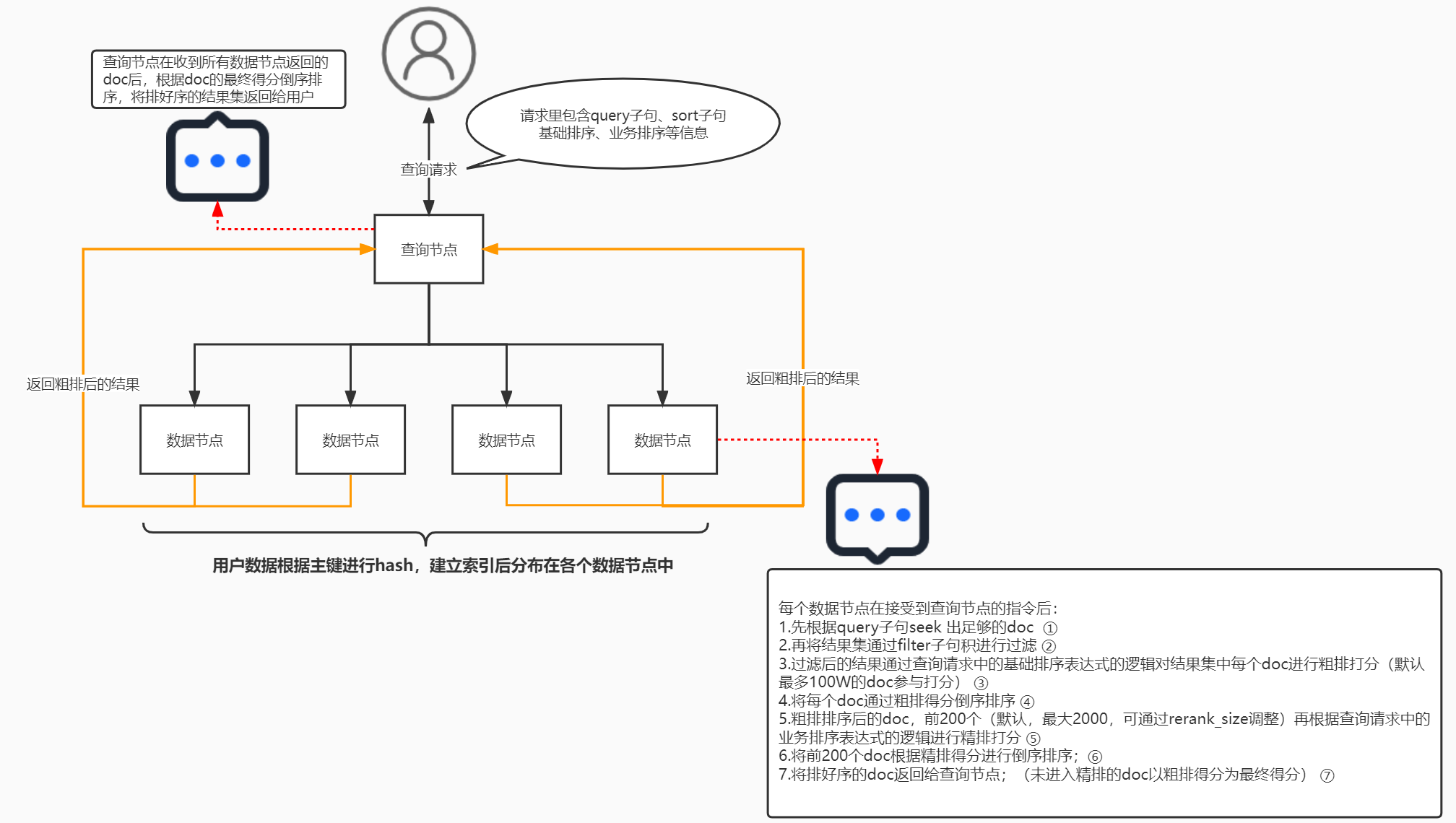
對于排序策略的算分分為兩個階段:基礎(chǔ)排序和業(yè)務(wù)排序,通過query召回并通過filter過濾后的文檔,首先進(jìn)入基礎(chǔ)排序,根據(jù)基礎(chǔ)排序表達(dá)式海選出文檔得分較高的文檔,然后取出TOP N個結(jié)果再按照業(yè)務(wù)排序表達(dá)式進(jìn)行精細(xì)算分,最終返回排序策略的最終得分。算分規(guī)則如下:
若只配置了基礎(chǔ)排序,則文檔得分為(10000+基礎(chǔ)排序表達(dá)式計算的結(jié)果),總分最大為20000,超過20000結(jié)果仍為20000。
若只配置了業(yè)務(wù)排序,則文檔得分為(10000+業(yè)務(wù)排序表達(dá)式計算的結(jié)果),總分無上限。
若同時配置了基礎(chǔ)排序和業(yè)務(wù)排序,那么進(jìn)入業(yè)務(wù)排序的文檔最終得分為(10000+業(yè)務(wù)排序表達(dá)式計算的結(jié)果),其余文檔最終得分為(10000+基礎(chǔ)排序表達(dá)式計算的結(jié)果,總分最大為20000,超過20000結(jié)果仍為20000)。
再結(jié)合上一節(jié)排序算分為:
FirstRank:
expression[static_bm25()], result[0.496452].
SecondRank:
expression[text_relevance(name)], result[0.225903].最終得分為10000.2259030193。
通過上述原理,可理解為該命中的doc,在基礎(chǔ)排序階段在召回100W的doc中,參與了基礎(chǔ)排序,通過static_bm25函數(shù)算分為0.496452,同時該文檔的基礎(chǔ)排序分正好使該文檔排在了所有命中文檔的前200內(nèi),參與了業(yè)務(wù)排序,在文檔從基礎(chǔ)排序進(jìn)入業(yè)務(wù)排序時文檔分會默認(rèn)加10000分,同時舍棄基礎(chǔ)排序的得分,以業(yè)務(wù)排序得分+10000分為最終的排序策略得分,由于該文檔在業(yè)務(wù)排序中通過text_relevance函數(shù)算分為0.225903,所以該文檔的最終排序策略得分為10000.2259030193。
業(yè)務(wù)排序函數(shù)用法
注意:以下內(nèi)置函數(shù)中引用到的應(yīng)用結(jié)構(gòu)中的字段均需要設(shè)置為屬性字段,否則會報錯Invalid formula。
函數(shù) | 描述 | 案例 |
i in (value1, value2, …, valuen) | 如果i的值在集合[value1, value2, …,valuen]中出現(xiàn),則該表達(dá)式值為1,否則為0。 | 字段age=5 age in (1,2,3,4,5) # 結(jié)果為1 age in (6,7,8,9) # 結(jié)果為0 |
if(cond, then_value, else_value) | 如果cond的值非0,則該if表達(dá)式的實(shí)際值為then_value,否則為else_value。 如if( 2,3, 5)的值為3,if( 0,3,5)的值為5。 | 字段a=1 if(a==1,5,10) #結(jié)果為5 if(1,5,10) #結(jié)果為5 if(a==2,5,10) #結(jié)果為10 if(0,5,10) #結(jié)果為10 |
random() | 返回[0,1]間的一個隨機(jī)值。 | - |
now() | 返回當(dāng)前時間,自Epoch ( 00:00:00 UTC,January 1,1970)開始計算,單位是秒。 | - |
常用的文本相關(guān)性、地理位置、時效性、算法相關(guān)性、功能性函數(shù)的介紹,可參考業(yè)務(wù)排序函數(shù)。
常用的數(shù)學(xué)函數(shù)以及表達(dá)式運(yùn)算符可參考排序策略配置。
若排序策略的表達(dá)式仍無法滿足復(fù)雜場景的算分邏輯,可以通過cava插件,編寫腳本進(jìn)行復(fù)雜場景的算分,關(guān)于cava插件的使用以及原理此處不再贅述,有興趣的用戶可以參考排序插件開發(fā)-Cava語言
常用場景的排序策略配置
1. 比如想根據(jù)age>10 的 +10分,age>40的+20分,根據(jù)weight>60的+30,最后根據(jù)最后得分排序。
實(shí)現(xiàn)1:
#業(yè)務(wù)排序表達(dá)式設(shè)置為:默認(rèn)是匹配到只加1分
(age>10)*10+(age>40)*20+(weight>60)*30實(shí)現(xiàn)2:
#精排表達(dá)式設(shè)置為:
if(age>10,10,0) + if(age>40,20,0) +if(weight>60,30,0)2. 比如,xxx公司,xxx杭州分公司,那么“xxx公司”要排在“xxx杭州分公司”的前面。
實(shí)現(xiàn):
#可以在業(yè)務(wù)排序(精排表達(dá)式)是里配置field_match_ratioc函數(shù)
field_match_ratio(title)3. 比如搜索 all:'dim_itm_tb',那么“dim_itm_tb”想在“dim_itm_tb_dst_itm_relation_dd”前面。
實(shí)現(xiàn):
#可以在業(yè)務(wù)排序(精排表達(dá)式)是里配置field_match_ratioc函數(shù):
field_match_ratio(detail) 4. 如何實(shí)現(xiàn)query = item:"iphone 8" OR item: 'iphone 8' 類似這種查詢呢
實(shí)現(xiàn):
#可以在業(yè)務(wù)排序(精排表達(dá)式)是里配置query_min_slide_window函數(shù):
query_min_slide_window(title)5. 我設(shè)置了一個精排 text_relevance,搜索關(guān)鍵詞是 "民國",但是不知道為什么 "民國趣聞-民國", "中國民族史-民國" 等要比 "民國" 排序要考前。(需要讓“民國”排在最前面)
實(shí)現(xiàn):
#可以在業(yè)務(wù)排序(精排表達(dá)式)是里配置query_min_slide_window函數(shù):
query_min_slide_window(title)6. 搜索關(guān)鍵字在字段內(nèi)容重復(fù)出現(xiàn),會導(dǎo)致static_bm25()函數(shù)重復(fù)算分,如果規(guī)避這種情況?
實(shí)現(xiàn):
#在業(yè)務(wù)排序里配置query_match_ratio
query_match_ratio(title) 7. 如何把搜索存在關(guān)鍵詞堆積的文檔給排到后面去?
實(shí)現(xiàn):
#使用query_term_match_count,定義重復(fù)多少次為結(jié)果堆積。
if(field_term_match_count(title)>3,1,10)8.如何配置字符串不為空時增加一定的分?jǐn)?shù)?
實(shí)現(xiàn):
可以先在源庫中增加標(biāo)記字段(mark),如過被判斷字段為空就標(biāo)記成0,不為空就標(biāo)記成1。然后在精排表達(dá)式中使用if函數(shù)進(jìn)行判斷。
精排表達(dá)式設(shè)置為:當(dāng)mark=1時排序分加500
if(mark==1,500,0)