服務運維
本文將主要分享大規模服務網格,在螞蟻集團當前體量下,落地到支撐螞蟻金服雙十一大促過程中,運維所面臨的挑戰與演進。
云原生化的選擇與問題
傳統的 Service Mesh:
在軟件形態上:將中間件的能力從框架中剝離成獨立軟件。
在具體部署上:保守的做法是以獨立進程的方式與業務進程共同存在于業務容器內。
螞蟻集團從開始就選擇了擁抱云原生。
Sidecar 模式
業務容器內獨立進程的優缺點為:
優點:與傳統的部署模式兼容,易于快速上線。
缺點:強侵入業務容器,對于鏡像化的容器更難于管理。
而云原生化,可以解決獨立進程的缺點,并帶來一些優點:
可以將 Service Mesh 本身的運維與業務容器解耦開來,實現中間件運維能力的下沉。
在業務鏡像內,僅保留長期穩定的 Service Mesh 相關 JVM 參數,從而僅通過少量環境變量完成與 Service Mesh 的聯結。
考慮到面向容器的運維模式的演進,接入 Service Mesh 還同時要求業務完成鏡像化,為進一步的云原生演進打下基礎。
優勢 | 劣勢 | |
獨立進程 | 兼容傳統的部署模式改造成本低快速上線 | 侵入業務容器鏡像化難于運維 |
Sidecar | 面向終態運維解耦 | 依賴 K8s 基礎設施運維環境改造成本高應用需要鏡像化改造 |
在接入 Service Mesh 之后,一個典型的 Pod 結構可能包含多個 Sidecar:
MOSN:RPC Mesh、MSG Mesh 等。
其它 Sidecar。
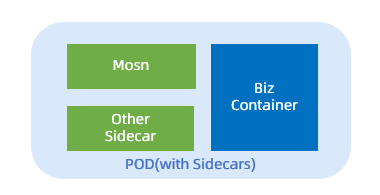
這些 Sidecar 容器,與業務容器共享相同的網絡 Namespace,使得業務進程可以從本地端口訪問 Service Mesh 提供的服務,保證了與保守做法一致的體驗。
基礎設施云原生支撐
螞蟻團隊也在基礎設施層面同步推進了面向云原生的改造,以支撐 Service Mesh 的落地。
業務全面鏡像化
首先是在螞蟻集團內部推進了全面的鏡像化,完成了內部核心應用的全量容器的鏡像化改造。改造點包括:
基礎鏡像層面增加對于 Service Mesh 的環境變量支撐。
應用 Dockerfile 對于 Service Mesh 的適配。
由于歷史原因,前后端分離管理的靜態文件還有一些存量,螞蟻團隊推進解決了存量文件的鏡像化改造。
對于大量使用前端區塊分發的應用,進行了推改拉的改造。
大批量的 VM 模式的容器升級與替換。
容器 Pod 化
除了業務鏡像層面的改造,Sidecar 模式還需要業務容器全部跑在 Pod 上,來適應多容器共享網絡。由于直接升級的開發和試錯成本很高,接入 Service Mesh 的數百個應用有數萬個非 K8s 容器,螞蟻團隊最終選擇通過大規模擴縮容的方式,將其全部更換成了 K8s Pods。
經過這兩輪改造,螞蟻團隊在基礎設施層面同步完成了面向云原生的改造。
對資源模型的挑戰
Sidecar 模式帶來的一個重要的問題是:如何分配資源。
理想比例的假設
最初的資源設計基于內存無法超賣的現實。螞蟻做了一個假設:MOSN 的基本資源占用與業務選擇的規格同比例。即 CPU 和 Memory 申請的額外資源與業務容器成相應比例,這一比例最后設定在了 CPU 1/4,Memory 1/16。
此時一個典型 Pod 的資源分配如下圖示:

理想比例的缺陷
理想比例的假設帶來了兩個問題:
螞蟻集團已經實現了業務資源的 Quota 管控,但 Sidecar 并不在業務容器內,Service Mesh 容器成為了一個資源泄漏點。
由于業務多樣性,部分高流量應用的 Service Mesh 容器出現了嚴重的內存不足和 OOM 情況。
為了快速支撐 Service Mesh 在非云環境的鋪開,上線了原地接入 Service Mesh。而原地接入 Service Mesh 的資源無法額外分配,在內存不能超賣的情況下,采取了二次分割的分配方式。此時的 Pod 內存資源分配方式為:
1/16 內存給 Sidecar。
15/16 內存給業務容器。
還有一些新的問題:
業務可見內存不一致。
業務監控偏差。
業務進程 OOM 風險。
解決方案
為了解決上述問題,螞蟻團隊追加了一個假設:在接入 Service Mesh 之前,業務已使用的資源,才是 Service Mesh 容器占用的資源。接入 Service Mesh 的過程,同時也是一次資源置換。
基于這個假設,推進了調度層面支持 Pod 內的資源超賣。Service Mesh 容器的 CPU、MEM 都從 Pod 中超賣出來,業務容器內仍然可以看到全部的資源。
新的資源分配方案,示例如下:

新的分配方案考慮了下述因素:
內存超賣
引入了 Pod OOM 的風險
因此,對于 Sidecar 容器還調整了 OOM Score,保證在內存不足時,通過 Service Mesh 進程比 Java 業務進程啟動更快,從而更降低影響。
同時,新的分配方案還解決了以上兩個問題,并且平穩支持了大促前的多輪壓測。
重建
新的分配方案上線時,Service Mesh 已經在彈性建站時同步上線。同時,螞蟻團隊還發現:在一些場景下,Service Mesh 容器無法搶占到 CPU 資源,導致業務 RT 出現了大幅抖動。原因是:在 CPU Share 模式下,Pod 內默認并沒有將等額的CPU Quota 分配給 Sidecar。
于是又產生了兩個新問題:
存量的已分配 Sidecar 仍有 OOM 風險。
Sidecar 無法搶占到 CPU。
螞蟻已經無法承受更換全部 Pod 的代價。最終在調度的支持下,通過手動對 Pod Annotation 進行重新計算及修改,在 Pod 內進行了全部資源的重分配,來修復這兩個風險。最終修復的容器總數約為 25 w 個。
大規模場景下運維設施的演進
Service Mesh 的變更包括了接入與升級,所有變更底層都是由 Operator 組件 來接受上層寫入到 Pod annotation 上的標識,然后通過對相應 Pod Spec 進行修改來完成,這是典型的云原生的方式。由于螞蟻集團的資源現狀與運維需要,又發展出了原地接入與平滑升級。
接入
有 2 種接入方式:
創建接入:最初 Service Mesh 接入只提供了創建時注入 Sidecar。
原地接入:后來引入了原地接入,主要是為了支撐大規模的快速接入與回滾。
2 種接入方式的優缺點如下:
創建接入:
資源替換過程需要大量 Buffer。
回滾困難。
原地接入:
不需要重新分配資源。
可原地回滾。
原地接入/回滾需要對 Pod Spec 進行精細化的修改,實踐中發現了很多問題,當前能力只做了小范圍的測試。
升級
Service Mesh 是深度參與業務流量的,因此最初的 Sidecar 的升級方式也需要業務伴隨重啟。這個過程看似簡單,螞蟻卻遇到了 2 個嚴重問題:
Pod 內的容器啟動順序隨機,導致業務無法啟動。這個問題最終通過調度層修改啟動邏輯來解決:Pod 內需要優先等待所有 Sidecar 啟動完成。但是,這導致了下述第二所述的新問題。
Sidecar 啟動慢了,上層超時。此問題仍在解決中。
Sidecar 中,MOSN 提供了更為靈活的平滑升級機制:由 Operator 控制啟動第二個 MOSN Sidecar,完成連接遷移,再退出舊的 Sidecar。小規模測試顯示,整個過程業務可以做到流量不中斷,幾近無感。目前平滑升級同樣涉及到 Pod Spec 的大量操作,考慮到大促前的穩定性,目前此方式未做大規模應用。
規模化的問題
在逐漸達到大促狀態的過程中,接入 Service Mesh 的容器數量開始大爆炸式增加。容器數量從千級別迅速膨脹到10 w +,最終達到全站數十萬容器規模,并在膨脹后還經歷了數次版本變更。
快速奔跑的同時,缺少相應的平臺能力也給大規模的 Sidecar 運維帶來了極大挑戰:
版本管理混亂:
Sidecar 的版本與應用 / Zone 的映射關系維護在內部元數據平臺的配置中。大量應用接入后,全局版本、實驗版本、特殊 Bugfix 版本等混雜在多個配置項中,統一基線被打破,難于維護。
元數據不一致:
元數據平臺維護了 Pod 粒度的 Sidecar 版本信息,但是由于 Operator 是面向終態的,會出現元數據與底層實際不一致的情況,當前仍依賴巡檢發現。
缺少完善的 Sidecar ops 支撐平臺:
缺少多維度的全局視圖。
缺少固化的灰度發布流程。
依賴于人工經驗配置管理變更。
監控噪聲巨大。
目前,Service Mesh 與 PaaS 的開發團隊都正在建設相應的能力,這些問題正得到逐步的緩解。
周邊技術風險能力的建設
監控能力
螞蟻的監控平臺為 Service Mesh 提供了基礎的監控能力和大盤,以及應用維度的 Sidecar 監控情況,包括:
系統監控:
CPU
MEM
LOAD
業務監控:
RT
RPC 流量
MSG 流量
Error 日志監控
Service Mesh 進程還提供了相應的 Metrics 接口,提供服務粒度的數據采集與計算。
巡檢
在 Service Mesh 上線后,巡檢也陸續被加入:
日志 Volume 檢查
版本一致性檢查
分時調度狀態一致性檢查
預案與應急
Service Mesh 自身具備按需關閉部分功能的能力,當前通過配置中心實現下述功能:
日志分級降級
Tracelog 日志分級降級
控制面(Pilot)依賴降級
軟負載均衡長輪詢降級
對于 Service Mesh 依賴的服務,為了防止潛在的抖動風險,也增加了相應的預案:
軟負載均衡列表停止變更。
服務注冊中心高峰期關閉推送。
Service Mesh 是非常基礎的組件,目前的應急手段主要是下述重啟方式:
Sidecar 單獨重啟
Pod 重啟
變更風險防控
除了傳統的變更三板斧之外,螞蟻還引入了無人值守變更,對 Service Mesh 變更做了自動檢測、自動分析與變更熔斷。
無人值守變更防控主要關注變更后對系統和業務和影響,串聯了多層檢測,主要包括:
系統指標:機器內存、磁盤、CPU。
業務指標:業務和 Service Mesh 的 RT、QPS 等。
業務關聯鏈路:業務上下游的異常情況。
全局的業務指標。
經過這一系列防控設施,可以在單一批次變更內,發現和阻斷全站性的 Service Mesh 變更風險,避免了風險放大。
未來展望
Service Mesh 在快速落地的過程中,遇到并解決了一系列的問題,但同時也要看到還有更多的問題亟待解決。做為下一代云原生化中間件的核心組件之一,Service Mesh 的技術風險能力還需要持續的建議與完善。
未來需要在下述領域持續建設:
大規模高效接入與回滾能力支撐。
更靈活的變更能力,包括業務無感的平滑/非平滑變更能力。
更精準的變更防控能力。
更高效,低噪聲的監控。
更完善的控制面支持。
應用維度的參數定制能力。