運行模式
Spark on MaxCompute支持三種運行方式:Local模式、Cluster模式和DataWorks執(zhí)行模式。
Local模式
Spark on MaxCompute支持用戶以原生Spark Local模式進行作業(yè)調試。
與Yarn Cluster模式類似,您首先需要做以下準備工作:
準備MaxCompute項目以及對應的AccessKey ID、AccessKey Secret。
下載Spark on MaxCompute客戶端。
準備環(huán)境變量。
配置spark-defaults.conf。
下載工程模板并編譯。
上述操作更多信息,請參見搭建Linux開發(fā)環(huán)境。
通過Spark on MaxCompute客戶端以Spark-Submit方式提交作業(yè),代碼示例如下:
## Java/Scala
cd $SPARK_HOME
./bin/spark-submit --master local[4] --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/odps-spark-examples/spark-examples/target/spark-examples-2.0.0-SNAPSHOT-shaded.jar
## PySpark
cd $SPARK_HOME
./bin/spark-submit --master local[4] \
/path/to/odps-spark-examples/spark-examples/src/main/python/odps_table_rw.py注意事項
Local模式讀寫MaxCompute表速度慢,是因為Local模式是通過Tunnel來讀寫的,讀寫速度相比于Yarn Cluster模式慢。
Local模式是在本地執(zhí)行的,部分用戶會經(jīng)常遇到Local模式下可以訪問VPC,但是在Yarn Cluster模式下無法訪問VPC。
Local模式是處于用戶本機環(huán)境,網(wǎng)絡沒有隔離。而Yarn Cluster模式是處于MaxCompute的網(wǎng)絡隔離環(huán)境中,必須要配置VPC訪問相關參數(shù)。
Local模式下訪問VPC的Endpoint通常是外網(wǎng)Endpoint,而Yarn Cluster模式下訪問VPC的Endpoint通常是VPC網(wǎng)絡Endpoint。更多Endpoint信息,請參見Endpoint。
IDEA Local模式下需要將相關配置寫入代碼中,而在Yarn Cluster模式運行時一定要將這些配置從代碼中刪除。
IDEA Local模式執(zhí)行
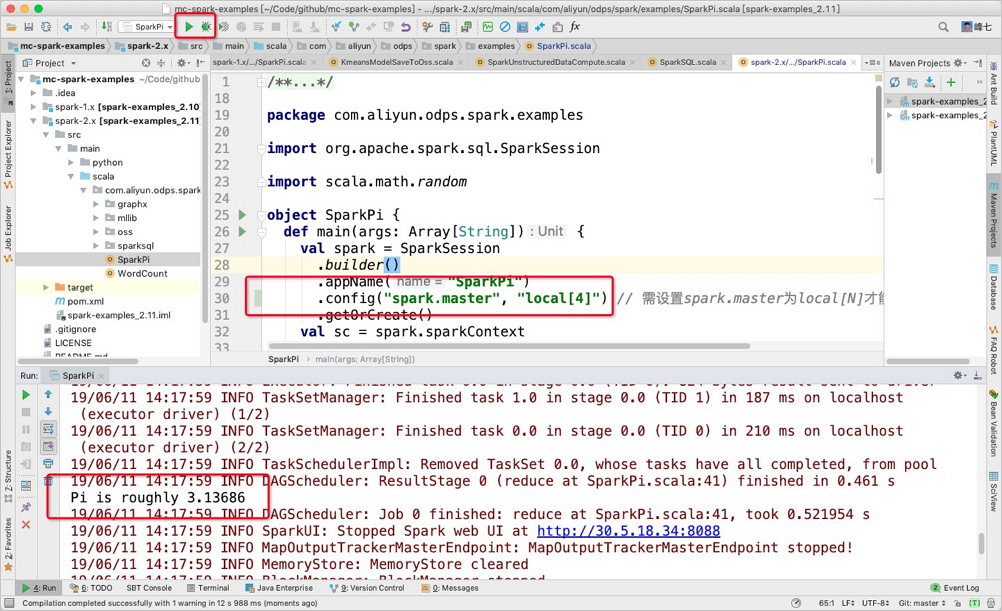
Spark on MaxCompute支持用戶在IDEA中以Local[N]的模式直接運行代碼,而不需要通過Spark on MaxCompute客戶端提交,您需要注意以下兩點:
在IDEA中運行Local模式時,不能直接引用spark-defaults.conf的配置,需要手動指定相關配置,即在
main下創(chuàng)建resource>odps.conf目錄,并在odps.conf中指定相關配置。配置示例如下:說明Spark 2.4.5及以上版本需要在
odps.conf中指定配置項。dops.access.id="" odps.access.key="" odps.end.point="" odps.project.name=""務必注意需要在IDEA中手動添加Spark on MaxCompute客戶端的相關依賴(
jars目錄),否則會出現(xiàn)如下報錯:the value of spark.sql.catalogimplementation should be one of hive in-memory but was odps您可以按照如下流程配置依賴:
在IDEA的頂部菜單欄,選擇。
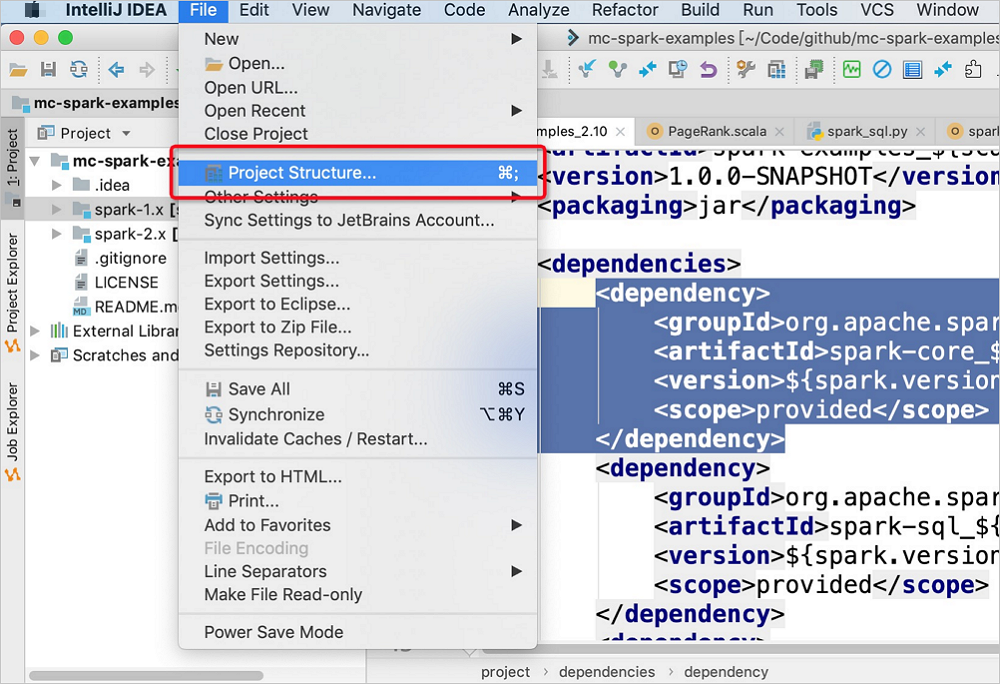
在Project Structure的Modules頁面,選擇目標Spark Module。單擊右側Dependencies后,在左下角單擊
 圖標,選擇JARS or directories...。
圖標,選擇JARS or directories...。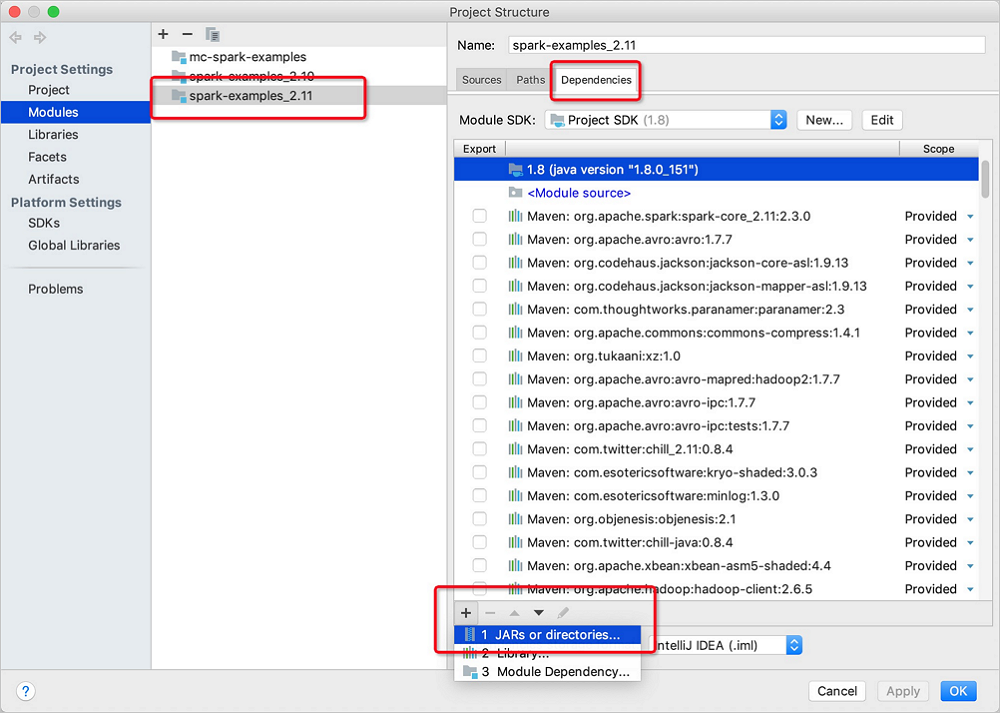
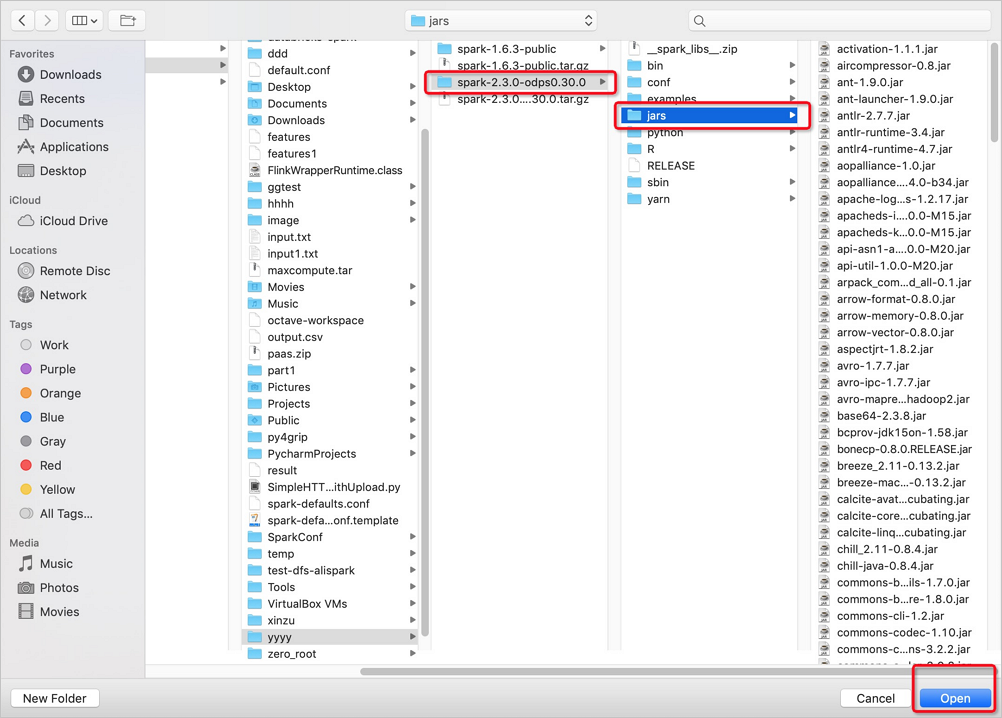
在打開的jars目錄下,選擇Spark on MaxCompute版本及jars,單擊Open。
單擊OK。
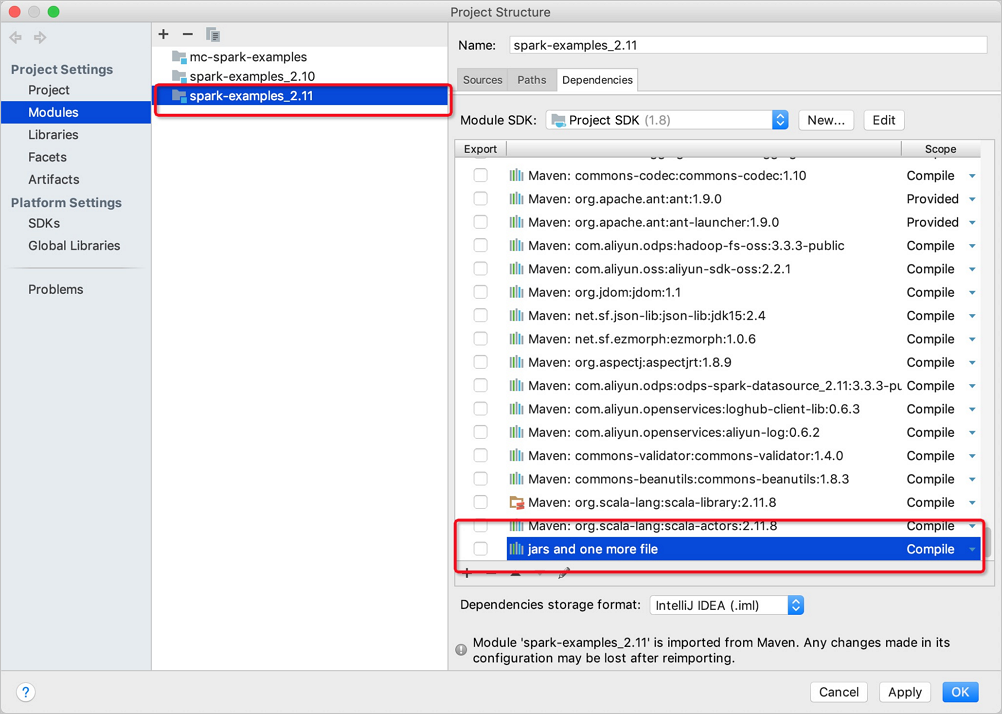
通過IDEA提交作業(yè)。
Cluster模式
在Cluster模式中,您需要指定自定義程序入口main。main結束(Success or Fail)時,對應的Spark作業(yè)就會結束。使用場景適合于離線作業(yè),可與阿里云DataWorks產(chǎn)品結合進行作業(yè)調度,命令行提交方式如下。
# /path/to/MaxCompute-Spark為編譯后的Application JAR包路徑。
cd $SPARK_HOME
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jarDataWorks執(zhí)行模式
您可以在DataWorks中運行Spark on MaxCompute離線作業(yè)(Cluster模式),以方便與其它類型執(zhí)行節(jié)點集成和調度。
操作步驟如下:
您需要在DataWorks的業(yè)務流程中上傳并提交(單擊提交按鈕)資源。
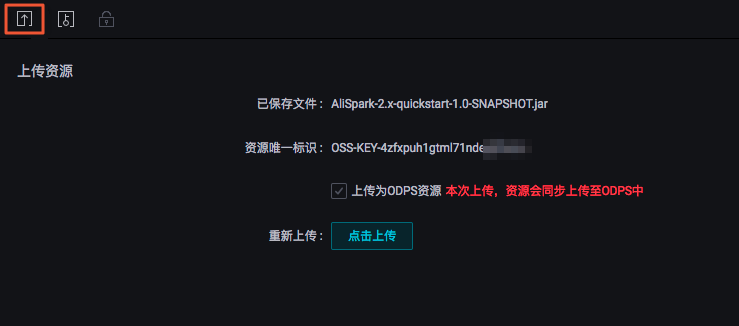
上傳成功如下圖所示。
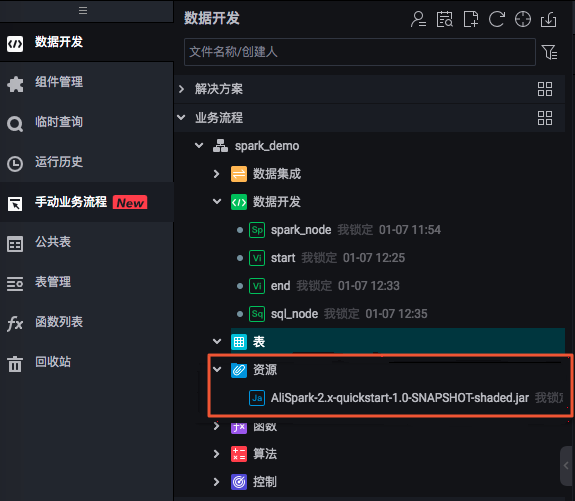
在創(chuàng)建的業(yè)務流程中,從數(shù)據(jù)開發(fā)組件中選擇ODPS Spark節(jié)點。
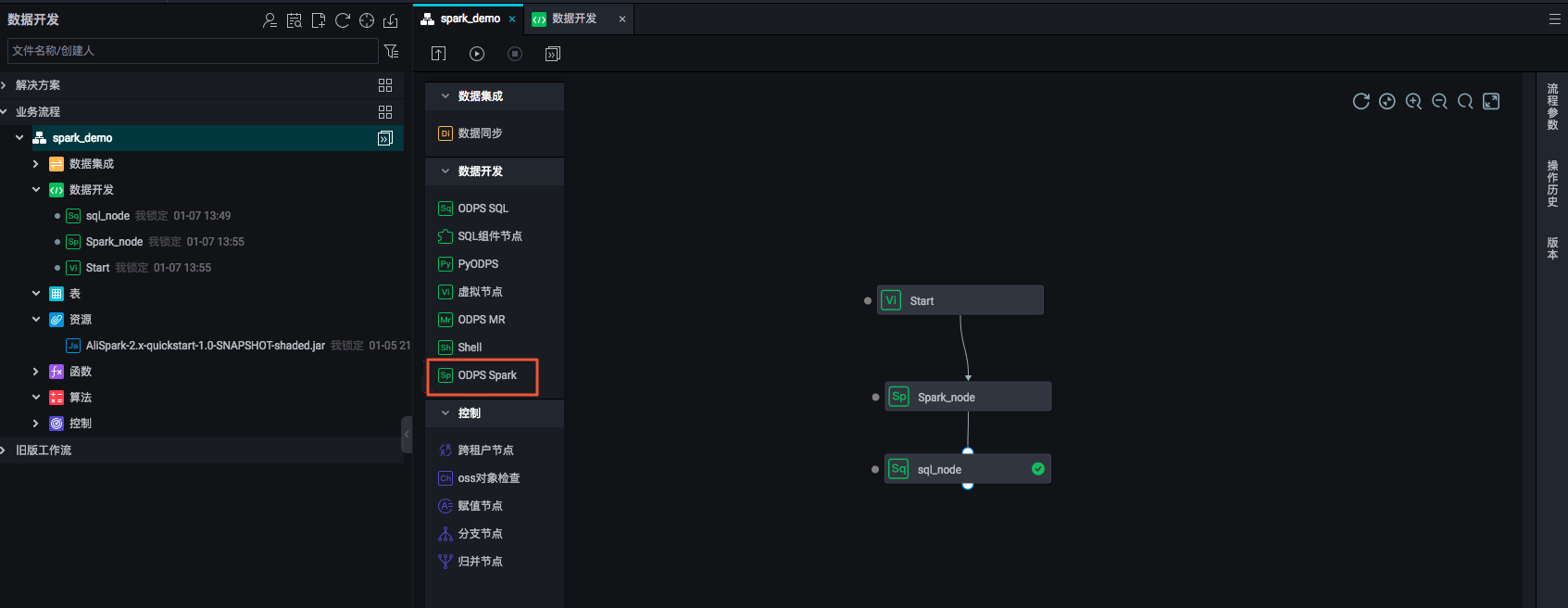
雙擊工作流中的Spark節(jié)點,對Spark作業(yè)進行任務定義。
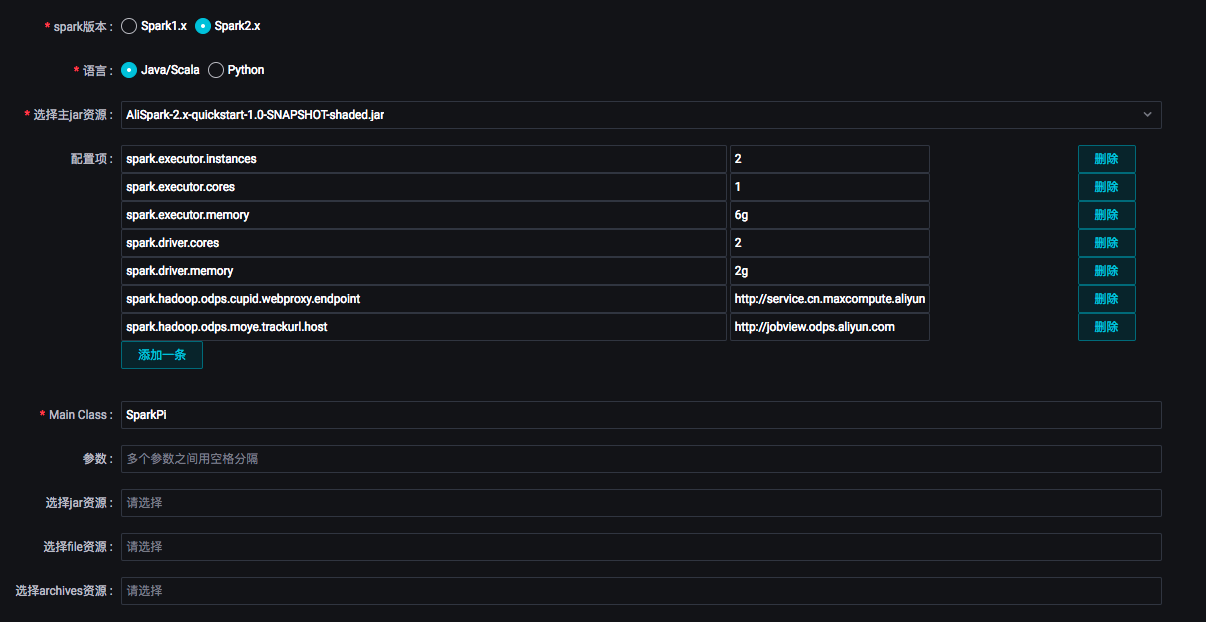 ODPS Spark節(jié)點支持三種spark版本和兩種語言。選擇不同的語言,會顯示相應不同的配置。您可以根據(jù)界面提示進行配置,參數(shù)詳情請參見開發(fā)ODPS Spark任務。其中:
ODPS Spark節(jié)點支持三種spark版本和兩種語言。選擇不同的語言,會顯示相應不同的配置。您可以根據(jù)界面提示進行配置,參數(shù)詳情請參見開發(fā)ODPS Spark任務。其中:選擇主jar資源:指定任務所使用的資源文件。此處的資源文件需要您提前上傳至DataWorks上。
配置項:指定提交作業(yè)時的配置項。
其中
spark.hadoop.odps.access.id、spark.hadoop.odps.access.key和spark.hadoop.odps.end.point無需配置,默認為MaxCompute項目的值(有特殊原因可顯式配置,將覆蓋默認值)。除此之外,
spark-defaults.conf中的配置需要逐條加到ODPS Spark節(jié)點配置項中,例如Executor的數(shù)量、內存大小和spark.hadoop.odps.runtime.end.point的配置。ODPS Spark節(jié)點的資源文件和配置項對應于spark-submit命令的參數(shù)和選項,如下表。此外,您也不需要上傳spark-defaults.conf文件,而是將spark-defaults.conf文件中的配置都逐條加到ODPS Spark節(jié)點配置項中。
ODPS SPARK節(jié)點
spark-submit
主Java、Python資源
app jar or python file配置項
--conf PROP=VALUEMain Class
--class CLASS_NAME參數(shù)
[app arguments]選擇JAR資源
--jars JARS選擇Python資源
--py-files PY_FILES選擇File資源
--files FILES選擇Archives資源
--archives ARCHIVES
手動執(zhí)行Spark節(jié)點,可以查看該任務的執(zhí)行日志,從打印出來的日志中可以獲取該任務的Logview和Jobview的URL,便于進一步查看與診斷。
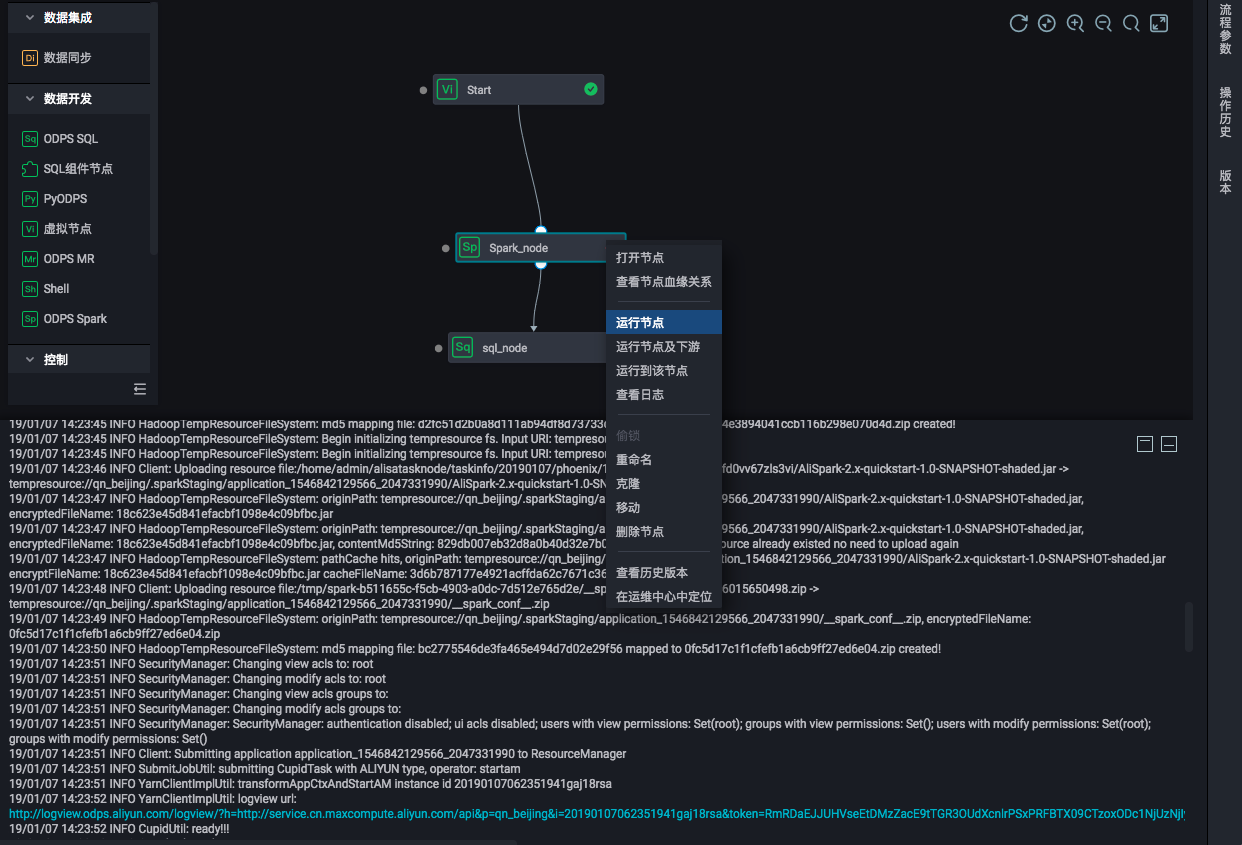
Spark作業(yè)定義完成后,即可在業(yè)務流程中對不同類型服務進行編排、統(tǒng)一調度執(zhí)行。