MaxCompute基于新一代的SQL引擎推出新功能UDT(User Defined Type)。MaxCompute的UDT功能允許您在SQL中直接調用第三方語言的類使用其方法,或直接使用第三方對象獲取其數據內容。
UDT介紹
很多SQL引擎中UDT與MaxCompute的復雜類型STRUCT類似,相比之下,MaxCompute中的UDT與Create Type的概念更類似,Type中包含數據域和方法。MaxCompute不需要用特殊的DDL語法來定義新類型,通過UDT可以在SQL中直接使用新類型。通過如下示例,為您直觀地介紹UDT的功能。
例如,在SQL語句中調用Java的java.lang包。您可以使用以下兩種方法:
通過UDT功能在SQL語句中直接調用java.lang。
--打開新類型,因為下面的操作會用到INTEGER,即INT類型。 set odps.sql.type.system.odps2=true; SELECT java.lang.Integer.MAX_VALUE;和Java語言一樣,java.lang包可以省略,所以上述示例可以簡寫為如下語句。
set odps.sql.type.system.odps2=true; SELECT Integer.MAX_VALUE;輸出結果如下。
+-----------+ | max_value | +-----------+ | 2147483647 | +-----------+使用UDF在SQL語句中調用java.lang。
代碼開發(定義一個UDF的類。)
package com.aliyun.odps.test; public class IntegerMaxValue extends com.aliyun.odps.udf.UDF { public Integer evaluate() { return Integer.MAX_VALUE; } }進行打包、上傳及注冊操作(將上面的UDF編譯,并打成JAR包,然后上傳JAR包,并創建Function。)
add jar odps-test.jar; create function integer_max_value as 'com.aliyun.odps.test.IntegerMaxValue' using 'odps-test.jar';在SQL中調用UDF。
select integer_max_value();
由上例可以看出,UDT簡化了上述一系列的過程,方便您使用其它語言擴展SQL的功能。
應用場景
UDT的常用場景如下:
MaxCompute沒有提供,但可以使用其它語言簡單實現的功能。
例如,只需調用一次Java內置類的方法即可實現,但MaxCompute卻沒有提供簡單的方法實現這個功能。如果使用UDF實現,整個過程會過于繁雜。
SQL中需要調用第三方庫實現相關功能。希望能夠在SQL中直接調用,而不需要再Wrap一層UDF。
SQL中需要直接調用第三方語言源代碼。Select Transform支持把腳本寫到SQL語句中,提升可讀性和代碼易維護性。但是某些語言無法這樣使用,例如Java源代碼必須經過編譯才能執行,通過UDT功能將這些語言也可以直接寫入SQL中。
使用限制
目前版本不支持使用UDF/UDAF/UDT讀取以下場景的表數據:
做過表結構修改(Schema Evolution)的表數據。
包含復雜數據類型的表數據。
包含JSON數據類型的表數據。
Transactional表的表數據。
實現原理
通過以下示例為您介紹UDT的執行過程。
--示例數據。
@table1 := select * from values ('100000000000000000000') as t(x);
@table2 := select * from values (100L) as t(y);
--代碼邏輯。
--new創建對象。
@a := select new java.math.BigInteger(x) x from @table1;
--靜態方法調用。
@b := select java.math.BigInteger.valueOf(y) y from @table2;
--實例方法調用。
select /*+mapjoin(b)*/ x.add(y).toString() from @a a join @b b;
--輸出結果如下所示。
100000000000000000100整個示例的運行過程如下圖所示。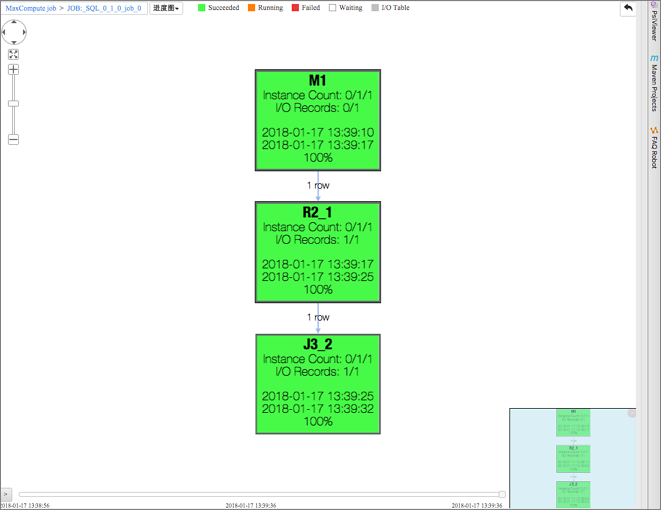
該UDT共有三個Stage:M1、R2和J3。如果您熟悉MapReduce原理即可知道,由于Join的存在需要做數據Reshuffle,所以會出現多個Stage。通常,不同的Stage是在不同的進程、不同的物理機器上運行的。
M1只執行new java.math.BigInteger(x)操作。
J3在不同階段執行了java.math.BigInteger.valueOf(y)和x.add(y).toString()操作。這幾個操作不僅分階段執行,而且在不同的進程、不同的物理機器上執行。UDT把這個過程封裝起來,將這個過程變得看起來和在同一個JVM中執行的效果幾乎一樣。
從上述示例中,您可以看到子查詢的結果允許UDT類型的列。例如上面變量a的x列是java.math.BigInteger類型,而不是內置類型。UDT類型的數據可以被帶到下一個Operator中,再調用其它方法,甚至可以參與數據Shuffle。
功能說明
UDT僅支持Java語言,Java SDK的類都是默認可用的。
說明Runtime使用的JDK版本是JDK1.8,可能不支持更新版本的JDK。
UDT支持您上傳自己的JAR包,并且直接引用。當前提供了一些Flag方便您的使用。
set odps.sql.session.resources指定引用的資源,可以指定多個,用逗號隔開,例如set odps.sql.session.resources=foo.sh,bar.txt;。說明這個Flag和
select transform中指定資源的Flag相同,所以這個Flag會同時影響兩個功能。例如UDT概述中UDF的JAR包,用于UDT使用。set odps.sql.type.system.odps2=true; set odps.sql.session.resources=odps-test.jar; --指定要引用的JAR。這些JAR需要提前上傳至Project,并且需要是JAR類型的資源。 select new com.aliyun.odps.test.IntegerMaxValue().evaluate();odps.sql.session.java.imports指定默認的Java Package,可以指定多個,用逗號隔開。和Java的import語句類似,可以提供完整類路徑,例如java.math.BigInteger,也可以使用*。暫不支持static import。UDT概述中UDF的JAR包,使用UDT功能還有如下寫法。
set odps.sql.type.system.odps2=true; set odps.sql.session.resources=odps-test.jar; set odps.sql.session.java.imports=com.aliyun.odps.test.*; -- 指定默認的Package。 select new IntegerMaxValue().evaluate();
UDT支持資源(Resource)的訪問,您可以在SQL中通過
com.aliyun.odps.udf.impl.UDTExecutionContext.get()靜態方法獲取ExecutionContext對象,從而訪問當前的ExecutionContext,進而訪問資源(例如文件資源和表格資源)。UDT支持的操作:
實例化對象的
new操作。實例化數組的
new操作,包括使用初始化列表創建數組,例如new Integer[] { 1, 2, 3 }。方法調用,包括靜態方法調用。
域訪問,包括靜態域。
說明僅支持公有方法和公有域的訪問。
UDT中的標識符是大小寫敏感的,包括Package、類名、方法名和域名。
暫不支持匿名類和Lambda表達式。
暫不支持無返回值的函數調用(因為UDT均出現在Expression中,沒有返回值的函數調用無法嵌入到Expression中,這個問題在后續的版本中會有解決方案)。
UDT支持的數據類型:
UDT支持類型轉換,支持SQL的風格,例如
cast(1 as java.lang.Object)。但不支持Java風格的類型轉換,例如(Object)1。UDT內置類型與特定Java類型有一一映射關系,詳情請參見Java UDF中的數據類型映射表,這個映射關系對UDT也有效。
內置類型的數據能夠直接調用其映射到的Java類型的方法,例如
'123'.length() , 1L.hashCode()。UDT類型能夠直接參與內置函數或者UDF的運算, 例如
chr(Long.valueOf('100')),其中Long.valueOf返回的是java.lang.Long類型的數據,而內置函數Chr接受的數據類型是內置類型BIGINT。Java的PRIMITIVE類型可以自動轉化為其BOXING類型,并應用前兩條規則。
說明部分內置的新數據類型需要先設置
set odps.sql.type.system.odps2=true;才可使用,否則會報錯。UDT擴展了類型轉換規則:
UDT對象可以被隱式類型轉換為其基類對象。
UDT對象可以被強制類型轉換為其基類或子類對象。
沒有繼承關系的兩個對象之間遵守原來的類型轉換規則,注意這時可能會導致內容的變化。例如
java.lang.Long類型的數據是可以強制轉換為java.lang.Integer的,應用的是內置類型的BIGINT強制轉換為INT的過程,而這個過程會導致數據內容的變化,甚至可能導致精度的損失。
說明目前除隱式類型轉換變成內置類型外,UDT對象不能存儲到硬盤,即不能將UDT對象
INSERT到表中(實際上DDL不支持UDT,不能創建這樣的表)。內置類型支持BINARY,即支持自己實現序列化的過程,將byte[]的數據存儲到硬盤,下次讀出時再還原回來。因此需要您自己調用序列化反序列化方法,將其轉換為BINARY數據類型再存儲到硬盤。屏顯的最終結果不可以是UDT類型。對于屏顯的場景,由于所有的Java類都有
toString()方法,而java.lang.String類型是合法的。所以Debug時,可以用這種方法觀察UDT的內容。您也可以設置
set odps.sql.udt.display.tostring=true;,MaxCompute會自動幫您把所有以UDT為最終輸出的列Wrap上java.util.Objects.toString(...),以方便調試。這個Flag只對屏顯語句生效,對INSERT語句不生效,所以它只在調試的過程中使用。UDT支持比較完整的泛型。例如
java.util.Arrays.asList(new java.math.BigInteger('1')),編譯器可以根據參數類型判斷出該方法的返回值是java.util.List<java.math.BigInteger>類型。說明構造函數需要指定類型參數,否則需要使用
java.lang.Object,這點和Java保持一致。new java.util.ArrayList(java.util.Arrays.asList('1', '2'))的結果是java.util.ArrayList<Object>類型,而new java.util.ArrayList<String>(java.util.Arrays.asList('1', '2'))的結果是java.util.ArrayList<String>類型。
所有的運算符都是MaxCompute SQL的語義,不是UDT的語義。例如:
STRING的相加操作:
String.valueOf(1) + String.valueOf(2)的結果是3(STRING隱式轉換為DOUBLE,并且DOUBLE相加) ,而不是12(Java中STRING相加是Concatenate的語義)。=操作:SQL中的=不是賦值而是判斷相等。而對于Java對象來說,判斷相等應該用Equals方法,而非=操作。
UDT對同一對象的概念是模糊的,這是由數據的Reshuffle導致的。對象有可能會在不同進程、不同物理機器之間傳輸。在傳輸過程中,同一個對象可能分別引用了不同的對象(例如對象先被Shuffle到兩臺機器,然后下次又Shuffle回一起)。 所以在使用UDT時,應該使用
equals方法判斷相等,避免使用=判斷相等。某行某列的對象,其內部包含的各個數據對象的相關性是可以保證的。不同行或者不同列的對象的數據相關性是不保證的。
UDT不能用作Shuffle Key,包括
Join、Group By、Distribute By、Sort By、Order By、Cluster By等結構的Key。UDT可以在Expression中間的任意階段使用,但不能作為最終輸出。例如,不可以使用語句
group by new java.math.BigInteger('123'),但可以使用語句group by new java.math.BigInteger('123').hashCode()。因為hashCode方法的返回值是int.class類型,可以當做內置類型INT來使用(應用上述內置類型與特定Java類型規則)。UDT不僅可以實現Scalar函數的功能,配合內置函數COLLECT_SET和其他函數,UDT還可以實現Aggregator和Table Function功能。
功能優勢
UDT的功能優勢:
使用簡單,無需定義任何函數。
支持JDK的所有功能,擴展了SQL的能力。
代碼可與SQL放于同一文件,便于管理。
可直接使用其它類庫,代碼重用率高。
可以使用面向對象的思想設計某些功能。
后續待完善功能:
支持無返回值的函數調用,或支持(有返回值但忽略返回值)直接取操作數本身的函數調用。例如,調用List的
add方法會返回執行完add操作的List。支持匿名類和Lambda表達式。
支持用作Shuffle Key。
支持Java外的其他語言,例如Python。
性能
因為UDT和UDF的執行過程非常接近,所以UDT與UDF的性能幾乎一致。優化后的計算引擎使得UDT在特定場景下的性能更高。
UDT對象只有在跨進程時才需要做序列化和反序列化,因此在執行不需要數據Reshuffle的操作(如
JOIN或AGGREGATE)時,UDT可節省序列化和反序列化的開銷。因為UDT的Runtime基于Codegen而非反射實現的,所以不存在反射帶來的性能損失。在您使用過程中,連續多個UDT操作會合并在一個FunctionCall里一起執行。例如在之前的示例中,
values[x].add(values[y]).divide(java.math.BigInteger.valueOf(2))實際上只會調用一次UDT。所以,UDT操作的單元雖然較小,卻并不會因多次函數調用而造成額外的接口開銷。
安全性
在安全控制方面,UDT和UDF完全一樣,都會受到Java沙箱Policy的限制。因此如果要使用受限的操作,需要打開沙箱隔離,或者申請沙箱白名單。