本文為您介紹MaxCompute查詢加速MCQA(MaxCompute Query Acceleration)功能,并幫助您了解該功能的系統架構、關鍵特性、應用場景和使用限制。
功能介紹
MaxCompute MCQA功能提供如下能力。
支持對中、小數據量查詢作業進行加速優化,將執行時間為分鐘級的查詢作業縮減至秒級,同時完全兼容原MaxCompute的查詢功能。
支持主流BI工具,開展即席查詢(Ad Hoc)或商業智能(BI)分析。
支持使用獨立的資源池,不占用離線計算資源,可以自動識別查詢作業,緩解排隊壓力,優化使用體驗。
支持將MCQA(MaxCompute Query Acceleration)查詢作業的運行結果寫入臨時緩存中。當用戶后續執行相同的查詢作業時,MaxCompute會優先返回緩存中的結果,加快執行速度。
查詢作業回退為普通SQL作業后,按原SQL作業計費模式計費。
產品架構
MCQA架構圖如下所示。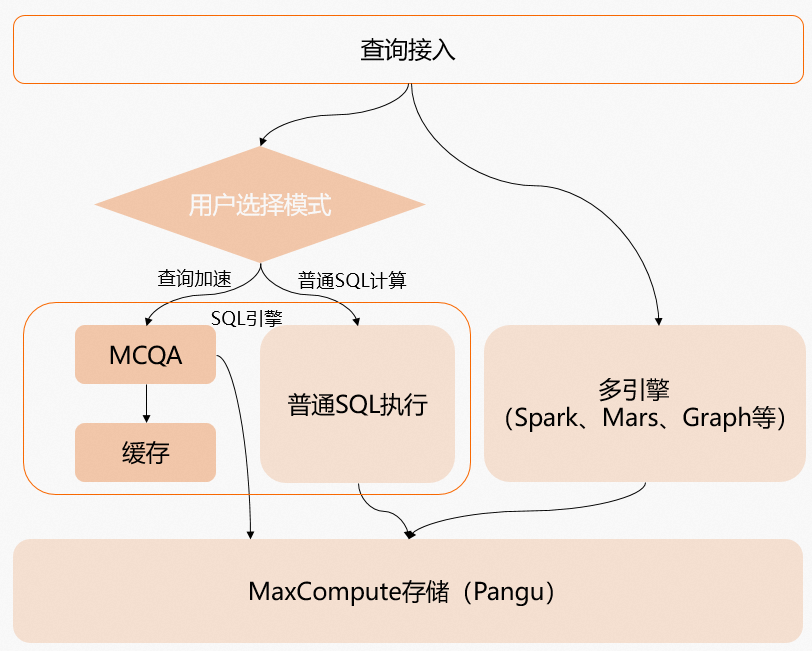
應用場景
MCQA功能的應用場景如下。
場景 | 說明 | 場景特點 |
即席查詢(Ad Hoc) | 您可以通過MCQA優化中小規模數據集(百GB規模內)的查詢性能,直接對MaxCompute表開展低時延的查詢操作,以便快速完成數據開發及數據分析。 | 您可以根據實際需求,靈活選擇查詢條件,快速獲取查詢結果并調整查詢邏輯。對查詢時延的要求在幾十秒內。使用者通常為掌握SQL技能的數據開發或數據分析師,希望使用熟悉的客戶端工具開展查詢分析。 |
商業智能(BI) | 利用MaxCompute搭建企業級數據倉庫時,ETL會將數據加工處理為面向業務可消費的聚合數據。借助MCQA的低延時、彈性并發、數據緩存等特性,結合MaxCompute表分區、分桶等優化設計,可以低成本滿足多并發、快速響應的報告生成、統計分析及固定報表分析需求。 | 查詢的數據對象通常為聚合后的結果數據,適用于數據量較小、多維查詢、固定查詢、高頻查詢場景。查詢延時要求高,秒級返回(例如大部分查詢不超過5秒,不同查詢作業由于數據規模和查詢復雜度不同,查詢時間有較大差異)。 |
海量數據明細查詢分析 | MCQA可以自動識別查詢作業特征,既能快速響應,處理小規模作業,同時還可以自動匹配大規模作業資源需求,滿足分析人員分析不同規模和復雜度的查詢作業的需求。 | 需要探索的歷史數據量大、真正需要的有效數據量不大、查詢延時要求適中。使用者通常為業務分析人員,往往需要從明細數據中探尋業務規律,發現業務機會,驗證業務假設。 |
使用限制
僅支持數據查詢(SELECT開頭)語句。如果您提交了MCQA不支持的語句,MaxCompute客戶端、JDBC和SDK可通過配置回退到普通離線模式執行,其他工具暫不支持回退到普通離線模式執行。版本要求如下:
默認最大查詢100W行數據,可通過在SQL語句中增加Limit關鍵字突破此限制。
MCQA功能的詳細使用限制如下。
限制項 | 說明 |
功能 |
|
查詢 |
|
查詢并發 |
|
緩存機制
MaxCompute支持將MCQA(MaxCompute Query Acceleration)查詢作業的運行結果寫入臨時緩存中。當用戶后續執行相同的查詢作業時,MaxCompute會優先返回緩存中的結果,加快執行速度。
對于每個MCQA查詢作業,MaxCompute會在內部創建臨時數據集來緩存查詢結果。臨時數據集的所有者即運行查詢作業生成了緩存結果的用戶。臨時數據集對用戶不可見,不支持查看臨時數據集內容。MaxCompute會自動為運行查詢作業的用戶授予對臨時數據集的訪問權限。
出現如下情況時,MaxCompute會刪除緩存結果:
MaxCompute項目的資源使用率較高時,MaxCompute會提前刪除緩存結果。
緩存結果所引用的表或視圖變更后,緩存結果立即失效,MaxCompute會刪除失效的緩存結果。
緩存結果已過期。
使用限制
MCQA查詢結果緩存的使用限制如下:
如果您希望從緩存的查詢結果中檢索數據,執行的查詢作業以及查詢的上下文配置必須與原始查詢作業完全相同。當您運行重復的查詢作業時,MaxCompute會重復使用緩存結果。
緩存的查詢結果中所引用的表或視圖變更后,緩存失效,再次執行相同的查詢作業,不會檢索到緩存數據。
臨時數據集的緩存大小限制為10 GB。
緩存計費規則
緩存的查詢結果不會產生任何存儲及計算費用,可以有效降低資源使用費用。
緩存驗證
您可以獲取查詢作業的Logview信息,并在Job Details頁簽,查看到查詢作業運行結果已寫入緩存中,如下圖示所示。更多獲取Logview信息,請參見使用Logview 2.0查看作業運行信息。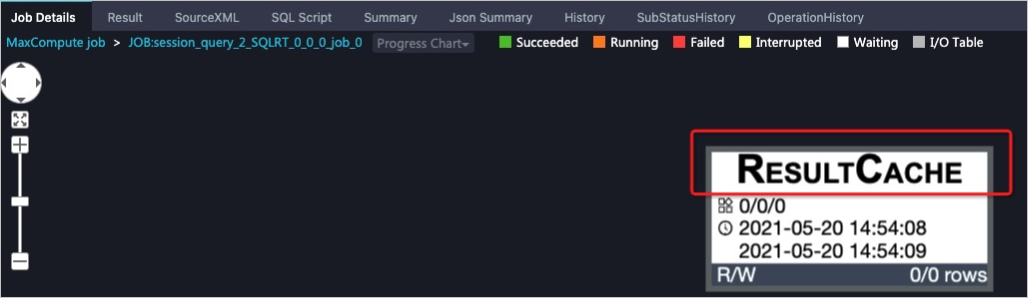
包年包月規格開通MCQA
操作步驟
使用查詢加速功能加速包年包月MaxCompute實例的項目步驟如下。
包年包月MCQA Quota決定了查詢時的掃描并發度,進而影響掃描目標表的數據量,大概比例是1 CU可以掃描0.6 GB數據。例如購買50 CU的MCQA Quota,正常同時掃描數據量在30 GB左右,目前MCQA最大掃描數量可以支持掃描300 GB。
登錄MaxCompute控制臺,在左上角選擇地域。
在左側導航欄,選擇工作區 > 配額(Quota)管理。
在Quota管理頁面,單擊需要配置的一級Quota操作列的Quota配置。
配置Quota模板。
在Quota配置頁面的Quota模板頁簽,單擊新增Quota。
在新增Quota對話框,單擊+添加一項后,填寫Quota名稱和選擇類型。
Quota名稱請自定義輸入,類型選擇交互式。
單擊確定,完成新增MCQA資源組。
配置Quota計劃。
在Quota配置頁面的Quota計劃頁簽,可以單擊添加計劃來創建一個新的計劃,也可以在已有計劃后單擊編輯做編輯操作。
在新建Quota計劃或編輯Quota計劃的對話框中,在MCQA資源組上輸入預留CU量[minCU,maxCU]的值。
輸入預留CU量[minCU,maxCU]的值時注意事項如下。
最小CU數(minCU)需要等于最大CU數(maxCU)。
最小CU數要大于等于
50CU。如果不需要交互式資源,設置為0。交互式類型的Quota不支持彈性預留CU。
單擊確定,完成Quota計劃錄入。
在Quota計劃頁簽,單擊新增或編輯Quota計劃操作列的立即生效
配置時間計劃。
配置時間計劃設置每日不同時間點啟用不同的Quota計劃,以此實現對Quota配置的分時邏輯,配置詳情請參見配置Quota。
調度策略
交互式配額組不支持顯式指定,由服務端根據規則自動進行調度,具體調度策略取決于租戶下的交互式配額組數量:
● 只有一個交互式配額組,則租戶下的所有查詢加速作業都會調度到這個配額組上。
● 如果租戶開通了多個交互式配額組,自動路由規則根據用戶配置進行選擇,詳情請參見Quota規則。
回退策略
如果因使用限制發生查詢加速作業回退為普通查詢作業,包年包月規格下專用于跑MCQA的配額回退為當前Project綁定的配額資源(Quota)。
可通過SDK(版本高于0.40.7)指定回退作業的執行配額資源(Quota)。
SQLExecutorBuilder builder = SQLExecutorBuilder.builder(); builder.quotaName("<OfflineQuotaName>");通過JDBC連接串參數
fallbackQuota=XXX指定回退作業的執行配額資源(Quota)。不允許指定回退作業運行配額為交互式配額組,否則會報錯。
MCQA渠道接入說明
MCQA功能支持的接入方式如下:
MaxCompute客戶端。
DataWorks臨時查詢或數據開發。
JDBC。
SDK。
MaxCompute Studio。
PyODPS。
SQLAlchemy。
基于MaxCompute客戶端啟用MCQA功能
下載最新版MaxCompute客戶端(odpscmd)。
安裝并配置客戶端,詳情請參見安裝并配置MaxCompute客戶端。
修改客戶端安裝目錄conf下的配置文件odps_config.ini,在配置文件最后一行增加如下命令行。
enable_interactive_mode=true --打開MCQA interactive_auto_rerun=true --代表MCQA失敗后自動回退到普通作業執行運行客戶端安裝目錄bin下的MaxCompute客戶端(Linux系統下運行./bin/odpscmd,Windows下運行./bin/odpscmd.bat)。出現如下信息,表示運行成功。
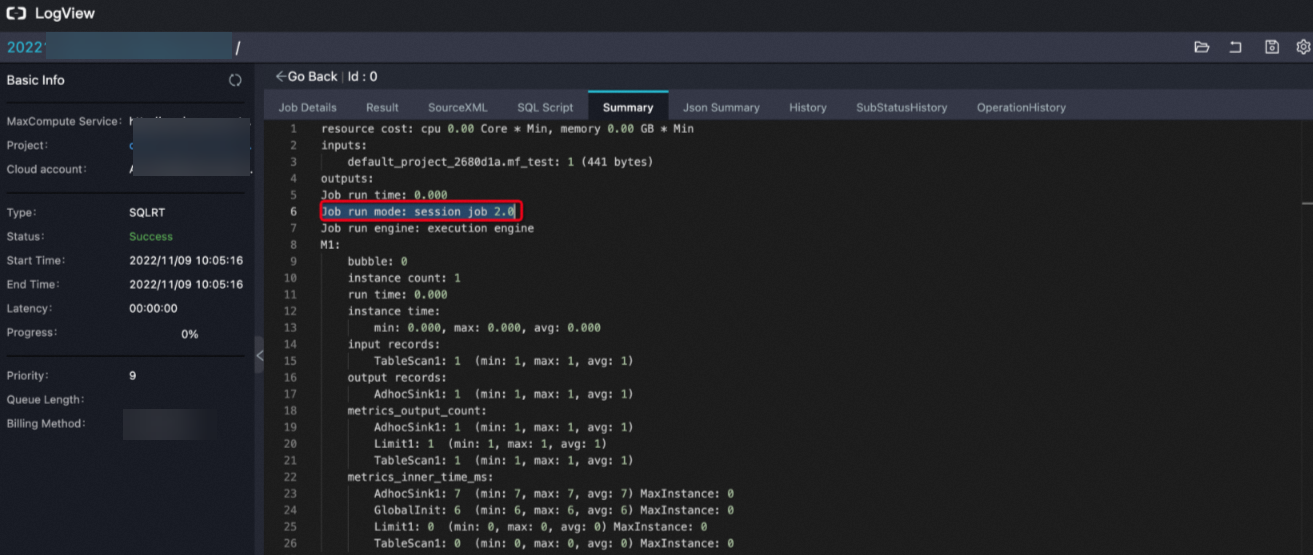
執行查詢作業后,客戶端界面返回結果中的Logview如果包含如下信息表明MCQA功能已開啟。
基于DataWorks臨時查詢或數據開發啟用MCQA功能
DataWorks的臨時查詢及手動業務流程模塊默認開啟MCQA功能,您無需手動開啟。如果您需要關閉MCQA功能,請填寫釘釘群申請表單加入釘釘群進行反饋處理。
在臨時查詢模塊執行查詢作業,如果返回結果包含如下信息表明MCQA功能已開啟。臨時查詢詳情請參見創建臨時查詢。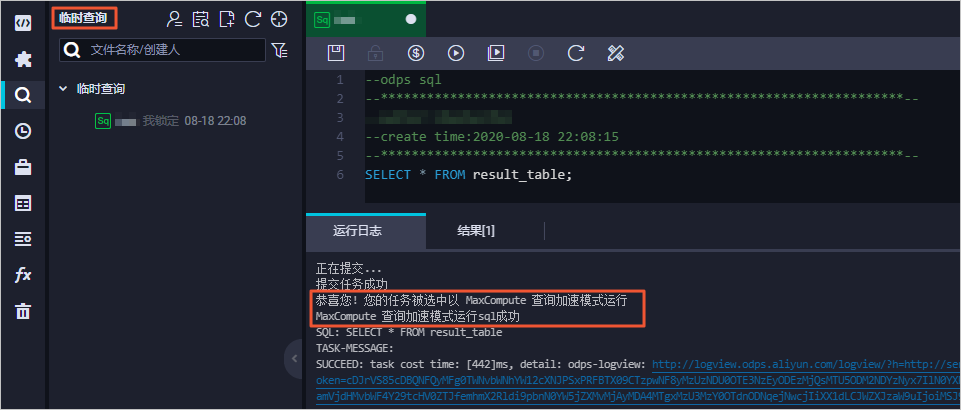
在手動業務流程模塊執行查詢作業,返回結果包含如下信息表明MCQA功能已開啟。手動業務流程詳情請參見創建手動任務。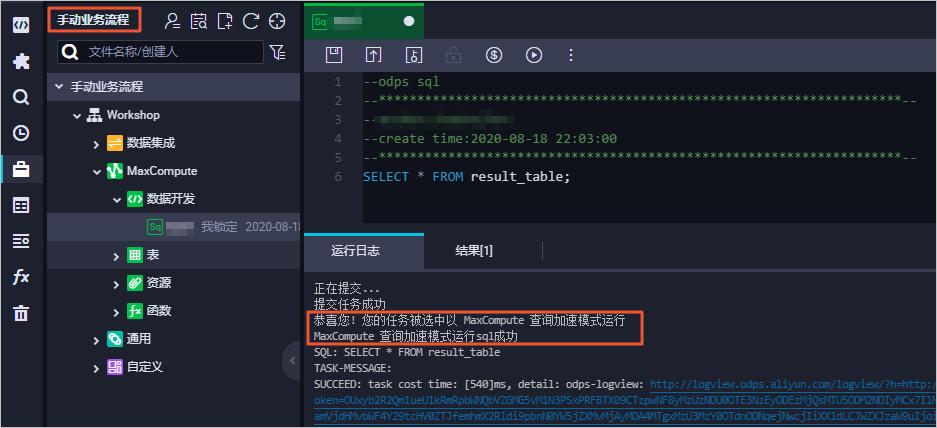
基于JDBC啟用MCQA功能
使用JDBC連接MaxCompute,您可以通過執行如下操作開啟MCQA功能。使用JDBC連接MaxCompute的操作詳情請參見JDBC使用說明。
通過Maven方式配置Pom依賴。
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-jdbc</artifactId> <version>3.3.0</version> <classifier>jar-with-dependencies</classifier> </dependency>基于源代碼創建Java程序,適配實際信息,詳情請參見MaxCompute JDBC,示例如下。
// 阿里云賬號AccessKey擁有所有API的訪問權限,風險很高。強烈建議您創建并使用RAM用戶進行API訪問或日常運維,請登錄RAM控制臺創建RAM用戶 // 此處以把AccessKey 和 AccessKeySecret 保存在環境變量為例說明。您也可以根據業務需要,保存到配置文件里 // 強烈建議不要把 AccessKey 和 AccessKeySecret 保存到代碼里,會存在密鑰泄漏風險 private static String accessId = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"); private static String accessKey = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"); //your_project_name為需要使用MCQA功能的項目名稱。 String conn = "jdbc:odps:http://service.<regionid>.maxcompute.aliyun.com/api?project=<YOUR_PROJECT_NAME>"&accessId&accessKey&charset=UTF-8&interactiveMode=true&alwaysFallback=false&autoSelectLimit=1000000000"; Statement stmt = conn.createStatement(); Connection conn = DriverManager.getConnection(conn, accessId, accessKey); Statement stmt = conn.createStatement(); String tableName = "testOdpsDriverTable"; stmt.execute("DROP TABLE IF EXISTS " + tableName); stmt.execute("CREATE TABLE " + tableName + " (key int, value string)");您可以選擇在連接串中配置如下參數,完善處理邏輯。
參數
說明
enableOdpsLogger
用于打印日志。未配置SLF4J時,建議您配置此參數為True。
fallbackForUnknownError
默認值為False,設置為True時,表示發生未知錯誤時回退到離線模式。
fallbackForResourceNotEnough
默認值為False,設置為True時,表示發生資源不足問題時回退到離線模式。
fallbackForUpgrading
默認值為False,設置為True時,表示升級期間回退到離線模式。
fallbackForRunningTimeout
默認值為False,設置為True時,表示執行超時時回退到離線模式。
fallbackForUnsupportedFeature
默認值為False,設置為True時,表示遇到MCQA不支持的場景時回退到離線模式。
alwaysFallback
默認值為False,設置為True時,表示在以上幾種場景下全部回退到離線模式,僅在JDBC 3.2.3及以上版本支持。
使用示例。
示例1:Tableau上使用MCQA:
服務器增加
interactiveMode=true屬性,用于開啟MCQA功能。建議您同步增加enableOdpsLogger=true屬性,用于打印日志。配置操作詳情請參見配置JDBC使用Tableau。完整的服務器配置示例如下。
http://service.cn-beijing.maxcompute.aliyun.com/api? project=****_beijing&interactiveMode=true&enableOdpsLogger=true&autoSelectLimit=1000000000"如果只對項目空間中的部分表進行Tableau操作,您可以在服務器參數中增加
table_list=table_name1, table_name2屬性選擇需要的表,表之間用半角逗號(,)分隔。如果表過多,會導致Tableau打開緩慢,強烈建議使用此方式只載入需要的表。示例如下,對于有大量分區的表不建議把所有分區的數據都設置成數據源,可以篩選需要的分區或通過自定義SQL獲取需要的數據。http://service.cn-beijing.maxcompute.aliyun.com/api?project=****_beijing &interactiveMode=true&alwaysFallback=true&enableOdpsLogger=true&autoSelectLimit=1000000000" &table_list=orders,customers示例2:SQLWorkBench使用MCQA。
完成JDBC驅動配置后,在Profile配置界面修改已填寫的JDBC URL,支持SQLWorkbench使用MCQA功能。Profile配置操作詳情請參見配置JDBC使用SQL Workbench/J。
需要配置的URL格式如下所示:
jdbc:odps:<MaxCompute_endpoint>? project=<MaxCompute_project_name>&accessId=<AccessKey ID>&accessKey=<AccessKey Secret> &charset=UTF-8&interactiveMode=true&autoSelectLimit=1000000000"參數說明如下。
參數
說明
MaxCompute_endpoint
MaxCompute服務所在區域的Endpoint,詳情請參見Endpoint。
MaxCompute_project_name
MaxCompute項目空間名稱。
AccessKey ID
有訪問指定項目空間權限的AccessKey ID。
您可以進入AccessKey管理頁面獲取AccessKey ID。
AccessKey Secret
AccessKey ID對應的AccessKey Secret。
您可以進入AccessKey管理頁面獲取AccessKey Secret。
charset=UTF-8
字符集編碼格式。
interactiveMode
MCQA功能開關,
true表示開啟MCQA功能。autoSelectLimit
數據量超過100萬限制時,需要配置此參數。
基于Java SDK啟用MCQA功能
Java SDK詳情請參見Java SDK介紹。您需要通過Maven配置Pom依賴,配置示例如下。
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-core</artifactId>
<version>3.3.0</version>
</dependency>創建Java程序,命令示例如下。
import com.aliyun.odps.Odps;
import com.aliyun.odps.OdpsException;
import com.aliyun.odps.OdpsType;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.data.ResultSet;
import com.aliyun.odps.sqa.*;
import java.io.IOException;
import java.util.*;
public class SQLExecutorExample {
public static void SimpleExample() {
// 設置賬號和項目信息。
// 阿里云賬號AccessKey擁有所有API的訪問權限,風險很高。強烈建議您創建并使用RAM用戶進行API訪問或日常運維,請登錄RAM控制臺創建RAM用戶
// 此處以把AccessKey 和 AccessKeySecret 保存在環境變量為例說明。您也可以根據業務需要,保存到配置文件里
// 強烈建議不要把 AccessKey 和 AccessKeySecret 保存到代碼里,會存在密鑰泄漏風險
Account account = new AliyunAccount(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"));
Odps odps = new Odps(account);
odps.setDefaultProject("<YOUR_PROJECT_NAME>");
odps.setEndpoint("http://service.<regionid>.maxcompute.aliyun.com/api");
// 準備構建SQLExecutor。
SQLExecutorBuilder builder = SQLExecutorBuilder.builder();
SQLExecutor sqlExecutor = null;
try {
// run in offline mode or run in interactive mode
if (false) {
// 創建一個默認執行離線SQL的Executor。
sqlExecutor = builder.odps(odps).executeMode(ExecuteMode.OFFLINE).build();
} else {
// 創建一個默認執行查詢加速SQL的Executor,并且在查詢加速模式失敗后,自動回退到離線查詢。
sqlExecutor = builder.odps(odps).executeMode(ExecuteMode.INTERACTIVE).fallbackPolicy(FallbackPolicy.alwaysFallbackPolicy()).build();
}
// 如果需要的話可以傳入查詢的特殊設置。
Map<String, String> queryHint = new HashMap<>();
queryHint.put("odps.sql.mapper.split.size", "128");
// 提交一個查詢作業,支持傳入Hint。
sqlExecutor.run("select count(1) from test_table;", queryHint);
// 列舉一些支持的常用獲取信息的接口。
// UUID
System.out.println("ExecutorId:" + sqlExecutor.getId());
// 當前查詢作業的logview。
System.out.println("Logview:" + sqlExecutor.getLogView());
// 當前查詢作業的Instance對象(Interactive模式多個查詢作業可能為同一個Instance)。
System.out.println("InstanceId:" + sqlExecutor.getInstance().getId());
// 當前查詢作業的階段進度(Console的進度條)。
System.out.println("QueryStageProgress:" + sqlExecutor.getProgress());
// 當前查詢作業的執行狀態變化日志,例如回退信息。
System.out.println("QueryExecutionLog:" + sqlExecutor.getExecutionLog());
// 提供兩種獲取結果的接口。
if(false) {
// 直接獲取全部查詢作業結果,同步接口,可能會占用本線程直到查詢成功或失敗。
// 一次性讀取全部結果數據到內存中,當數據量較大時不建議使用,可能會有內存問題。
List<Record> records = sqlExecutor.getResult();
printRecords(records);
} else {
// 獲取查詢結果的迭代器ResultSet,同步接口,可能會占用本線程直到查詢成功或失敗。
// 獲取大量結果數據時推薦使用,分次讀取查詢結果。
ResultSet resultSet = sqlExecutor.getResultSet();
while (resultSet.hasNext()) {
printRecord(resultSet.next());
}
}
// run another query
sqlExecutor.run("select * from test_table;", new HashMap<>());
if(false) {
// 直接獲取全部查詢結果,同步接口,可能會占用本線程直到查詢成功或失敗。
// 一次性讀取全部結果數據到內存中,當數據量較大時不建議使用,可能會有內存問題。
List<Record> records = sqlExecutor.getResult();
printRecords(records);
} else {
// 獲取查詢結果的迭代器ResultSet,同步接口,可能會占用本線程直到查詢成功或失敗。
// 獲取大量結果數據時推薦使用,分次讀取查詢結果。
ResultSet resultSet = sqlExecutor.getResultSet();
while (resultSet.hasNext()) {
printRecord(resultSet.next());
}
}
} catch (OdpsException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (sqlExecutor != null) {
// 關閉Executor釋放相關資源。
sqlExecutor.close();
}
}
}
// SQLExecutor can be reused by pool mode
public static void ExampleWithPool() {
// 設置賬號和項目信息。
// 阿里云賬號AccessKey擁有所有API的訪問權限,風險很高。強烈建議您創建并使用RAM用戶進行API訪問或日常運維,請登錄RAM控制臺創建RAM用戶
// 此處以把AccessKey 和 AccessKeySecret 保存在環境變量為例說明。您也可以根據業務需要,保存到配置文件里
// 強烈建議不要把 AccessKey 和 AccessKeySecret 保存到代碼里,會存在密鑰泄漏風險
Account account = new AliyunAccount(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"));
Odps odps = new Odps(account);
odps.setDefaultProject("your_project_name");
odps.setEndpoint("http://service.<regionid>.maxcompute.aliyun.com/api");
// 通過連接池方式執行查詢。
SQLExecutorPool sqlExecutorPool = null;
SQLExecutor sqlExecutor = null;
try {
// 準備連接池,設置連接池大小和默認執行模式。
SQLExecutorPoolBuilder builder = SQLExecutorPoolBuilder.builder();
builder.odps(odps)
.initPoolSize(1) // init pool executor number
.maxPoolSize(5) // max executors in pool
.executeMode(ExecuteMode.INTERACTIVE); // run in interactive mode
sqlExecutorPool = builder.build();
// 從連接池中獲取一個Executor,如果不夠將會在Max限制內新增Executor。
sqlExecutor = sqlExecutorPool.getExecutor();
// Executor具體用法和上一示例一致。
sqlExecutor.run("select count(1) from test_table;", new HashMap<>());
System.out.println("InstanceId:" + sqlExecutor.getId());
System.out.println("Logview:" + sqlExecutor.getLogView());
List<Record> records = sqlExecutor.getResult();
printRecords(records);
} catch (OdpsException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
sqlExecutor.close();
}
sqlExecutorPool.close();
}
private static void printRecord(Record record) {
for (int k = 0; k < record.getColumnCount(); k++) {
if (k != 0) {
System.out.print("\t");
}
if (record.getColumns()[k].getType().equals(OdpsType.STRING)) {
System.out.print(record.getString(k));
} else if (record.getColumns()[k].getType().equals(OdpsType.BIGINT)) {
System.out.print(record.getBigint(k));
} else {
System.out.print(record.get(k));
}
}
}
private static void printRecords(List<Record> records) {
for (Record record : records) {
printRecord(record);
System.out.println();
}
}
public static void main(String args[]) {
SimpleExample();
ExampleWithPool();
}
}基于MaxCompute Studio啟用MCQA功能
V3.5.0及以上版本的MaxCompute Studio插件支持MCQA功能,推薦您安裝最新版本的MaxCompute Studio插件。安裝MaxCompute Studio插件的操作詳情請參見安裝MaxCompute Studio。
您在MaxCompute Studio的SQL編輯器中,選擇帶查詢加速功能的SQL執行模式查詢加速或加速失敗重跑后,執行查詢語句即可啟用查詢加速功能。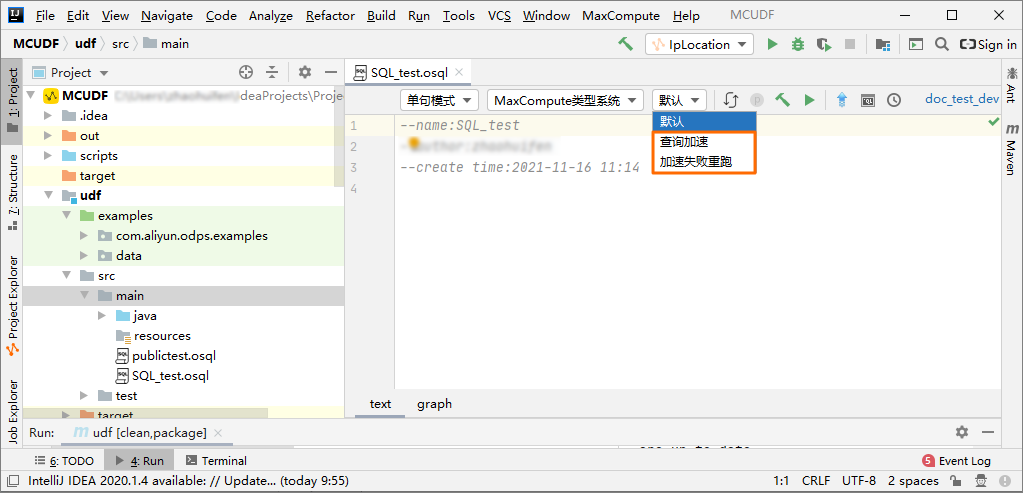
查詢加速:使用查詢加速功能執行SQL查詢語句。
加速失敗重跑:使用查詢加速功能執行SQL查詢語句失敗后,回退到離線模式(即默認模式)執行SQL查詢語句。
基于PyODPS使用MCQA功能
execute_sql_interactive(fallback='all')
PyODPS從V0.11.4.1版本開始支持以execute_sql_interactive(fallback='all')方法通過MCQA執行SQL,并返回MCQA Instance。
如果MCQA無法執行相應的SQL,會自動回退到傳統模式。此時,函數返回的Instance為回退后的Instance。
o.execute_sql_interactive('SELECT * FROM dual', fallback='all')如果不希望回退,可以指定參數fallback=False。也可以指定為回退策略(或回退策略的組合,使用逗號分隔的字符串)。可用的策略名如下,默認策略為unsupported,upgrading,noresource,timeout。
回退策略 | 描述 |
generic | 指定時,表示發生未知錯誤時回退到傳統模式。 |
noresource | 指定時,表示發生資源不足問題時回退到傳統模式。 |
upgrading | 指定時,表示升級期間回退到傳統模式。 |
timeout | 指定時,表示執行超時時回退到傳統模式。 |
unsupported | 指定時,表示遇到MCQA不支持的場景時回退到傳統模式。 |
例如,下述代碼要求在MCQA不支持和資源不足時回退:
o.execute_sql_interactive('SELECT * FROM dual', fallback="noresource,unsupported")基于PyODPS,使用SQLAlchemy或其他支持SQLAlchemy接口的第三方工具實現查詢加速
PyODPS集成了SQLAlchemy,可以使用SQLAlchemy查詢MaxCompute數據。您需要在連接串中指定如下參數實現查詢加速:
interactive_mode=true:必填。查詢加速功能總開關。reuse_odps=true:可選。打開強制復用連接,對于部分第三方工具(例如Apache Superset),打開此選項可提高性能。
您可以在連接串中配置fallback_policy=<policy1>,<policy2>,...參數,完善處理邏輯。與JDBC的配置項類似,控制加速失敗的回退行為。
generic:默認為False,設置為True時,表示發生未知錯誤時回退到離線模式。noresource:默認為False,設置為True時,表示發生資源不足問題時回退到離線模式。upgrading:默認為False,設置為True時,表示升級期間回退到離線模式。timeout:默認為False,設置為True時,表示執行超時時回退到離線模式。unsupported:默認為False,設置為True時,表示遇到MCQA不支持的場景時回退到離線模式。default:等同于同時指定unsupported、upgrading、noresource和timeout。如果連接串中未指定fallback_policy,則此項為默認值。all:默認為False,設置為True時,表示在以上幾種場景下全部回退到離線模式,僅在JDBC 3.2.3及以上版本才支持。
例如,打開查詢加速,打開強制復用鏈接,在查詢加速功能尚未支持、升級中和資源不足時回退到離線模式的連接串如下。
odps://<access_id>:<ACCESS_KEY>@<project>/?endpoint=<endpoint>&interactive_mode=true&reuse_odps=true&fallback_policy=unsupported,upgrading,noresource常見問題
問題一:使用JDBC鏈接MaxCompute,執行包年包月資源的SQL任務時報錯(ODPS-1800001),詳細報錯信息如下。
sError:com.aliyun.odps.OdpsException: ODPS-1800001: Session exception - Failed to submit sub-query in session because:Prepaid project run out of free query quota.可能原因:
您當前使用了查詢加速(MCQA)功能,當前查詢加速功能正在公測中,如果您已購買包年包月套餐,公測期間,無需進行額外操作,即可免費體驗查詢加速功能。免費體驗查詢加速時,單個MaxCompute項目支持的最大作業并發數為5,日免費加速作業數累計為500個。如果作業數超過500個時,會出現上述報錯。
解決方法:
您需要在配置JDBC啟用MCQA功能的配置過程中,設置alwaysFallback參數值為true,設置完成后,沒有超過500個作業數時,能正常使用MCQA進行查詢加速,超過500個的作業會退回至離線模式。配置的詳細操作及參數解釋請參見MCQA渠道接入說明。
問題二:基于PyODPS發送請求并獲取結果的時長比DataWorks長。
可能原因:
使用了
wait_for_xxx方法,延長了時間。輪詢間隔時間長。
解決方法:
請求本身運行很快的情況下,不使用
wait_for_xxx方法,發出請求后直接使用Tunnel下載結果。調低輪詢間隔:
instance.wait_for_success(interval=0.1)。命令示例如下。from odps import ODPS, errors max_retry_times = 3 def run_sql(odps, stmt): retry = 0 while retry < max_retry_times: try: inst = odps.run_sql_interactive(stmt) print(inst.get_logview_address()) inst.wait_for_success(interval=0.1) records = [] for each_record in inst.open_reader(tunnel=True): records.append(each_record) return records except errors.ODPSError as e: retry = retry + 1 print("Error: " + str(e) + " retry: " + str(retry) + "/" + str(max_retry_times)) if retry >= max_retry_times: raise e odps = ODPS(...) run_sql(odps, 'SELECT 1')
問題三:基于SDK如何使用Logview排查Java SDK報錯?
解決方法:MaxCompute Java SDK提供了Logview接口,請使用如下命令調用Logview接口獲取日志。
String logview = sqlExecutor.getLogView();問題四:基于JDBC如何獲取MaxCompute Logview URL?
解決方法:MaxCompute JDBC Driver是基于MaxCompute Java SDK的封裝。因此使用時和MaxCompute客戶端、MaxCompute Studio以及DataWorks一樣,通過MaxCompute JDBC Driver執行SQL時,會生成Logview URL。您可以通過Logview查看任務執行狀態、追蹤任務進度、獲取任務執行結果。Logview URL可以通過配置日志輸出(properties.log4j),默認以標準輸出打印到終端屏幕。