數(shù)據(jù)實時入倉實踐
為滿足業(yè)務(wù)對數(shù)據(jù)倉庫中高度時效性數(shù)據(jù)的需求,MaxCompute基于Delta Table實現(xiàn)了分鐘級近實時數(shù)據(jù)寫入和主鍵更新功能,顯著提升了數(shù)據(jù)倉庫的數(shù)據(jù)更新效率。
數(shù)據(jù)寫入場景
面對具有突發(fā)性和熱點性的客戶行為日志,如評論、評分和點贊,傳統(tǒng)的關(guān)系型數(shù)據(jù)庫和離線數(shù)據(jù)分析方法在處理這類數(shù)據(jù)時可能存在資源消耗大、成本高、數(shù)據(jù)延遲以及更新復(fù)雜的問題,通常只能滿足次日分析需求。
針對上述問題,您可以采用近實時數(shù)倉數(shù)據(jù)入倉方案,可以在分鐘級別內(nèi)實現(xiàn)數(shù)據(jù)增量同步到Delta Table,從而將數(shù)據(jù)寫入到查詢的延遲控制在5~10分鐘,極大地提高了數(shù)據(jù)分析的時效性。如果您的生產(chǎn)任務(wù)是將數(shù)據(jù)同步至MaxCompute ODS(Operational Data Store)層的普通表,為避免生產(chǎn)任務(wù)改造的風(fēng)險,您可以使用Delta Table的Upsert功能,它能有效將數(shù)據(jù)同步至Delta Table,同時防止數(shù)據(jù)重復(fù)存儲,并提高存儲效率和降低存儲成本。

示例
Flink數(shù)據(jù)寫入Delta Table
本文以第三方引擎Flink為例,介紹了Flink集成MaxCompute Flink Connector進行近實時寫入數(shù)據(jù)至Delta Table的主要流程。
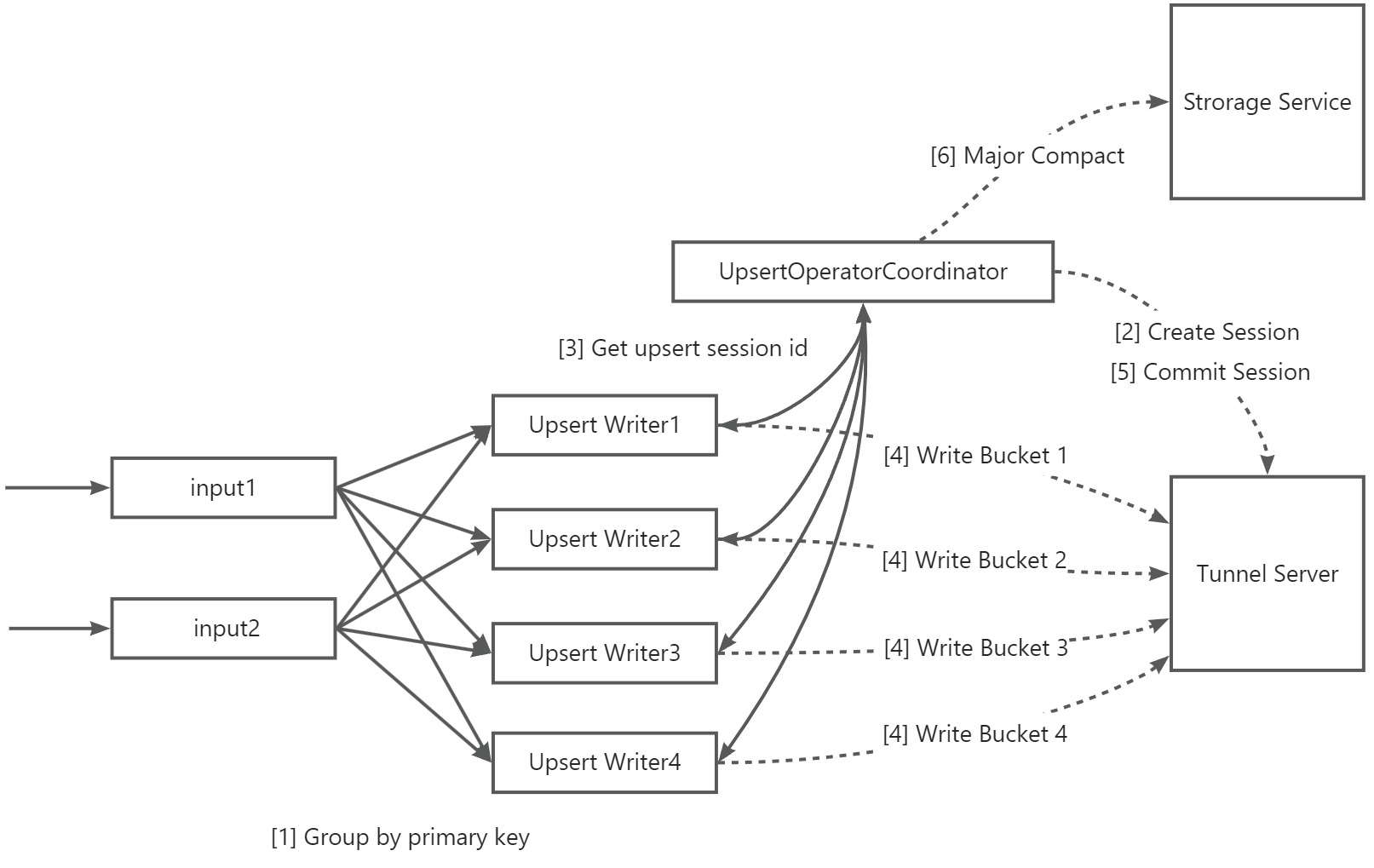
介紹如下:
序號 | 說明 |
【1】 | 支持按照數(shù)據(jù)的Primary Key列進行分組并發(fā)寫入。 若您的并發(fā)寫入的分區(qū)較多,且每個分區(qū)數(shù)據(jù)分布均勻,同時表的Bucket數(shù)量較少(如個位數(shù)),那么您也可以根據(jù)Partition列進行分組寫入,有助于提高寫入吞吐量。 |
【2】 | UpsertWriterTask收到數(shù)據(jù)后,會解析數(shù)據(jù)所屬分區(qū)并向UpsertOperatorCoordinator發(fā)起請求,然后創(chuàng)建分區(qū)實時寫入的Upsert Session。 |
【3】 | UpsertOperatorCoordinator向UpsertWriterTask返回已創(chuàng)建的Upsert session。 |
【4】 | UpsertWriterTask根據(jù)Upsert Session創(chuàng)建Upsert Writer,并連接MaxCompute的數(shù)據(jù)傳輸通道服務(wù)Tunnel Server,將數(shù)據(jù)持續(xù)寫入。 在數(shù)據(jù)傳輸過程中,若啟用了文件緩存,數(shù)據(jù)將會先進入Flink本地磁盤的緩存區(qū),直到數(shù)據(jù)文件大小達到特定閾值或Checkpoint流程啟動后,才將數(shù)據(jù)傳輸至Tunnel Server。 |
【5】 | Checkpoint流程啟動后,Upsert Writer將數(shù)據(jù)全量提交至Tunnel Server,再向UpsertOperatorCoordinator發(fā)起請求,觸發(fā)Commit操作,成功后數(shù)據(jù)可見。 |
【6】 | 若開啟自動Major Compact,當分區(qū)Commit次數(shù)超過特定閾值時,由UpsertOperatorCoordinator向Storage Service發(fā)起Major compact操作。 說明 根據(jù)表數(shù)據(jù)量大小,此操作可能會對實時數(shù)據(jù)導(dǎo)入造成延時,因此需要謹慎使用。 |
將Flink數(shù)據(jù)寫入至MaxCompute Delta Table的操作,詳情請參見使用Flink寫入數(shù)據(jù)到Delta Table。
Upsert寫入?yún)?shù)配置建議
您可以通過調(diào)整Upsert實時寫入場景的配置參數(shù)來提高系統(tǒng)吞吐量和性能,并確保穩(wěn)定性,以滿足不同的業(yè)務(wù)需求。Upsert寫入?yún)?shù)詳情,請參見Upsert寫入?yún)?shù)。
通用關(guān)鍵參數(shù)配置
表Bucket數(shù)量可影響同時寫入的最大并發(fā)數(shù),在一定程度上決定了最大寫入吞吐,推薦按照1 M/s * 表Bucket數(shù)量來計算總吞吐。
實際能達到的吞吐量與Sink節(jié)點并發(fā)等參數(shù)相關(guān)。詳情請參見表格式和數(shù)據(jù)治理。
sink.parallelism:數(shù)據(jù)寫入的Sink節(jié)點并發(fā)數(shù),強烈建議表Bucket數(shù)量是該配置值的整數(shù)倍,可達到較好的性能效果。當sink.parallelism參數(shù)值與表Bucket數(shù)量一致時,理論上可以實現(xiàn)最佳性能。
非分區(qū)表提升吞吐的參數(shù)配置
如果設(shè)置了sink parallelism參數(shù)以增加寫入并發(fā),但發(fā)現(xiàn)吞吐量并未提升,可能的問題在于Sink節(jié)點的上游數(shù)據(jù)處理鏈路效率低下,建議您可優(yōu)化數(shù)據(jù)處理鏈路來提高整體性能。
若表Bucket的數(shù)量是sink.parallelism的整數(shù)倍,那單個Sink節(jié)點寫入的Bucket數(shù)量 = 表Bucket數(shù)量 ÷ sink.parallelism,若Bucket值過大,也會影響性能。建議您優(yōu)先調(diào)整表Bucket數(shù)量和sink.parallelism參數(shù)值。若upsert.writer.buffer-size ÷ 單節(jié)點Bucket數(shù)量低于特定閾值(如128 K)時,可能會導(dǎo)致網(wǎng)絡(luò)傳輸效率降低。為改善網(wǎng)絡(luò)性能,建議考慮增大upsert.writer.buffer-size。
upsert.flush.concurrent參數(shù):默認值為2,表示可并發(fā)flush的Bucket數(shù)。為了優(yōu)化吞吐量,可以適當增加該值以觀察性能提升。
說明需要注意的是,如果此值設(shè)置得過大,可能會導(dǎo)致過多的Bucket同時發(fā)送,從而引起網(wǎng)絡(luò)擁堵,反而會使整體吞吐量下降。因此,在調(diào)整這個參數(shù)時需要謹慎,找到一個平衡點以確保系統(tǒng)的穩(wěn)定和高效運行。
少量分區(qū)并發(fā)寫入提升吞吐的參數(shù)配置
在此場景下,您可以參考通用關(guān)鍵參數(shù)配置和非分區(qū)表參數(shù)配置建議。同時,您還可以參考以下內(nèi)容。
單個Sink節(jié)點在寫入數(shù)據(jù)時涉及多個分區(qū)的操作,同時在Checkpoint階段,每個分區(qū)需要獨立進行Commit操作,這些特性可能會對整體的寫入吞吐量產(chǎn)生影響。
單個Sink節(jié)點Buffer數(shù)據(jù)的最大內(nèi)存=upsert.writer.buffer-size * 分區(qū)數(shù),因此如果發(fā)生內(nèi)存溢出(OOM),建議調(diào)整upsert.writer.buffer-size參數(shù),減小其值以防止內(nèi)存超出限制。
增加upsert.commit.thread-num參數(shù)值,可減少checkpoint階段Commit的耗時。此參數(shù)默認值為16,意味著有16個線程并發(fā)處理分區(qū)進行Commit操作。
說明盡管可以適當增加這個數(shù)值以提高性能,但要注意不應(yīng)超過32,以防止過度并發(fā)可能導(dǎo)致的問題。
海量分區(qū)并發(fā)寫入(FileCached模式)提升吞吐的參數(shù)配置
在此場景下,您可以參考少量分區(qū)并發(fā)寫入?yún)?shù)配置建議。同時,您還可以參考以下內(nèi)容:
每個分區(qū)的數(shù)據(jù)都會首先緩存在本地文件中,然后在Checkpoint階段并發(fā)寫入MaxCompute中。
sink.file-cached.writer.num參數(shù)默認值為16,增加該參數(shù)值(不建議超過32),可增加單個Sink節(jié)點并發(fā)寫入的分區(qū)數(shù)量。建議并發(fā)寫入的Bucket數(shù)量建議等于sink.file-cached.writer.num * upsert.flush.concurrent。但需注意此值不應(yīng)設(shè)置得過大,以防止引發(fā)網(wǎng)絡(luò)擁堵問題,從而導(dǎo)致整體吞吐量下降。
FileCached模式寫入?yún)?shù)詳情,請參見FileCached模式寫入?yún)?shù)。
其他建議
如果參考以上參數(shù)建議都無法達到吞吐要求,或者吞吐不穩(wěn)定,需考慮以下因素:
每個項目空間可免費使用的公共數(shù)據(jù)傳輸服務(wù)資源組是有限的,達到上限后,會Block數(shù)據(jù)寫入,從而導(dǎo)致整體吞吐下降。如果數(shù)據(jù)寫入吞吐較大,同時對延時要求比較高,建議購買獨享數(shù)據(jù)傳輸服務(wù)資源組,確保資源供給。
Connector的上游數(shù)據(jù)處理鏈路效率低下,導(dǎo)致整體吞吐率不高。建議您優(yōu)化數(shù)據(jù)處理鏈路,以提高整體性能。
常見問題
Flink相關(guān)問題
問題一:
問題現(xiàn)象:提示出現(xiàn)報錯信息“Checkpoint xxx expired before completing”。
問題原因:Checkpoint流程超時,通常由于Checkpoint過程中寫入的分區(qū)數(shù)過多。
解決措施:
建議調(diào)整Flink Checkpoint時間,增加其時間間隔。
配置sink.file-cached.enable參數(shù),開啟文件緩存模式。詳情請參見附錄:新版Flink Connector全量參數(shù)。
問題二:
問題現(xiàn)象:提示出現(xiàn)報錯信息“org.apache.flink.util.FlinkException: An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency. ”。
問題原因:通常由于JobManager與TaskManager通信異常導(dǎo)致,任務(wù)會自動發(fā)起重試。
解決措施:建議提升任務(wù)資源來確保任務(wù)穩(wěn)定性。
數(shù)據(jù)寫入問題
問題一:
問題現(xiàn)象:TIMESTAMP類型的數(shù)據(jù)在寫入MaxCompute后,時間偏移了8小時。
問題原因:Flink中的TIMESTAMP類型不包含時區(qū)信息,且在MaxCompute寫入過程中也不會進行時區(qū)轉(zhuǎn)換,因此數(shù)據(jù)會被視為零時區(qū)數(shù)據(jù)。然而,MaxCompute在讀取這些數(shù)據(jù)時,會根據(jù)項目的時區(qū)設(shè)定對數(shù)據(jù)進行轉(zhuǎn)換。
解決措施:使用TIMESTAMP_LTZ類型替換MaxCompute Sink Table中的TIMESTAMP類型。
Tunnel相關(guān)問題
問題一:
問題現(xiàn)象:數(shù)據(jù)寫入時出現(xiàn)Tengine相關(guān)報錯,報錯信息內(nèi)容如下。
<body> <h1>An error occurred.</h1> <p>Sorry, the page you are looking for is currently unavailable.<br/> Please try again later.</p> <p>If you are the system administrator of this resource then you should check the <a >error log</a> for details.</p> <p><em>Faithfully yours, tengine.</em></p> </body> </html>問題原因:遠程Tunnel服務(wù)暫時不可用。
解決措施:等待Tunnel服務(wù)恢復(fù)后任務(wù)可以自動重試成功。
問題二:
問題現(xiàn)象:提示出現(xiàn)報錯信息“java.io.IOException: RequestId=xxxxxx, ErrorCode=SlotExceeded, ErrorMessage=Your slot quota is exceeded.”。
問題原因:寫入Quota超出限制,需要降低寫入并發(fā),或者增加獨享Tunnel并發(fā)數(shù)。
解決措施:
降低寫入并發(fā),以減少對系統(tǒng)資源的占用。
增加獨享Tunnel并發(fā)數(shù),通過提升處理能力來適應(yīng)更高的數(shù)據(jù)寫入需求。購買獨享資源詳情,請參見購買與使用獨享數(shù)據(jù)傳輸服務(wù)資源組。