本文介紹如何通過MaxCompute實現GitHub近實時數據同步以及增全量數據一體化分析。
方案概述
基于GitHub Archive公開數據集,通過DataWorks數據集成、FlinkCDC和Flink等多種實時數據寫入方式,將GitHub中的項目、行為等超過十種事件類型的數據實時采集至MaxCompute進行增全量更新。借助MCQA 2.0的資源隔離能力,同時構建批處理資源組(QuotaA組)與交互式資源組(QuotaB組),從而實現MaxCompute中增全量數據的寫入與更新,并同時進行交互式查詢分析。此外,通過使用TopConsole和DataWorks Notebook,從開發者、項目和編程語言等多個維度,對GitHub實時數據的變化情況進行深入分析與挖掘。
方案架構與優勢
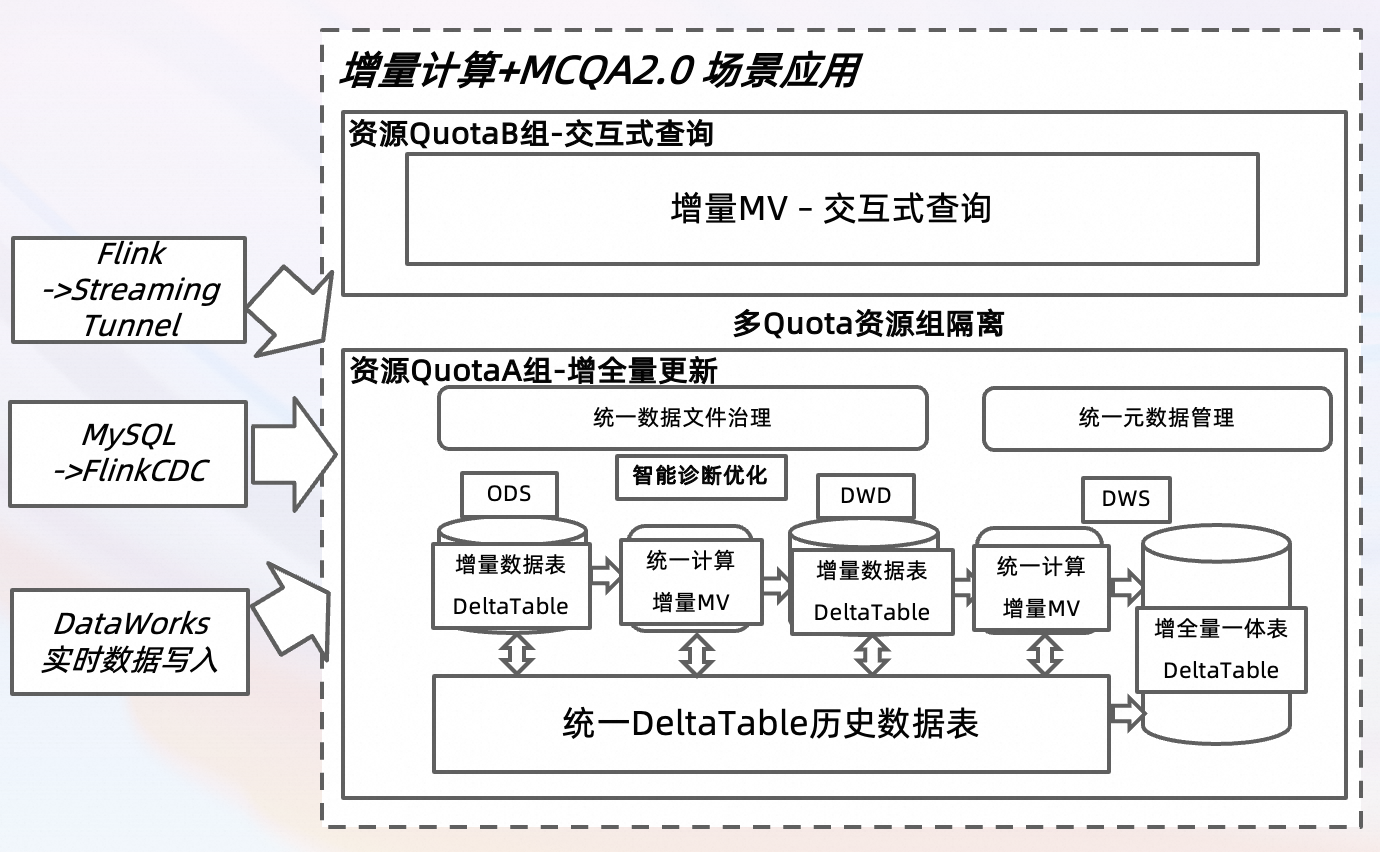
以上圖示基于典型數據分析場景設計,可以滿足當日近實時數據的寫入以及歷史離線數據的更新與查詢分析場景。
實現增全量數據的統一校正(包括數據聚合、去重和反作弊等),定期將全量數據回寫至DWD,并對應地更新DWS和ADS的增量MV。通過FlinkCDC和DataWorks實時數據集成,將數據寫入Delta Table的增量數據表,實現增量查詢與更新。
實現交互式數據查詢(DWS/ADS層),支持增量物化視圖(MV)在DWS和ADS中自動刷新,以確保數據的時效性。同時,與TopConsole和DataWorks對接,以便進行數據查詢和展示。
借助MCQA 2.0查詢加速引擎,在資源隔離架構下配置不同的Quota組,以分別支持增量數據計算和交互式查詢分析場景。
近實時數倉-Delta Table增量表格式
針對分鐘級或者小時級的近實時數據處理疊加海量數據批處理的場景,MaxCompute基于Delta Table的統一表格式特性,提供近實時的增全量一體的數據存儲和計算解決方案,支持分鐘級數據實時Upsert寫入和TimeTravel數據回溯等能力。其核心特性包括:
支持近實時寫入,并且能夠實現Checkpoint間隔達到分鐘級別以內。
支持SQL近實時查詢(Incremental Query),且在完成寫入后,可在分鐘級別內進行查詢。
通過StorageService、AutoCompaction和AutoSorting功能,實現對數據文件的自動管理。
近實時數倉-增量計算&增量物化視圖(Incremental MV)
MaxCompute的增量計算結合了CDC和Stream增量查詢能力,使用戶可以通過自定義SQL來構建自己的增量數據處理鏈路。增量物化視圖(MV)可有效地構建增量計算模型,用戶只需使用聲明式SQL表達預期的數據結果,便可通過配置不同的刷新參數來指定刷新頻率或數據新鮮度,后臺引擎將自動進行增量刷新和內部優化,從而實現近實時數據分析Pipeline。其主要核心特性包括:
聲明式SQL。
增量與全量數據一體化,支持統一的SQL、存儲和計算。
增量物化視圖(MV)支持智能Pipeline編排 。
增量CDC應用,支持周期性任務及流處理特性。
數據新鮮度,提供實時或自定義的增量數據刷新。公式為:
MV(T1) = delta(T0, T1) + MV(T0)。
近實時數倉-MCQA2.0查詢加速
MaxCompute的MCQA2.0查詢加速引擎旨在滿足對性能、隔離性以及穩定性有更高要求的業務需求。它構建類似Virtual Warehouse的資源隔離管理引擎,從而顯著提升了交互式查詢的性能。支持租戶級獨占計算資源,使用多線程Pipeline執行,以充分利用精準獨享的計算資源管理。此外,還支持全鏈路的Cache能力,全類型的SQL作業、屏顯作業以及DDL、DML作業等特性。
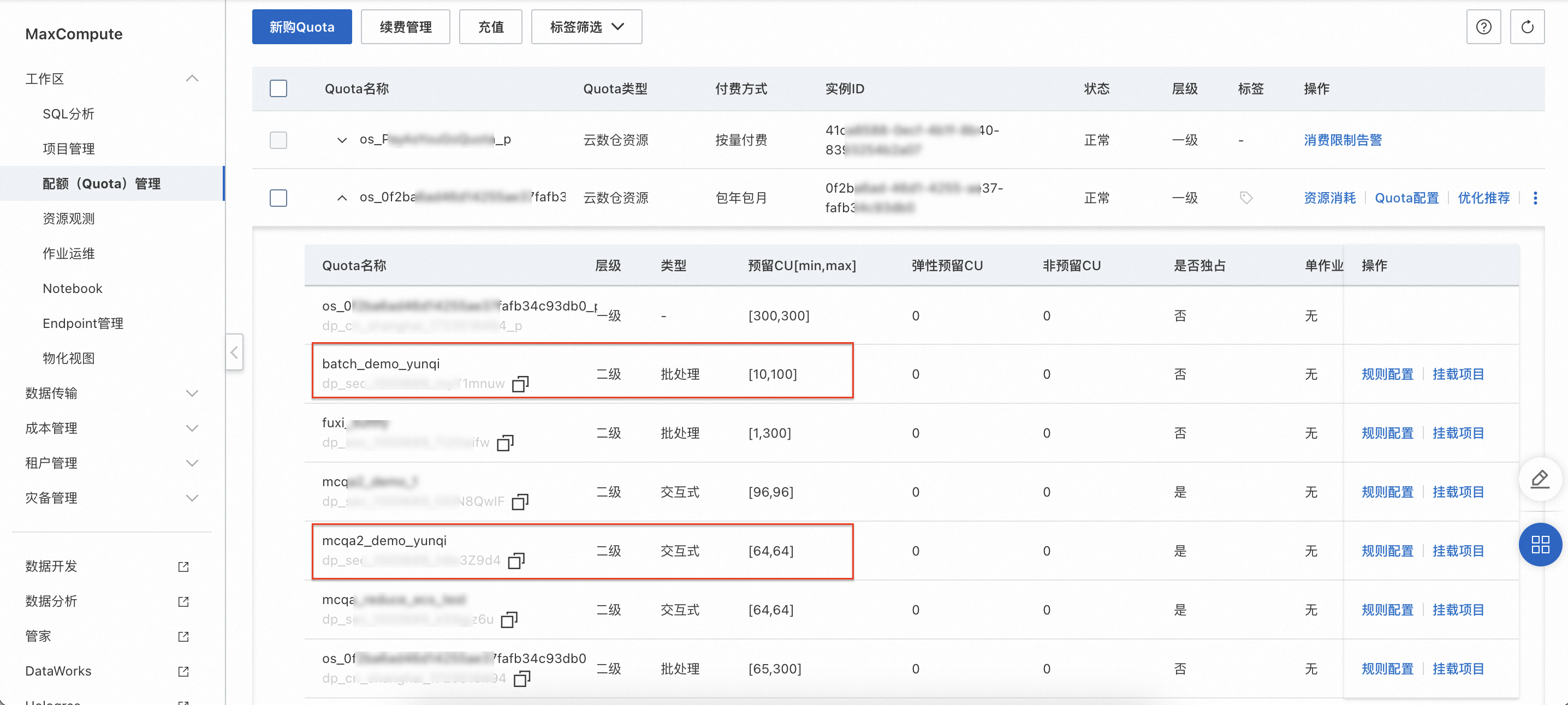
支持單租戶環境下構建多Quota組進行資源隔離,并支持對Quota組進行交互式查詢。
支持分時資源的分組管理。
交互式查詢性能加速,與上一版本相比,性能提升1倍。
操作視頻
操作步驟
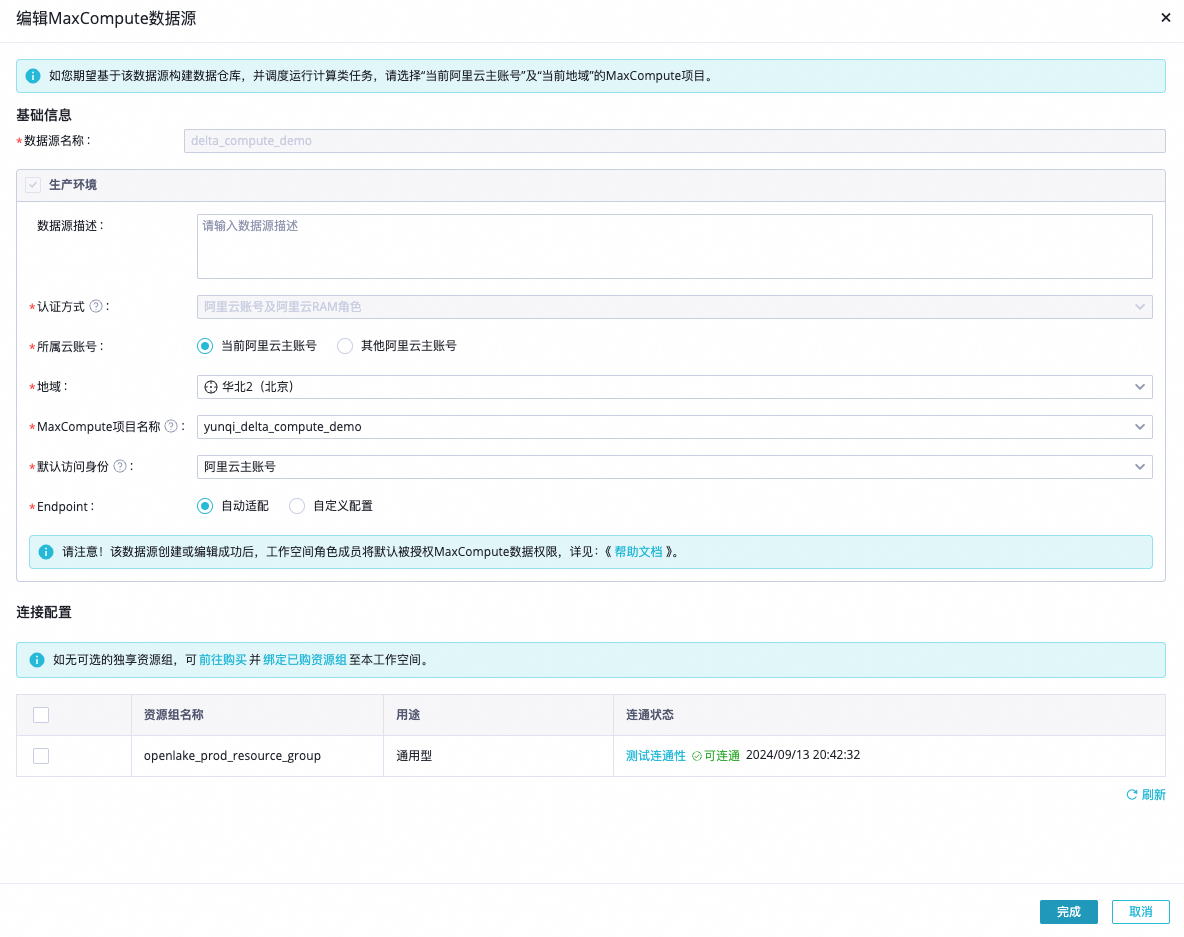
步驟一:MaxCompute項目準備
步驟 | 操作 | 預期結果 |
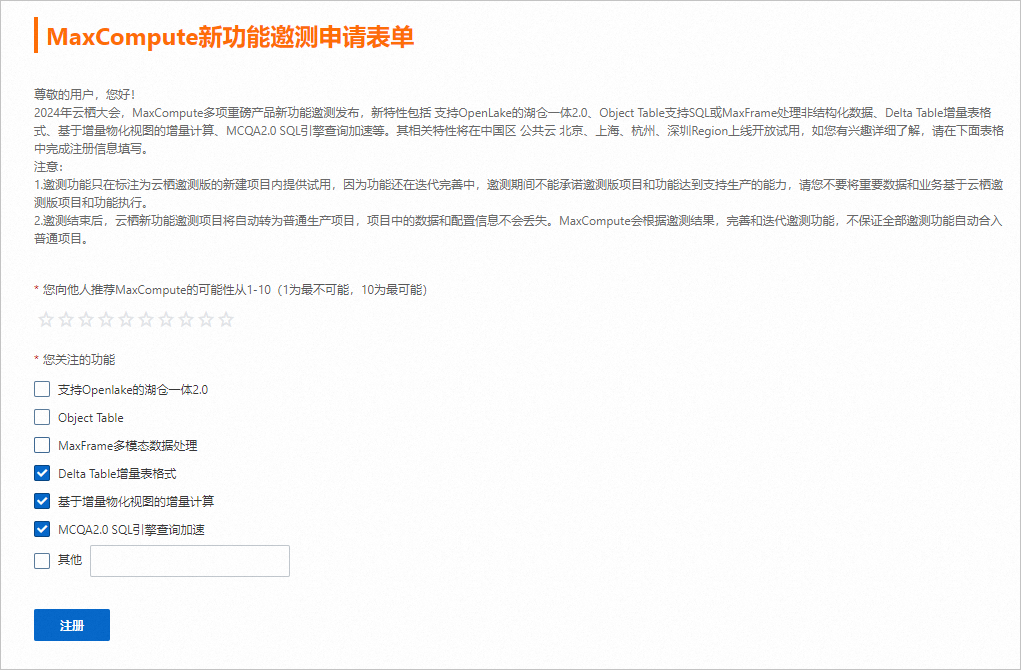
Step 0 注冊MaxCompute新功能邀測申請表單 |
| 開通MaxCompute新功能。 |
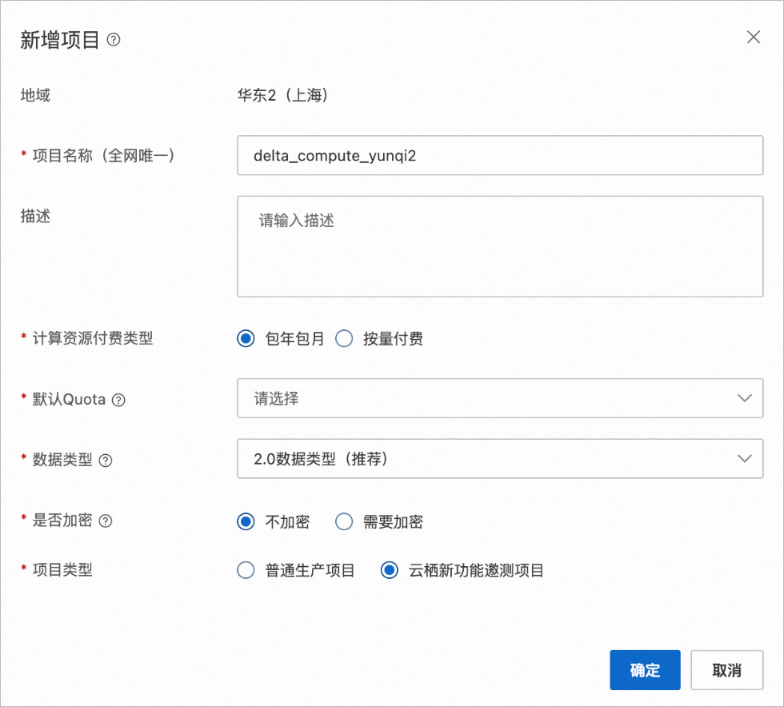
Step 1 初始化MaxCompute新項目 |
|
|
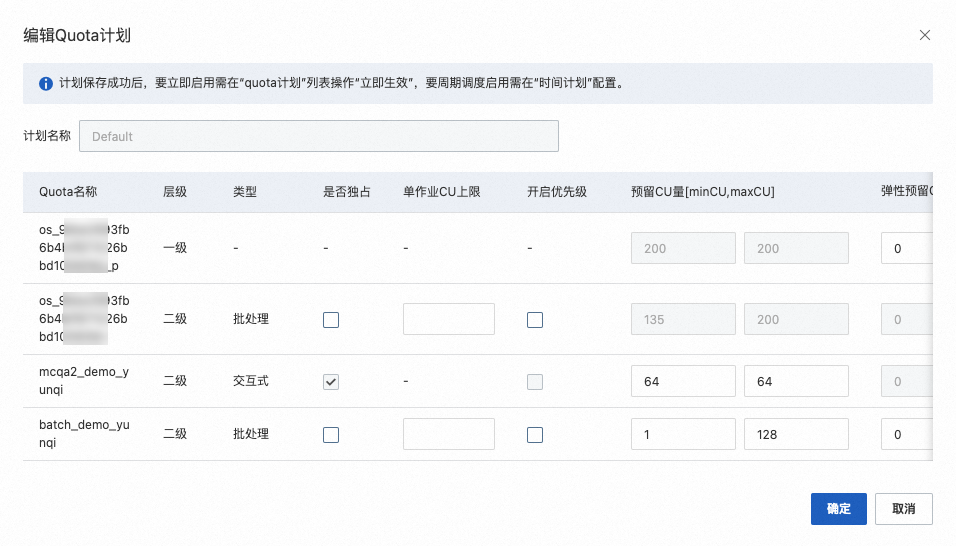
Step 2 配額(Quota)管理上新購Quota |
| 在配額(Quota)管理頁面,確認批處理Quota組和交互式Quota組已成功創建。 |
Step 3 新建MaxCompute Delta Table增量表 | 在SQL分析頁面,執行如下示例命令,創建2個MaxCompute內部表:
| 在SQL分析頁面,選擇項目
|


步驟二:實時增全量數據寫入
通過FlinkCDC或DataWorks數據集成能力獲取基于GitHub Archive公開實時數據集。
您可以按需選擇以下任意一種方式寫入數據。
Flink CDC
步驟 | 操作 | 預期結果 |
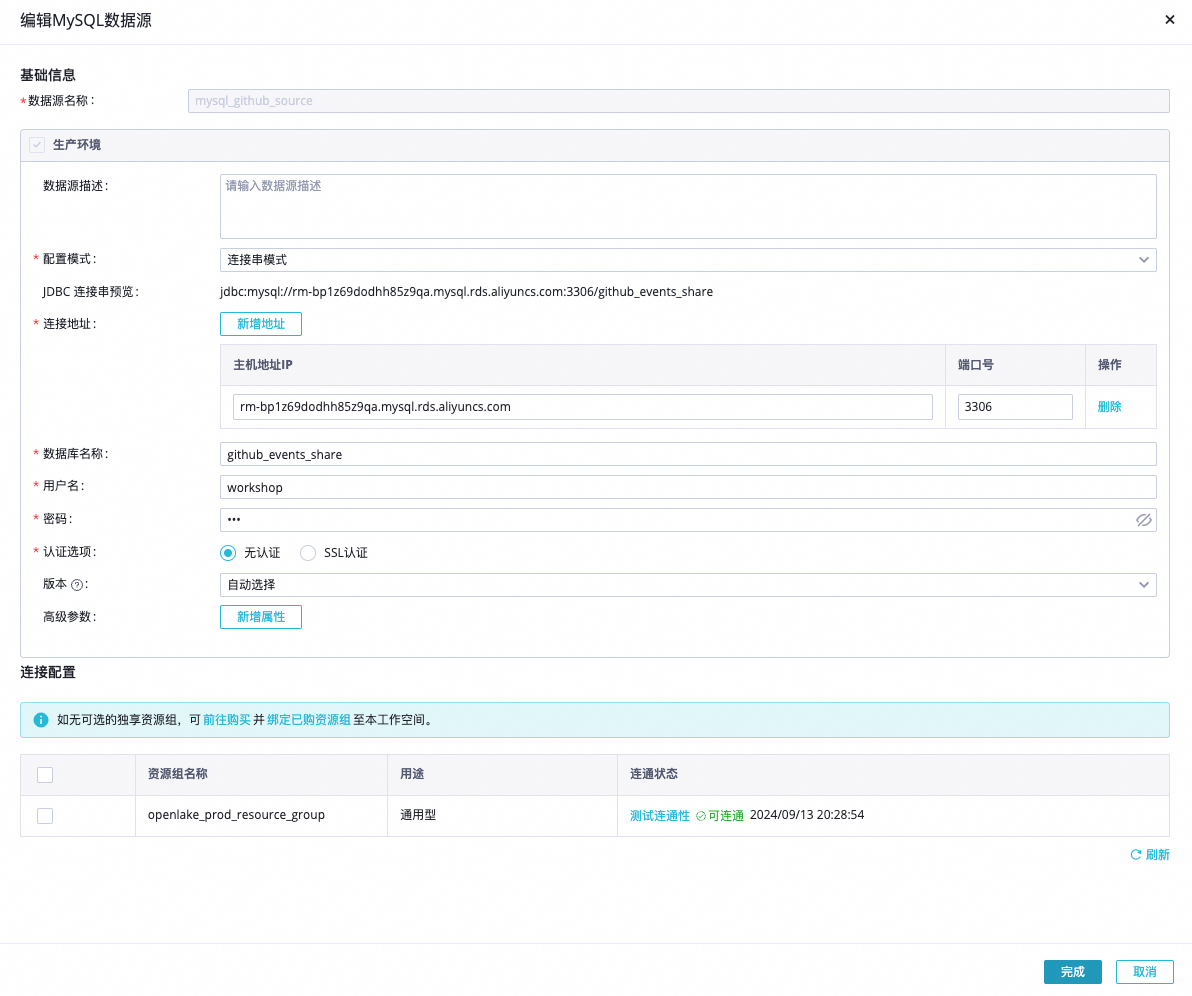
Step 1 實時MySQL數據源對接與驗證 | MySQL數據源連接信息格式如下。 說明 請確保MySQL數據源可以通過公網訪問,如無法通過公網訪問,可以配置公網NAT網關。 | 確認公開Github數據源可用。 |
Step 2 通過Flink CDC寫入數據 | 實時GitHub Event數據通過FlinkCDC實時數據寫入MaxCompute Delta Table增量表,更多信息,請參見利用Flink CDC實現數據同步至Delta Table。
| 查看MaxCompute的yunqi_github_events_odps_cdc數據表的數據變化。 |
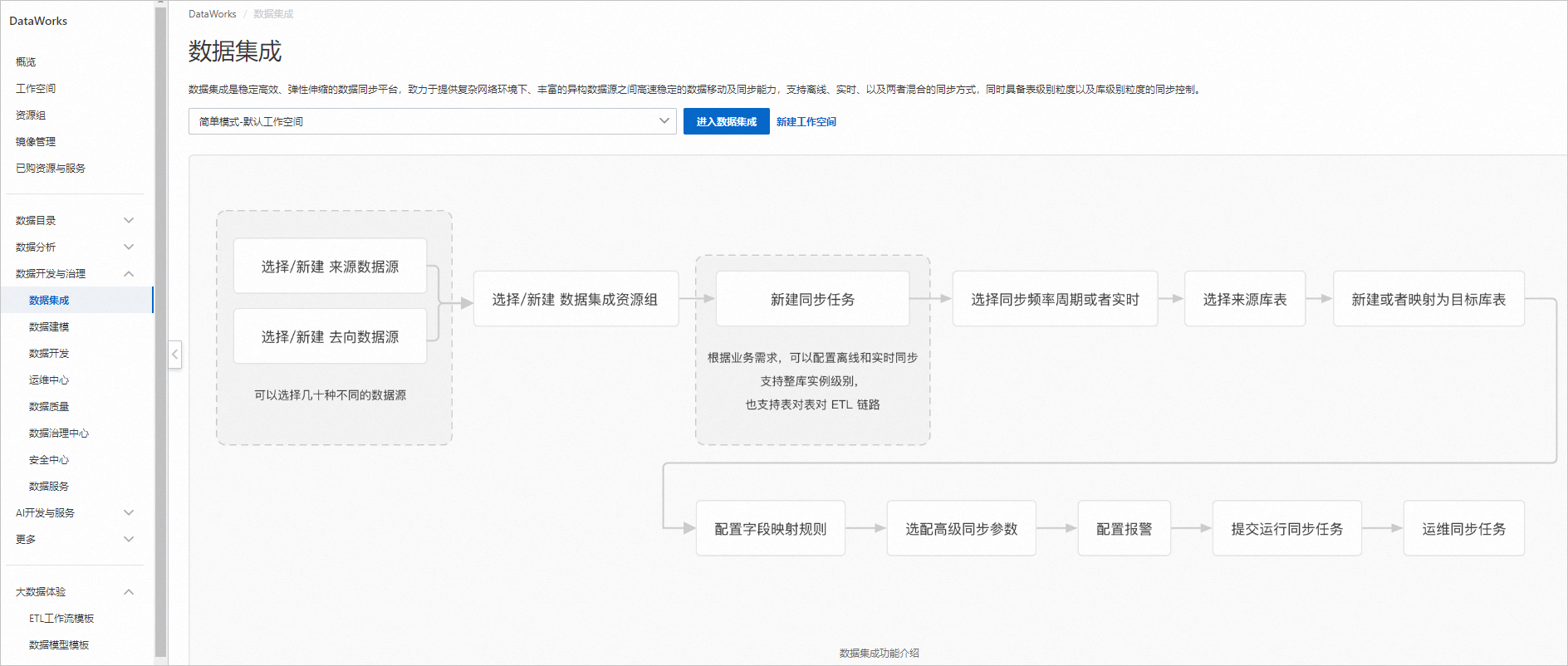
DataWorks數據集成
步驟 | 操作 | 預期結果 |
Step 1 實時MySQL數據源對接與驗證 | MySQL數據源連接信息格式如下。 說明 請確保MySQL數據源可以通過公網訪問,如無法通過公網訪問,可以配置公網NAT網關。 | 確認公開Github數據源可用。 |
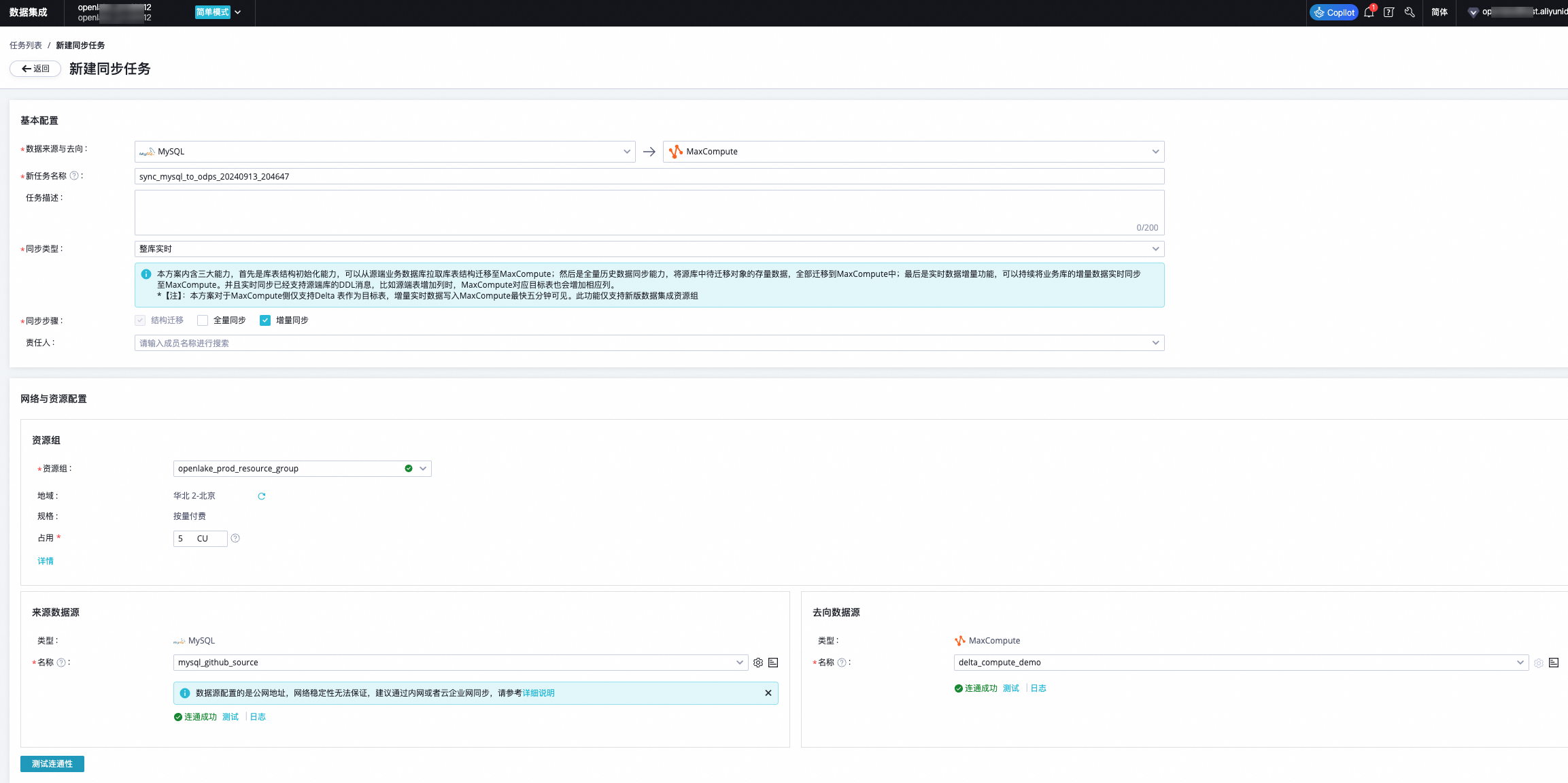
Step 2 配置DataWorks實時數據源 | 實時GitHub Event數據通過DataWorks數據集成實時數據寫入MaxCompute Delta Table增量表(實時數據源)。
| 確認來源和去向數據源聯通正常。 |
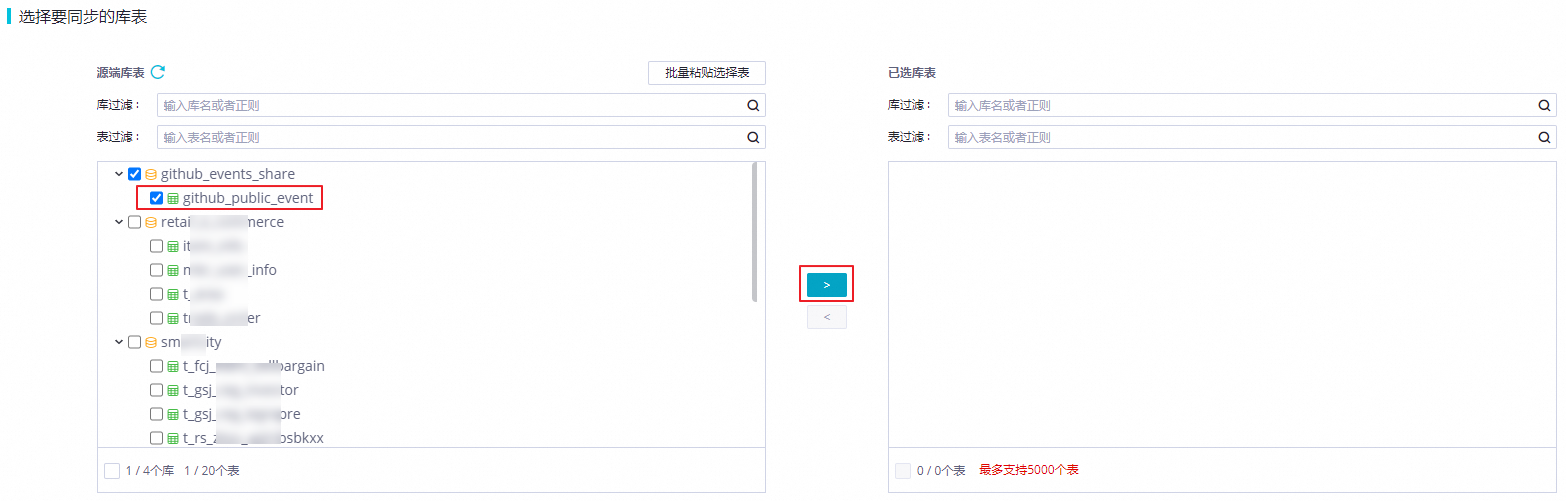
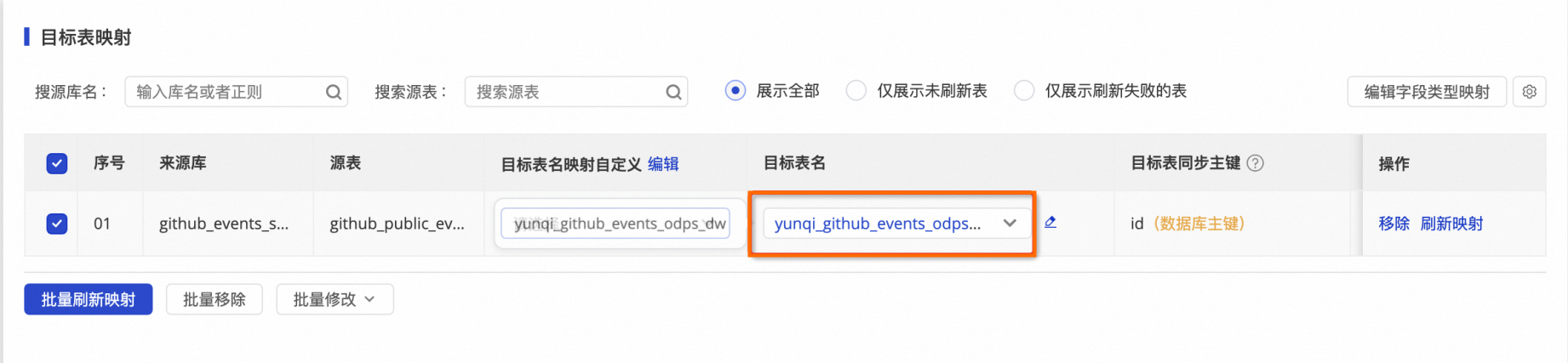
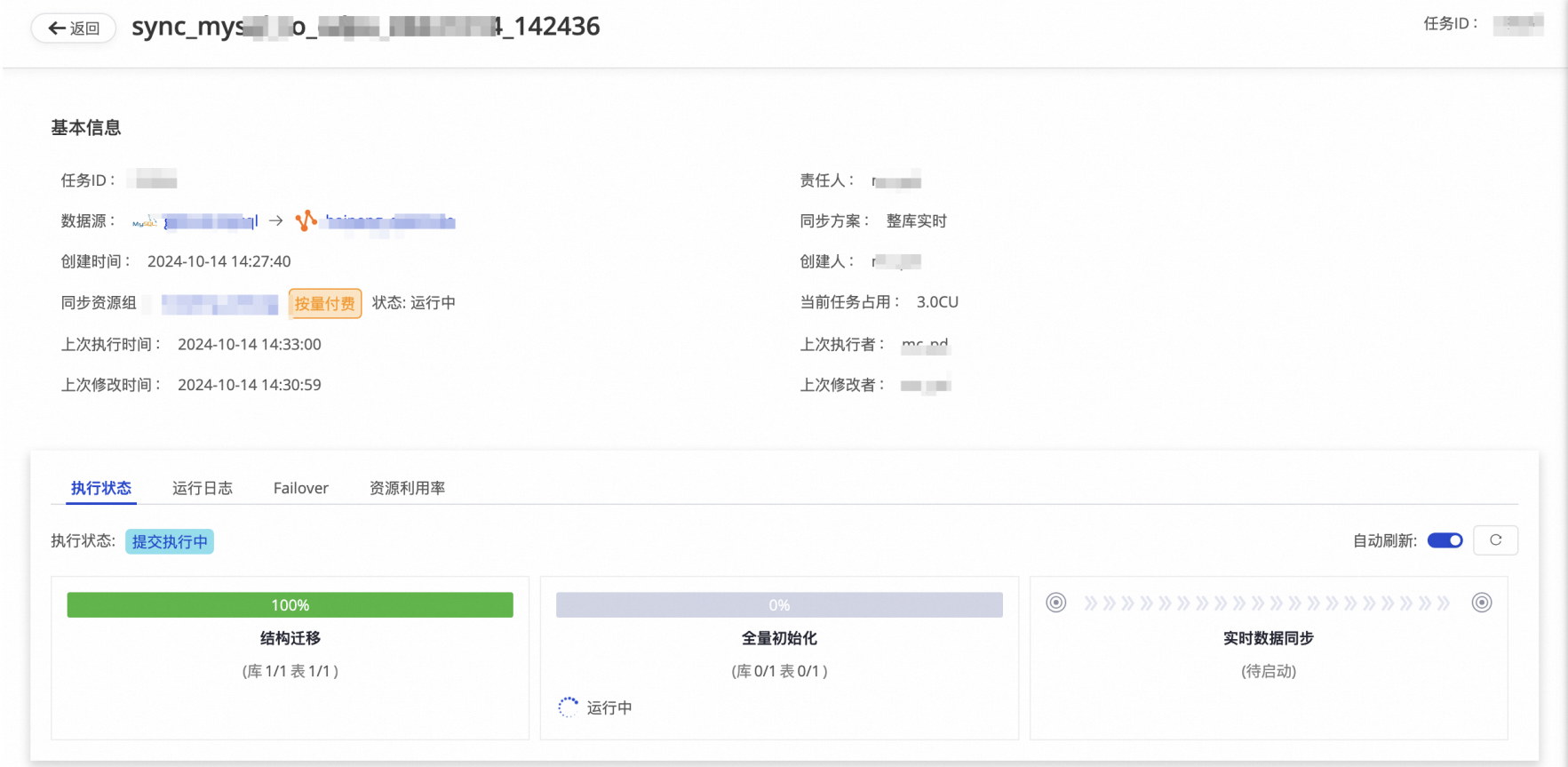
Step 3 DataWorks實時任務同步 | 實時GitHub Event數據通過DataWorks數據集成實時數據寫入MaxCompute Delta Table增量表。
| 查看MaxCompute的yunqi_github_events_odps_dw數據表的數據變化。 |

步驟三:近實時查詢分析和增量計算
近實時數據分析:使用交互式Quota組-mcqa2_demo_yunqi(64CU)在MaxCompute TopConsole SQL數據分析。
增量MV-自動化動態表:使用批處理Quota組-batch_demo_yunqi(128CU)在MaxCompute TopConsole進行動態表增量計算。
增量計算-CDC/Stream/周期性Tasks:使用批處理Quota組-batch_demo_yunqi在MaxCompute TopConsole進行自定義增量計算。
步驟 | 操作 | 預期結果 |
Step 1 使用交互式資源組-近實時數據分析 |
具體SQL分析步驟如下:
| 觀察查詢SQL結果。 |
Step 2 使用批處理資源組-增量計算-增量物化視圖MV聚合查詢 |
具體SQL分析步驟如下:
| 觀察查詢SQL結果。 |
Step 3 使用批處理資源組-增量計算-Stream&Task應用 |
具體SQL分析步驟如下:
| 觀察查詢SQL結果。 |
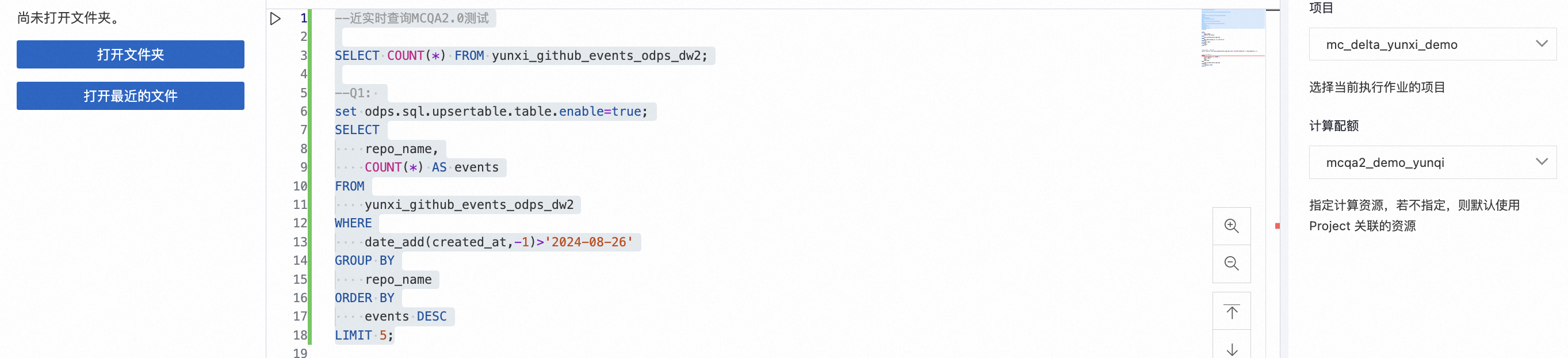
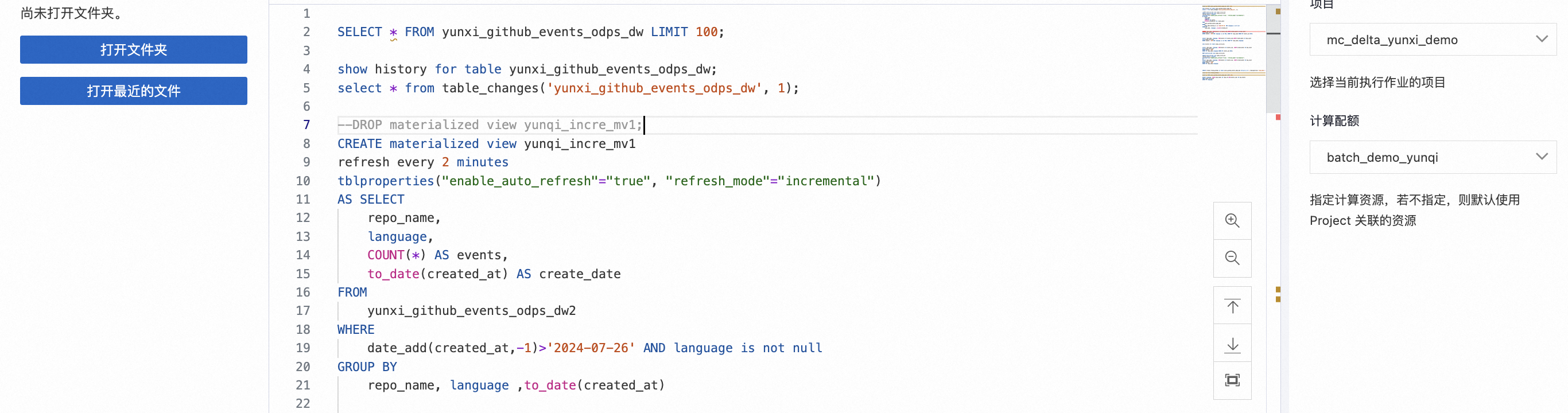
步驟四:多Quota資源配置和交互式查詢加速
交互式Quota組擴容(64CU->96CU),在新規格的Quota組情況下,在MaxCompute TopConsole進行交互式查詢, 觀測查詢加速性能提升。
步驟 | 操作 | 預期結果 |
Step 1 Quota擴容 |
| 目標Quota組資源擴容成功。 |
Step 2 查詢對比分析與性能優化 |
具體SQL分析步驟如下:
| 觀察查詢SQL結果。 |
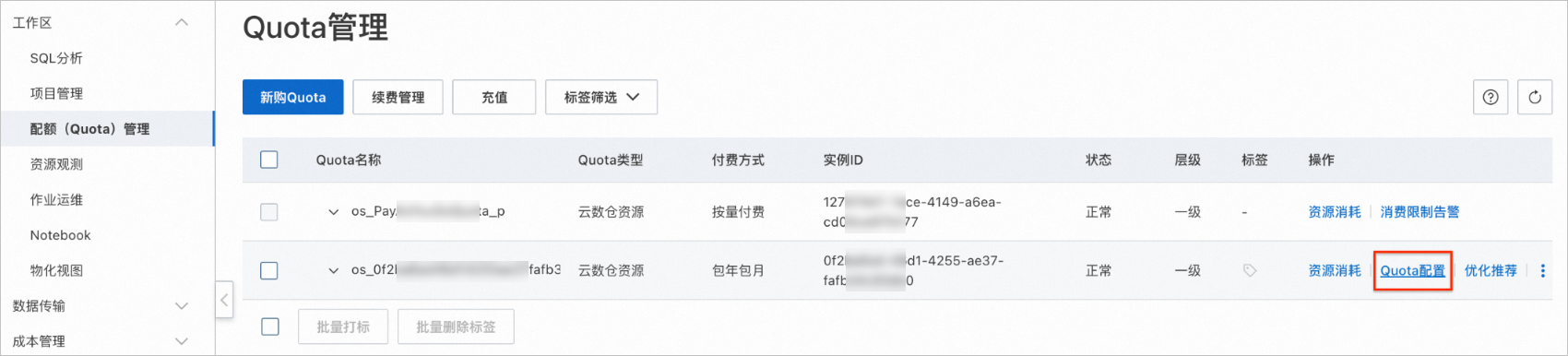
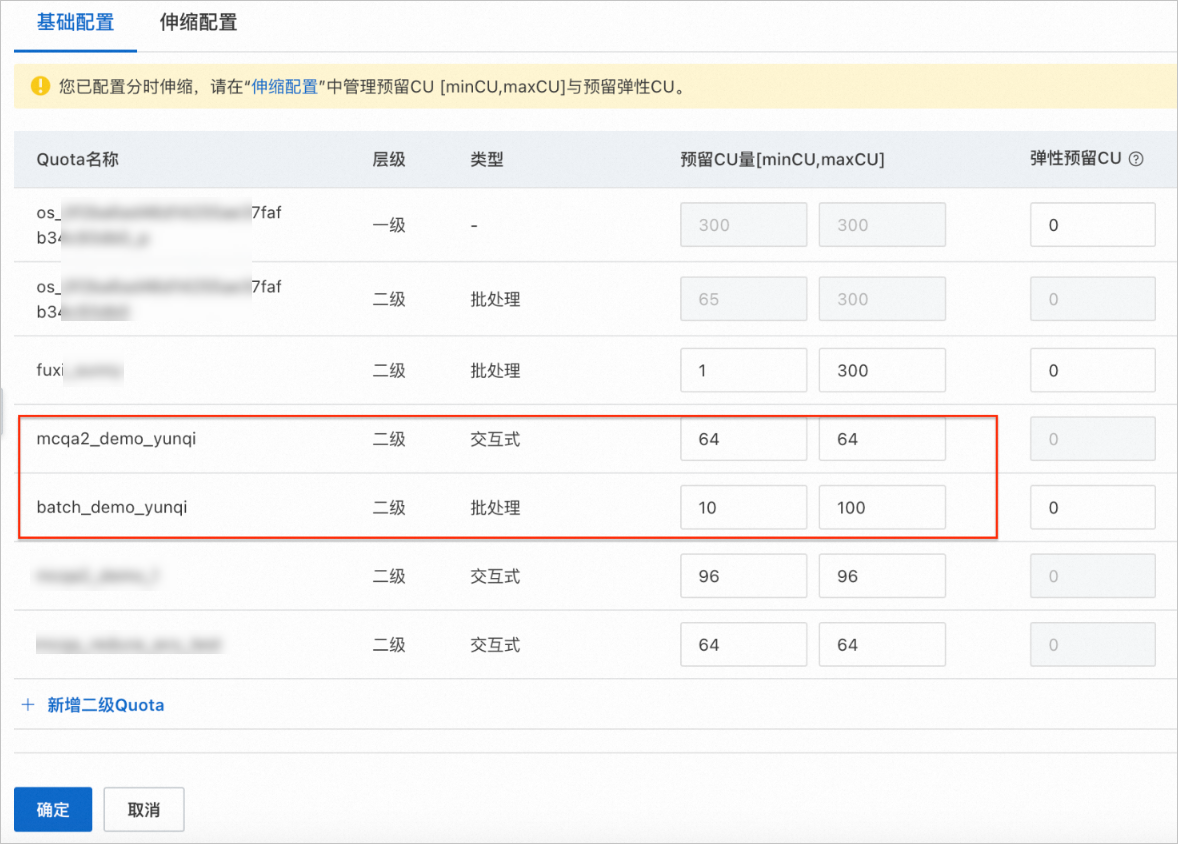
步驟五(可選):增全量一體交互式分析
使用DataWorks IDE模塊-實現增全量一體的近實時數據分析。
步驟 | 操作 | 預期結果 |
Step 1 在DataWorks IDE 數據開發模塊配置MaxCompute計算資源 |
| 無 |
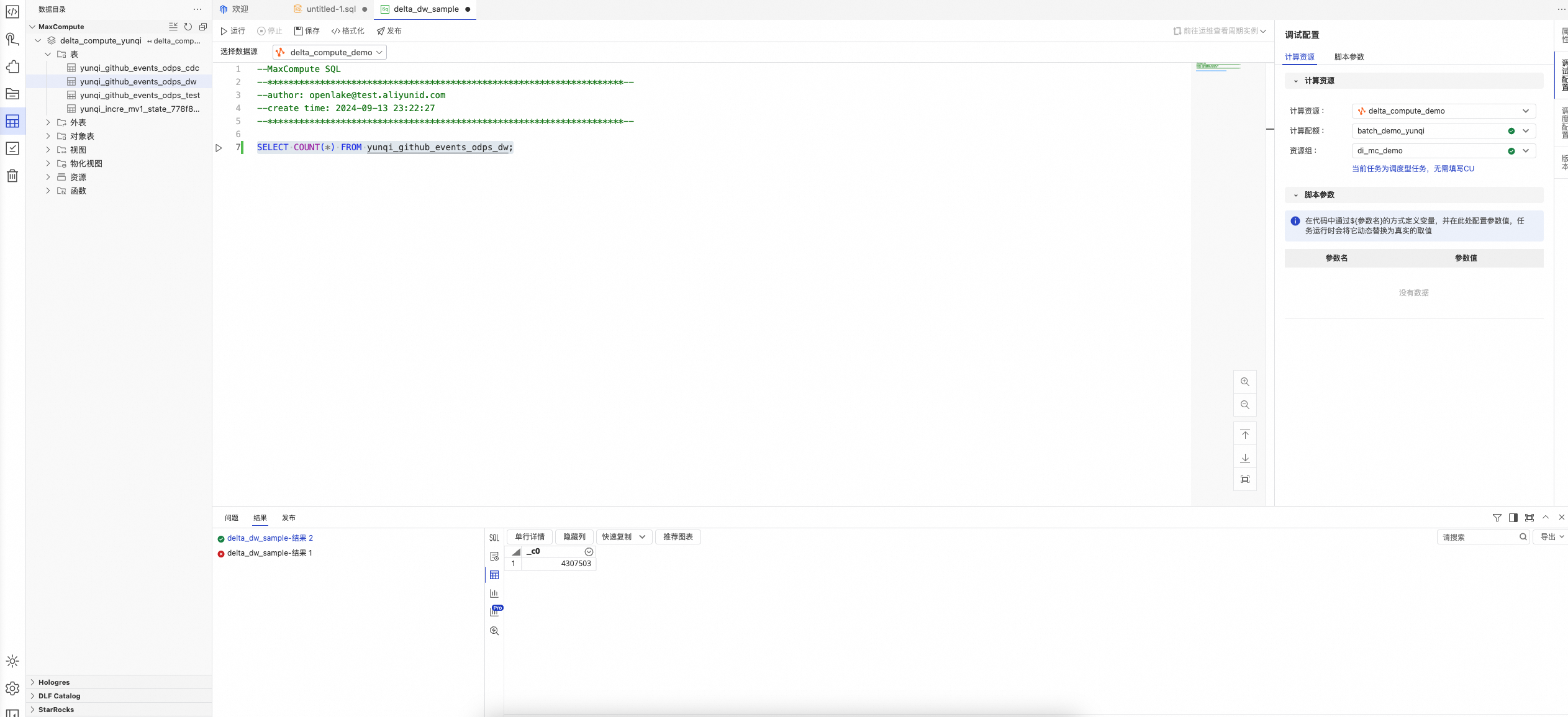
Step 2 在DataWorks IDE數據開發平臺進行數據分析 | 具體SQL分析步驟如下:
| 觀察查詢SQL結果。 |

總結
本次示例展示了MaxCompute全新構建的基于近實時數倉產品特性的產品方案實踐。MaxCompute提供增全量一體的數據處理和近實時查詢能力,從數據存儲層(Delta Table統一表格式)、計算層(增量計算:CDC/Task/增量MV)、加速層(MCQA2.0查詢加速引擎)等三層架構來實現MaxCompute近線計算能力的全面升級。通過此次典型的Demo創建,您能夠深度了解如何在MaxCompute產品上構建完備的近實時以及增全量計算的計算任務,簡化數據全生命周期的計算優化工作。