云消息隊(duì)列 Kafka 版數(shù)據(jù)遷移至MaxCompute
本文介紹如何使用DataWorks數(shù)據(jù)同步功能,將云消息隊(duì)列 Kafka 版集群上的數(shù)據(jù)遷移至阿里云大數(shù)據(jù)計(jì)算服務(wù)MaxCompute,方便您對(duì)離線數(shù)據(jù)進(jìn)行分析加工。
前提條件
在開始本教程前,確保您在同一地域中已完成以下操作:
云消息隊(duì)列 Kafka 版
購(gòu)買并部署云消息隊(duì)列 Kafka 版。具體操作,請(qǐng)參見購(gòu)買并部署實(shí)例。 本文以部署在華東1(杭州)地域(Region)的集群為例。
說明云消息隊(duì)列 Kafka 版實(shí)例支持的部署版本(0.10.x版本~2.x版本)、提供的規(guī)格類型(標(biāo)準(zhǔn)版和專業(yè)版)、支持的網(wǎng)絡(luò)屬性(VPC實(shí)例和公網(wǎng)/VPC實(shí)例)均支持?jǐn)?shù)據(jù)同步。您可以根據(jù)業(yè)務(wù)需要選擇。
創(chuàng)建Topic和Group,具體操作,請(qǐng)參見步驟三:創(chuàng)建資源。本文以Topic名稱為testkafka,Group名稱為console-consumer為例,Group console-consumer將用于消費(fèi)Topic testkafka中的數(shù)據(jù)。
已開通MaxCompute和DataWorks,本文以在華東1(杭州)地域創(chuàng)建名為bigdata_DOC的項(xiàng)目為例。
背景信息
大數(shù)據(jù)計(jì)算服務(wù)MaxCompute(原ODPS)是一種大數(shù)據(jù)計(jì)算服務(wù),能提供快速、完全托管免運(yùn)維的EB級(jí)云數(shù)據(jù)倉(cāng)庫(kù)解決方案。
DataWorks基于MaxCompute計(jì)算和存儲(chǔ),提供工作流可視化開發(fā)、調(diào)度運(yùn)維托管的一站式海量數(shù)據(jù)離線加工分析平臺(tái)。在數(shù)加(一站式大數(shù)據(jù)平臺(tái))中,DataWorks控制臺(tái)即為MaxCompute控制臺(tái)。MaxCompute和DataWorks一起向用戶提供完善的數(shù)據(jù)處理和數(shù)倉(cāng)管理能力,以及SQL、MR、Graph等多種經(jīng)典的分布式計(jì)算模型,能夠更快速地解決用戶海量數(shù)據(jù)計(jì)算問題,有效降低企業(yè)成本,保障數(shù)據(jù)安全。
本教程旨在幫助您使用DataWorks,將云消息隊(duì)列 Kafka 版中的數(shù)據(jù)導(dǎo)入至MaxCompute,來進(jìn)一步探索大數(shù)據(jù)的價(jià)值。
步驟一:準(zhǔn)備云消息隊(duì)列 Kafka 版數(shù)據(jù)
向Topic testkafka中寫入數(shù)據(jù),以作為遷移至MaxCompute中的數(shù)據(jù)。由于云消息隊(duì)列 Kafka 版用于處理流式數(shù)據(jù),您可以持續(xù)不斷地向其中寫入數(shù)據(jù)。為保證測(cè)試結(jié)果,建議您寫入10條以上的數(shù)據(jù)。
在概覽頁(yè)面的資源分布區(qū)域,選擇地域。
在實(shí)例列表頁(yè)面,單擊目標(biāo)實(shí)例名稱。
在左側(cè)導(dǎo)航欄,單擊Topic 管理。
在Topic 管理頁(yè)面,找到目標(biāo)Topic,在其操作列中,選擇。
在快速體驗(yàn)消息收發(fā)面板,發(fā)送測(cè)試消息。
發(fā)送方式選擇控制臺(tái)。
在消息 Key文本框中輸入消息的Key值,例如demo。
在消息內(nèi)容文本框輸入測(cè)試的消息內(nèi)容,例如 {"key": "test"}。
設(shè)置發(fā)送到指定分區(qū),選擇是否指定分區(qū)。
單擊是,在分區(qū) ID文本框中輸入分區(qū)的ID,例如0。如果您需查詢分區(qū)的ID,請(qǐng)參見查看分區(qū)狀態(tài)。
單擊否,不指定分區(qū)。
根據(jù)界面提示信息,通過SDK訂閱消息,或者執(zhí)行Docker命令訂閱消息。
發(fā)送方式選擇Docker,運(yùn)行Docker容器。
執(zhí)行運(yùn)行 Docker 容器生產(chǎn)示例消息區(qū)域的Docker命令,發(fā)送消息。
執(zhí)行發(fā)送后如何消費(fèi)消息?區(qū)域的Docker命令,訂閱消息。
發(fā)送方式選擇SDK,根據(jù)您的業(yè)務(wù)需求,選擇需要的語(yǔ)言或者框架的SDK以及接入方式,通過SDK體驗(yàn)消息收發(fā)。
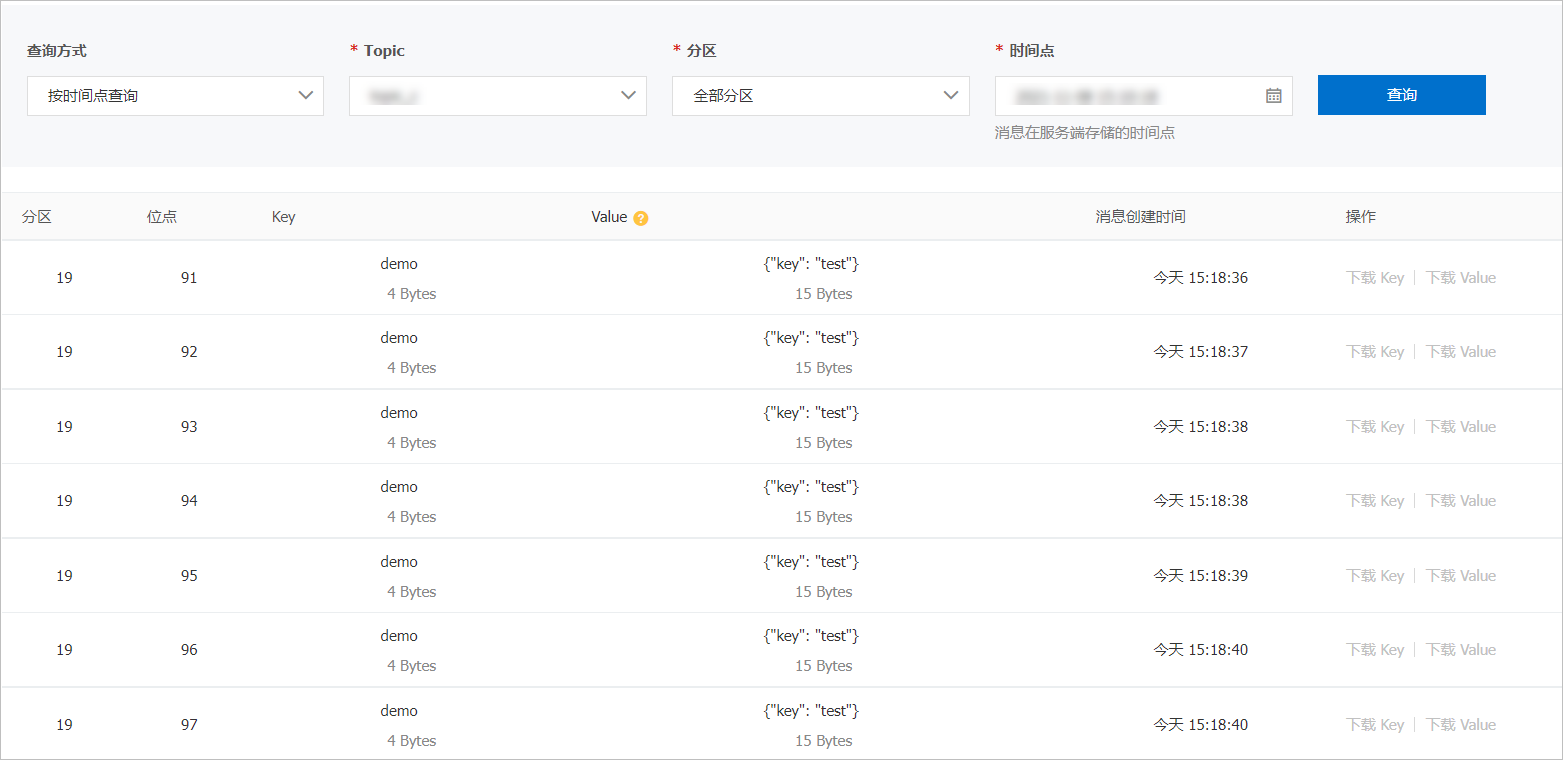
在左側(cè)導(dǎo)航欄,單擊消息查詢,然后在消息查詢頁(yè)面,選擇查詢方式、所屬的Topic、分區(qū)等信息,單擊查詢,查看之前寫入的Topic的數(shù)據(jù)。
關(guān)于消息查詢的更多信息,請(qǐng)參見消息查詢。以按時(shí)間查詢?yōu)槔樵兊囊徊糠窒⑷缦陆貓D:
步驟二:創(chuàng)建DataWorks表
您需創(chuàng)建DataWorks表,以保證大數(shù)據(jù)計(jì)算服務(wù)MaxCompute可以順利接收云消息隊(duì)列 Kafka 版數(shù)據(jù)。為測(cè)試便利,本文以使用非分區(qū)表為例。
進(jìn)入數(shù)據(jù)開發(fā)頁(yè)面。
在左側(cè)導(dǎo)航欄,單擊工作空間列表。
在目標(biāo)工作空間的操作列中,單擊快速進(jìn)入,選擇數(shù)據(jù)開發(fā)。
跳轉(zhuǎn)到數(shù)據(jù)開發(fā)頁(yè)面,在已有業(yè)務(wù)流程的情況下,可右鍵單擊目標(biāo)業(yè)務(wù)流程,選擇。
在新建表頁(yè)面,選擇引擎類型并輸入表名為testkafka,單擊新建。
在表編輯頁(yè)面左上角,單擊
 圖標(biāo)。
圖標(biāo)。在DDL對(duì)話框中,輸入如下建表語(yǔ)句,單擊生成表結(jié)構(gòu)。
CREATE TABLE testkafka ( key string, value string, partition1 string, timestamp1 string, offset string, t123 string, event_id string, tag string ) ;其中的每一列,對(duì)應(yīng)于DataWorks數(shù)據(jù)集成Kafka Reader的默認(rèn)列:
__key__表示消息的key。
__value__表示消息的完整內(nèi)容 。
__partition__表示當(dāng)前消息所在分區(qū)。
__headers__表示當(dāng)前消息headers信息。
__offset__表示當(dāng)前消息的偏移量。
__timestamp__表示當(dāng)前消息的時(shí)間戳。
您還可以自主命名,詳情參見Kafka Reader。
單擊提交到開發(fā)環(huán)境。
具體信息,請(qǐng)參見表管理。
步驟三:新增數(shù)據(jù)源
將已經(jīng)寫入數(shù)據(jù)的云消息隊(duì)列 Kafka 版添加至DataWorks,作為遷移數(shù)據(jù)源,并添加MaxCompute作為數(shù)據(jù)遷移的目標(biāo)源。
新建獨(dú)享數(shù)據(jù)集成資源組。
由于當(dāng)前DataWorks的公共資源組無(wú)法完美支持Kafka插件,您需要使用獨(dú)享數(shù)據(jù)集成資源組完成數(shù)據(jù)同步。詳情請(qǐng)參見新增和使用獨(dú)享數(shù)據(jù)集成資源組。
在左側(cè)導(dǎo)航欄,單擊工作空間列表
在工作空間列表,單擊目標(biāo)工作空間操作列中的。
在管理中心頁(yè)面左側(cè)導(dǎo)航欄,選擇,即可新增相應(yīng)的數(shù)據(jù)源。具體操作,請(qǐng)參見數(shù)據(jù)源配置
新增數(shù)據(jù)源云消息隊(duì)列 Kafka 版
在新增數(shù)據(jù)源面板,選擇Kafka。
填寫數(shù)據(jù)源Kafka信息。
數(shù)據(jù)源類型:選擇阿里云實(shí)例模式。
數(shù)據(jù)源名稱:輸入新增的數(shù)據(jù)源名稱。
適用環(huán)境:選擇開發(fā)。
地區(qū):選擇華東1(杭州)。
實(shí)例ID:在云消息隊(duì)列 Kafka 版控制臺(tái)創(chuàng)建的實(shí)例ID。
特殊認(rèn)證方式:保持默認(rèn)。
資源組連通性:選擇數(shù)據(jù)集成。
在獨(dú)享集群集成資源組列表,目標(biāo)資源組所在行,單擊測(cè)試連通性。
測(cè)試成功后,單擊完成。
新增數(shù)據(jù)源MaxCompute
在新增數(shù)據(jù)源面板,選擇MaxCompute。
填寫數(shù)據(jù)源MaxCompute信息。
數(shù)據(jù)源名稱:輸入新增的數(shù)據(jù)源名稱。
適用環(huán)境:選擇開發(fā)。
ODPS Endpoint:保持默認(rèn)。
ODPS項(xiàng)目名稱:輸入ODPS項(xiàng)目名稱為bigdata_DOC。
AccessKey ID:MaxCompute訪問用戶的AccessKey ID。更多信息,請(qǐng)參見創(chuàng)建AccessKey。
AccessKey Secret:MaxCompute訪問用戶的AccessKey ID的密碼。更多信息,請(qǐng)參見創(chuàng)建AccessKey。
資源組連通性:選擇數(shù)據(jù)集成。
在獨(dú)享集群集成資源組列表,目標(biāo)資源組所在行,單擊測(cè)試連通性。
測(cè)試成功后,單擊完成。
步驟四:同步數(shù)據(jù)
登錄DataWorks控制臺(tái),切換至目標(biāo)地域后,單擊左側(cè)導(dǎo)航欄的,在下拉框中選擇對(duì)應(yīng)工作空間后單擊進(jìn)入數(shù)據(jù)開發(fā)。
在數(shù)據(jù)開發(fā)頁(yè)面,右鍵單擊業(yè)務(wù)名稱,選擇。
在新建節(jié)點(diǎn)對(duì)話框,輸入節(jié)點(diǎn)名稱(即數(shù)據(jù)同步任務(wù)名稱),然后單擊確認(rèn)。
在創(chuàng)建的節(jié)點(diǎn)頁(yè)面,選擇數(shù)據(jù)源信息。
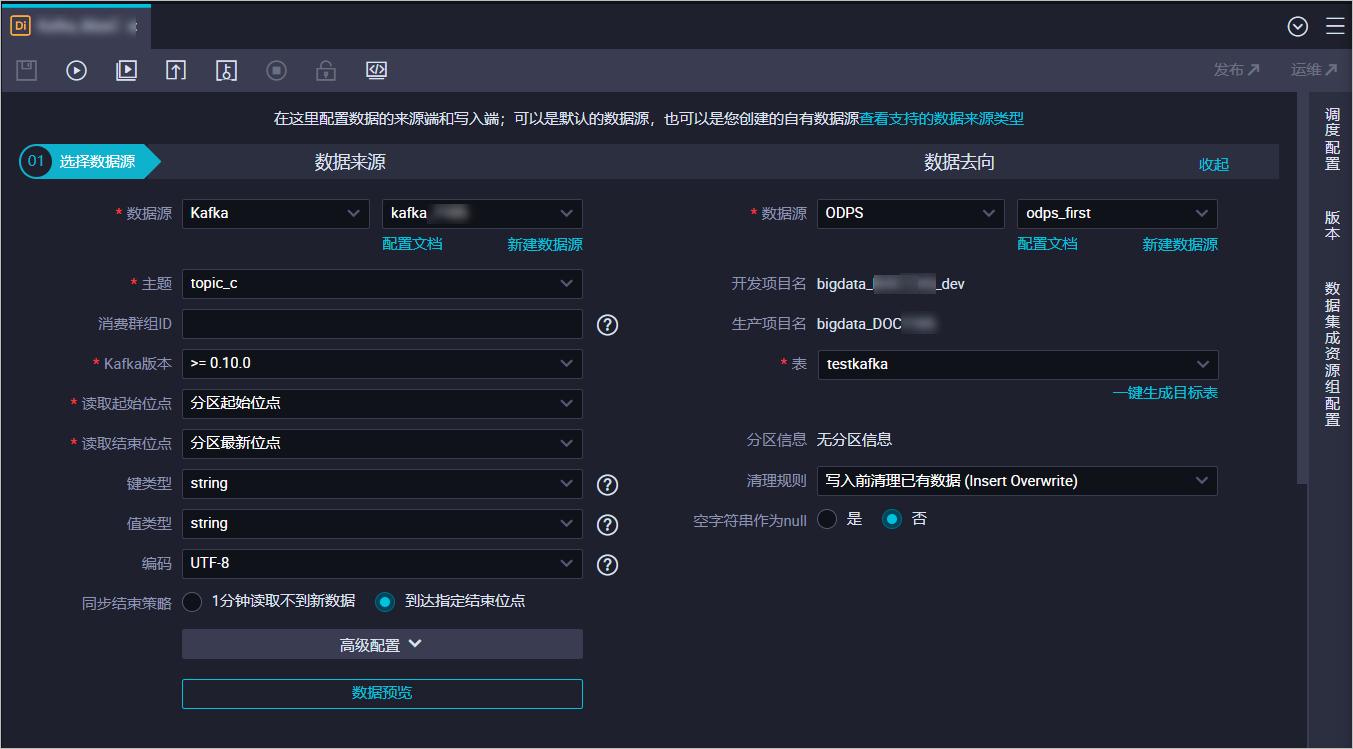
數(shù)據(jù)來源:選擇數(shù)據(jù)源為Kafka和步驟三:新增數(shù)據(jù)源新增的數(shù)據(jù)源Kafka名稱。主題選擇寫入數(shù)據(jù)的Topic。
數(shù)據(jù)去向:選擇數(shù)據(jù)去向的數(shù)據(jù)源為ODPS和步驟三:新增數(shù)據(jù)源新增的數(shù)據(jù)源MaxCompute名稱。表選擇您在步驟二:創(chuàng)建DataWorks表中創(chuàng)建的表。
您也可以單擊配置區(qū)域上方的
 圖標(biāo),轉(zhuǎn)換為腳本模式,通過腳本配置。示例如下:
圖標(biāo),轉(zhuǎn)換為腳本模式,通過腳本配置。示例如下:{ "type": "job", "version": "2.0", "steps": [ { "stepType": "kafka", "parameter": { "server": "localhost:9093", "fetchMaxWaitMs": "500", "kafkaConfig": { "group.id": "datax_consumer_group" }, "endType": "specific", "column": [ "__key__", "__value__", "__partition__", "__headers__", "__offset__", "__timestamp__" ], "timeZone": "Asia/Shanghai", "fetchMinBytes": "1", "endDateTime": "${endDateTime}", "encoding": "UTF-8", "version": "10", "stopWhenPollEmpty": "false", "beginType": "specific", "autoOffsetReset": "none", "envType": 0, "datasource": "kafka_001", "valueType": "string", "topic": "topic_c", "beginDateTime": "${beginDateTime}", "keyType": "string", "sessionTimeoutMs": "30000", "waitTime": "10" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "truncate": true, "datasource": "odps_001", "envType": 0, "column": [ "key", "value", "partition1", "timestamp1", "offset", "t123" ], "emptyAsNull": false, "table": "testkafka" }, "name": "Writer", "category": "writer" } ], "setting": { "executeMode": null, "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }單擊數(shù)據(jù)集成資源出配置,選擇步驟三:新增數(shù)據(jù)源中第一步創(chuàng)建的獨(dú)享資源組,單擊
 圖標(biāo),運(yùn)行任務(wù)。
圖標(biāo),運(yùn)行任務(wù)。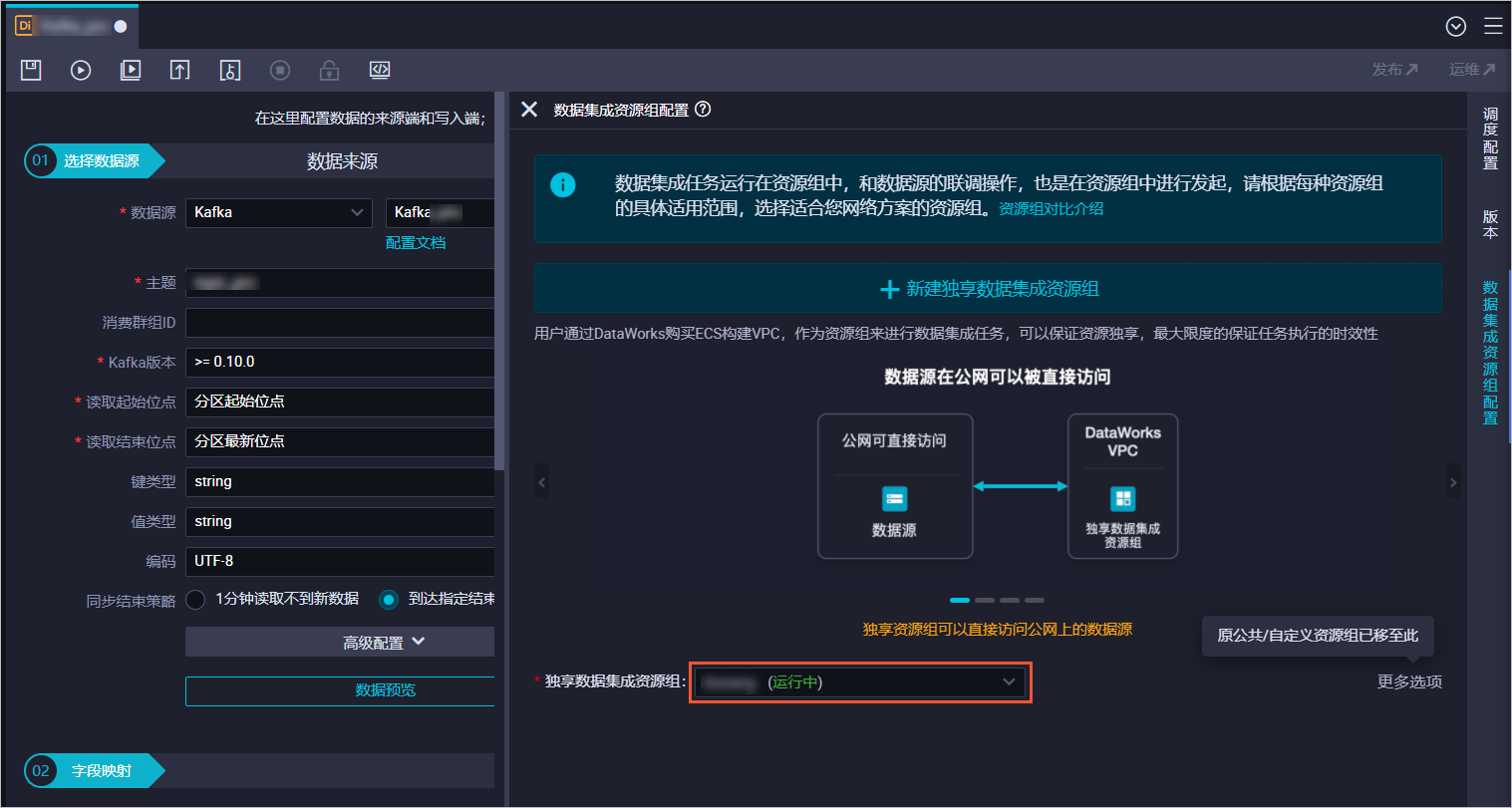
執(zhí)行結(jié)果
完成運(yùn)行后,運(yùn)行日志中顯示運(yùn)行成功。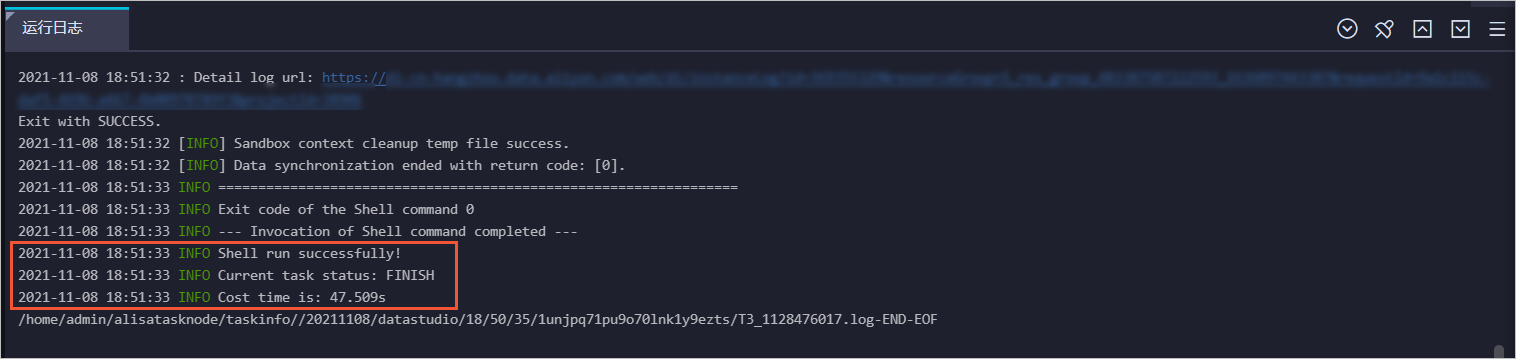
后續(xù)步驟
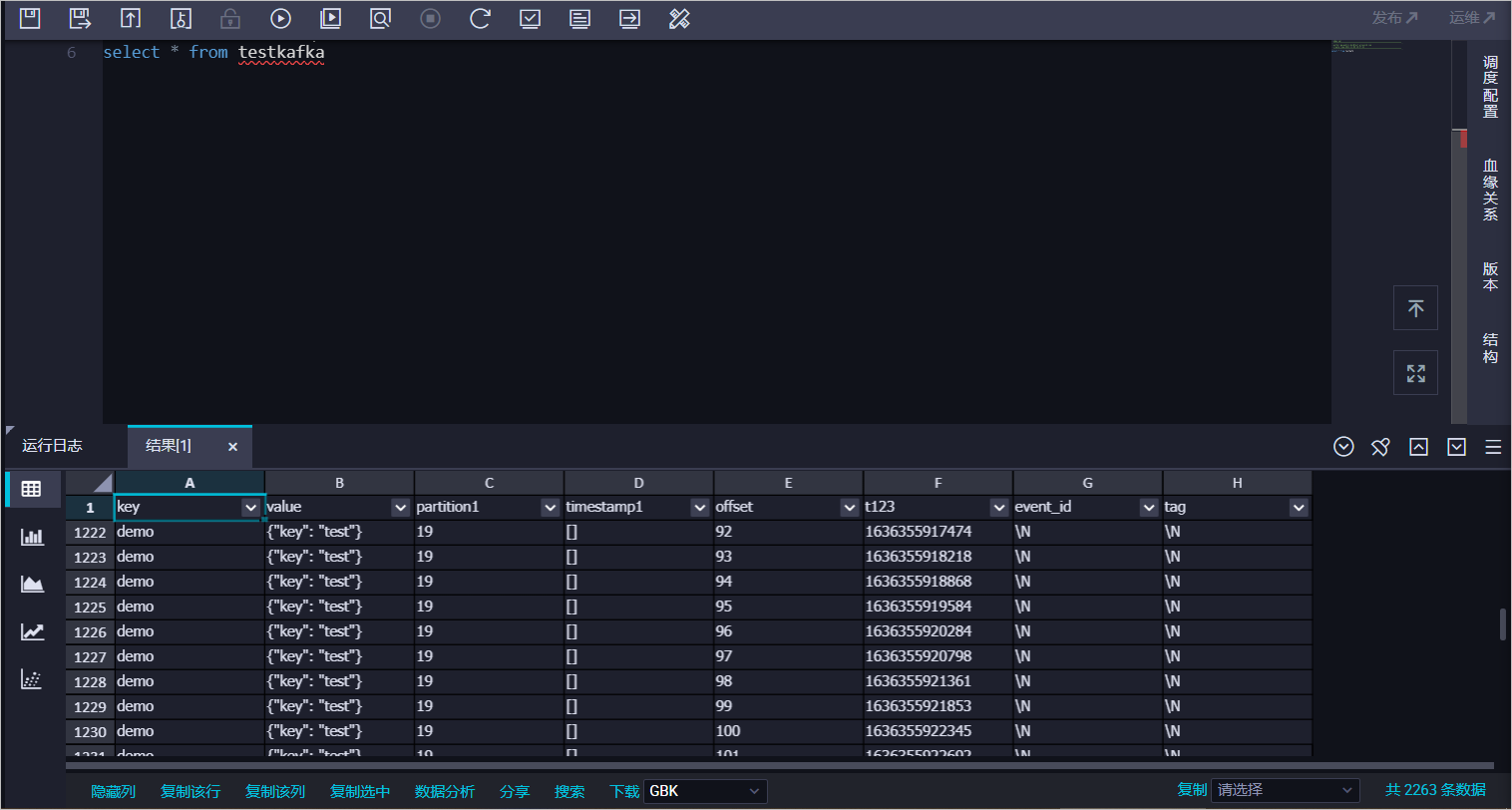
您可以新建一個(gè)數(shù)據(jù)開發(fā)任務(wù)運(yùn)行SQL語(yǔ)句,查看當(dāng)前表中是否已存在從云消息隊(duì)列 Kafka 版同步過來的數(shù)據(jù)。本文以select * from testkafka為例,具體步驟如下:
登錄DataWorks控制臺(tái),切換至目標(biāo)地域后,單擊左側(cè)導(dǎo)航欄的,在下拉框中選擇對(duì)應(yīng)工作空間后單擊進(jìn)入數(shù)據(jù)開發(fā)。
在臨時(shí)查詢面板,右鍵單擊臨時(shí)查詢,選擇。
在新建節(jié)點(diǎn)對(duì)話框中,輸入名稱。
說明節(jié)點(diǎn)名稱的長(zhǎng)度不能超過128個(gè)字符。
單擊確認(rèn)。
在創(chuàng)建的節(jié)點(diǎn)頁(yè)面,輸入
select * from testkafka,單擊 圖標(biāo),運(yùn)行完成后,查看運(yùn)行日志。
圖標(biāo),運(yùn)行完成后,查看運(yùn)行日志。