如果您想了解費用的分布情況并避免在使用MaxCompute產品時費用超出預期,您可以通過獲取MaxCompute賬單并進行分析,為資源使用率最大化及降低成本提供有效支撐。本文為您介紹如何通過用量明細表分析MaxCompute的費用分布情況。
背景信息
MaxCompute是一款大數據分析平臺,其計算資源的計費方式分為包年包月和按量付費兩種。MaxCompute每天以項目為維度進行計費,賬單會在第二天06:00前生成。更多MaxCompute計量計費信息,請參見計費項與計費方式概述。
MaxCompute會在數據開發階段或者產品上線前發布賬單波動(通常情況下為消費增長)信息。您可以自助分析賬單波動情況,再對MaxCompute項目的作業進行優化。您可以在阿里云費用中心下載阿里云所有收費產品的用量明細。更多獲取和下載賬單操作,請參見查看賬單詳情。
通常您需要使用阿里云賬號查看賬單詳情。如果RAM用戶需要查看賬單信息,需要阿里云賬號選擇策略并對RAM用戶授權,詳情請參見費用中心RAM配置策略。
步驟一:下載用量明細
您可以通過用量明細下載每天的詳細使用信息,了解費用是如何產生。例如每天的存儲費用、計算費用是由哪些任務產生的。
您也可以通過計量API獲取MaxCompute使用記錄,計量API的使用說明請參見查詢產品計量記錄服務。MaxCompute的計量表(Table)為按量付費(ODPS)、包年包月(ODPSDataPlus)。
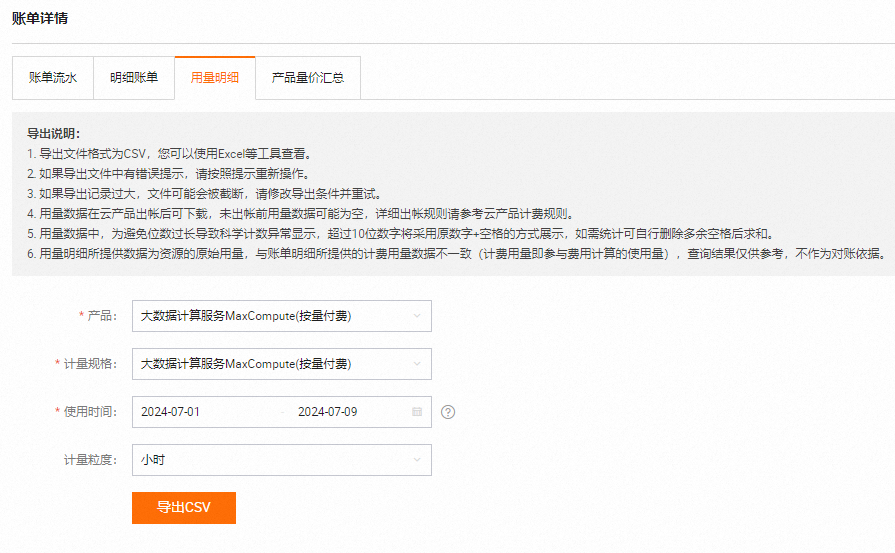
配置參數說明如下:
產品:選擇大數據計算服務MaxCompute(按量付費)。
計量規格:
大數據計算服務MaxCompute(按量付費)是按量付費模式的計量明細。
ODPSDataPlus是包年包月模式的計量明細。
使用時間:單擊下拉框選擇開始時間和結束時間。
如果出現跨天執行的任務,例如某任務開始時間為12月1日,結束時間為12月2日,那么需要選擇開始時間為12月1日才能在下載的用量明細表中查詢到該任務,但是該任務的消費記錄體現在12月2日的賬單中。
單擊導出CSV,等待一段時間后,可前往導出記錄下載用量明細表。
步驟二(可選):上傳用量明細數據至MaxCompute
如果您期望通過MaxCompute SQL進行用量明細分析,則需要參考本步驟將用量明細導入MaxCompute;如果您只希望使用Excel進行用量明細分析,則無需進行此步驟。
使用MaxCompute客戶端(odpscmd)按如下示例語句創建
maxcomputefee表。CREATE TABLE IF NOT EXISTS maxcomputefee ( projectid STRING COMMENT '項目編號' ,feeid STRING COMMENT '計費信息編號' ,meteringtime STRING COMMENT '文件表頭(MeteringTime)' ,type STRING COMMENT '數據分類,包括Storage、ComputationSQL、DownloadEx等' ,starttime STRING COMMENT '開始時間' ,storage BIGINT COMMENT '存儲(Byte)' ,endtime STRING COMMENT '結束時間' ,computationsqlinput BIGINT COMMENT 'SQL/交互式分析讀取量(Byte)' ,computationsqlcomplexity DOUBLE COMMENT 'SQL復雜度' ,uploadex BIGINT COMMENT '公網上行流量Byte' ,download BIGINT COMMENT '公網下行流量Byte' ,cu_usage DOUBLE COMMENT 'MR/Spark作業計算(core*second)' ,Region STRING COMMENT '地域' ,input_ots BIGINT COMMENT '訪問OTS的數據輸入量' ,input_oss BIGINT COMMENT '訪問OSS的數據輸入量' ,source_id STRING COMMENT 'DataWorks調度任務ID' ,source_type STRING COMMENT '計算資源規格' ,RecycleBinStorage BIGINT COMMENT '備份存儲(Byte)' ,JobOwner STRING COMMENT '作業Owner' ,Signature STRING COMMENT 'SQL作業簽名' );賬單明細字段說明如下:
項目編號:當前賬號或RAM用戶對應的阿里云賬號的MaxCompute項目列表。
計量信息編號:以存儲、計算、上傳和下載的任務ID為計費信息編號,SQL為InstanceID,上傳和下載為Tunnel SessionId。
數據分類:Storage(存儲)、LowFreqStorage(低頻存儲)、ColdStorage (長期存儲)、SqlLongterm(長期存儲訪問費)、SqlLowFrequency(低頻存儲訪問費)、ComputationSql(計算)、UploadIn(內網上傳)、UploadEx(外網上傳)、DownloadIn(內網下載)、DownloadEx(外網下載)。按照計費規則只有紅色部分為實際計費項目。
存儲(Byte):每小時讀取的存儲量,單位為Byte。
開始時間或結束時間:按照實際作業執行時間進行計量,只有存儲是按照每個小時取一次數據。
SQL/交互式分析讀取量(Byte):SQL計算項,每一次SQL執行時SQL的Input數據量,單位為Byte。
SQL復雜度:SQL的復雜度,為SQL計費因子之一。
公網上行流量(Byte)或公網下行流量(Byte):分別為外網上傳或下載的數據量,單位為Byte。
MR/Spark作業計算(Core*Second):MapReduce或Spark作業的計算時單位為
Core*Second,需要轉換為計算時Hour。SQL讀取量_訪問OTS(Byte)、SQL讀取量_訪問OSS(Byte):外部表實施收費后的讀取數據量,單位為Byte。
計算資源規格(按量付費):計量信息所屬項目的計算資源規格,若值為
OdpsStandard或NULL,則表示按量付費標準版,詳情請參見按量付費標準版;若值為OdpsSpot,則表示,按量付費閑時版,詳情請參見按量付費閑時版;若值為OdpsDev,則表示按量計費開發者版。說明按量付費開發者版已停止新購,并將于北京時間2023年10月31日(周二)00:00:00停止服務,建議您盡快調整至標準版或閑時版計算資源,詳情請參見2022年09月23日-MaxCompute部分售賣規格停止新購公告。
計算資源規格(包年包月):計量信息所屬項目的計算資源規格。若值為NULL,則表示包年包月標準版;若值為OdpsPlus160CU150TB、OdpsPlus320CU300TB或OdpsPlus600CU500TB,則分別表示存儲密集型160套餐、存儲密集型320套餐或存儲密集型600套餐。
DataWorks調度任務ID:作業在DataWorks上的調度節點ID。若值NULL,則表示非DataWorks調度節點提交的作業;若值為一串數字ID,則表示作業對應的DataWorks調度節點ID。您可以在DataWorks對應的項目中使用該ID搜索到具體任務。
備份存儲(Byte):每小時讀取的備份存儲量,單位為Byte。
地域:MaxCompute項目所在的地域。
作業Owner:提交作業的用戶。
SQL作業簽名:用于標識SQL作業,主體內容一致、而多次重復或調度執行的SQL作業簽名一致。
使用Tunnel上傳數據。
在上傳CSV文件時,您需確保CSV文件中的列數、數據類型必須與表maxcomputefee的列數、數據類型保持一致,否則會導入失敗。
tunnel upload ODPS_2019-01-12_2019-01-14.csv maxcomputefee -c "UTF-8" -h "true" -dfp "yyyy-MM-dd HH:mm:ss";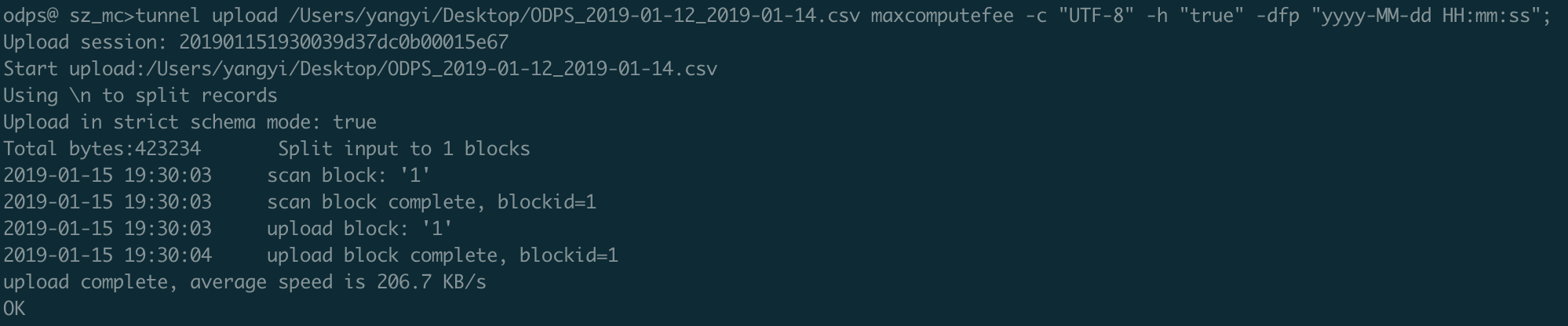 說明
說明Tunnel的配置詳情請參見Tunnel命令。
您也可以通過DataWorks的數據導入功能來執行此操作,具體請參見使用DataWorks(離線與實時)。
執行如下語句驗證數據。
SELECT * FROM maxcomputefee limit 10;
步驟三:分析賬單數據
分析SQL費用。
云上用戶使用MaxCompute,95%的用戶通過SQL即可滿足需求,SQL也在消費增長中占很大比例。
一次標準版SQL計算費用 = 計算輸入數據量×SQL復雜度×單價(0.3元/GB)
一次SpotSQL計算費用 = 計算輸入數據量×SQL復雜度×單價(0.1元/GB)
通過Excel分析:分析用量明細中數據分類為ComputationSql的數據。對SQL作業費用進行排序,觀察是否存在某些SQL作業費用超出預期或者SQL任務過多。SQL作業費用計算公式為(
SQL/交互式分析讀取量(Byte)/1024/1024/1024 × SQL復雜度 × SQL單價)。例如下圖中計量信息編號20171106100629865g4iplf9的標準SQL任務,產生的費用為
SQL讀取量(7352600872(Byte)/1024/1024/1024)×SQL復雜度 1×0.3元/(GB×復雜度)=2元。
通過SQL分析(已完成步驟二的數據導入,生成maxcomputefee表):
--分析SQL消費,按照sqlmoney排行。 SELECT REPLACE(SUBSTR(endtime,1,10),'-','') AS ds, feeid AS instanceid , projectid , source_type , computationsqlcomplexity , SUM((computationsqlinput / 1024 / 1024 / 1024)) AS computationsqlinput , CASE WHEN source_type ='OdpsSpot' THEN SUM((computationsqlinput / 1024 / 1024 / 1024)) * computationsqlcomplexity * 0.1 ELSE SUM((computationsqlinput / 1024 / 1024 / 1024)) * computationsqlcomplexity * 0.3 END AS sqlmoney FROM maxcomputefee WHERE TYPE = 'ComputationSql' AND computationsqlinput IS NOT NULL AND source_type !='OdpsDev' AND REPLACE(SUBSTR(endtime,1,10),'-','') >= '20230701' GROUP BY REPLACE(SUBSTR(endtime,1,10),'-',''), feeid , projectid , computationsqlcomplexity , source_type ORDER BY sqlmoney DESC LIMIT 10000 ;查詢結果如下。
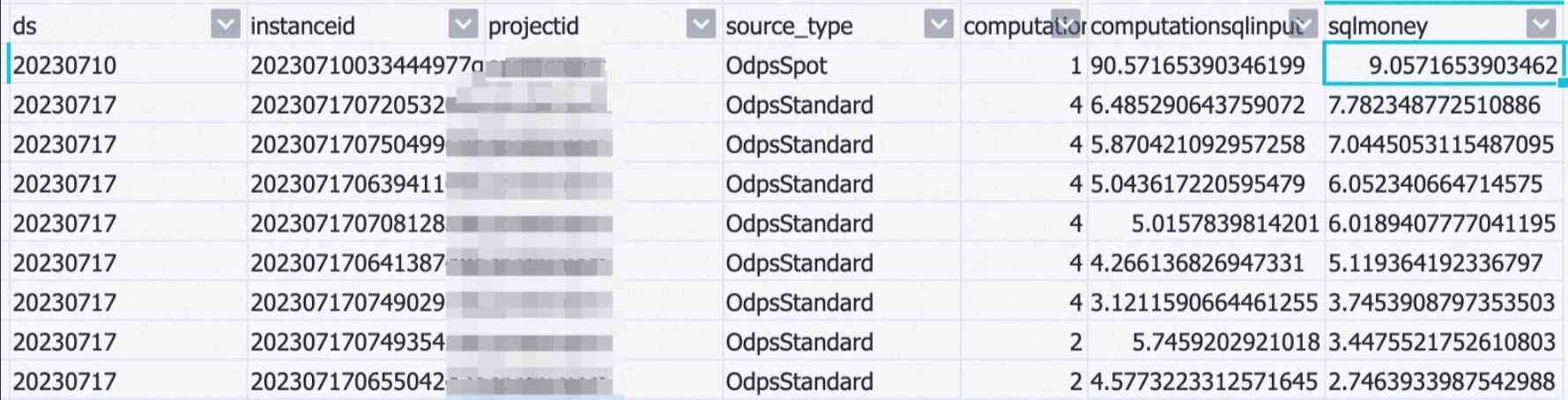
根據查詢結果可以得到以下結論:
大作業可以減小數據讀取量、降低復雜度、優化費用成本。
可以按照
ds字段(按照天)進行匯總,分析某個時間段內的SQL消費金額走勢。例如利用本地Excel或Quick BI等工具繪制折線圖等方式,更直觀地反映作業的趨勢。根據執行結果可以定位到需要優化的點,方法如下:
通過查詢的instanceid,獲取目標實例運行日志的Logview地址。
在MaxCompute客戶端(odpscmd)或DataWorks中執行
wait <instanceid>;命令,查看instanceid的運行日志。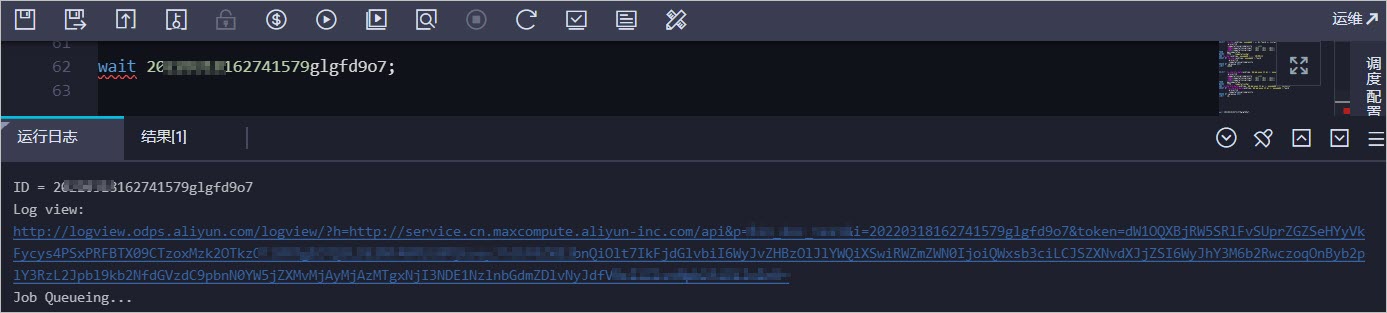
通過如下命令查看作業的詳細信息。
DESC instance 2016070102275442go3xxxxxx;返回結果如下:
ID 2016070102275442go3xxxxxx Owner ALIYUN$***@aliyun-inner.com StartTime 2016-07-01 10:27:54 EndTime 2016-07-01 10:28:16 Status Terminated console_query_task_1467340078684 Success Query select count(*) from src where ds='20160628';在瀏覽器中打開Logview的URL地址,在Logview頁面的SourceXML頁簽,獲取該實例的SKYNET_NODENAME。
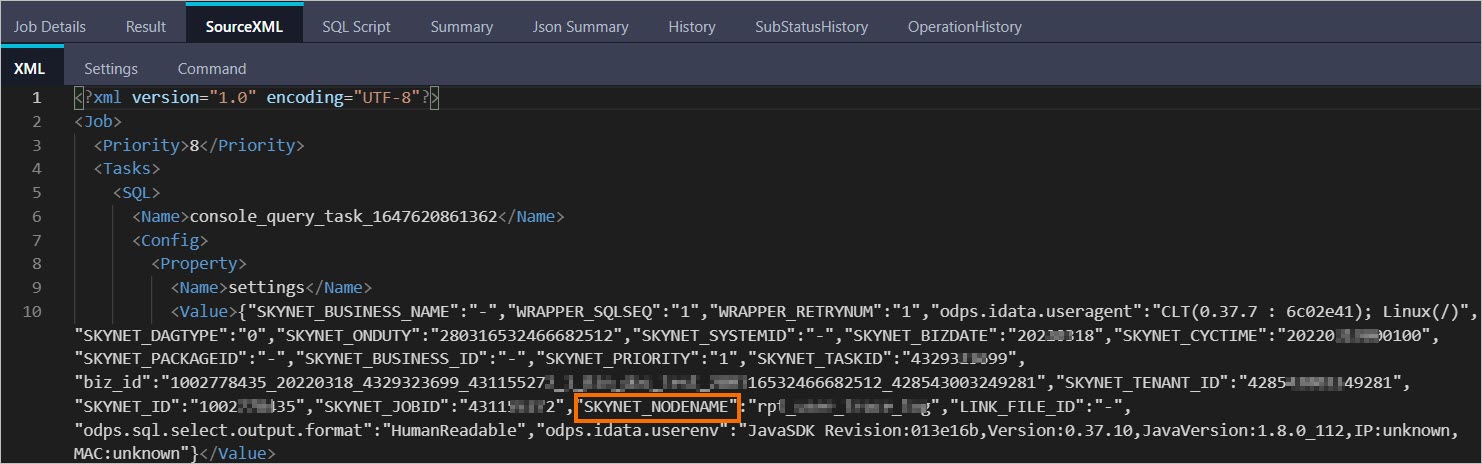 說明
說明關于Logview的介紹,詳情請參見使用Logview 2.0查看作業運行信息。
如果獲取不到SKYNET_NODENAME或SKYNET_NODENAME無值,您可以在SQL Script頁簽獲取代碼片段后,在DataWorks上通過搜索代碼片段,獲取目標節點進行優化。詳情請參見DataWorks代碼搜索。
在DataWorks中,搜索查詢到的SKYNET_NODENAME,對目標節點進行優化。
分析作業增長趨勢
通常費用的增長是由于重復執行或調度屬性配置不合理造成作業量暴漲導致。
通過Excel分析:分析用量明細中數據分類為ComputationSql的數據。統計各項目每天的作業數量,觀察是否存在某些項目作業數量波動較大。
通過SQL分析(已完成步驟二的數據導入,生成maxcomputefee表):
--分析作業增長趨勢。 SELECT TO_CHAR(endtime,'yyyymmdd') AS ds ,projectid ,COUNT(*) AS tasknum FROM maxcomputefee WHERE TYPE = 'ComputationSql' AND TO_CHAR(endtime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(endtime,'yyyymmdd') ,projectid ORDER BY tasknum DESC LIMIT 10000 ;執行結果如下。
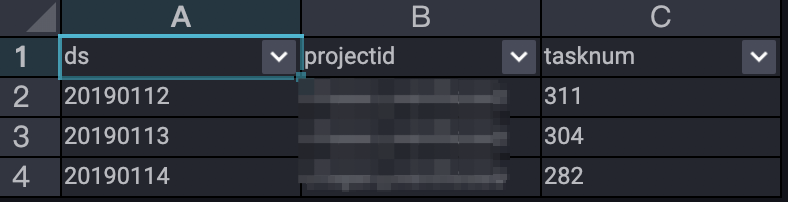 從執行結果可以看出12~14日提交到MaxCompute且執行成功的作業數的波動趨勢。
從執行結果可以看出12~14日提交到MaxCompute且執行成功的作業數的波動趨勢。
分析存儲費用
存儲費用的計費規則相對復雜。明細中是按每個小時取一次得出的數據。按照MaxCompute存儲計費規則,會先整體24小時求和,再將平均之后的值進行階梯收費。詳情請參見存儲費用。
通過Excel分析存儲收取1分錢的原因:
開通MaxCompute進行試用,當前沒有業務在MaxCompute上運行,但是每天都有1分錢賬單,此問題一般是因為有存留數據在MaxCompute上存儲,且數據量不超過0.5 GB。
通過Excel分析
不足一天的數據存儲費用: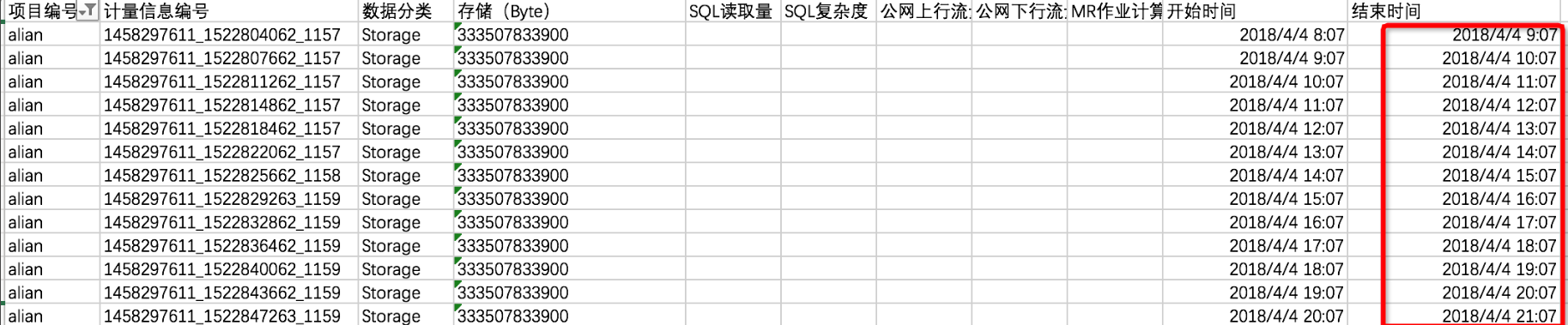
查看數據分類中的Storage存儲計費項,會發現在alian項目下存儲了333507833900字節數據,由于是8點上傳的數據,所以從09:07開始計量存儲費用,一共計量15小時。
說明天計量范圍以當天的結束時間為準,所以最后一條數據不包括在4月4日賬單中。
按照存儲費用計費規則先計算24小時存儲平均值,再根據計費公式進行計算。
--計算存儲平均值。 333507833900 Byte×15/1024/1024/1024/24=194.127109076362103 GB --一天的存儲費用計算如下,結果保留4位小數。 194.127109076362103GB×0.004元/GB/天=0.7765元/天
通過SQL分析存儲費用的分布(已完成步驟二的數據導入,生成maxcomputefee表):
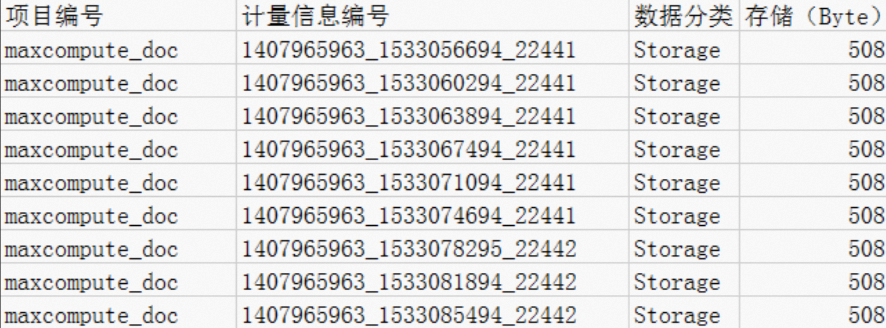
--分析存儲費用。 SELECT t.ds ,t.projectid ,t.storage ,CASE WHEN t.storage < 0.5 THEN t.storage*0.01 ---當項目的實際數據存儲量大于0 MB小于等于512MB時,計費單價為0.01元/GB/天 WHEN t.storage >= 0.5 THEN t.storage*0.004 ---當項目的實際數據存儲量大于512MB時,計費單價為0.004元/GB/天 END storage_fee FROM ( SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(storage/1024/1024/1024)/24 AS storage FROM maxcomputefee WHERE TYPE = 'Storage' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid ) t ORDER BY storage_fee DESC ;執行結果如下。
 根據執行結果可以分析得出如下結論:
根據執行結果可以分析得出如下結論:存儲在12日有一個增長的過程,但在14日出現降低。
存儲優化,建議為表設置生命周期,刪除長期不使用的臨時表等。
通過SQL分析長期存儲、低頻存儲、長期存儲訪問和低頻存儲訪問的分布。(已完成步驟二的數據導入,生成maxcomputefee表):
--分析長期存儲費用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(storage/1024/1024/1024)/24*0.0011 AS longTerm_storage FROM maxcomputefee WHERE TYPE = 'ColdStorage' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid; --分析低頻存儲費用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(storage/1024/1024/1024)/24*0.0011 AS lowFre_storage FROM maxcomputefee WHERE TYPE = 'LowFreqStorage' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid; --分析長期存儲訪問費用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(computationsqlinput/1024/1024/1024)*0.522 AS longTerm_IO FROM maxcomputefee WHERE TYPE = 'SqlLongterm' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid; --分析低頻存儲訪問費用。 SELECT to_char(starttime,'yyyymmdd') as ds ,projectid ,SUM(computationsqlinput/1024/1024/1024)*0.522 AS lowFre_IO FROM maxcomputefee WHERE TYPE = 'SqlLowFrequency' and to_char(starttime,'yyyymmdd') >= '20190112' GROUP BY to_char(starttime,'yyyymmdd') ,projectid;
 如果這份數據只用于測試,您可以通過以下方式解決此問題。
如果這份數據只用于測試,您可以通過以下方式解決此問題。分析下載費用
對于外網或者跨區域的數據下載,MaxCompute將按照下載的數據量進行計費。
一次下載費用=下載數據量×單價(0.8元/GB)。
通過Excel分析:數據分類為DownloadEx代表公網下載計費項。

公網下行流量產生了一條約0.036 GB(38199736 Byte)的下行流量,根據數據傳輸費用(公網下載)標準,產生費用為
(38199736byte/1024/1024/1024)× 0.8 元/GB=0.028元。下載優化舉例。查看您的Tunnel設置的Service,是否因為設置了公共網絡產生費用,更多信息請參見Endpoint。如果是大批量下載,您本地在蘇州,Region在華東2(上海),則可以先通過華東2(上海)的ECS把數據下載到虛擬機,然后利用ECS包月下載資源。
通過SQL分析下載費用的分布(已完成步驟二的數據導入,生成maxcomputefee表):
--分析下載消費明細。 SELECT TO_CHAR(starttime,'yyyymmdd') AS ds ,projectid ,SUM((download/1024/1024/1024)*0.8) AS download_fee FROM maxcomputefee WHERE type = 'DownloadEx' AND TO_CHAR(starttime,'yyyymmdd') >= '20190112' GROUP BY TO_CHAR(starttime,'yyyymmdd') ,projectid ORDER BY download_fee DESC ;按照執行結果也可以分析出某個時間段內的下載費用走勢。另外可以通過
tunnel show history命令查看具體歷史信息,具體命令詳見Tunnel命令。
分析MapReduce作業消費
標準MapReduce作業當日計算費用 = 當日總計算時×單價(0.46元/計算時)
SpotMapReduce作業當日計算費用 = 當日總計算時×單價(0.154元/計算時)
通過Excel分析:分析用量明細中數據分類為MapReduce的數據。按照計算資源規格分別對MapReduce作業費用進行計算及排序。
通過SQL分析(已完成步驟二的數據導入,生成maxcomputefee表):
--分析MapReduce作業消費。 SELECT REPLACE(SUBSTR(endtime,1,10),'-','') AS ds, feeid AS instanceid , projectid , source_type , (cu_usage/3600) as cuh, CASE WHEN source_type ='OdpsSpot' THEN (cu_usage/3600)*0.154 ELSE (cu_usage/3600)*0.46 END AS mr_fee FROM maxcomputefee WHERE TYPE = 'MapReduce' AND REPLACE(SUBSTR(endtime,1,10),'-','')>= '20230701' GROUP BY REPLACE(SUBSTR(endtime,1,10),'-','') ,feeid , projectid , source_type, (cu_usage/3600) ORDER BY mr_fee DESC LIMIT 10000 ;
分析外部表作業(OTS和OSS)
一次SQL外部表計算費用 = 計算輸入數據量×單價(0.03元/GB)
通過Excel分析:分析用量明細中數據分類為ComputationSqlOTS、ComputationSqlOSS的數據。對SQL外部表計算費用進行排序,費用計算公式為
(SQL/交互式分析讀取量(Byte)/1024/1024/1024 × 單價(0.03))。通過SQL分析(已完成步驟二的數據導入,生成maxcomputefee表):
--分析OTS外部表SQL作業消費。 SELECT REPLACE(SUBSTR(endtime,1,10),'-','') AS ds ,feeid ,projectid ,source_type ,SUM((computationsqlinput / 1024 / 1024 / 1024)) AS computationsqlinput ,(computationsqlinput/1024/1024/1024)*1*0.03 AS ots_fee FROM maxcomputefee WHERE type = 'ComputationSqlOTS' AND REPLACE(SUBSTR(endtime,1,10),'-','') >= '20230701' GROUP BY REPLACE(SUBSTR(endtime,1,10),'-','') ,feeid ,projectid ,source_type ,computationsqlinput ORDER BY ots_fee DESC LIMIT 10000 ; --分析OSS外部表SQL作業消費。 SELECT REPLACE(SUBSTR(endtime,1,10),'-','') AS ds ,feeid ,projectid ,source_type ,SUM((computationsqlinput / 1024 / 1024 / 1024)) AS computationsqlinput ,(computationsqlinput/1024/1024/1024)*1*0.03 AS ots_fee FROM maxcomputefee WHERE type = 'ComputationSqlOSS' AND REPLACE(SUBSTR(endtime,1,10),'-','') >= '20230701' GROUP BY REPLACE(SUBSTR(endtime,1,10),'-','') ,feeid ,projectid ,source_type ,computationsqlinput ORDER BY ots_fee DESC LIMIT 10000 ;
分析Spark計算費用
標準Spark作業當日計算費用 = 當日總計算時×單價(0.66元/計算時)
SpotSpark作業當日計算費用 = 當日總計算時×單價(0.22元/計算時)
通過Excel分析:分用量明細中數據分類為spark的數據。對作業費用進行排序,計算公式為
(MR/Spark作業計算(Core*Second)/3600 × 單價(0.66))(MR/Spark作業計算(Core*Second)/3600 × 單價(0.1041))。通過SQL分析(已完成步驟二的數據導入,生成maxcomputefee表):
--分析Spark作業消費。 SELECT REPLACE(SUBSTR(endtime,1,10),'-','') AS ds, feeid AS instanceid , projectid , source_type , (cu_usage/3600) as cuh, CASE WHEN source_type ='OdpsSpot' THEN (cu_usage/3600)*0.22 ELSE (cu_usage/3600)*0.66 END AS spark_fee FROM maxcomputefee WHERE TYPE = 'spark' AND REPLACE(SUBSTR(endtime,1,10),'-','')>= '20230701' GROUP BY REPLACE(SUBSTR(endtime,1,10),'-','') ,feeid , projectid , source_type, (cu_usage/3600) ORDER BY spark_fee DESC LIMIT 10000 ;
更多信息
如果您想了解更多關于費用成本優化的文章,請參見成本優化概述。
相關文檔
TO_CHAR函數分為字符串類型和日期類型兩種,關于TO_CHAR函數的詳情,請參見TO_CHAR。