分區表是指擁有分區空間的表,即將表數據按照某個列或多個列進行劃分,從而將表中的數據分散存儲在不同的物理位置上。合理設計和使用分區,可以提高查詢性能、簡化數據管理,并支持更靈活的數據訪問和操作。
概述
分區可以理解為分類,通過分類把不同類型的數據放到不同的目錄下。分類的標準就是分區字段,可以是一個,也可以是多個。
MaxCompute將分區列的每個值作為一個分區(目錄),您可以指定多級分區,即將表的多個字段作為表的分區,分區之間類似多級目錄的關系。
分區表的意義在于優化查詢。查詢表時通過WHERE子句查詢指定所需查詢的分區,避免全表掃描,提高處理效率,降低計算費用。使用數據時,如果指定需要訪問的分區名稱,則只會讀取相應的分區。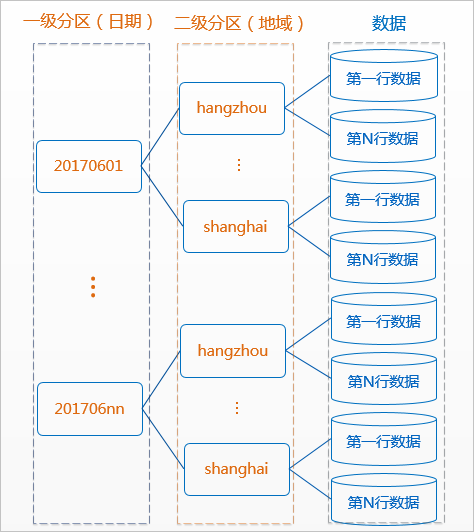
部分對分區操作的SQL的運行效率較低,會給您帶來較高的費用,例如插入或覆寫動態分區數據(DYNAMIC PARTITION)。
使用限制
單表分區層級最多為6級。
單表分區數最大值為60000個。
單次查詢允許查詢最多的分區個數為10000個。
STRING分區類型的分區值不支持使用中文。
使用說明
分區數據不宜過小,如果創建很多過小分區,會導致計算查詢性能下降。建議單分區數據不要小于一萬行。
分區列的數據類型
MaxCompute 2.0數據類型版本支持的分區字段為TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING。
在Meta中表的分區值通常以STRING類型進行存儲。對于非字符串類型的分區字段,其值會在內部被自動轉換為字符串類型。為避免因數據類型轉換導致的異常,建議在設計分區字段時使用STRING類型。
MaxCompute 1.0數據類型版本支持的分區字段僅有STRING。雖然可以指定分區列的類型為BIGINT,但是除了表的字段顯示為BIGINT類型,任何其他情況(例如,字段的計算和比較)下都當作STRING類型處理。執行如下語句后,返回結果為空。
---創建表parttest。
create table parttest (a bigint) partitioned by (pt bigint);
---向表中插入數據。
insert into parttest partition(pt)(a,pt) values (1, 1);
insert into parttest partition(pt)(a,pt) values (1, 10);
---查詢表中字段pt大于等于2的行。
select * from parttest where pt >= '2';示例
創建分區。
--創建一個二級分區表,以日期為一級分區,地域為二級分區 CREATE TABLE src (shop_name string, customer_id bigint) PARTITIONED BY (pt string,region string);使用分區列作為過濾條件查詢數據。
--正確使用方式。MaxCompute在生成查詢計劃時只會將'20170601'分區下region為'hangzhou'二級分區的數據納入輸入中。 select * from src where pt='20170601'and region='hangzhou'; --錯誤的使用方式。在這樣的使用方式下,MaxCompute并不能保障分區過濾機制的有效性。pt是STRING類型,當STRING類型與BIGINT(20170601)比較時,MaxCompute會將二者轉換為DOUBLE類型,此時有可能會有精度損失。 select * from src where pt = 20170601;
相關文檔
分區相關操作(如添加分區、修改分區值等)命令請參見分區和列操作。