本文為您介紹如何將同步至MaxCompute的用戶信息表ods_user_info_d及訪問日志數據ods_raw_log_d,通過DataWorks的ODPS SQL節點加工得到目標用戶畫像數據,閱讀本文后您可了解到如何通過DataWorks+MaxCompute產品組合來計算和分析已同步的數據,完成數倉簡單數據加工場景。
前提條件
開始本實驗前,請首先完成同步數據中的操作。
已通過數據集成將存儲于MySQL的用戶基本信息(ods_user_info_d)同步至MaxCompute的ods_user_info_d表。
已通過數據集成將存儲于OSS的網站訪問日志(user_log.txt)同步至MaxCompute的ods_raw_log_d表。
快速體驗
本案例中,數據同步和數據加工的部分任務可以通過ETL工作流模板一鍵導入。在導入模板后,您可以前往目標空間,并自行完成后續的數據質量監控和數據可視化操作。
僅空間管理員角色可導入ETL模板至目標工作空間,為賬號授權空間管理員角色詳情請參見空間級模塊權限管控。
導入ETL工作流模板,詳情請參見ETL工作流快速體驗。
ETL工作流模板快捷入口,請點擊網站用戶行為分析。
背景信息
數據開發DataStudio提供豐富的節點,并對引擎能力進行封裝,本案例使用ODPS SQL節點對同步至MaxCompute的用戶數據與訪問日志數據進行分層加工,具體邏輯請參照下文。
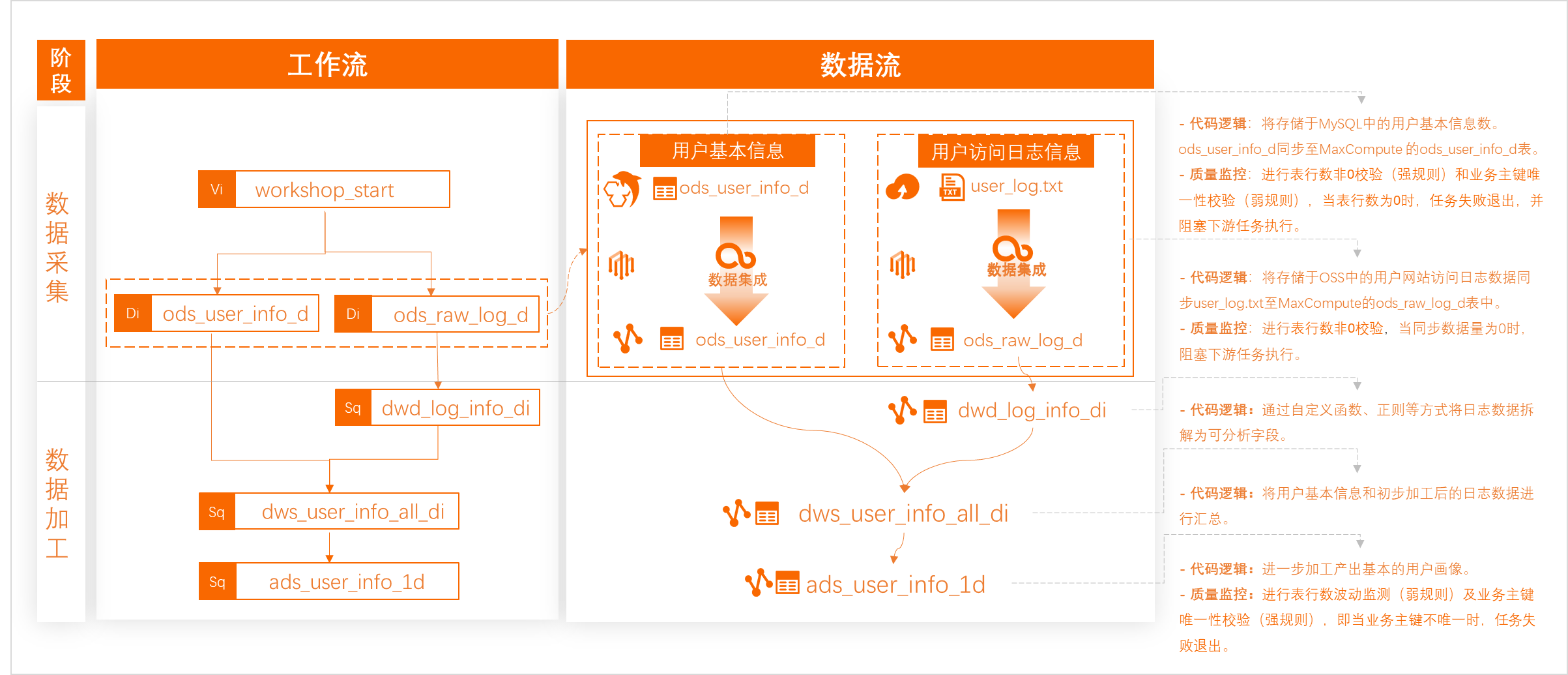
業務流程管控:
使用虛擬節點統籌管理整個業務流程,例如整個用戶行為分析畫像業務流程調起時間、是否運行等。本案例設置加工任務為日調度任務,并通過指定workshop_start節點實現整個工作流每日00:15開始調度。
增量數據加工:
使用調度參數,通過分區名+動態參數的方式,實現調度場景下,每日將增量數據寫入目標表對應時間分區。
數據加工過程:
使用可視化方式上傳資源并注冊自定義函數getregion,將系統日志數據中的IP信息轉換為地域信息。
依賴關系設置:
使用自動解析機制,根據節點代碼血緣自動設置節點依賴關系,保障下游取數無誤。
重要建議實際開發時嚴格遵守以下節點開發規范,這樣更有利于調度依賴自動解析,避免非預期報錯產生。更多關于調度依賴的原理,請參見調度依賴配置指引。
節點和產出表存在一對一關系。
節點名命名與產出表名保持一致。
進入數據開發
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
步驟一:新建MaxCompute表
提前新建dwd_log_info_di、dws_user_info_all_di、ads_user_info_1d表,用于存放每層加工后的數據。以下僅快速創建相關表,更多MaxCompute表相關操作,請參見創建并使用MaxCompute表。
進入新建表入口。
在數據開發頁面,打開數據同步階段創建的業務流程WorkShop。右鍵單擊MaxCompute,選擇新建表。
定義MaxCompute表結構。
在新建表對話框中,輸入表名,單擊新建。此處需要創建三張表,表名分別為dwd_log_info_di、dws_user_info_all_di、ads_user_info_1d。選擇DDL方式建表,三張表建表命令請參考下文。
提交至引擎生效。
表結構定義完成后,分別單擊提交到開發環境和提交到生產環境,系統將根據您的配置在開發環境與生產環境對應計算引擎項目分別創建目標引擎物理表。
提交表至DataWorks的開發環境,即在開發環境的MaxCompute引擎中創建當前表。
提交表至DataWorks的生產環境,即在生產環境的MaxCompute引擎中創建當前表。
說明若使用簡單模式的工作空間,僅需將表提交至生產環境。簡單模式與標準模式工作空間的介紹,詳情請參見必讀:簡單模式和標準模式的區別。
DataWorks與MaxCompute關系及對應環境的MaxCompute引擎,詳情請參見:DataWorks On MaxCompute使用說明。
1、新建dwd_log_info_di表
雙擊dwd_log_info_di表,在右側的編輯頁面單擊DDL,輸入下述建表語句。
CREATE TABLE IF NOT EXISTS dwd_log_info_di (
ip STRING COMMENT 'ip地址',
uid STRING COMMENT '用戶ID',
time STRING COMMENT '時間yyyymmddhh:mi:ss',
status STRING COMMENT '服務器返回狀態碼',
bytes STRING COMMENT '返回給客戶端的字節數',
region STRING COMMENT '地域,根據ip得到',
method STRING COMMENT 'http請求類型',
url STRING COMMENT 'url',
protocol STRING COMMENT 'http協議版本號',
referer STRING COMMENT '來源url',
device STRING COMMENT '終端類型 ',
identity STRING COMMENT '訪問類型 crawler feed user unknown'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;2、新建dws_user_info_all_di表
雙擊dws_user_info_all_di表,在右側的編輯頁面單擊DDL,輸入下述建表語句。
CREATE TABLE IF NOT EXISTS dws_user_info_all_di (
uid STRING COMMENT '用戶ID',
gender STRING COMMENT '性別',
age_range STRING COMMENT '年齡段',
zodiac STRING COMMENT '星座',
region STRING COMMENT '地域,根據ip得到',
device STRING COMMENT '終端類型 ',
identity STRING COMMENT '訪問類型 crawler feed user unknown',
method STRING COMMENT 'http請求類型',
url STRING COMMENT 'url',
referer STRING COMMENT '來源url',
time STRING COMMENT '時間yyyymmddhh:mi:ss'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;3、新建ads_user_info_1d表
雙擊ads_user_info_1d表,在右側的編輯頁面單擊DDL,輸入下述建表語句。
CREATE TABLE IF NOT EXISTS ads_user_info_1d (
uid STRING COMMENT '用戶ID',
region STRING COMMENT '地域,根據ip得到',
device STRING COMMENT '終端類型 ',
pv BIGINT COMMENT 'pv',
gender STRING COMMENT '性別',
age_range STRING COMMENT '年齡段',
zodiac STRING COMMENT '星座'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14; 步驟二:創建函數(getregion)
根據同步的原始日志數據格式,我們需要通過函數等方式將其拆解為目標格式。本案例已為您提供用于將IP解析為地域的函數所需資源,您僅需將其下載至本地,并在DataWorks注冊函數前,將函數涉及的資源上傳至DataWorks空間即可。
該函數僅為本教程使用(IP資源樣例),若需在正式業務中實現IP到地理位置的映射功能,需前往專業IP網站獲取相關IP轉換服務。
1、上傳資源(ip2region.jar)
- 說明
ip2region.jar此資源樣例僅為教程使用。 在數據開發頁面打開WorkShop業務流程。右鍵單擊MaxCompute,選擇。
單擊上傳,選擇已下載至本地的ip2region.jar,單擊打開。
說明請選中上傳為ODPS資源。
資源名稱無需與上傳的文件名保持一致。
單擊工具欄
 按鈕,將資源提交至開發環境對應的MaxCompute引擎項目。
按鈕,將資源提交至開發環境對應的MaxCompute引擎項目。
2、注冊函數(getregion)
進入函數注冊頁。
在數據開發頁面打開業務流程,右鍵單擊MaxCompute,選擇新建函數。
填寫函數名稱。
在新建函數對話框中,輸入函數名稱(getregion),單擊新建。
在注冊函數對話框中,配置各項參數。
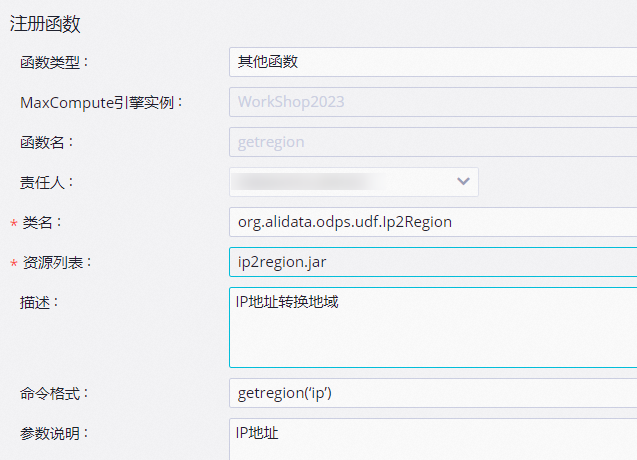
參數
描述
函數類型
選擇函數類型。
MaxCompute引擎實例
默認不可以修改。
函數名
新建函數時輸入的函數名稱。
責任人
選擇責任人。
類名
輸入org.alidata.odps.udf.Ip2Region。
資源列表
輸入ip2region.jar。
描述
輸入IP地址轉換地域。
命令格式
輸入getregion('ip')。
參數說明
輸入IP地址。
提交函數。
單擊
按鈕,將函數提交至開發環境對應的引擎。
步驟三:配置ODPS SQL節點
本案例需要將每層加工邏輯通過ODPS SQL調度實現,由于各層節點間存在強血緣依賴,并且在數據同步階段已將同步任務產出表手動添加為節點的輸出,所以本案例數據加工類的任務依賴關系通過DataWorks自動解析機制根據血緣自動配置。
請按照順序依次創建,否則將可能產生非預期報錯。
打開業務流程。
在數據開發頁面,雙擊同步數據階段創建的業務流程名,本案例業務流程名為WorkShop。
新建節點。
在該業務流程下,右鍵單擊MaxCompute,選擇新建節點 >ODPS SQL。本案例需要依次創建如下三個節點:dwd_log_info_di、dws_user_info_all_di、ads_user_info_1d,具體配置如下。
1、配置dwd_log_info_di節點
使用步驟二創建的getregion函數對ods_raw_log_d表中的IP信息進行解析,并使用正則等方式,拆解為可分析字段寫入dwd_log_info_di表,dwd加工前后數據比對,可參見附錄:加工示例。
1. 編輯代碼
在業務流程面板中,雙擊打開dwd_log_info_di節點,并配置如下代碼,DataWorks通過${變量名}格式定義代碼變量。其中代碼中的${bizdate}為代碼變量,該變量將在后續步驟2中為其賦值。
-- 場景:以下SQL使用函數getregion對原始日志數據中的ip進行解析,并通過正則等方式,將原始數據拆解為可分析字段寫入并寫入dwd_log_info_di表。
-- 本案例已為您準備好用于將IP解析為地域的函數getregion。
-- 補充:
-- 1. 在DataWorks節點中使用函數前,您需要先將注冊函數所需資源上傳至DataWorks,再通過可視化方式使用該資源注冊函數,詳見:http://bestwisewords.com/document_detail/136928.html
-- 本案例注冊函數getregion所用的資源為ip2region.jar。
-- 2. DataWorks提供調度參數,可實現調度場景下,將每日增量數據寫入目標表對應業務分區。
-- 在實際開發場景下,您可通過${變量名}格式定義代碼變量,并在調度配置頁面通過為變量賦值調度參數的方式,實現調度場景下代碼動態入參。
INSERT OVERWRITE TABLE dwd_log_info_di PARTITION (dt='${bizdate}')
SELECT ip
, uid
, time
, status
, bytes
, getregion(ip) AS region --使用自定義UDF通過IP得到地域。
, regexp_substr(request, '(^[^ ]+ )') AS method --通過正則把request差分為3個字段。
, regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url
, regexp_substr(request, '([^ ]+$)') AS protocol
, regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer --通過正則清晰refer,得到更精準的URL。
, CASE
WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' --通過agent得到終端信息和訪問形式。
WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone'
WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad'
WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh'
WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone'
WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc'
ELSE 'unknown'
END AS device
, CASE
WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler'
WHEN TOLOWER(agent) RLIKE 'feed'
OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed'
WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)'
AND agent RLIKE '^[Mozilla|Opera]'
AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user'
ELSE 'unknown'
END AS identity
FROM (
SELECT SPLIT(col, '##@@')[0] AS ip
, SPLIT(col, '##@@')[1] AS uid
, SPLIT(col, '##@@')[2] AS time
, SPLIT(col, '##@@')[3] AS request
, SPLIT(col, '##@@')[4] AS status
, SPLIT(col, '##@@')[5] AS bytes
, SPLIT(col, '##@@')[6] AS referer
, SPLIT(col, '##@@')[7] AS agent
FROM ods_raw_log_d
WHERE dt ='${bizdate}'
) a;2. 配置調度屬性
通過以下配置實現調度場景下,每日00:15待上游ods_raw_log_d節點將存儲于OSS的user_log.txt數據同步至MaxCompute的ods_raw_log_d表后,可觸發當前dwd_log_info_di節點對ods_raw_log_d表數據進行加工,加工結果寫入dwd_log_info_di表對應業務時間分區。
配置調度參數:為代碼中的變量bizdate賦值$[yyyymmdd-1],獲取前一天的日期。
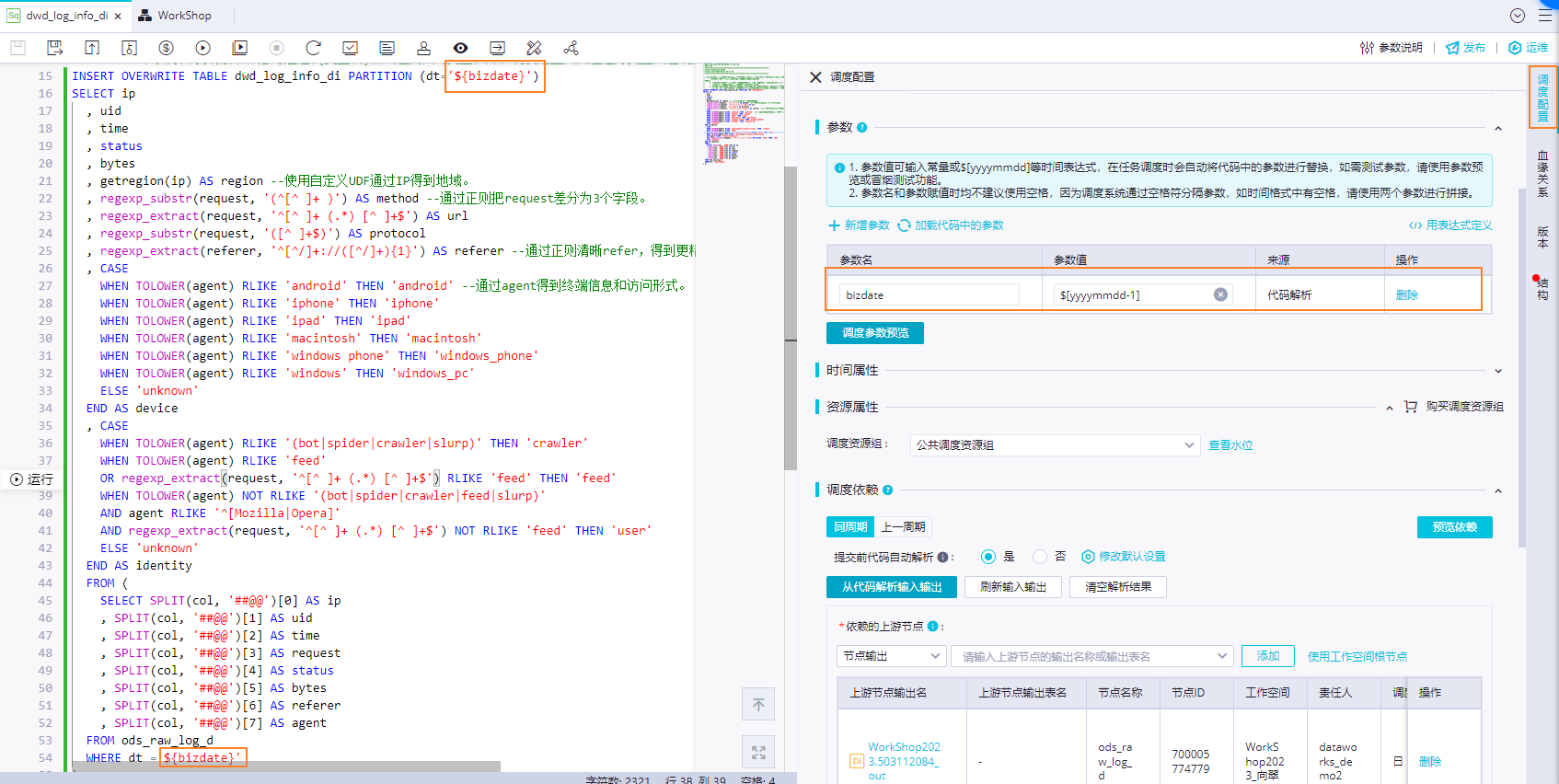
配置定時調度時間:配置調度周期為日,無需單獨配置當前節點定時調度時間,當前節點每日調起時間由業務流虛擬節點workshop_start的定時調度時間控制,即每日00:15后才會調度。
配置依賴關系:通過代碼自動解析自動將產出ods_raw_log_d表數據的ods_raw_log_d節點設置為當前節點dwd_log_info_di的上游依賴。將dwd_log_info_di表作為節點輸出,方便下游查詢該表數據時自動掛上當前節點依賴。
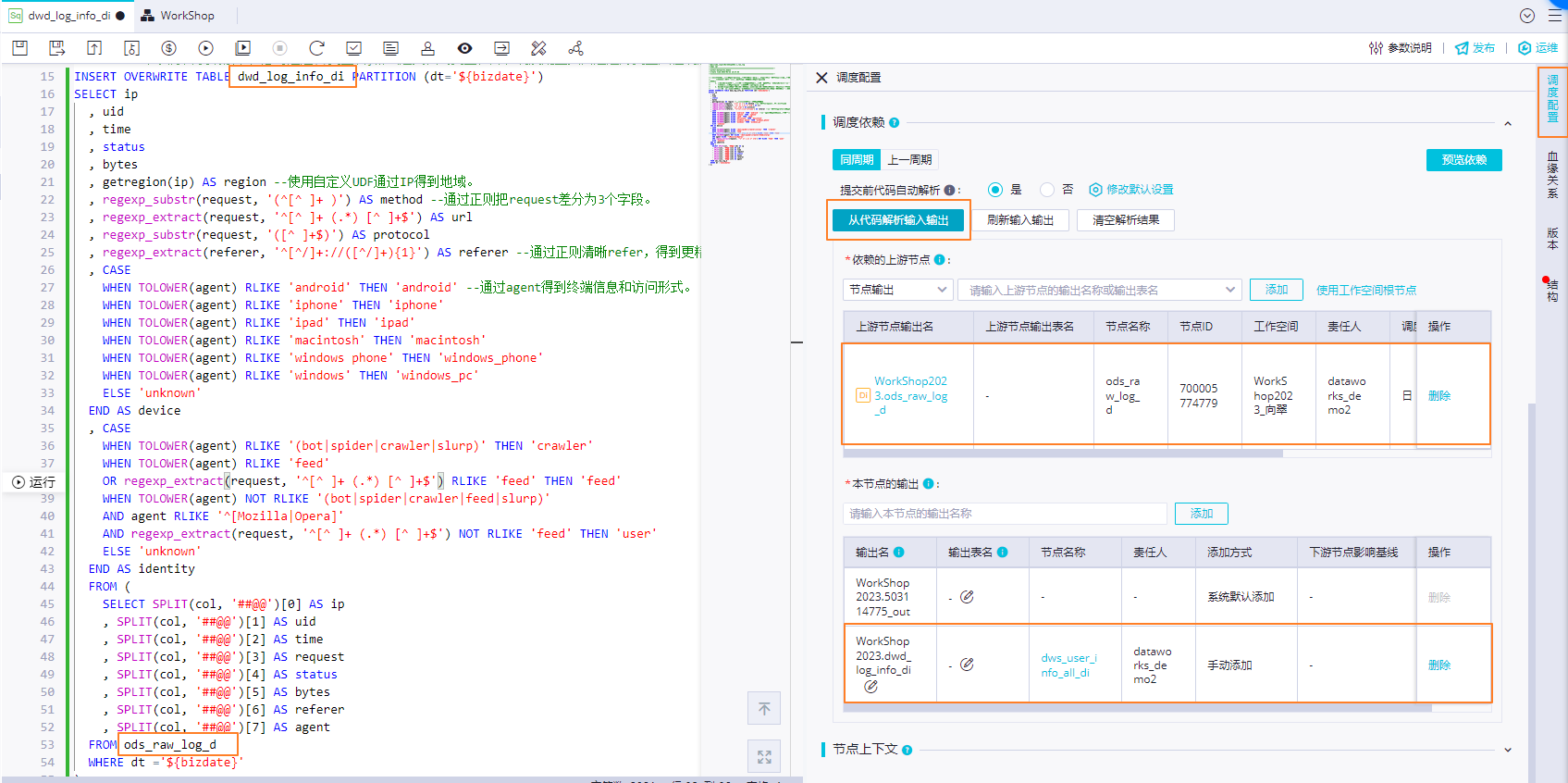 說明
說明DataWorks節點輸出是其他節點與當前節點建立依賴關系的媒介。DataWorks通過將上游節點的節點輸出作為下游節點的節點輸入,形成節點間的依賴關系。
系統會為每個節點自動生成兩個輸出名,格式分別為:projectName.randomNumber_out、projectName.nodeName_out。
如果使用自動解析功能,系統將根據代碼解析結果為節點生成輸出名,格式為:projectName.tableName。
3. 保存配置
本案例其他必填配置項,您可按需自行配置,配置完成后,在節點代碼編輯頁面,單擊工具欄中的![]() 按鈕,保存當前配置。
按鈕,保存當前配置。
2、配置dws_user_info_all_di節點
對同步到MaxCompute的用戶基本信息數據ods_user_info_d和初步加工后的日志數據dwd_log_info_di進行匯總,產出用戶訪問信息匯總表dws_user_info_all_di。
1. 編輯代碼
在業務流程面板中,雙擊打開dws_user_info_all_di節點,并配置如下代碼,DataWorks通過${變量名}格式定義代碼變量。其中代碼中的${bizdate}為代碼變量,該變量將在后續步驟2中為其賦值。
-- 場景:將加工后的日志數據dwd_log_info_di與用戶基本信息數據ods_user_info_d匯總寫入dws_user_info_all_di表。
-- 補充:DataWorks提供調度參數,可實現調度場景下,將每日增量數據寫入目標表對應業務分區。
-- 在實際開發場景下,您可通過${變量名}格式定義代碼變量,并在調度配置頁面通過為變量賦值調度參數的方式,實現調度場景下代碼動態入參。
INSERT OVERWRITE TABLE dws_user_info_all_di PARTITION (dt='${bizdate}')
SELECT COALESCE(a.uid, b.uid) AS uid
, b.gender
, b.age_range
, b.zodiac
, a.region
, a.device
, a.identity
, a.method
, a.url
, a.referer
, a.time
FROM (
SELECT *
FROM dwd_log_info_di
WHERE dt = '${bizdate}'
) a
LEFT OUTER JOIN (
SELECT *
FROM ods_user_info_d
WHERE dt = '${bizdate}'
) b
ON a.uid = b.uid;2. 配置調度屬性
通過以下配置實現調度場景下,每日00:15待上游MySQL用戶基本數據通過數據集成同步至MaxCompute的ods_user_info_d表,以及dwd_log_info_di節點對ods_raw_log_d表加工完成后,將其匯總寫入dws_user_info_all_di表對應業務分區。
配置調度參數:為代碼中的變量bizdate賦值$[yyyymmdd-1],獲取前一天的日期。
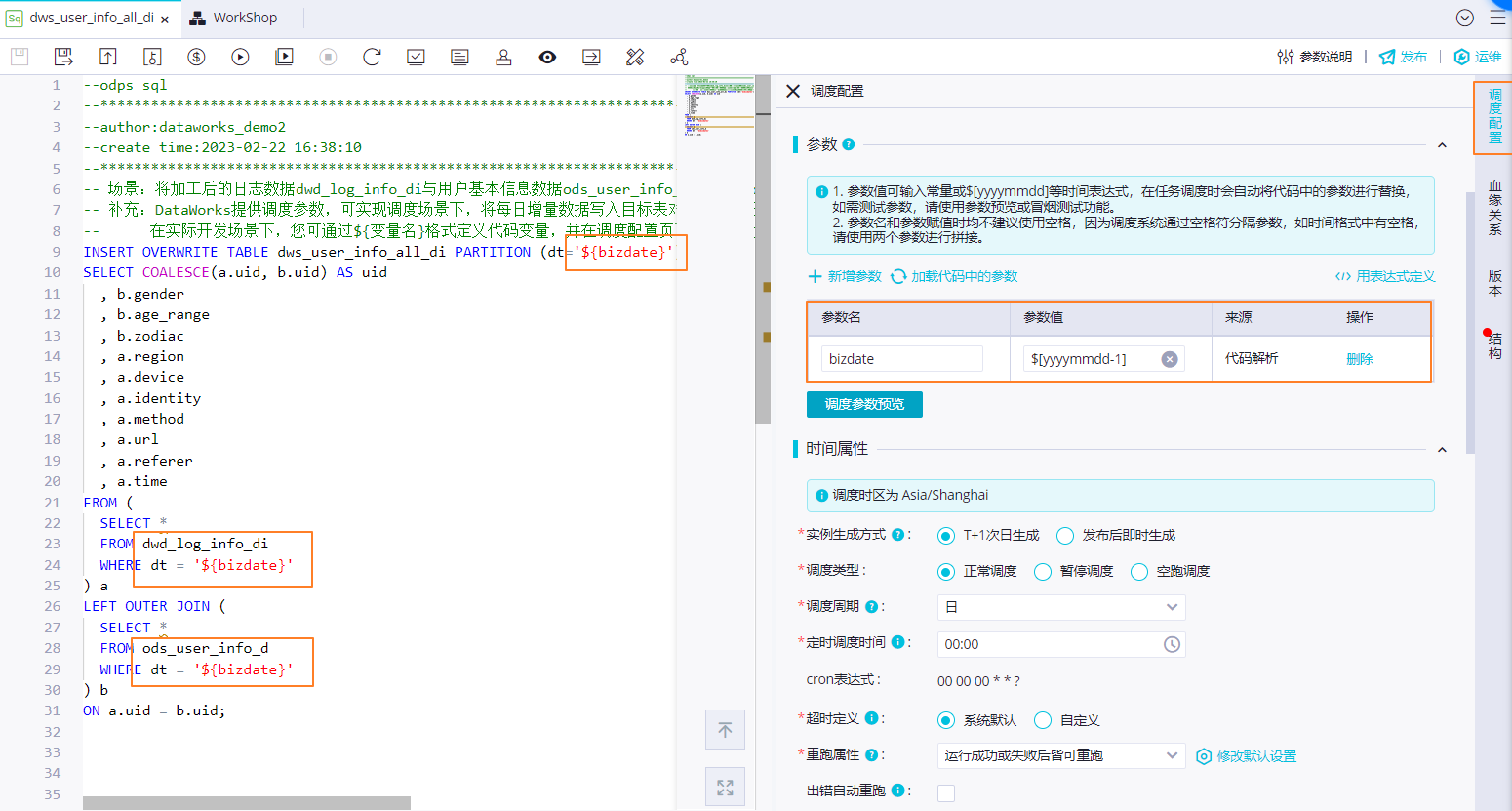
配置定時調度時間:配置調度周期為日,無需單獨配置當前節點定時調度時間,當前節點每日起調時間由業務流虛擬節點workshop_start的定時調度時間控制,即每日00:15分后才會調度。
配置依賴關系:通過代碼自動解析自動將產出dwd_log_info_di和ods_user_info_d表數據的節點dwd_log_info_di、ods_user_info_d作為當前節點dws_user_info_all_di的上游依賴。將節點產出表dws_user_info_all_di作為節點輸出,方便下游查詢該表數據時自動掛上當前節點依賴。
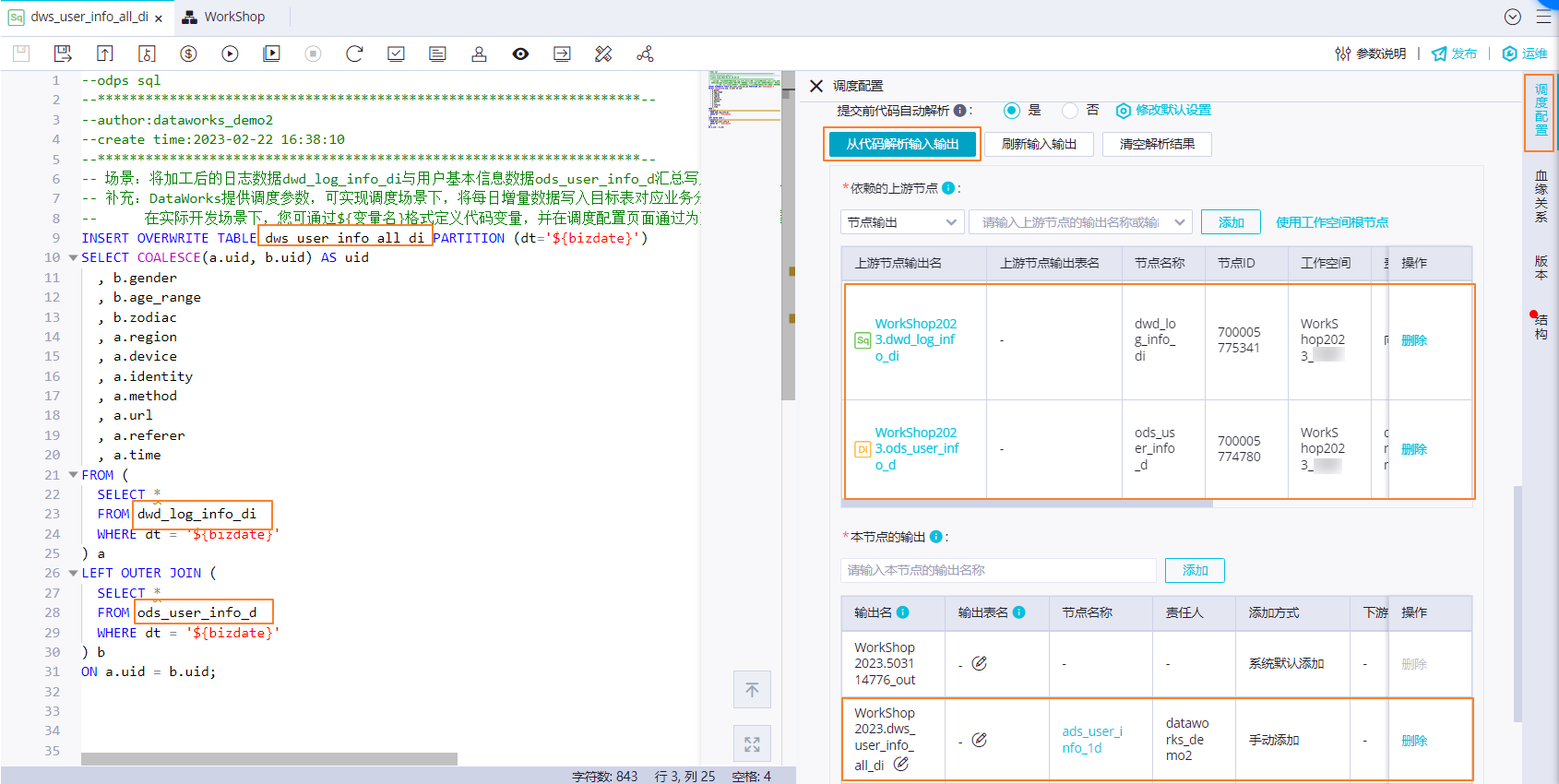
3. 保存配置
本案例其他必填配置項,您可按需自行配置,配置完成后,在節點代碼編輯頁面,單擊工具欄中的![]() 按鈕,保存當前配置。
按鈕,保存當前配置。
3、配置ads_user_info_1d節點
對用戶訪問信息匯總表dws_user_info_all_di進一步加工產出基本的用戶畫像數據ads_user_info_1d。
1. 編輯代碼
在業務流程面板中,雙擊打開ads_user_info_1d節點,并配置如下代碼,DataWorks通過${變量名}格式定義代碼變量。其中代碼中的${bizdate}為代碼變量,該變量將在后續步驟2中為其賦值。
-- 場景:以下SQL用于對用戶訪問信息寬表dws_user_info_all_di進一步加工產出基本的用戶畫像數據寫入ads_user_info_1d表。
-- 補充:DataWorks提供調度參數,可實現調度場景下,將每日增量數據寫入目標表對應業務分區。
-- 在實際開發場景下,您可通過${變量名}格式定義代碼變量,并在調度配置頁面通過為變量賦值調度參數的方式,實現調度場景下代碼動態入參。
INSERT OVERWRITE TABLE ads_user_info_1d PARTITION (dt='${bizdate}')
SELECT uid
, MAX(region)
, MAX(device)
, COUNT(0) AS pv
, MAX(gender)
, MAX(age_range)
, MAX(zodiac)
FROM dws_user_info_all_di
WHERE dt = '${bizdate}'
GROUP BY uid; 2. 配置調度屬性
為實現周期調度,我們需要定義任務周期調度的相關屬性。
配置調度參數:為代碼中的變量bizdate賦值$[yyyymmdd-1],獲取前一天的日期。
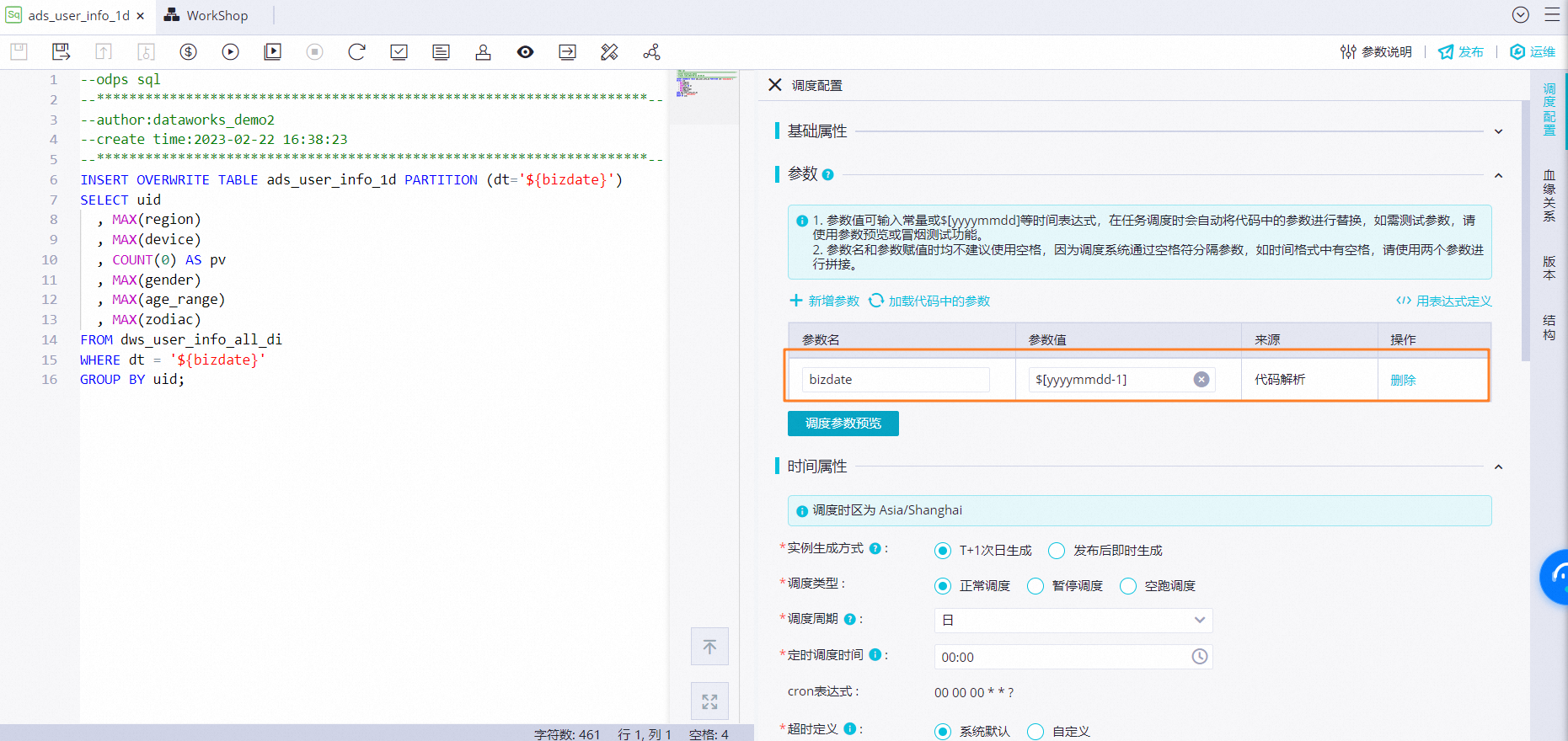
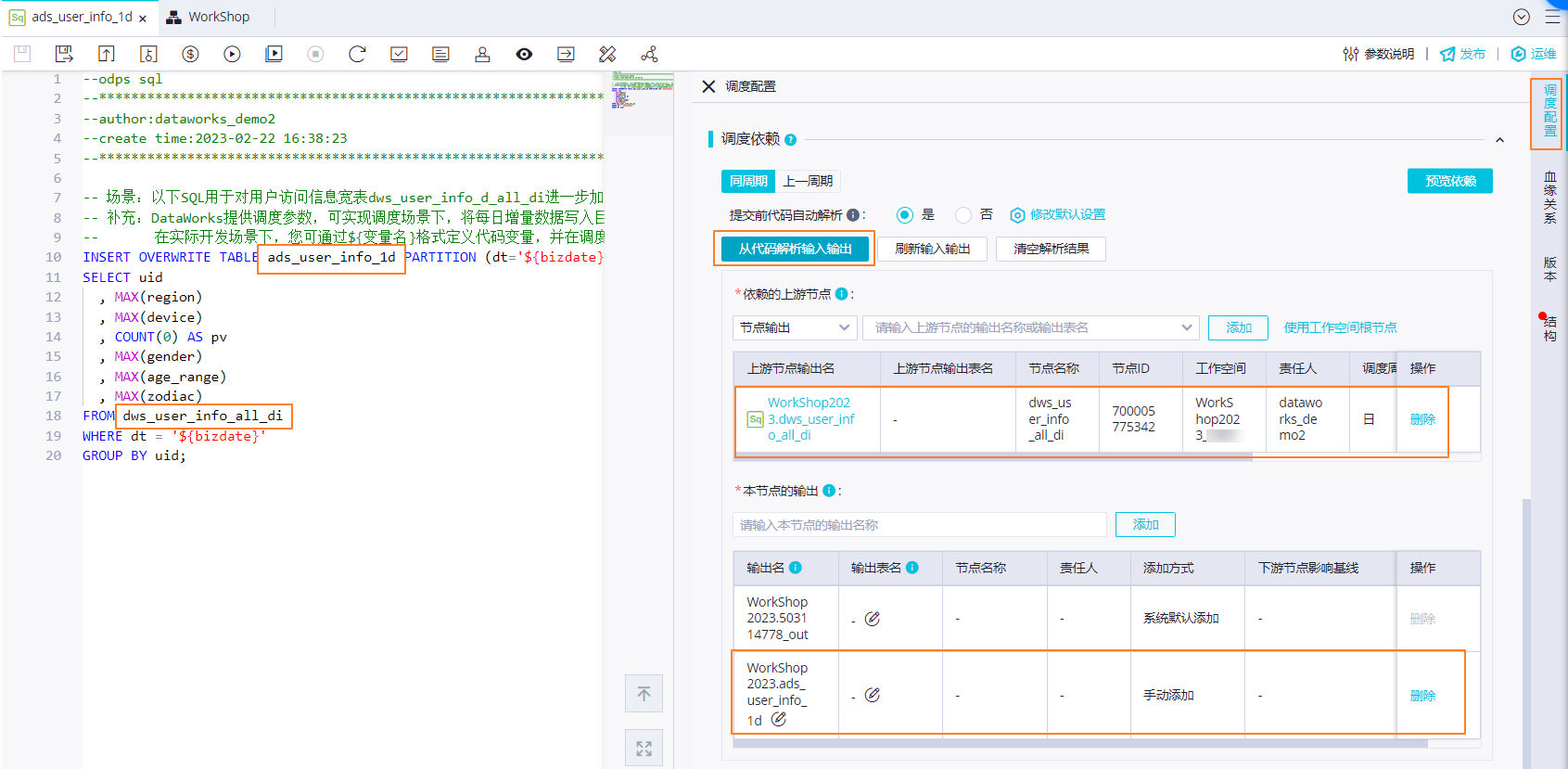
配置定時調度時間:無需單獨配置當前節點定時調度時間,當前節點每日起調時間由業務流程虛擬節點workshop_start的定時調度時間控制,即每日00:15分后才會調度。
配置依賴關系:通過代碼自動解析自動根據節點血緣關系配置節點上下游依賴關系,即將產出dws_user_info_all_1d表數據的dws_user_info_all_1d節點設置為當前節點ads_user_info_1d的上游。將節點產出表ads_user_info_1d作為節點輸出,方便下游查詢該表數據時自動掛上當前節點依賴。
3. 保存配置
本案例其他必填配置項,您可按需自行配置,配置完成后,在節點代碼編輯頁面,單擊工具欄中的![]() 按鈕,保存當前配置。
按鈕,保存當前配置。
步驟四:運行業務流程
發布任務至生產環境前,您可以運行整個業務流程,對代碼進行測試,確保其正確性。
運行業務流程
在業務流程(WorkShop)的編輯頁面,您需要確認最終通過自動解析設置的依賴關系是否與下圖一致。確認依賴關系無誤后,單擊工具欄的![]() 圖標,運行整個任務。
圖標,運行整個任務。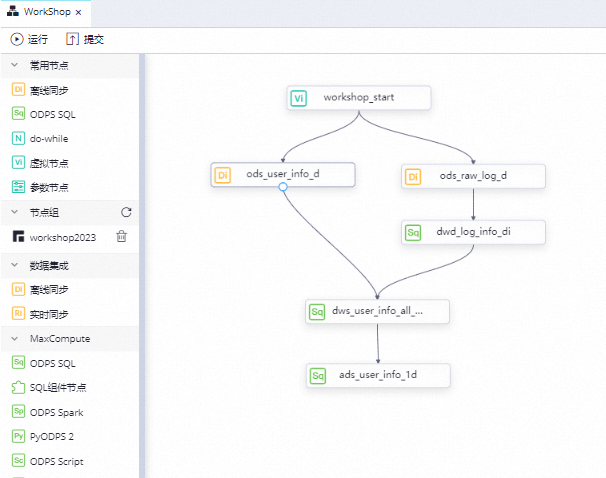
查看運行結果
待所有任務處于![]() 狀態后,查詢最終加工的結果表。
狀態后,查詢最終加工的結果表。
您可在數據開發頁面的左側導航欄,單擊
 ,進入臨時查詢面板。
,進入臨時查詢面板。右鍵單擊臨時查詢,選擇新建節點 > ODPS SQL。
在ODPS SQL節點中執行如下SQL語句,確認本案例最終的結果表。
//您需要將分區過濾條件更新為您當前操作的實際業務日期。例如,任務運行的日期為20230222,則業務日期為20230221,即任務運行日期的前一天。 select count(*) from ads_user_info_1d where dt='業務日期';
步驟五:提交并發布業務流程
任務需要發布至生產環境后才可自動調度運行,請參見以下內容。
提交至開發環境
在業務流程面板工具欄中,單擊![]() 按鈕,提交整個業務流程中的任務,請按照圖示配置,并單擊確認。
按鈕,提交整個業務流程中的任務,請按照圖示配置,并單擊確認。
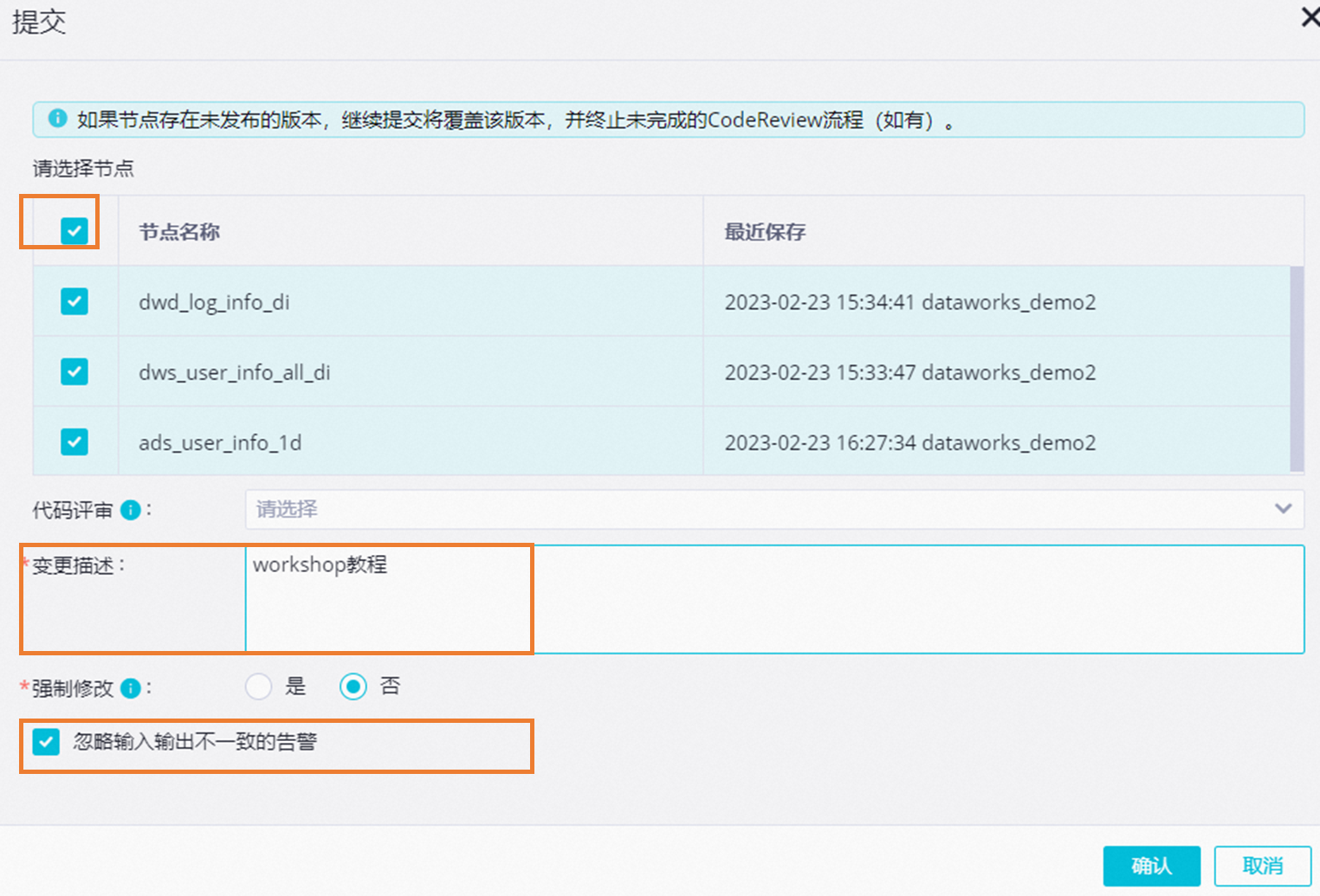
發布至生產環境
提交業務流程后,表示任務已進入開發環境。由于開發環境的任務不會自動調度,您需要將任務發布至生產環境。
在業務流程面板,單擊工具欄中的
 圖標,或單擊數據開發頁面任務發布按鈕,進入創建發布包頁面。
圖標,或單擊數據開發頁面任務發布按鈕,進入創建發布包頁面。批量發布目標任務,包括該業務流程涉及的資源、函數。
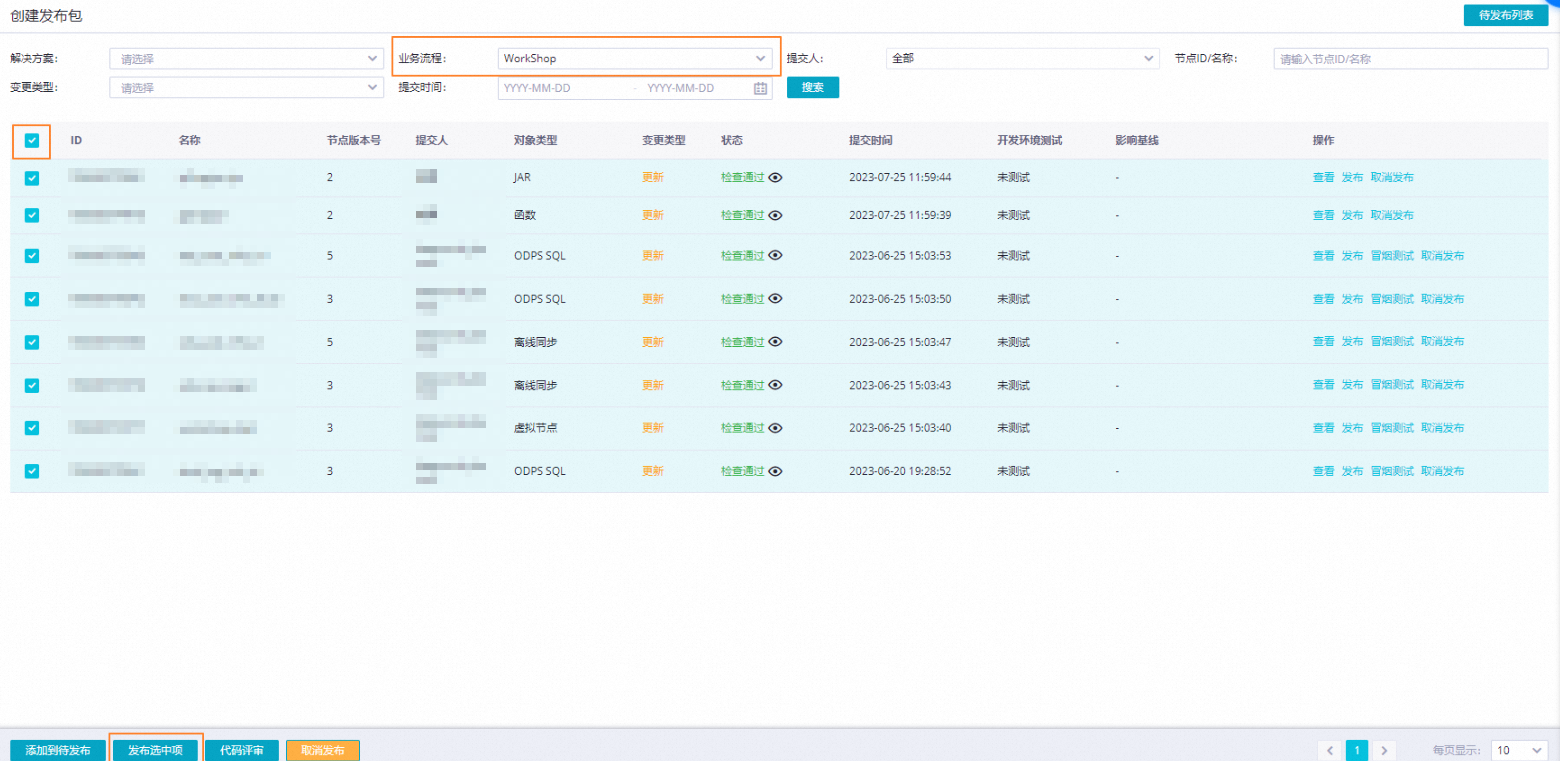
步驟六:在生產環境執行任務
在實際開發場景下,您可通過在生產環境執行補數據操作實現歷史數據回刷,具體操作如下。
進入運維中心。
任務發布成功后,單擊右上角的運維中心。
您也可以進入業務流程的編輯頁面,單擊工具欄中的前往運維,進入運維中心頁面。
針對周期任務執行補數據操作。
在左側導航欄,單擊,進入周期任務頁面,單擊workshop業務流程的起始根節點workshop_start。
右鍵單擊workshop_start節點,選擇。
選中workshop_start節點的所有下游節點,輸入業務日期,單擊確定,自動跳轉至補數據頁面。
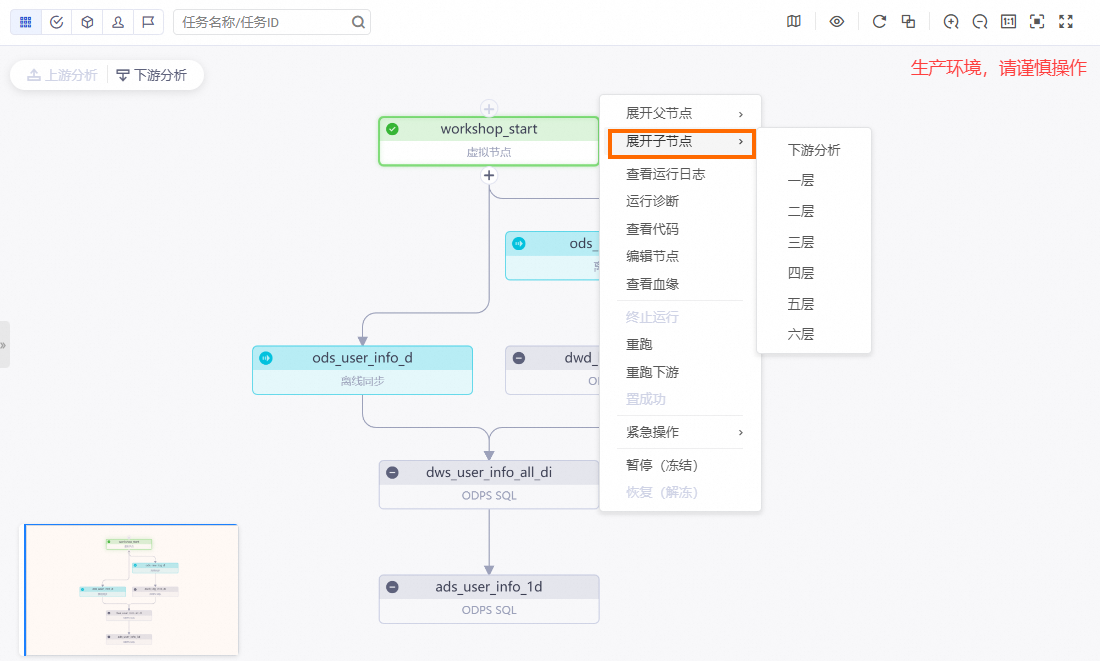
單擊刷新,直至SQL任務全部運行成功即可。
后續步驟
任務周期性調度場景下,為保障任務產出的表數據符合預期,我們可以對任務產出的表數據進行數據質量監控,詳情請參見配置數據質量監控。
附錄:加工示例
加工前
58.246.10.82##@@2d24d94f14784##@@2014-02-12 13:12:25##@@GET /wp-content/themes/inove/img/feeds.gif HTTP/1.1##@@200##@@2572##@@http://coolshell.cn/articles/10975.html##@@Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36加工后
