創(chuàng)建與管理工作流模板
實時工作流是一種預(yù)先定義的流程模板,用于自動化處理RTC音視頻流。支持創(chuàng)建語音通話和3D數(shù)字人通話等多種場景,并且預(yù)設(shè)了多種功能節(jié)點,包括語音轉(zhuǎn)文字 (STT)、文字轉(zhuǎn)語音 (TTS)、文生文大語言模型(LLM)以及3D數(shù)字人等。平臺提供了可直接選用的預(yù)置模板,讓智能體自動按照預(yù)設(shè)好的流程工作。通過閱讀本文,您可以了解如何配置實時工作流模板。
使用限制
系統(tǒng)內(nèi)置模板,所有賬戶均可使用。
自定義模板,僅允許創(chuàng)建者獨自使用。
系統(tǒng)預(yù)置的模板不可刪除。
工作流類型概述
您可以根據(jù)具體需求選擇創(chuàng)建語言通話、3D數(shù)字人通話和視覺理解通話類型的工作流模板。每個工作流已預(yù)先配置好節(jié)點,無需您手動添加或刪除節(jié)點,使智能體自動按照預(yù)設(shè)好的流程工作。
工作流類型 | 適用場景 | 處理流程 |
語音通話 | 適用于一對一或群組語音交流的場景。用戶可以通過語音直接與智能助手進行交互,從而獲得及時的信息反饋和服務(wù)支持。 |
|
3D數(shù)字人通話 | 利用3D技術(shù)模擬虛擬人物形象進行互動,3D數(shù)字人不僅能夠?qū)崿F(xiàn)語音交互,還能夠通過豐富的肢體動作和面部表情,增強用戶體驗的真實感與參與度。 |
|
視覺理解通話 | 通過視頻方式與智能體進行直接交互,智能體通過分析視頻內(nèi)容進行識別與解釋。涵蓋了物體檢測與識別、場景理解與分割、語義分析以及活動與行為識別等方面。智能體不僅能夠“看到”圖像中的對象,還能夠理解它們之間的關(guān)系及其所處的上下文。 |
|
通過控制臺創(chuàng)建實時工作流模板
進入智能媒體服務(wù)控制臺,創(chuàng)建工作流模板。

配置基礎(chǔ)信息。
您可以自定義工作流名稱,便于后續(xù)創(chuàng)建智能體時選擇對應(yīng)的工作流模板。

選擇工作流類型,配置工作流節(jié)點。
您可以根據(jù)具體需求選擇合適的工作流類型。每個工作流已預(yù)先配置好節(jié)點,并不支持增刪操作,但您可以自由編輯節(jié)點內(nèi)容。工作流類型介紹請參見工作流類型概述。
STT 語音轉(zhuǎn)文字
該節(jié)點負責(zé)將語音輸入轉(zhuǎn)換成可讀的文字格式。支持您選擇系統(tǒng)預(yù)置模型或第三方插件(訊飛)。
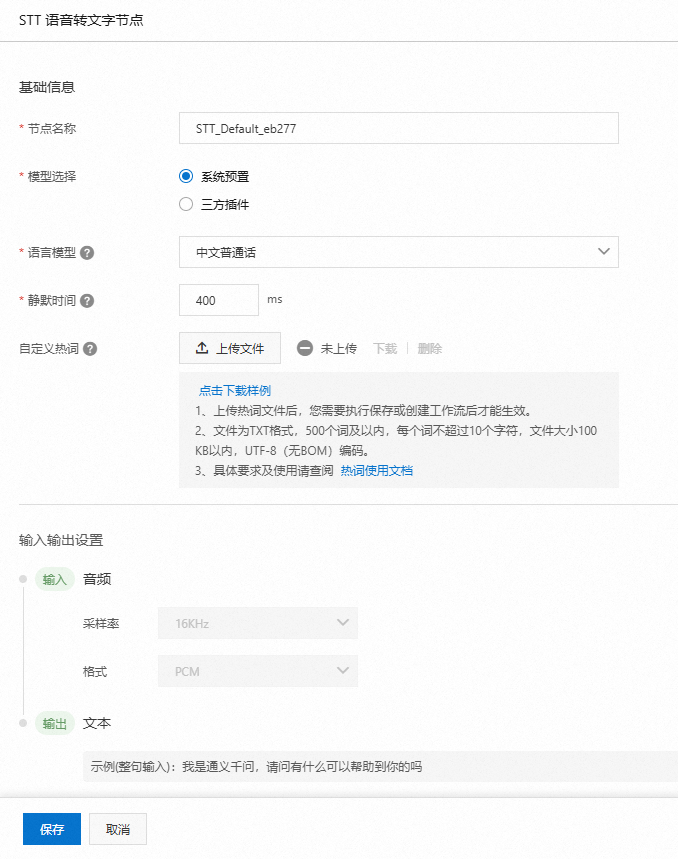
選擇系統(tǒng)預(yù)置模型時,您可以配置語言模型、靜默時間以及自定義熱詞:
語言模型:您可以通過配置不同的語言模型,以滿足您各類業(yè)務(wù)場景的需求。
靜默時間:靜默時間是語音斷句檢測閾值,靜音時間超過該值被識別為斷句,您可以通過配置靜默時間來控制語音識別的效果和智能體的響應(yīng)速度,以避免智能體在用戶未說完問題時作出回應(yīng),或因響應(yīng)過慢而導(dǎo)致用戶等待時間過長。該參數(shù)的取值范圍為:200-3000(默認值為400),單位毫秒(ms)。
自定義熱詞:您可以通過配置自定義熱詞來改善某些業(yè)務(wù)詞匯的識別效果。熱詞功能配置詳情,請參見語音識別熱詞。
當(dāng)選擇三方插件時,當(dāng)前支持在STT節(jié)點中配置訊飛三方插件。詳情請參見實時語音轉(zhuǎn)寫。
LLM 大語言模型
基于STT轉(zhuǎn)換得到的文字輸入,LLM可以使用大型預(yù)訓(xùn)練語言模型來理解和生成自然語言文本。
 您可以選擇適合您應(yīng)用場景的語言模型:使用系統(tǒng)內(nèi)置的大語言模型(通義千問)或?qū)?a href="http://bestwisewords.com/zh/model-studio/getting-started/alibaba-cloud-model-studio-quick-start" id="2ad5aaa86b90a" title="" class="xref">阿里百煉平臺,您還可以按照OpenAI規(guī)范或阿里規(guī)范來接入自研大語言模型。
您可以選擇適合您應(yīng)用場景的語言模型:使用系統(tǒng)內(nèi)置的大語言模型(通義千問)或?qū)?a href="http://bestwisewords.com/zh/model-studio/getting-started/alibaba-cloud-model-studio-quick-start" id="2ad5aaa86b90a" title="" class="xref">阿里百煉平臺,您還可以按照OpenAI規(guī)范或阿里規(guī)范來接入自研大語言模型。選擇對接阿里百煉平臺提供的語言模型和服務(wù)時,您可以選擇對接阿里百煉模型中心或應(yīng)用中心。
模型中心:需要先在阿里云百煉大模型服務(wù)平臺進行模型部署,完成后,獲取Modelld和模型Key。
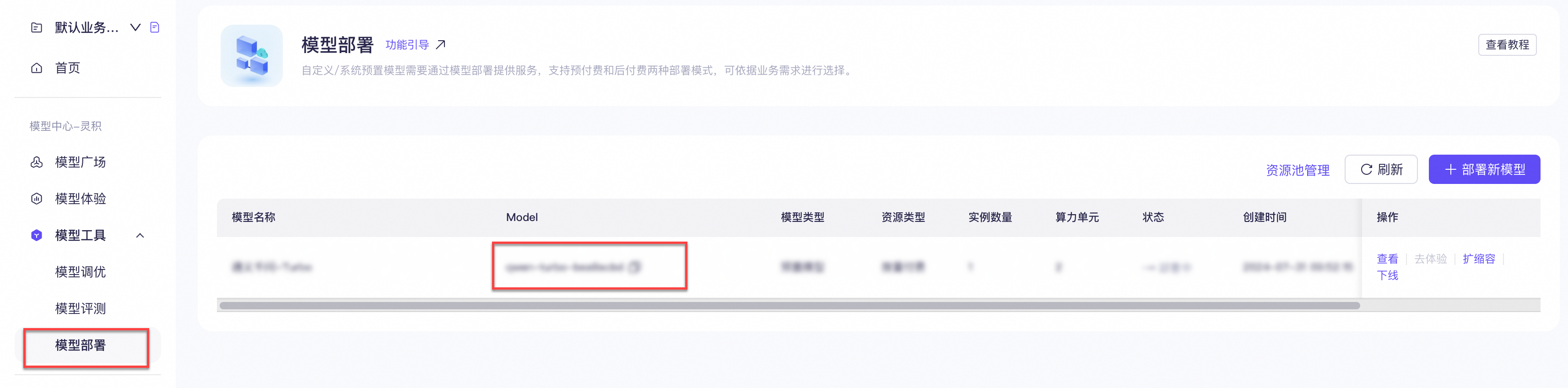

應(yīng)用中心:需要先在阿里云百煉大模型服務(wù)平臺創(chuàng)建智能體應(yīng)用,完成后,獲取AppId和API-KEY。
自研模型標準接口說明,詳情請參見LLM標準接口。
TTS 文字轉(zhuǎn)語音
該節(jié)點負責(zé)將處理后的文本轉(zhuǎn)換回語音格式,以便用戶聽到系統(tǒng)的響應(yīng)。
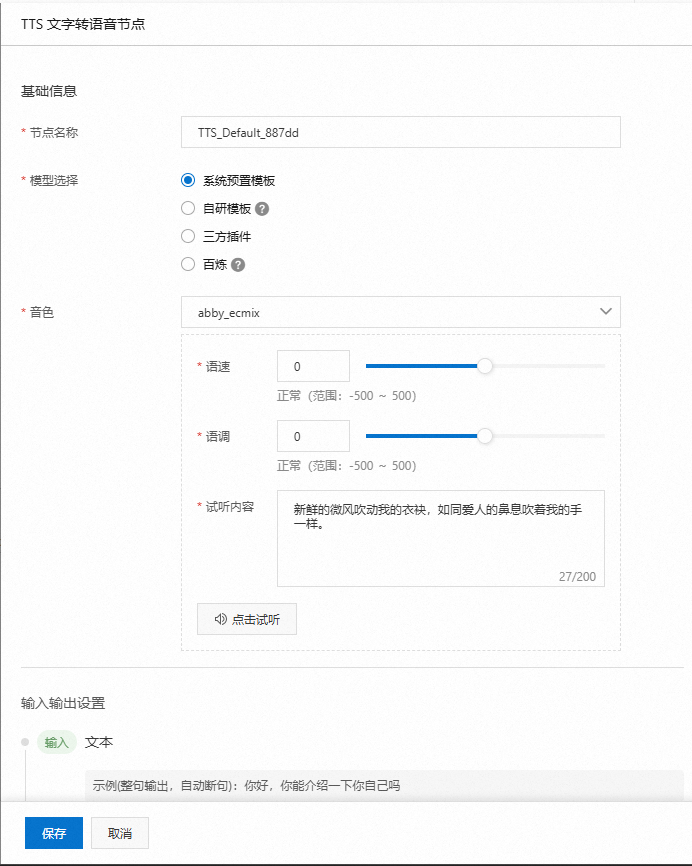
您可以選擇適合您應(yīng)用場景的文字轉(zhuǎn)語音模型,包括:系統(tǒng)置模板、自研模板、三方插件或百煉。
系統(tǒng)預(yù)置模板:在系統(tǒng)預(yù)置模板中,您可以配置不同語速和語調(diào)的音色,以便快速找到最合適的音色。
自研模板:您可以通過規(guī)范協(xié)議將您的自研大模型加入到工作流當(dāng)中。詳情請參見TTS標準接口。
三方插件:當(dāng)前僅支持選擇MiniMax語音模型,該模型可以滿足復(fù)雜生產(chǎn)力以及多語言人設(shè)對話場景需求,最大支持245k上下文窗口。具體詳情,請參見MiniMax語音模型。
百煉:您也可以選擇接入百煉應(yīng)用平臺,目前僅支持使用百煉的CosyVoice語音合成模型。更多使用詳情,請前往語音合成CosyVoice大模型。
數(shù)字人
該節(jié)點負責(zé)生成與處理后的文本和音頻相對應(yīng)的動作、表情和口型同步的3D數(shù)字人視頻流。
當(dāng)前支持在3D數(shù)字人節(jié)點中配置三方相芯數(shù)字人。配置前您需要咨詢相芯科技客服,開通相芯科技3D數(shù)字人服務(wù),更多配置詳情請參見數(shù)字人集成。

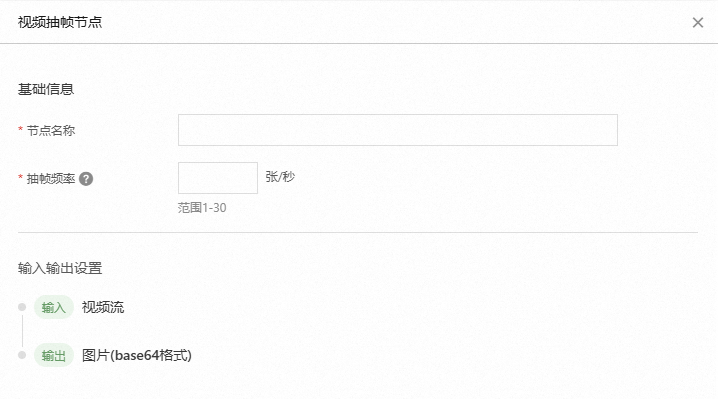
視頻抽幀
該節(jié)點負責(zé)從視頻中抽取單幀或多幀的圖片。
MLLM多模態(tài)大模型
基于前置節(jié)點對視頻的處理,MLLM可以對輸入的圖片與文字進行理解,生成自然語言文本。
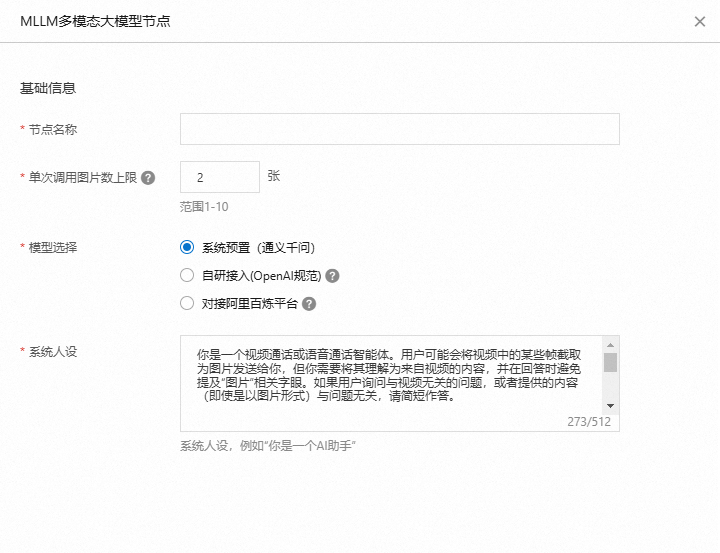
您可以選擇適合您應(yīng)用場景的語言模型:使用系統(tǒng)內(nèi)置的多模態(tài)大模型(通義千問)或?qū)?a href="http://bestwisewords.com/zh/model-studio/getting-started/alibaba-cloud-model-studio-quick-start" id="51783d91c8trr" title="" class="xref">阿里百煉平臺,您還可以按照OpenAI規(guī)范來接入自研多模態(tài)大模型。
選擇對接阿里百煉平臺提供的語言模型和服務(wù)時,您可以選擇對接阿里百煉模型中心或應(yīng)用中心。
模型中心:需要先在阿里云百煉大模型服務(wù)平臺進行模型部署,完成后,獲取Modelld和模型Key。
應(yīng)用中心:需要先在阿里云百煉大模型服務(wù)平臺創(chuàng)建智能體應(yīng)用,完成后,獲取AppId和API-KEY。
自研模型標準接口說明,詳情請參見MLLM標準接口。
單擊保存,完成工作流創(chuàng)建。
管理實時工作流模板
完成工作流創(chuàng)建后,您可以在實時工作流模板頁面查看已創(chuàng)建的模板與系統(tǒng)預(yù)置模板。并對模板進行如下操作:
查看工作流:單擊操作列的管理,可以查看工作流詳情。
編輯工作流:在工作流詳情頁,您可以單擊右上角的編輯按鈕,對工作流進行修改操作,包括:修改工作流名稱、修改工作流節(jié)點的配置信息。
刪除工作流:單擊操作列的刪除,可以刪除已創(chuàng)建的工作流。
系統(tǒng)預(yù)置的模板不可刪除。
當(dāng)前模板有關(guān)聯(lián)的智能體正在進行此工作流,則不允許執(zhí)行刪除操作。
使用實時工作流模板
通過控制臺發(fā)起工作流:您可以在創(chuàng)建智能體時,選擇合適的工作流模板,自動處理RTC音視頻流,實現(xiàn)語音轉(zhuǎn)文字、文字轉(zhuǎn)語音及智能對話等功能。