MaxCompute分區(qū)表數(shù)據(jù)導(dǎo)入
本文為您介紹如何將MaxCompute分區(qū)表數(shù)據(jù)導(dǎo)入到Hologres分區(qū)表。
前提條件
已購買并開通Hologres實例,開通方法請參見購買Hologres。
已開通MaxCompute并創(chuàng)建項目,詳情請參見開通MaxCompute和DataWorks。
已開通DataWorks服務(wù)并創(chuàng)建DataWorks工作空間,詳情請參見創(chuàng)建工作空間。
背景信息
通過Hologres中的MaxCompute外表方式向Hologres導(dǎo)入數(shù)據(jù)是非常常見的數(shù)據(jù)導(dǎo)入模式。在日常工作中會經(jīng)常需要進(jìn)行數(shù)據(jù)導(dǎo)入,此時可以借助DataWorks的強(qiáng)大調(diào)度和作業(yè)編排能力,實現(xiàn)周期性調(diào)度,配置一個調(diào)度作業(yè)覆蓋數(shù)據(jù)導(dǎo)入兩個場景,詳情請參見DataWorks作業(yè)案例。
考慮到作業(yè)較為復(fù)雜,所以可以利用DataWorks的遷移助手功能,將Data作業(yè)案例文件導(dǎo)入您的項目中,您即可獲得Data作業(yè)案例,之后按照您的具體業(yè)務(wù)需求更改部分參數(shù)或腳本即可,詳情請參見使用遷移工具導(dǎo)入DataWorks作業(yè)。
注意事項
使用臨時表的原因是為了保證原子性,只有在導(dǎo)入完成后才綁定至分區(qū)表,為了避免導(dǎo)入任務(wù)失敗時還需要重新刪除表等操作。
對于更新子表分區(qū)數(shù)據(jù)場景,需要刪除子表和重新綁定臨時表放入一個事務(wù)過程中,保證該過程的事務(wù)性。
使用遷移工具導(dǎo)入DataWorks作業(yè)時需滿足以下條件:
DataWorks需標(biāo)準(zhǔn)版及以上版本,詳情請參見DataWorks各版本詳解。
DataWorks工作空間需綁定MaxCompute和Hologres數(shù)據(jù)源,詳情請參見創(chuàng)建并管理工作空間。
詳細(xì)操作步驟
MaxCompute數(shù)據(jù)準(zhǔn)備
單擊左側(cè)導(dǎo)航欄數(shù)據(jù)分析。
在SQL查詢頁面,輸入如下SQL語句用于創(chuàng)建分區(qū)表,單擊運(yùn)行。
DROP TABLE IF EXISTS odps_sale_detail; --創(chuàng)建一張分區(qū)表sale_detail。 CREATE TABLE IF NOT EXISTS odps_sale_detail ( shop_name STRING ,customer_id STRING ,total_price DOUBLE ) PARTITIONED BY ( sale_date STRING ) ;在SQL查詢頁面,輸入如下SQL語句用于向分區(qū)表中導(dǎo)入數(shù)據(jù),單擊運(yùn)行。
-- 向源表增加分區(qū)20210815 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210815') ; -- 向分區(qū)寫入數(shù)據(jù) INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210815') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- 向源表增加分區(qū)20210816 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210816') ; -- 向分區(qū)寫入數(shù)據(jù) INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210816') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- 向源表增加分區(qū)20210817 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210817') ; -- 向分區(qū)寫入數(shù)據(jù) INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210817') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- 向源表增加分區(qū)20210818 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210818') ; -- 向分區(qū)寫入數(shù)據(jù) INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210818') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ;
Hologres中建表
創(chuàng)建外部表
登錄數(shù)據(jù)庫
在HoloWeb開發(fā)頁面,單擊元數(shù)據(jù)管理。
在元數(shù)據(jù)管理頁面,雙擊左側(cè)目錄樹中已創(chuàng)建成功的數(shù)據(jù)庫名稱,單擊確認(rèn)。
創(chuàng)建外部表
在SQL編輯器頁面,單擊左上角的
 新建SQL查詢。
新建SQL查詢。在新增的臨時Query查詢頁面,選擇已創(chuàng)建的實例名和數(shù)據(jù)庫后,在SQL查詢的編輯框輸入如下語句,單擊運(yùn)行。
DROP FOREIGN TABLE IF EXISTS odps_sale_detail; -- 創(chuàng)建外部表 IMPORT FOREIGN SCHEMA maxcompute_project LIMIT to ( odps_sale_detail ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'error',if_unsupported_type 'error');
創(chuàng)建分區(qū)表(內(nèi)部表)
登錄數(shù)據(jù)庫
在HoloWeb開發(fā)頁面,單擊元數(shù)據(jù)管理。
在元數(shù)據(jù)管理頁面,雙擊左側(cè)目錄樹中已創(chuàng)建成功的數(shù)據(jù)庫名稱,單擊確認(rèn)。
創(chuàng)建分區(qū)表
在SQL編輯器頁面,單擊左上角的
新建SQL查詢。在新增的臨時Query查詢頁面,選擇已創(chuàng)建的實例名和數(shù)據(jù)庫后,請您在SQL查詢的編輯框輸入如下語句,單擊運(yùn)行。
DROP TABLE IF EXISTS holo_sale_detail; -- 創(chuàng)建Hologres分區(qū)表(內(nèi)部表) BEGIN ; CREATE TABLE IF NOT EXISTS holo_sale_detail ( shop_name TEXT ,customer_id TEXT ,total_price FLOAT8 ,sale_date TEXT ) PARTITION BY LIST(sale_date); COMMIT;
分區(qū)數(shù)據(jù)導(dǎo)入Hologres臨時表
在臨時Query查詢頁面,請您在SQL查詢的編輯框輸入如下語句,單擊運(yùn)行。
此SQL語句將MaxCompute的hologres_test項目中的odps_sale_detail分區(qū)表的20210816分區(qū)導(dǎo)入Hologres中的holo_sale_detail分區(qū)表的20210816分區(qū)。
說明Hologres從V2.1.17版本起支持Serverless Computing能力,針對大數(shù)據(jù)量離線導(dǎo)入、大型ETL作業(yè)、外表大數(shù)據(jù)量查詢等場景,使用Serverless Computing執(zhí)行該類任務(wù)可以直接使用額外的Serverless資源,避免使用實例自身資源,無需為實例預(yù)留額外的計算資源,顯著提升實例穩(wěn)定性、減少OOM概率,且僅需為任務(wù)單獨付費。Serverless Computing詳情請參見Serverless Computing概述,Serverless Computing使用方法請參見Serverless Computing使用指南。
-- 清理潛在的臨時表 BEGIN ; DROP TABLE IF EXISTS holo_sale_detail_tmp_20210816; COMMIT ; -- 創(chuàng)建臨時表 SET hg_experimental_enable_create_table_like_properties=on; BEGIN ; CALL HG_CREATE_TABLE_LIKE ('holo_sale_detail_tmp_20210816', 'select * from holo_sale_detail'); COMMIT; -- (可選)推薦使用Serverless Computing執(zhí)行大數(shù)據(jù)量離線導(dǎo)入和ETL作業(yè) SET hg_computing_resource = 'serverless'; -- 向臨時表插入數(shù)據(jù) INSERT INTO holo_sale_detail_tmp_20210816 SELECT * FROM public.odps_sale_detail WHERE sale_date='20210816'; -- 重置配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;臨時表綁定至Hologres分區(qū)表
在臨時Query查詢頁面,請您在SQL查詢的編輯框輸入如下語句,單擊運(yùn)行。
存在舊的子表,則需要先刪除舊子表,再將臨時表綁定至Hologres分區(qū)表。
此SQL語句用于刪除子表holo_sale_detail_20210816并將臨時表holo_sale_detail_tmp_20210816綁定至holo_sale_detail分區(qū)表的20210816分區(qū)。
-- 已有子表時替換子表 BEGIN ; -- 刪除舊子表 DROP TABLE IF EXISTS holo_sale_detail_20210816; -- 將臨時表改名 ALTER TABLE holo_sale_detail_tmp_20210816 RENAME TO holo_sale_detail_20210816; -- 將臨時表綁定至指定分區(qū)表 ALTER TABLE holo_sale_detail ATTACH PARTITION holo_sale_detail_20210816 FOR VALUES IN ('20210816') ; COMMIT ;不存在舊子表,直接將臨時表綁定至Hologres分區(qū)表。
此SQL語句用于將臨時表holo_sale_detail_tmp_20210816綁定至holo_sale_detail分區(qū)表的20210816分區(qū)。
BEGIN ; -- 將臨時表改名 ALTER TABLE holo_sale_detail_tmp_20210816 RENAME TO holo_sale_detail_20210816; -- 將臨時表綁定至指定分區(qū)表 ALTER TABLE holo_sale_detail ATTACH PARTITION holo_sale_detail_20210816 FOR VALUES IN ('20210816'); COMMIT ;
ANALYZE Hologres分區(qū)表
在臨時Query查詢頁面,請您在SQL查詢的編輯框輸入如下語句,單擊運(yùn)行。
此SQL語句用于ANALYZE holo_sale_detail分區(qū)表,驗證分區(qū)表執(zhí)行計劃。ANALYZE分區(qū)表時,僅需ANALYZE父表。
-- 大量數(shù)據(jù)導(dǎo)入后執(zhí)行ANALYZE分區(qū)表父表操作 ANALYZE holo_sale_detail;清理過期的分區(qū)子表(按需)
生產(chǎn)環(huán)境中,數(shù)據(jù)具備生命周期,對于超期的分區(qū)需要清理。
在臨時Query查詢頁面,請您在SQL查詢的編輯框輸入如下語句,單擊運(yùn)行。
此SQL語句清理20210631的分區(qū)。
DROP TABLE IF EXISTS holo_sale_detail_20210631;
DataWorks作業(yè)案例
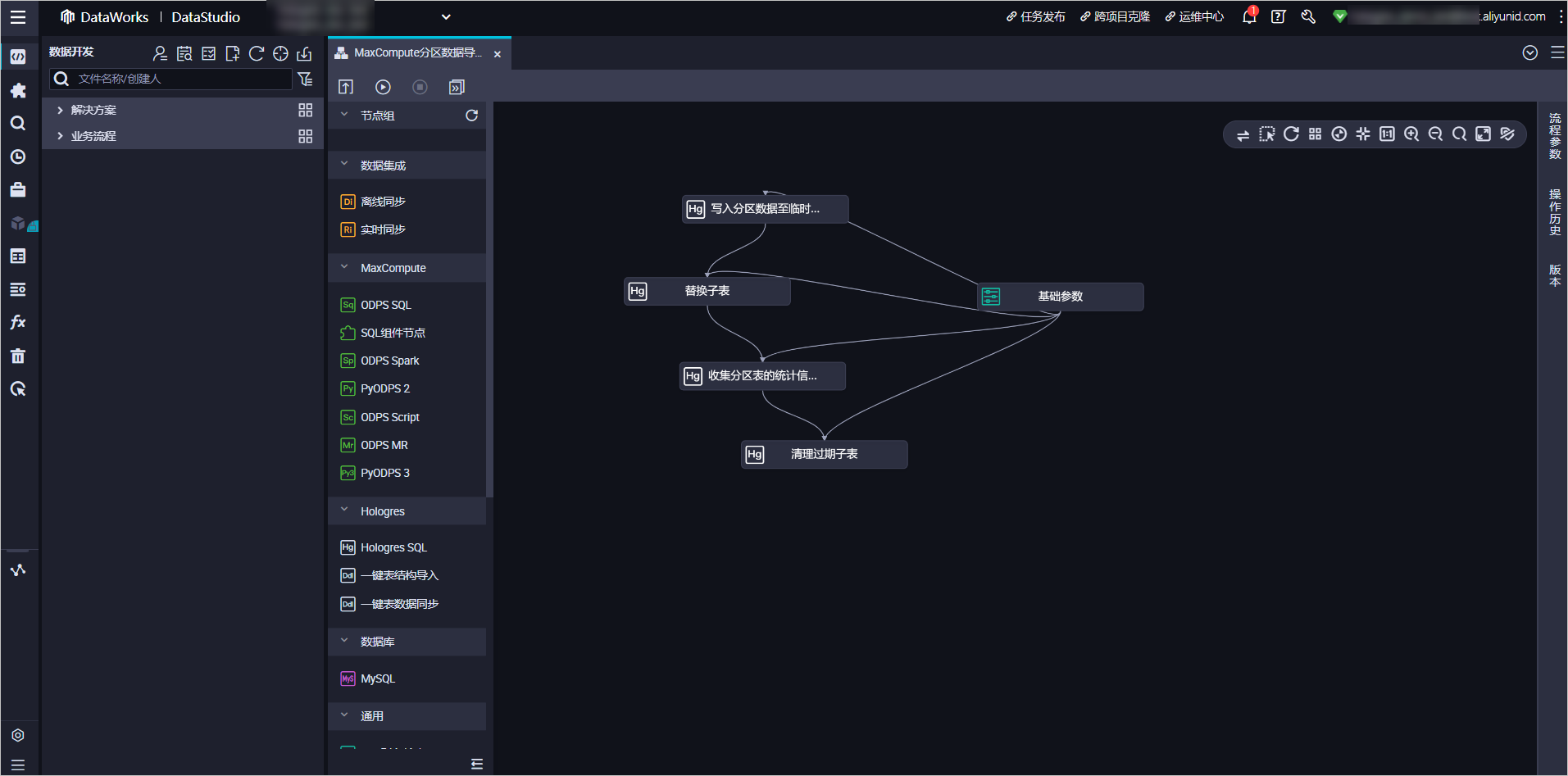
日常工作中往往需要周期性調(diào)度以上SQL,此時可以借助DataWorks的強(qiáng)大調(diào)度和作業(yè)編排能力,實現(xiàn)周期性調(diào)度,且使用一個調(diào)度作業(yè)覆蓋以上兩個場景。請仔細(xì)閱讀以下內(nèi)容,便于您使用遷移工具導(dǎo)入DataWorks作業(yè)時按照您的具體業(yè)務(wù)需求更改部分參數(shù)或腳本。業(yè)務(wù)流程總覽如下。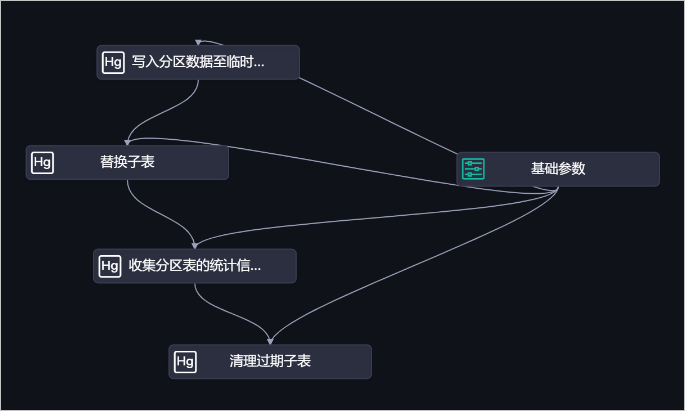
業(yè)務(wù)流程模塊詳解
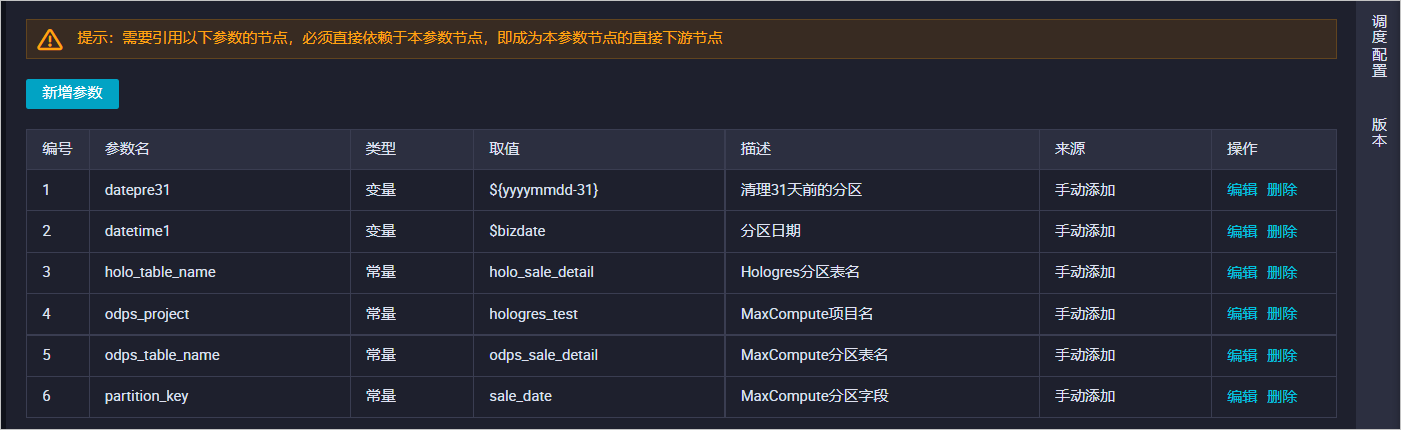
基礎(chǔ)參數(shù)
基礎(chǔ)參數(shù)用于管理整個業(yè)務(wù)流程中用到的所有參數(shù),主要用到的參數(shù)如下。
編號
參數(shù)名
類型
取值
描述
1
datepre31
變量
${yyyymmdd-31}
用于控制清理過期分區(qū)的參數(shù),此處含義為清理31天前的分區(qū)。
2
datetime1
變量
$bizdate
用于控制創(chuàng)建分區(qū)的參數(shù)。
3
holo_table_name
常量
holo_sale_detail
Hologres分區(qū)表名。
4
odps_project
常量
hologres_test
MaxCompute項目名。
5
odps_table_name
常量
odps_sale_detail
MaxCompute分區(qū)表名。
6
partition_key
常量
sale_date
MaxCompute分區(qū)字段。
系統(tǒng)配置圖如下。
寫入分區(qū)數(shù)據(jù)至臨時表
該步驟是一個Hologres SQL模塊,其中SQL代碼如下。
說明Hologres從V2.1.17版本起支持Serverless Computing能力,針對大數(shù)據(jù)量離線導(dǎo)入、大型ETL作業(yè)、外表大數(shù)據(jù)量查詢等場景,使用Serverless Computing執(zhí)行該類任務(wù)可以直接使用額外的Serverless資源,避免使用實例自身資源,無需為實例預(yù)留額外的計算資源,顯著提升實例穩(wěn)定性、減少OOM概率,且僅需為任務(wù)單獨付費。Serverless Computing詳情請參見Serverless Computing概述,Serverless Computing使用方法請參見Serverless Computing使用指南。
-- 清理潛在的臨時表 BEGIN ; DROP TABLE IF EXISTS ${holo_table_name}_tmp_${datetime1}; COMMIT ; -- 創(chuàng)建臨時表 SET hg_experimental_enable_create_table_like_properties=on; BEGIN ; CALL HG_CREATE_TABLE_LIKE ('${holo_table_name}_tmp_${datetime1}', 'select * from ${holo_table_name}'); COMMIT; -- 向臨時表插入數(shù)據(jù) -- (可選)推薦使用Serverless Computing執(zhí)行大數(shù)據(jù)量離線導(dǎo)入和ETL作業(yè) SET hg_computing_resource = 'serverless'; INSERT INTO ${holo_table_name}_tmp_${datetime1} SELECT * FROM public.${odps_table_name} WHERE ${partition_key}='${datetime1}'; -- 重置配置,保證非必要的SQL不會使用Serverless資源 RESET hg_computing_resource;需要將基礎(chǔ)參數(shù)綁定至該模塊上游,用于控制其中的參數(shù)變量,系統(tǒng)配置如下:
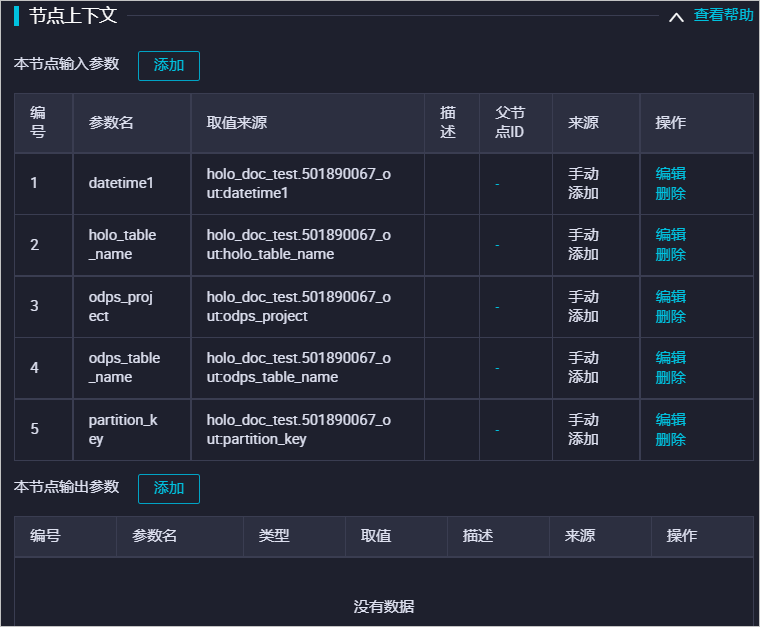
替換子表
該步驟是一個Hologres SQL模塊,用于替換已有子表。將替換子表相關(guān)過程放在一個事務(wù)中,保證執(zhí)行的事務(wù)性,SQL代碼如下。
-- 已有子表時替換子表 BEGIN ; -- 刪除已經(jīng)存在的子表 DROP TABLE IF EXISTS ${holo_table_name}_${datetime1}; -- 將臨時表改名 ALTER TABLE ${holo_table_name}_tmp_${datetime1} RENAME TO ${holo_table_name}_${datetime1}; -- 將臨時表綁定至指定分區(qū)表 ALTER TABLE ${holo_table_name} ATTACH PARTITION ${holo_table_name}_${datetime1} FOR VALUES IN ('${datetime1}'); COMMIT ;需要將基礎(chǔ)參數(shù)綁定至該模塊上游,用于控制其中的參數(shù)變量,系統(tǒng)配置如下。

收集分區(qū)表的統(tǒng)計信息
該步驟是一個Hologres SQL模塊,收集父表的統(tǒng)計信息,SQL代碼如下。
-- 大量數(shù)據(jù)導(dǎo)入后執(zhí)行ANALYZE分區(qū)表父表操作 ANALYZE ${holo_table_name};需要將基礎(chǔ)參數(shù)綁定至該模塊上游,用于控制其中的參數(shù)變量,系統(tǒng)配置如下。
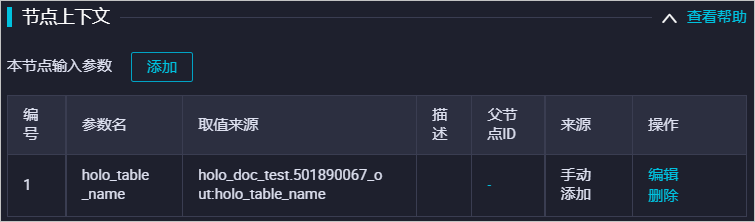
清理過期子表
生產(chǎn)環(huán)境中,數(shù)據(jù)具備生命周期,對于超期的分區(qū)需要清理。
現(xiàn)以僅在Hologres中存儲最近31天的分區(qū)為例,由于之前設(shè)置的參數(shù)為datepre31=${yyyymmdd-31},所以清理過期子表的SQL代碼如下。
-- 清理過期子表 BEGIN ; DROP TABLE IF EXISTS ${holo_table_name}_${datepre31}; COMMIT ;所以在作業(yè)運(yùn)行時,如果bizdate=20200309,則datepre31=20200207,這樣即可達(dá)到清理分區(qū)的目的。
同時需要將基礎(chǔ)參數(shù)綁定至該模塊上游,用于控制其中的參數(shù)變量,系統(tǒng)配置如下。
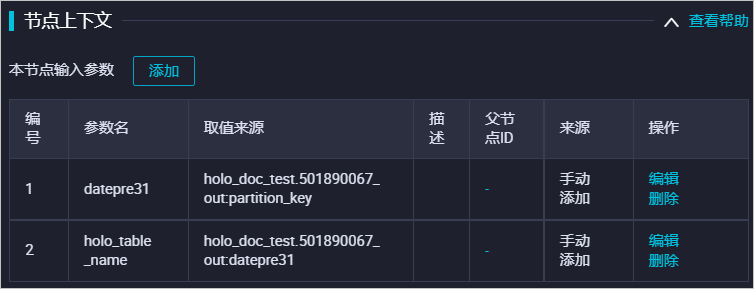
使用遷移工具導(dǎo)入DataWorks作業(yè)
考慮到作業(yè)較為復(fù)雜,所以可以利用DataWorks的遷移助手功能,將以下文件導(dǎo)入您的項目中,您即可獲得以上說明的DataWorks的作業(yè),之后按照您的具體業(yè)務(wù)需求更改部分參數(shù)或腳本即可。
DataWorks遷移助手的詳細(xì)介紹,請參見DataWorks遷移助手介紹及實踐。
下載如下作業(yè)包:DataWorks作業(yè)包。
進(jìn)入DataWorks遷移助手,詳情請參見進(jìn)入遷移助手。
在遷移助手的左側(cè)導(dǎo)航欄,單擊。
在DataWorks導(dǎo)入頁面,單擊右上方的新建導(dǎo)入任務(wù)。
在新建導(dǎo)入任務(wù)對話框中,配置各項參數(shù)。
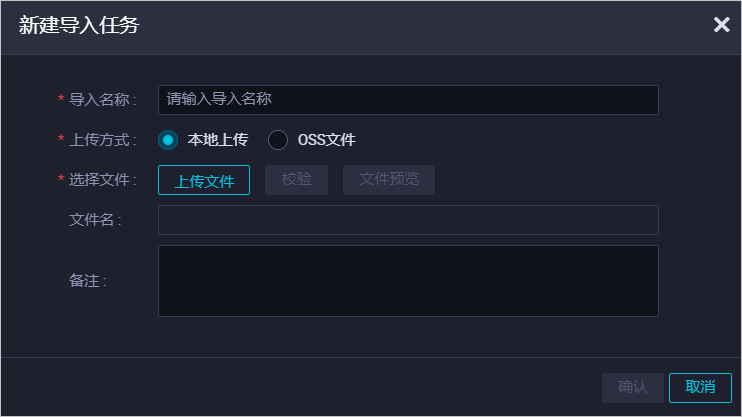
參數(shù)
描述
導(dǎo)入名稱
自定義名稱。導(dǎo)入名稱僅支持大小寫字母、中文、數(shù)字、下劃線(_)和英文句號(.)。
上傳方式
上傳文件的方式。
備注
對導(dǎo)入任務(wù)進(jìn)行簡單描述。
單擊確認(rèn),進(jìn)入導(dǎo)入任務(wù)設(shè)置頁面,設(shè)置匹配關(guān)系。
單擊左下方的開始導(dǎo)入,在請確認(rèn)對話框中,單擊確認(rèn)。
導(dǎo)入成功后,在您的數(shù)據(jù)開發(fā)模塊中則會出現(xiàn)以上提及的周期性作業(yè)。
同時在手工作業(yè)流程中會出現(xiàn)相關(guān)的DDL語句。