本文為您介紹在Hologres中數倉分層的最佳實踐,方便快速構建業務,建設集高性能、敏捷化于一體的實時數倉。
背景信息
Hologres與Flink、MaxCompute、DataWorks深度兼容,能夠提供實時離線一體化聯合解決方案。在該方案下有著非常豐富的應用場景,例如實時大屏、實時風控、精細化運營等。不同的應用場景對處理的數據量、數據復雜度、數據來源、數據實時性等會有不一樣的要求。傳統數倉的開發按照經典的方法論,采用ODS(Operational Data Store) > DWD(Data Warehouse Detail) > DWS(Data WareHouse Summary) > ADS(Application Data Service)逐層開發的方法,層與層之間采用事件驅動,或者微批次的方式調度。分層帶來更好的語義層抽象和數據復用,但也增加了調度的依賴、降低了數據的時效性、減少了數據靈活分析的敏捷性。
實時數倉驅動了業務決策的實時化,在決策時通常需要豐富的上下文信息,因此傳統高度依據業務定制ADS的開發方法受到了較大挑戰,成千上萬的ADS表維護困難,利用率低,更多的業務方希望通過DWS甚至DWD進行多角度數據對比分析,這對查詢引擎的計算效率、調度效率、IO效率都提出了更高的要求。
隨著計算算子向量化重寫、精細化索引、異步化執行、多級緩存等多種查詢引擎優化技術的應用,Hologres的計算能力在每個版本都有較大改善。因此越來越多的用戶采用了敏捷化的開發方式,在計算前置的階段,只做數據質量清理、基本的大表關聯拉寬,建模到DWD、DWS即可,減少建模層次。同時將靈活查詢在交互式查詢引擎中執行,通過秒級的交互式分析體驗,支撐了數據分析民主化的重要趨勢。
為了滿足業務場景的不同需求,建議您通過如下圖所示三種方式進行數據分層和處理,以實現更加敏捷的開發需求。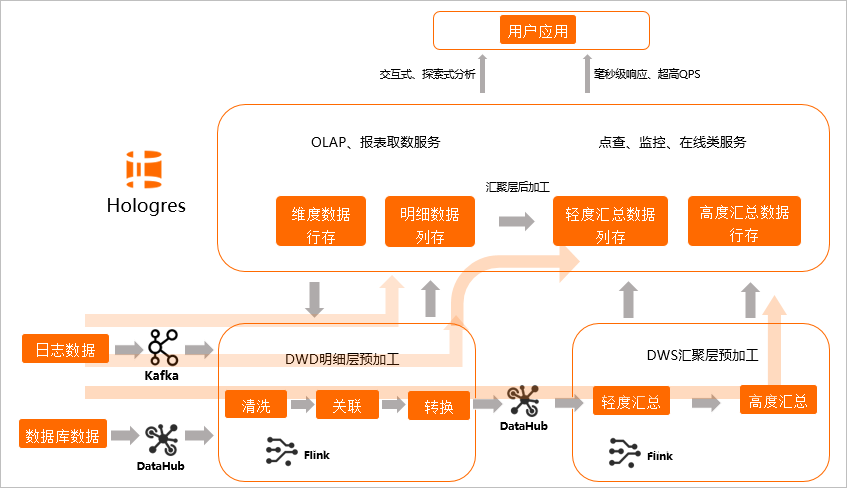
場景一(即席查詢,寫入即服務):在Flink中進行DWD數據明細層預加工,加工完的數據直接寫入Hologres,由Hologres提供OLAP查詢和在線服務。
場景二(分鐘級準實時,微批次加工):在Flink中進行DWD數據明細層預加工,寫入Hologres后,在Hologres中進行匯聚層加工,再對接上層應用。
場景三(增量數據實時統計,事件驅動加工):DWD明細層預加工和DWS匯聚層預加工全部由Flink完成,寫入Hologres提供上層應用。
場景選擇原則
當數據寫入Hologres之后,Hologres里定義了三種實現實時數倉的方式:
實時要求非常高,要求寫入即可查,更新即反饋,有即席查詢需求,且資源較為充足,查詢復雜度較低,適合實時數倉場景一:即席查詢。
有實時需求,以分析為主,實時性滿足分析時數據在業務場景具備實時含義,不追求數據產生到分析的秒級絕對值,但開發效率優先,推薦分鐘級準實時方案,這個方案適合80%以上的實時數倉場景,平衡了時效性與開發效率,適合實時數倉場景二:分鐘級準實時。
實時需求簡單、數據更新少、只需要增量數據即可統計結果,以大屏和風控等在線服務場景為主,需要數據產生到分析盡量實時,可以接受一定開發效率的降低和計算成本的上升,適合實時數倉場景三:增量數據實時統計。
實時數倉場景一:即席查詢
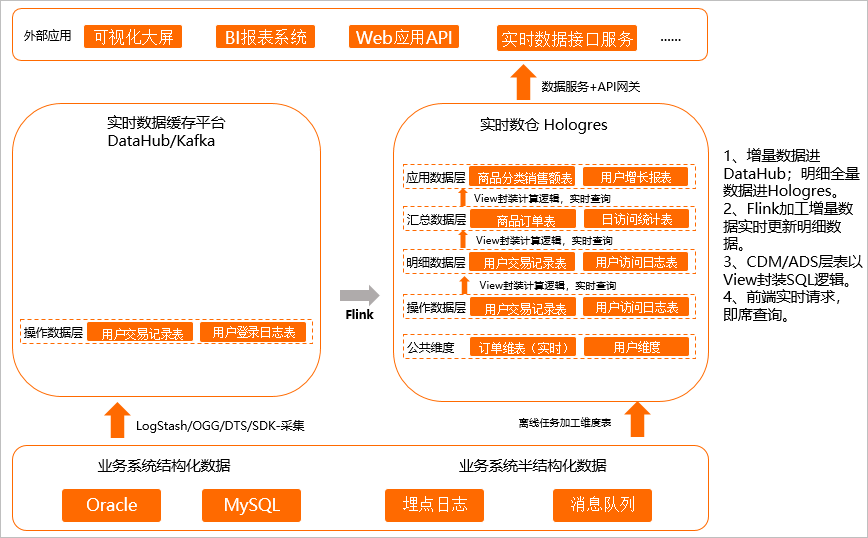
即席查詢通俗來說就是不確定應用的具體查詢模式,先把數據存下來,后續支撐盡量多靈活性的場景,如下圖所示。
 因此建議您應用如下策略:
因此建議您應用如下策略:
將操作層(ODS層)的數據經過簡單的清理、關聯,然后存儲到明細數據,暫不做過多的二次加工匯總,明細數據直接寫入Hologres。
Flink加工增量數據,實時更新明細數據至Hologres,MaxCompute加工后的離線表寫入Hologres。
因為上層的分析SQL無法固化,在CDM/ADS層以視圖(View)封裝成SQL邏輯。
上層應用直接查詢封裝好的View,實現即席查詢。
方案優勢:
靈活性強,可隨時根據業務邏輯調整View。
指標修正簡單,上層都是View邏輯封裝,只需要刷新一層數據,更新底表的數據即可,因為上層沒有匯聚表,無需再次更新上層應用表。
方案缺點:當View的邏輯較為復雜,數據量較多時,查詢性能較低。
適用場景:數據來源于數據庫和埋點系統,適合對QPS要求不高,對靈活性要求比較高,且計算資源較為充足的場景。
實時數倉場景二:分鐘級準實時
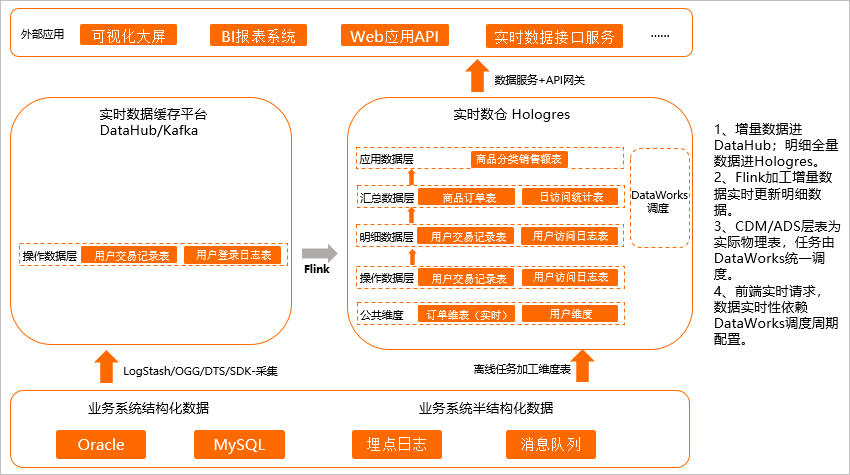
場景一的計算效率在某些場景上還存在不足,無法支撐更高的QPS,場景二是場景一的升級,把場景一中視圖的部分物化成表,邏輯與場景一相同,但是最終落在表上的數據量變少,顯著提升查詢性能,可以獲得更高的QPS,如下圖所示。
 建議您應用如下策略:
建議您應用如下策略:
將操作層(ODS層)的數據經過簡單的清理、關聯,然后存儲到明細數據,暫不做過多的二次加工匯總,明細數據直接寫入Hologres。
Flink加工增量數據實時更新明細數據至Hologres。
CDM/ADS層為實際的物理表,通過DataWorks等調度工具調度周期性寫入數據。
前端實時請求實際的物理表,數據的實時性依賴DataWorks調度周期配置,例如5分鐘調度、10分鐘調度等,實現分鐘級準實時。
方案優勢:
查詢性能強,上層應用只查最后匯總的數據,相比View,查詢的數據量更好,性能會更強。
數據重刷快,當某一個環節或者數據有錯誤時,重新運行DataWorks調度任務即可。因為所有的邏輯都是固化好的,無需復雜的訂正鏈路操作。
業務邏輯調整快,當需要新增或者調整各層業務,可以基于SQL所見即所得開發對應的業務場景,業務上線周期縮短。
方案缺點:時效性低于方案一,因為引入了更多的加工和調度。
適用場景:數據來源于數據庫和埋點系統,對QPS和實時性均有要求,適合80%實時數倉場景使用,能滿足大部分業務場景需求。
實時數倉場景三:增量數據實時統計
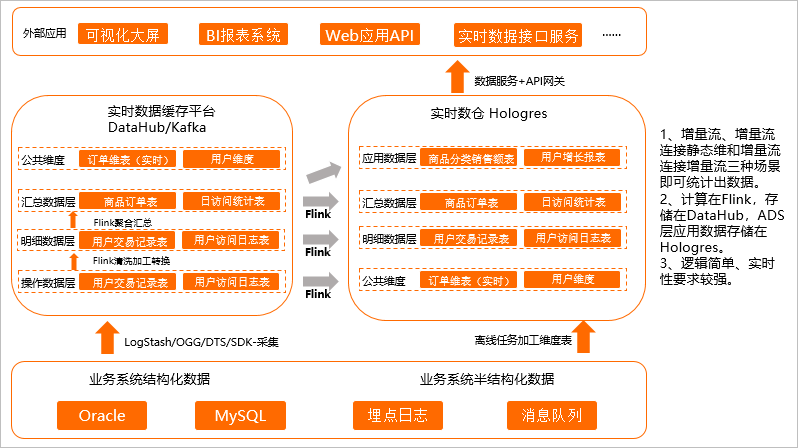
增量計算的場景是因為一些場景對數據延遲非常敏感,數據產生的時候必須完成加工,此時通過增量計算的方式,提前用Flink將明細層、匯總層等層數據進行匯聚,匯聚之后把結果集存下來再對外提供服務,如下圖所示。
 在增量計算中,建議您應用如下策略:
在增量計算中,建議您應用如下策略:
增量計算的數據由Flink進行清洗加工轉換和聚合匯總,ADS層應用數據存儲在Hologres中。
Flink加工的結果集采取雙寫的方式,一方面繼續投遞給下一層消息流Topic,一方面Sink到同層的Hologres中,方便后續歷史數據的狀態檢查與刷新。
在Flink內通過增量流、增量流連接靜態維表、增量流連接增量流這三種場景統計出數據,寫入Hologres。
Hologres通過表的形式直接對接上層應用,實現應用實時查詢。
方案優勢:
實時性強,能滿足業務對實時性敏感的場景。
指標修正簡單,與傳統增量計算方式不一樣的是,該方案將中間的狀態也持久存儲在Hologres中,提升了后續分析的靈活性,當中間數據質量有問題時,直接對表修正,重刷數據即可。
方案缺點:大部分實時增量計算都依賴Flink,對使用者Flink的技能和熟練度要求會更高一些;不適合數據頻繁更新,無法累加計算的場景,不適合多流Join等計算復雜資源開銷大場景。
適用場景:實時需求簡單,數據量不大,以埋點數據統計為主的數據,只需要增量數據即可統計結果的場景,實時性最強。