UPDATE
UPDATE語句用于更新目標表指定列的行數(shù)據(jù)。本文為您介紹在Hologres中UPDATE語句的用法。
命令介紹
UPDATE命令的語法如下所示。
UPDATE <table> [ * ] [ [ AS ] <alias> ]
SET { <column> = { <expression> } |
( <column> [, ...] ) = ( { <expression> } [, ...] ) } [, ...]
[ FROM <from_list> ]
[ WHERE <condition> ]參數(shù)說明如下表所示。
參數(shù) | 描述 |
table | 更新目標表的名稱。 |
alias | 別名。目標表的替代名稱。 |
column | 更新目標表中目標列的名稱。 |
expression | 表達式 |
from_list | 數(shù)據(jù)來源的列名稱。 |
condition | 更新目標表的條件。 |
技術原理
在Hologres中,每一張表都會有一個數(shù)據(jù)文件、主鍵索引文件以及標記文件,主鍵索引文件詳情請參見主鍵Primary Key。標記文件主要用在DELETE、UPDATE、INSERT ON CONFLICT等有數(shù)據(jù)刪除、更新的場景中。以如下SQL為例來介紹Hologres UPDATE原理。
create table update_test (
col1 text NOT NULL PRIMARY KEY,
col2 text
);
UPDATE update_test SET col2 = 'tom' where col1 = 'a1';示意圖如下。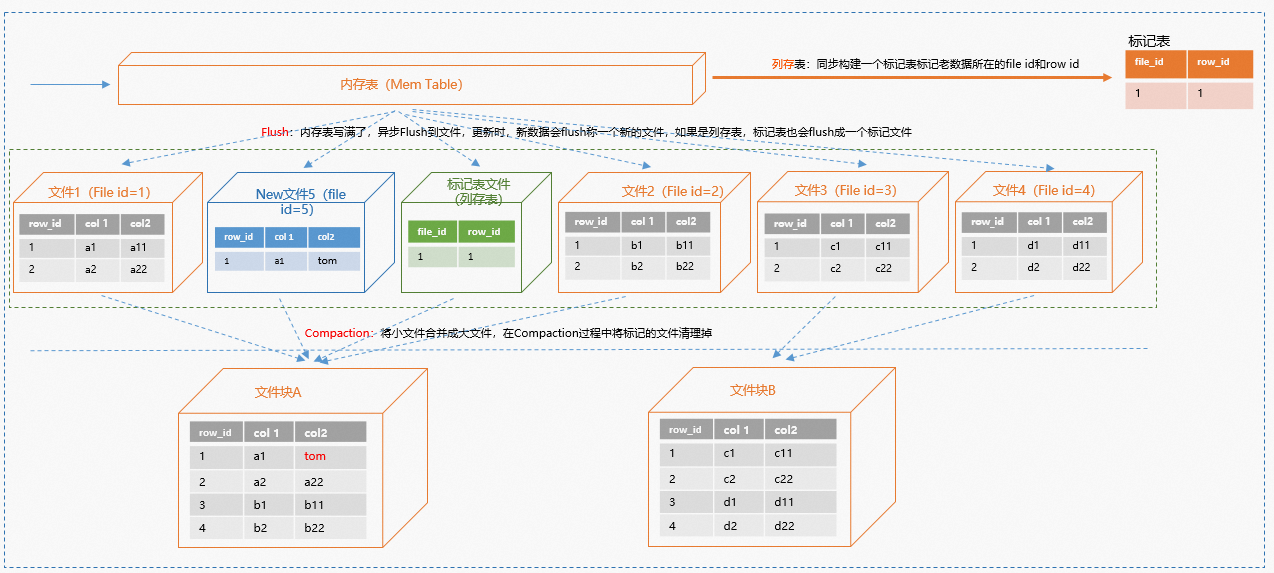 數(shù)據(jù)更新時,會先將數(shù)據(jù)寫入到內(nèi)存表(Mem Table),然后異步Flush到文件。對于行存表,會直接將新數(shù)據(jù)Flush成一個新的文件,然后在Compaction的時候合并掉舊數(shù)據(jù)。對于列存表,內(nèi)存中會構(gòu)建一個標記表,記錄刪除數(shù)據(jù)所在的文件號(file id)和行號(row id),然后進行Flush操作,其中新數(shù)據(jù)會Flush成一份新的文件,標記表也會Flush成一個標記文件。后臺會將標記文件和數(shù)據(jù)文件進行Compaction,在Compaction的過程中就會將舊數(shù)據(jù)給清理掉,并合并新數(shù)據(jù)。為了更新的速度盡可能的快,后臺會先將數(shù)據(jù)寫完,待異步Compaction時再執(zhí)行壓縮和整理,因此在數(shù)據(jù)更新過程中,會看到數(shù)據(jù)的存儲會一定的膨脹,待數(shù)據(jù)更新之后,Compaction完成后實例存儲用量會下降。Hologres高性能寫入更新原理詳情請參見Hologres高性能寫入技術大揭秘。
數(shù)據(jù)更新時,會先將數(shù)據(jù)寫入到內(nèi)存表(Mem Table),然后異步Flush到文件。對于行存表,會直接將新數(shù)據(jù)Flush成一個新的文件,然后在Compaction的時候合并掉舊數(shù)據(jù)。對于列存表,內(nèi)存中會構(gòu)建一個標記表,記錄刪除數(shù)據(jù)所在的文件號(file id)和行號(row id),然后進行Flush操作,其中新數(shù)據(jù)會Flush成一份新的文件,標記表也會Flush成一個標記文件。后臺會將標記文件和數(shù)據(jù)文件進行Compaction,在Compaction的過程中就會將舊數(shù)據(jù)給清理掉,并合并新數(shù)據(jù)。為了更新的速度盡可能的快,后臺會先將數(shù)據(jù)寫完,待異步Compaction時再執(zhí)行壓縮和整理,因此在數(shù)據(jù)更新過程中,會看到數(shù)據(jù)的存儲會一定的膨脹,待數(shù)據(jù)更新之后,Compaction完成后實例存儲用量會下降。Hologres高性能寫入更新原理詳情請參見Hologres高性能寫入技術大揭秘。
從更新的原理中,可以看到列存表總是會有一次標記表的記錄和反查過程,所以更新效率:行存表>列存表。
結(jié)果表有主鍵
如果為表設置了主鍵(PK),那么主鍵索引文件就可以通過PK快速定位到RID,然后定位到數(shù)據(jù)文件。在UPDATE的過程中也是如此,可以通過主鍵快速過濾出要更新的文件,減少文件掃描;如果沒有主鍵,更新就很容易退化成全表更新,導致性能變差。詳情請參見主鍵Primary Key。
局部更新
局部更新是指部分列更新,缺失的列不更新。局部更新是Hologres特有的更新功能,能夠滿足更多的業(yè)務需求。局部更新的原理同整行更新一致,但在細節(jié)處有一些略微差異:
行存表因為是LSM結(jié)構(gòu),局部更新的數(shù)據(jù)以Append Only的方式寫入。
列存需要先查詢?nèi)笔Я械闹翟賹懭耄瑫懈蟮南摹?/p>
行列混合存同樣需要先查詢?nèi)笔У牧校土写娌煌氖牵辛谢旌洗娌樵內(nèi)笔Я袝r會通過行存文件進行查詢,代價會更小。
因此局部更新在性能上:行存>行列共存>列存。
以上描述的是SQL走Fixed Plan場景,局部更新性能:行存>行列共存>列存。但如果局部更新未走Fixed Plan,局部更新相當于是兩表Join,性能:列存>行列共存>行存。
局部更新示例如下:
--局部更新示例:
create table update_test2 (
col1 text NOT NULL PRIMARY KEY,
col2 text,
col3 text
);
INSERT INTO update_test2 VALUES ('a1','a2','a3'),('a11','a22','a33');
--update局部更新
UPDATE update_test2 SET col2 = 'tom' where col1 = 'a1';
--局部更新的另外一種寫法,通過insert on conflict局部更新
INSERT INTO update_test2 (col1,col2) VALUES ('a1','tom')
ON CONFLICT(col1) DO UPDATE
SET col2 = EXCLUDED.col2;
--局部更新后的結(jié)果
col1 | col2 | col3
------+------+------
a1 | tom | a3
a11 | a22 | a33
(2 rows)
使用限制
Hologres不支持更新Distribution Key。
Hologres不支持直接更新分區(qū)表父表,您只能更新具體的分區(qū)表子表。
推薦使用Fixed Plan優(yōu)化Update執(zhí)行效率,參考UPDATE場景。
使用示例
更新表的示例語句如下。
CREATE TABLE update_test (
a text primary key,
b int not null,
c text not null,
d text);
INSERT INTO update_test VALUES ('b1', 10, '', '');
UPDATE update_test SET b = b + 10 where a = 'b1';
UPDATE update_test SET c = 'new_' || a, d = null where b = 20;
UPDATE update_test SET (b,c,d) = (1, 'test_c', 'test_d');
CREATE TABLE tmp(a int);
INSERT INTO tmp VALUES (2);
UPDATE update_test SET b = tmp.a FROM tmp;更多關于UPDATE命令的詳情,請參見PostgreSQL官網(wǎng)文檔。
常見問題
在執(zhí)行UPDATE命令時,為什么監(jiān)控指標中存儲用量先上漲,UPDATE完成后存儲用量又下降?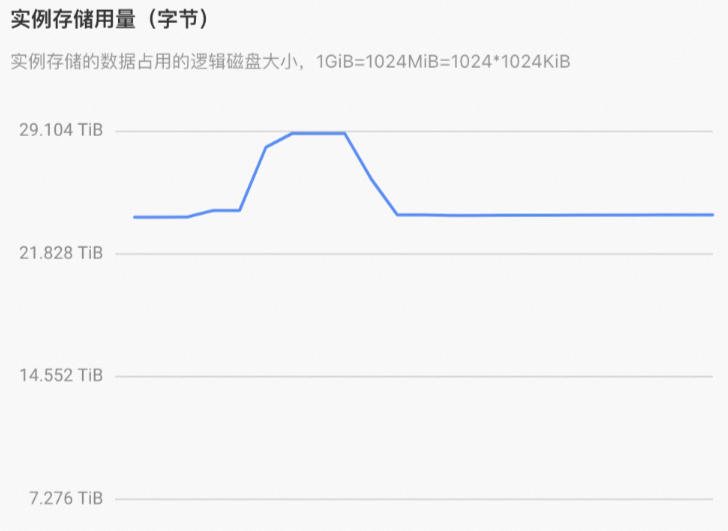
根據(jù)UPDATE的技術原理,UPDATE時會將老數(shù)據(jù)做標記,新數(shù)據(jù)會Flush成新的小文件,后臺會將這些小文件做Compaction,在Compaction的過程中就會將老數(shù)據(jù)給清理掉,并合并新數(shù)據(jù)。為了更新速度盡可能的快,后臺會先將數(shù)據(jù)寫完,待異步Compaction時再執(zhí)行壓縮和整理,因此會看到在數(shù)據(jù)更新過程中,數(shù)據(jù)的存儲會一定的膨脹,等數(shù)據(jù)更新之后,Compaction完成后存儲會下降,更多詳情請參見技術原理。