在文件存儲 HDFS 版上使用Apache HBase
本文主要介紹在文件存儲 HDFS 版上使用Apache HBase的方法。
前提條件
已開通文件存儲 HDFS 版服務(wù)并創(chuàng)建文件系統(tǒng)實例和掛載點(diǎn)。具體操作,請參見文件存儲HDFS版快速入門。
已為Hadoop集群所有節(jié)點(diǎn)安裝JDK,且JDK版本不低于1.8。
已部署Apache HBase分布式集群,且版本必須與Hadoop版本兼容。具體操作,請參見Apache HBase Reference Guide。
本文使用Hadoop-2.10.1和HBase-2.3.7測試驗證。更多信息,請參見HBase官網(wǎng)Hadoop版本兼容性說明。
如果您使用的是阿里云E-MapReduce中內(nèi)置的HBase,請參見在文件存儲HDFS版上使用E-MapReduce。
步驟一:Hadoop集群掛載文件存儲 HDFS 版實例
在Hadoop集群中配置文件存儲 HDFS 版實例。具體操作,請參見掛載文件存儲 HDFS 版文件系統(tǒng)。
步驟二:配置Apache HBase
將Hadoop中配置的core-site.xml復(fù)制到${HBASE_HOME}/conf目錄下。
cp ${HADOOP_HOME}/etc/hadoop/core-site.xml ${HBASE_HOME}/conf配置
${HBASE_HOME}/conf/hbase-site.xml。<property> <!-- 使用分布式模式運(yùn)行HBase --> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <!-- 指定HBase存儲目錄,f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com為您的掛載點(diǎn)域名,根據(jù)實際情況修改 --> <name>hbase.rootdir</name> <value>dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/hbase</value> </property> <property> <!-- 在文件存儲 HDFS 版上使用HBase時該配置必須設(shè)置為false --> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <!-- 依賴的ZooKeeper配置, 請根據(jù)實際情況修改 --> <name>hbase.zookeeper.quorum</name> <value>hostname:2181</value> </property>配置${HBASE_HOME}/conf/hbase-env.sh。
## HBase不使用自己的ZooKeeper export HBASE_MANAGES_ZK=false ## 在HBASE_CLASSPATH中添加文件存儲 HDFS 版Java SDK export HBASE_CLASSPATH=/path/to/aliyun-sdk-dfs-x.y.z.jar:${HBASE_CLASSPATH}
步驟三:驗證Apache HBase
執(zhí)行以下命令,啟動HBase。
${HBASE_HOME}/bin/start-hbase.sh重要啟動分布式HBase集群前確保ZooKeeper已經(jīng)啟動。
創(chuàng)建測試文件(例如dfs_test.txt)并寫入如下內(nèi)容。
create 'dfs_test', 'cf' for i in Array(0..9999) put 'dfs_test', 'row'+i.to_s , 'cf:a', 'value'+i.to_s end list 'dfs_test' scan 'dfs_test', {LIMIT => 10, STARTROW => 'row1'} get 'dfs_test', 'row1'執(zhí)行以下命令,在HBase中創(chuàng)建表并寫入10000條數(shù)據(jù)。
${HBASE_HOME}/bin/hbase shell dfs_test.txt其中,
dfs_test.txt為剛創(chuàng)建的測試文件,請根據(jù)實際情況替換。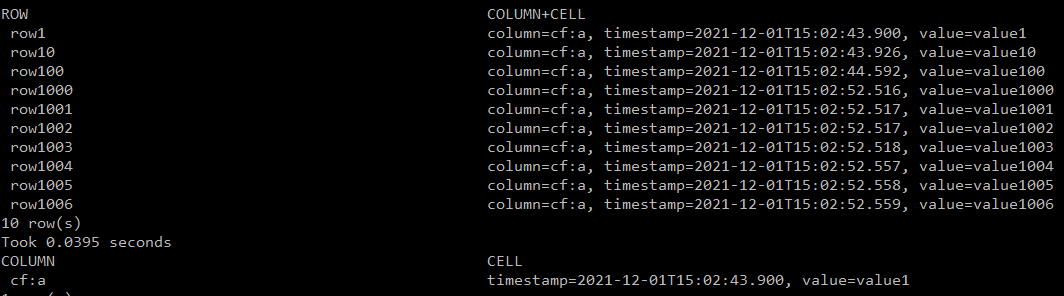
使用MapReduce計算行數(shù)。
重要在YARN上執(zhí)行MapReduce計數(shù)前需要先在Hadoop集群中啟動YARN服務(wù)。
執(zhí)行命令
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-2.3.7.jar \ rowcounter dfs_test返回信息
如果計算行數(shù)與寫入數(shù)據(jù)一致,則表示Apache HBase配置成功。
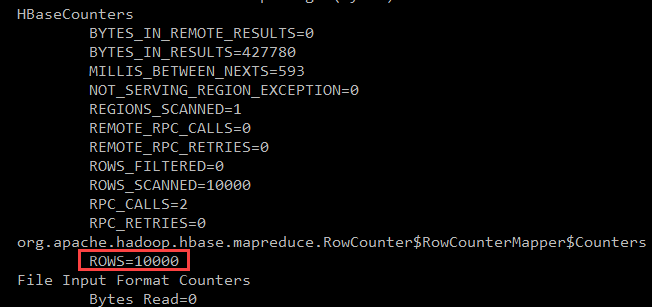
如果在環(huán)境變量中已配置HADOOP_HOME及HADOOP_CLASSPATH也可以執(zhí)行以下命令進(jìn)行RowCounter計算。
${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter dfs_test