本章節介紹圖計算服務GraphCompute使用過程中遇到的常用名詞的基本概念和簡要描述。
實例
獨享型實例:客戶創建的一個圖計算服務GraphCompute實例,每個實例都是保證雙副本,采用proxy + searcher的集群架構服務。在獨享實例下可由客戶自行創建多個圖模型。
iGraph引擎
iGraph引擎:阿里巴巴自主研發的圖引擎iGraph。該引擎提供高性能、低延遲的查詢計算能力,是Graph Compute一站式圖計算平臺的引擎內核。
Proxy/Searcher
proxy:iGraph引擎的計算層,負責接受用戶請求并處理成具體的執行計劃,然后轉發給下層searcher,同時支持合并、分組等復雜的算子。
searcher:iGraph引擎的存儲層,負責加載和管理各種索引并服務上層proxy轉發的查詢請求,同時支持排序、打散、截斷等簡單算子。
數據表
支持KV、KKV、倒排三種表類型來支持屬性圖數據模型;
該數據表包括源數據、自定義字段屬性、索引相關信息的schema信息,用于后續GraphCompute系統構建索引的基本信息。
通過離線系統進行索引構建,從而產生對應表類型的索引結構(KV索引/KKV索引/倒排索引),最終這些索引內容將加載到引擎服務中,可通過API/SDK接口訪問的方式進行查詢。
屬性圖
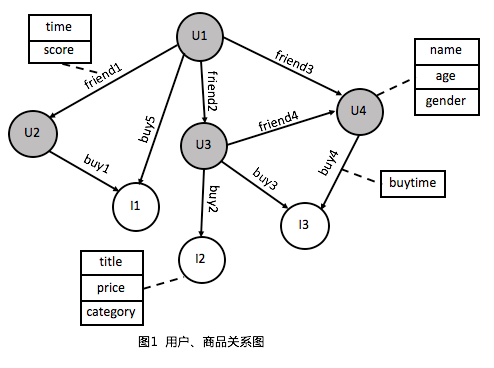
屬性圖(如下圖1所示)具有如下特征:
屬性圖由不同的節點和邊組成
用戶節點U1/U2/U3/U4和商品節點I1/I2/I3
好友關系friend1/friend2/friend3/friend4,購買關系buy1/buy2/buy3/buy4/buy5
屬性圖中所有邊都是有向邊
屬性圖中的節點和邊都有屬性
用戶節點有屬性name、age、gender
商品節點有屬性title、price、category
好友關系有屬性time、score
購買關系有屬性buytime
節點和邊都有類型,相同類型的節點或邊的屬性是同構的
Key-Value表
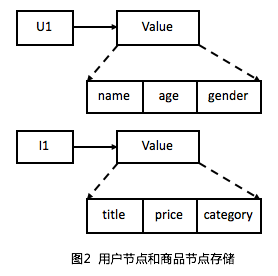
簡稱KV表(如下圖2所示),通常用來存儲屬性圖中的節點實例(比如圖1中的用戶節點、商品節點)。其中Key存儲節點ID(比如用戶節點ID,U1),Value存儲節點屬性(比如用戶節點屬性name、age、gender)。
PKey-SKey-Value表
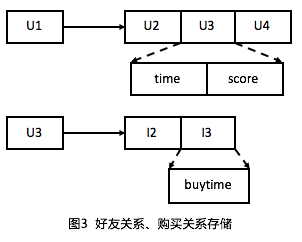
簡稱KKV表(如下圖3所示),通常用來存儲屬性圖中的關系實例(如圖1中的好友關系),其中PKey(primary key)存儲一條邊的源節點ID(上圖中節點U1),SKey(secondary key)存儲一條邊的目標節點ID(比如上圖中節點U2/U3/U4),Value用來存放關系的屬性(比如好友關系的time和score屬性)。
倒排表
也可稱為Index表,倒排表中定義了索引存儲從單詞到DocID的映射關系。倒排表主要定義源數據以及數據類型,包括倒排配置schema字段。
什么是倒排索引? 倒排索引也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,被用來存儲在全文搜索下某個單詞在一個文檔或者一組文檔中的存儲位置的映射。它是文檔檢索系統中最常用的數據結構。
倒排索引可以為我們做什么? 通過倒排索引,可以快速定位單詞所在的文檔列表以及該詞在文檔中的位置,詞頻等信息。供信息分析使用。
Gremlin語法
基于C++語言,實現開源Gremlin算子,并提供查詢語法。
語法詳述見功能概覽
使用過程中請注意:iGraph Gremlin語法與開源使用差異
其他相關服務
MaxCompute:大數據計算服務MaxCompute(原名ODPS)是一種快速、完全托管的TB/PB級數據倉庫解決方案,提供了完善的數據導入方案以及多種經典的分布式計算模型,能夠快速地解決海量數據計算問題。