數據集成是大數據開發治理平臺DataWorks提供的數據同步服務,致力于提供復雜網絡環境下、豐富的異構數據源之間高速穩定的數據移動及同步能力。借助DataWorks提供的數據同步能力可將多種數據源的數據批量寫入iGraph。
本文為您講解如何配置數據從MaxCompute一次同步全量數據至iGraph,以及配置周期任務同步增量數據。
前提條件
1.已在阿里云官網購買DataWorks產品。
2.已購買合適規格的獨享數據集成資源組,獨享數據資源組用于提供數據同步時使用的機器資源和網絡環境。詳情請參見:新增和使用獨享數據集成資源組。
3.已完成數據集成資源組與iGraph網絡端連通,詳情請參見:配置資源組與網絡連通。在數據同步任務配置與執行前, 需要確保上下游數據源與購買的獨享數據集成資源組網絡連通,通常做法是上下游數據源購買在同一個VPC網絡內,并通過鏈接中的方式將購買的集成資源組綁定該VPC。
4.已完成數據源環境準備。在同步任務執行前,授予數據源配置的賬號在數據庫進行相應操作的權限。詳情請參見:數據庫環境準備概述。
5.對于數據離線同步的腳本模式已有初步了解。詳情請參見:通過腳本模式配置離線同步任務。
操作流程
1.確認同步方案
整庫離線同步可選擇的同步方案如下表所示。
同步方案 | 描述 |
全量一次性同步 | 只執行一次同步操作,將來源數據源的存量數據,全量同步至iGraph中。 |
周期性增量同步 | 按照指定的周期調度,每次執行任務時僅將增量數據同步至iGraph中。 |
通常的同步方案是先做一次全量一次性同步,將已有的數據同步至iGraph。之后選擇一個固定的時間間隔,周期將新增的數據同步至iGraph中,確保數據最終一致。
2.創建數據離線同步節點
登錄DataWorks控制臺,在左側導航欄,單擊工作空間列表。選擇工作空間所在地域后,單擊相應工作空間的數據開發。進入數據開發界面。
創建業務流程,詳情請參見:創建業務流程。之后創建離線同步節點,展開業務流程,右鍵單擊數據集成 > 新建節點 > 離線同步。
3.進入腳本模式添加數據同步腳本模板
單擊工具欄中的轉換腳本圖標。
將準備好的腳本模板粘貼進去。此處給出MaxCompute到iGraph的數據同步腳本模板:
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "odps",
"parameter": {
"accessId": "${maxcompute_accessid}",
"accessKey": "${maxcompute_key}",
"odpsServer": "${maxcompute_server}",
"tunnelServer": "${maxcompute_tunnel}",
"isCompress": "false",
"partition": [
"ds=${maxcompute_partition}"
],
"column": [
"id",
"name"
],
"project": "${maxcompute_project}",
"table": "${maxcompute_table}"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "igraph",
"parameter": {
"graphName": "${igraph_graph}",
"endpoint": "${igraph_endpoint}",
"username": "${igraph_username}",
"password": "${igraph_password}",
"pkField": "id",
"column": [
"id",
"name"
],
"cmd": "ADD",
"labelName": "${igraph_label}"
},
"name": "Writer",
"category": "writer"
},
{
"copies": 1,
"parameter": {
"nodes": [],
"edges": [],
"groups": [],
"version": "2.0"
},
"name": "Processor",
"category": "processor"
}
],
"setting": {
"errorLimit": {
"record": "1"
},
"locale": "zh",
"speed": {
"throttle": false,
"concurrent": 4
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}4.執行一次離線全量同步
點擊右側“數據集成資源組配置”面板,選擇購買的集成資源組后保存任務。
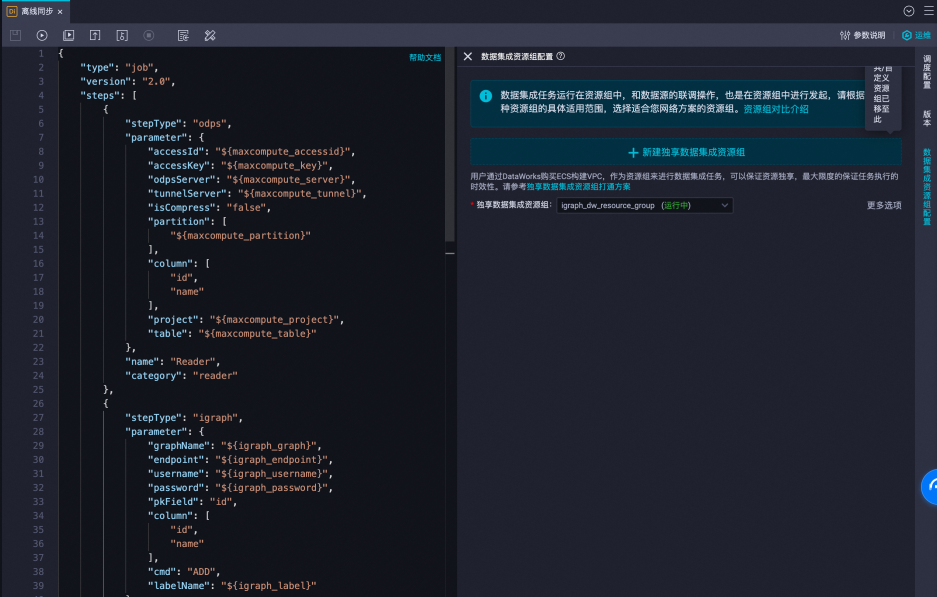
點擊上側面板中的“帶參執行”,填入對應的參數后點擊運行。此處為了同步全量數據,maxcompute_partition參數填寫*,可以匹配到指定MaxCompute下所有分區,MaxCompute的分區配置支持linux Shell通配符,填寫規則詳情請參見:MaxCompute Reader,下游數據源iGraph參數填寫規則詳情請參見:iGraph Writer配置。
如果上游需要使用其他數據源,可替換模板中Reader部分,腳本模板中可適配的上游數據源詳情請參見支持的數據源與讀寫插件。
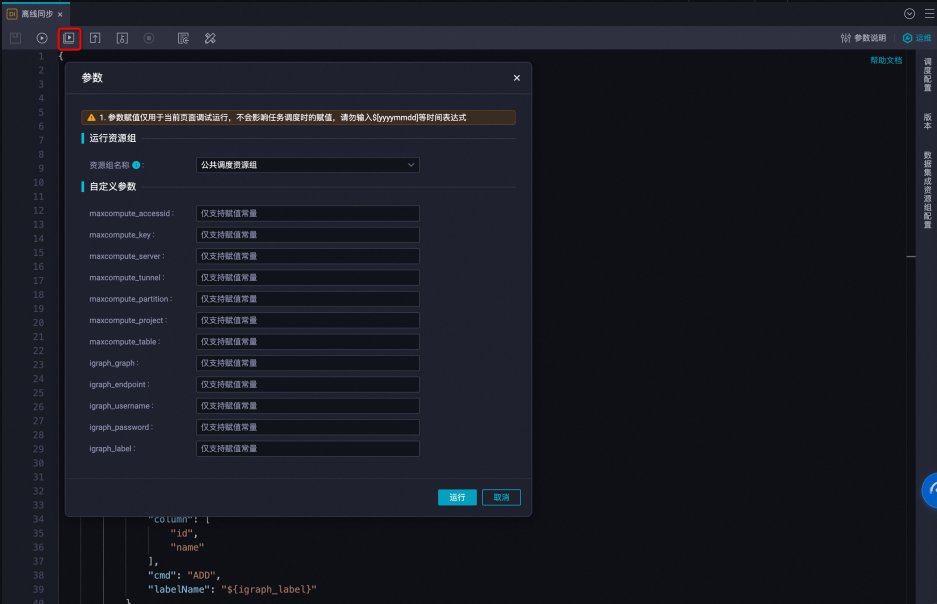
運行結束后可以在底部日志面板查看數據同步任務執行是否成功。
5.配置周期增量同步的調度屬性
周期性的增量同步需要配置任務自動調度時的相關屬性,此步驟介紹如何配置這些屬性。您可以進入離線同步節點的編輯頁面,單擊右側的調度配置,下文將為您介紹如何在同步任務中配置節點調度屬性。調度參數使用說明請參見數據集成使用調度參數的相關說明。
配置節點調度屬性:用于為任務配置階段使用的變量賦值調度參數,您在上述配置中定義的變量均可以在此處進行賦值,支持賦值常量與變量。
配置時間屬性:用于定義任務在生產環境的周期調度方式。您可以在調度配置的時間屬性區域,配置任務生成周期實例的方式、調度類型、調度周期等屬性。
配置資源屬性:用于定義調度場景下,將當前任務下發至數據集成任務執行資源時所使用的調度資源組,您可以在調度配置的資源屬性區域,選擇任務調度運行時需要使用的資源組。
以增量數據由MaxCompute同步到iGraph為例,每隔一個周期上游節點應該會產出一個新分區數據存儲需要同步的增量數據,一般分區名會與時間屬性掛鉤,那么同步的模板中${maxcompute_partition}參數可配置為此時間屬性,并將此任務依賴上游分區產出節點。
每當一個新分區產出時,都會自動調度此離線同步任務將新分區數據同步進iGraph。
6.提交并發布任務
若任務需要進行周期性調度運行,您需要將任務發布至生產環境。關于任務發布,詳情請參見:發布任務。