本文介紹如何使用GPU預留實例,以及如何基于GPU預留實例構建延遲敏感的實時推理服務。
背景信息
場景介紹
在實時推理應用場景中,工作負載具有以下一個或多個特征。
低延遲
單次請求的處理時效性要求高,RT(Response Time)延遲要求嚴格,90%的長尾延時普遍在百毫秒級別。
主鏈路
普遍位于業務核心鏈路,推理成功率要求高,不接受長時間重試。示例如下。
開屏廣告推薦/首頁產品推薦:根據用戶的行為喜好,在應用開屏時進行用戶行為的推薦,并實時地展現在用戶終端上。
實時流程媒體生產:在互動連麥、直播帶貨、超低延時播放等場景下,音視頻流均需要以極低的延遲在端到端之間進行傳播,AI視頻超分、AI視頻識別的實時性需要保證。
峰波峰谷
業務流量具有明顯的潮汐特征,普遍與終端用戶使用習慣高度相關。
資源利用率
由于GPU資源規劃普遍根據業務高峰評估,峰谷時存在較大資源浪費,資源利用率普遍低于30%。
功能優勢
函數計算為實時推理工作負載提供以下功能優勢。
預留GPU實例
函數計算平臺提供了默認的按量GPU實例之外的另一種GPU使用方式——預留GPU實例。如果您希望消除冷啟動延時的影響,滿足實時推理業務低延遲響應的要求,可以通過配置預留GPU實例來實現。更多關于預留模式的信息,請參見彈性管理(含預留模式)。
預留GPU實例的彈性伸縮策略(推薦)
函數計算平臺為預留GPU實例提供了多種指標的彈性伸縮策略,包括并發度、GPU SM利用率、GPU顯存利用率、GPU Encoder利用率和GPU Decoder利用率,以及按時彈性伸縮策略,以滿足實時推理業務在不同峰波峰谷下對GPU實例算力的供給要求,從而降低整體部署成本。
服務質量優先,服務成本次優
預留GPU實例的計費周期不同于按量GPU實例,預留GPU實例是以實例存活生命周期進行計費,而不考慮實例的活躍與閑置(不按請求計費)。因此,相較于按量GPU實例,總體使用成本較高,但相較于長期自建GPU集群,降本幅度達50%以上。
規格最優
函數計算平臺提供的GPU實例規格,允許您根據自己的工作負載選擇不同的卡型,獨立配置CPU/GPU/MEM/DISK。最小GPU規格小至1 GB顯存/算力,將為您提供最貼合業務的實例規格。
突發流量支撐
函數計算平臺提供充足的GPU資源供給,當業務遭遇突發流量時,函數計算將以秒級彈性供給海量GPU算力資源,避免因GPU算力供給不足、GPU算力彈性滯后導致的業務受損。
功能原理
當GPU函數部署完成后,您可以通過配置預留GPU實例的彈性伸縮策略開啟預留GPU實例,以提供實時推理應用場景所需的基礎設施能力。函數計算平臺將根據您配置的伸縮指標進行預留GPU實例的HPA,客戶請求將優先分配至預留GPU實例進行推理服務,平臺完全遮蔽冷啟動,業務保持低延遲響應。

實時推理場景基本信息
容器支持
函數計算GPU場景下,當前僅支持以Custom Container(自定義容器運行環境)進行交付。關于Custom Container的使用詳情,請參見Custom Container簡介。
Custom Container同時支持Web Server模式與非Web Server模式,在線推理應用場景普遍選擇Web Server模式的容器交付,離線應用場景普遍選擇非Web Server模式的容器交付。
Web Server模式需要在鏡像內攜帶Web Server,滿足執行不同代碼路徑、通過事件或HTTP觸發函數的需求。適用于AI學習推理等多路徑請求執行場景。更多信息,請參見Web Server模式。
GPU實例規格
您可以在推理應用場景下,根據業務需要,特別是算法模型所需要的CPU算力、GPU算力與顯存、內存、磁盤,選擇不同的GPU卡型與GPU實例規格。關于GPU實例規格的詳細信息,請參見實例規格。
模型部署方式
您可以使用多種方式將您的模型部署在函數計算。
通過函數計算控制臺部署。具體操作,請參見在控制臺創建函數。
通過調用SDK部署。更多信息,請參見API概覽。
通過Serverless Devs工具部署。更多信息,請參見Serverless Devs操作命令。
更多部署示例,請參見start-fc-gpu。
預留模式的彈性伸縮
定時修改彈性伸縮策略
函數計算支持使用定時修改彈性伸縮策略。具體操作,請參見定時修改限制。在實時推理場景中,如果您的流量波形呈現為較規律的潮汐流量,您可以在流量高峰來臨前的若干分鐘,進行預留GPU實例數量的修改;在流量水位下降后,再進行縮容操作,協調最佳的成本和最優的性能。
根據指標的彈性伸縮策略
函數計算針對GPU函數提供以下五種可追蹤指標,您可以根據業務的特性選擇所需要追蹤的指標,來指導動態的彈性策略。
實時推理應用場景中,推薦使用ProvisionedConcurrencyUtilization并發度指標作為HPA指標。因為并發度/QPS更偏向業務指標,GPU資源利用率更偏向資源指標,業務指標變化會影響資源指標,使用更偏向業務的并發度/QPS指標,可以更及時地觸發預留GPU實例擴縮容行為,從而優先保障業務服務質量。
指標名稱 | 描述 | 取值范圍 |
ProvisionedConcurrencyUtilization | 預留實例的并發利用率。用于統計該函數預留實例正在響應的請求并發值與該函數所有預留實例最大可響應并發值的占比。 | [0, 1],對應利用率為0%~100% |
GPUSmUtilization | GPU SM利用率。用于統計多個實例GPU SM利用率的最大值。 | |
GPUMemoryUtilization | GPU顯存利用率。用于統計多個實例GPU顯存利用率的最大值。 | |
GPUDecoderUtilization | GPU硬件解碼器利用率。用于統計多個實例GPU硬件解碼器利用率的最大值。 | |
GPUEncoderUtilization | GPU硬件編碼器利用率。用于統計多個實例GPU硬件編碼器利用率的最大值。 |
模型服務預熱
為了解決模型上線后初次請求耗時較長的問題,函數計算為您提供了模型預熱的功能。模型預熱的目的是使模型上線后即可進入正常的服務狀態。
函數計算推薦您配置實例的initialize生命周期回調功能來實現模型預熱,函數計算會在您的實例啟動后自動執行initialize里的業務邏輯來進行模型服務預熱。更多信息,請參見函數實例生命周期回調。
您可以通過以下操作使用模型預熱。
在實例的
initialize生命周期回調功能中加入模型預熱邏輯。在您構建的HTTP Server中添加POST方法的
/initialize的調用Path,并將模型預熱的邏輯放在/initialize的Path下。通常可以讓模型服務來執行簡單的推理來實現預熱的效果。下面是Python語言的示例代碼。def prewarm_inference(): res = model.inference() @app.route('/initialize', methods=['POST']) def initialize(): request_id = request.headers.get("x-fc-request-id", "") print("FC Initialize Start RequestId: " + request_id) # Prewarm model and perform naive inference task. prewarm_inference() print("FC Initialize End RequestId: " + request_id) return "Function is initialized, request_id: " + request_id + "\n"在函數配置頁面配置實例生命周期回調信息。
在對應的函數詳情頁面的函數配置頁簽下,單擊實例生命周期回調區域的編輯,在實例生命周期回調面板配置Initializer回調信息。

配置彈性伸縮并驗證
本文為您介紹兩種配置GPU實例的彈性伸縮策略的方法,分別為:
配置完彈性伸縮策略后,您可以通過壓測的方式查看彈性伸縮的效果,具體請參見執行壓測。
通過Serverless Devs工具配置GPU實例的彈性伸縮策略
前提條件
在GPU實例所在地域,完成以下操作:
創建容器鏡像服務的企業版實例或個人版實例,推薦您創建企業版實例。具體操作步驟,請參見創建企業版實例。
創建命名空間鏡像倉庫。具體操作步驟,請參見步驟二:創建命名空間和步驟三:創建鏡像倉庫。
操作步驟
執行以下命令,克隆工程。
git clone https://github.com/devsapp/start-fc-gpu.git部署項目。
執行以下命令,進入項目目錄。
cd fc-http-gpu-inference-paddlehub-nlp-porn-detection-lstm/src/項目結構如下所示。
. ├── hook │ └── index.js └── src ├── code │ ├── Dockerfile │ ├── app.py │ ├── hub_home │ │ ├── conf │ │ ├── modules │ │ └── tmp │ └── test │ └── client.py └── s.yaml執行以下命令,通過Docker構建鏡像,并向您的鏡像倉庫進行推送。
export IMAGE_NAME="registry.cn-shanghai.aliyuncs.com/fc-gpu-demo/paddle-porn-detection:v1" # sudo docker build -f ./code/Dockerfile -t $IMAGE_NAME . # sudo docker push $IMAGE_NAME重要由于PaddlePaddle框架自身體積較大,首次構建鏡像耗時較久,約1個小時,因此,此處為您提供一個VPC地址的公共鏡像供您直接使用。使用公共鏡像時,無需執行上述docker build和docker push命令。
編輯s.yaml文件。
edition: 1.0.0 name: container-demo access: {access} vars: region: cn-shanghai services: gpu-best-practive: component: devsapp/fc props: region: ${vars.region} service: name: gpu-best-practive-service internetAccess: true logConfig: enableRequestMetrics: true enableInstanceMetrics: true logBeginRule: DefaultRegex project: log-ca041e7c29f2a47eb8aec48f94b**** # 替換為您創建的日志服務項目名稱 logstore: config***** # 替換為您創建的日志庫名稱 role: acs:ram::143199913651****:role/aliyunfcdefaultrole function: name: gpu-porn-detection description: This is the demo function deployment handler: not-used timeout: 1200 caPort: 9000 memorySize: 8192 # 8 GB內存配置 cpu: 2 gpuMemorySize: 8192 # 8 GB顯存配置 diskSize: 512 instanceType: fc.gpu.tesla.1 # 部署Tesla卡型的GPU實例 instanceConcurrency: 1 runtime: custom-container environmentVariables: FCGPU_RUNTIME_SHMSIZE : '8589934592' customContainerConfig: image: registry.cn-shanghai.aliyuncs.com/serverless_devs/gpu-console-supervising:paddle-porn-detection # 此處以公共鏡像為例,您可以根據實際情況替換為您的鏡像名稱 accelerationType: Default triggers: - name: httpTrigger type: http config: authType: anonymous methods: - GET - POST執行以下命令,部署函數。
sudo s deploy --skip-push true -t s.yaml執行成功后,在執行輸出中返回一個URL地址,獲取此地址用于后續測試函數。
測試函數,并登錄函數計算控制臺查看監控結果。
執行Curl命令測試函數,使用上一步獲取的URL。
curl https://gpu-poretection-gpu-bes-service-gexsgx****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"返回以下結果,表示測試通過。
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%在函數計算控制臺,選擇,依次單擊步驟2部署的服務和函數,然后單擊實例指標頁簽,查看GPU相關指標的變化。
配置彈性預留策略。
創建彈性配置的模板provision.json。
示例如下。該模板使用了實例并發度作為追蹤指標,最小實例數為2,最大實例數為30。
{ "target": 2, "targetTrackingPolicies": [ { "name": "scaling-policy-demo", "startTime": "2023-01-01T16:00:00.000Z", "endTime": "2024-01-01T16:00:00.000Z", "metricType": "ProvisionedConcurrencyUtilization", "metricTarget": 0.3, "minCapacity": 2, "maxCapacity": 30 } ] }執行以下命令,進行彈性策略的部署。
sudo s provision put --config ./provision.json --qualifier LATEST -t s.yaml -a {access}執行
sudo s provision list進行驗證,可以看到如下輸出。其中target和current的數值相等,表示預留實例正確拉起,彈性規則部署正確。[2023-05-10 14:49:03] [INFO] [FC] - Getting list provision: gpu-best-practive-service gpu-best-practive: - serviceName: gpu-best-practive-service qualifier: LATEST functionName: gpu-porn-detection resource: 143199913651****#gpu-best-practive-service#LATEST#gpu-porn-detection target: 2 current: 2 scheduledActions: null targetTrackingPolicies: - name: scaling-policy-demo startTime: 2023-01-01T16:00:00.000Z endTime: 2024-01-01T16:00:00.000Z metricType: ProvisionedConcurrencyUtilization metricTarget: 0.3 minCapacity: 2 maxCapacity: 30 currentError: alwaysAllocateCPU: true在預留實例拉起成功后,您的模型已成功部署并準備好進行服務。
釋放函數預留實例。
執行以下命令關閉彈性規則,將預留實例配置為0。
sudo s provision put --target 0 --qualifier LATEST -t s.yaml -a {access}執行以下命令確認當前函數的彈性伸縮策略已被關閉。
s provision list -a {access}返回以下執行結果,表示彈性伸縮策略已成功關閉。
[2023-05-10 14:54:46] [INFO] [FC] - Getting list provision: gpu-best-practive-service End of method: provision
通過函數計算控制臺配置GPU實例的彈性伸縮策略
前提條件
已創建函數計算的服務和GPU函數。具體操作,請參見創建服務和創建GPU函數。
操作步驟
- 登錄函數計算控制臺,在左側導航欄,單擊服務及函數。
開啟目標服務的實例級別指標。具體操作,請參見配置實例級別指標。
開啟實例級別指標后,您可以在函數計算控制臺的函數可觀測頁面查看到函數調用所消耗的GPU相關資源。
單擊目標函數,然后單擊觸發器管理(URL)頁簽,獲取HTTP觸發器的URL用于后續測試函數。
測試函數,并登錄函數計算控制臺查看監控結果。
執行Curl命令測試函數,使用上一步獲取的URL。
curl https://gpu-poretection-gpu-bes-service-gexsgx****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"返回以下結果,表示測試通過。
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%在函數計算控制臺,選擇,依次單擊步驟2部署的服務和函數,然后單擊實例指標頁簽,查看GPU相關指標的變化。
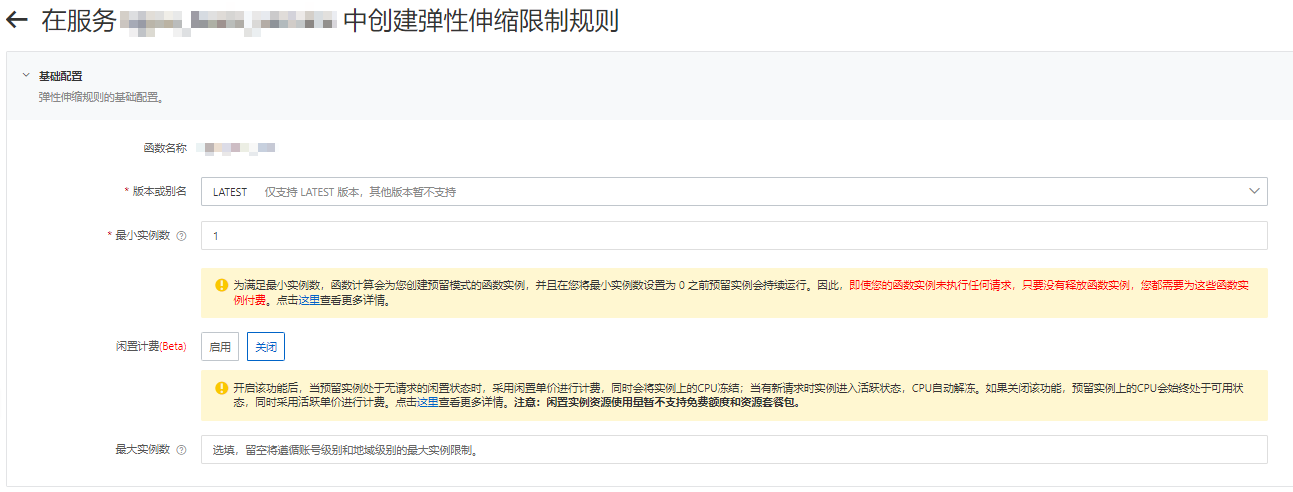
在函數詳情頁面的彈性管理頁簽,單擊創建規則。
在創建彈性伸縮限制規則頁面,按需設置以下配置項,然后單擊創建。
設置版本和最小實例數,其他配置項保持默認值即可。
在根據指標修改限制區域,單擊+添加配置,然后設置相關策略配置。
示例如下。

設置完成后,您可以在目標函數的,查看函數預留實例數的變化。
后續如果沒有使用預留模式GPU實例的需求,請及時刪除添加的預留實例。
執行壓測
您還可以使用常用的壓測工具對HTTP函數進行壓測,例如Apache Bench壓測工具。也可以使用阿里云的性能測試 PTS產品進行測試。使用PTS產品進行壓測,將產生額外費用,具體信息,請參見計費概述。
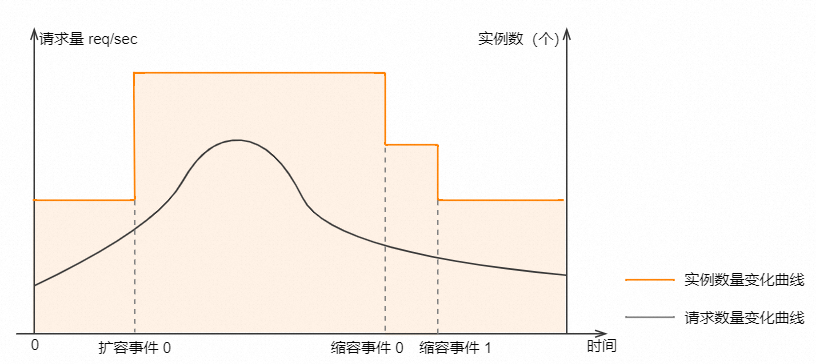
壓測結束后,在函數計算控制臺,找到目標服務下的目標函數,然后在函數詳情頁選擇,查看壓測結果。根據指標詳情,您可以看到在壓測過程中函數預留實例數進行了自動擴容,并在壓測結束后自動縮容,如下圖所示。
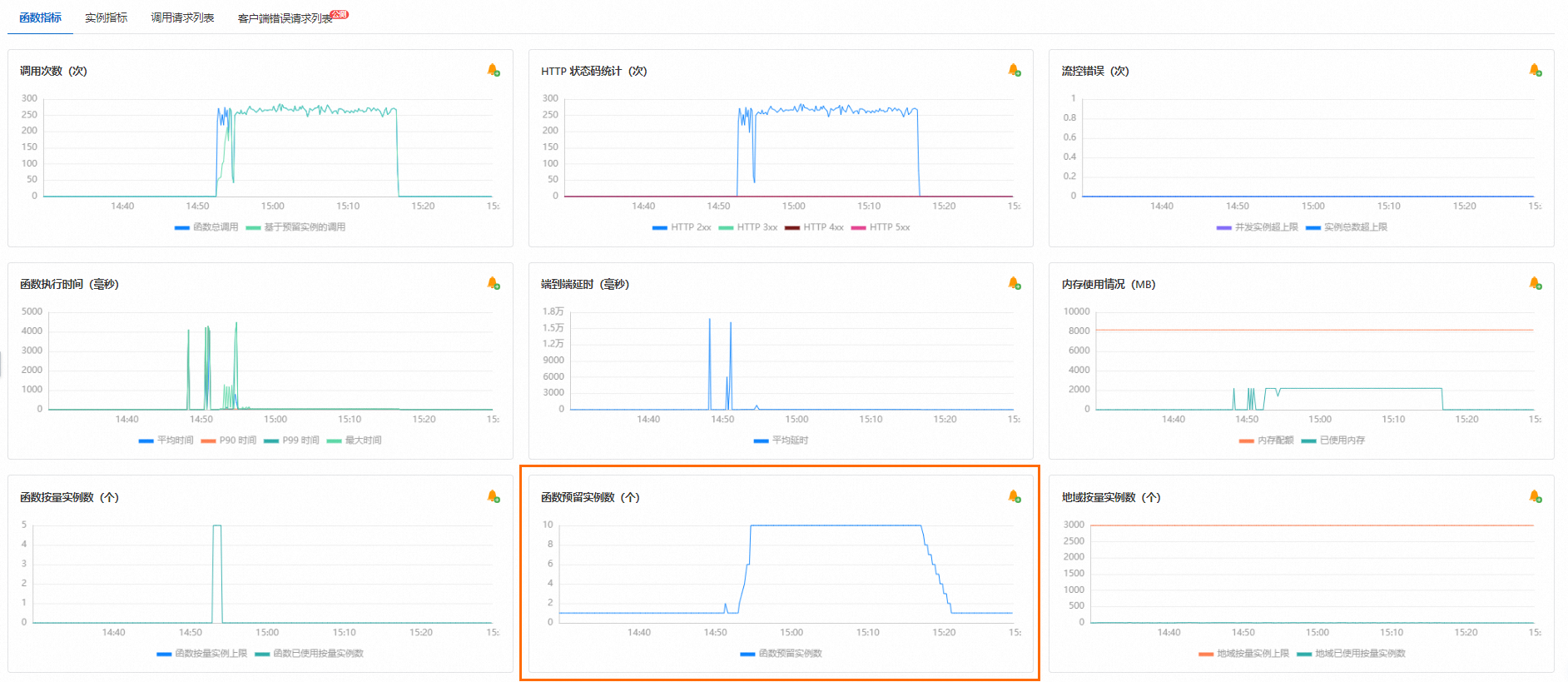
常見問題
使用函數計算實時推理場景的成本如何計算?
關于函數計算的計費詳情,請參見計費概述。預留模式區別于按量模式,請注意您的賬單詳情。
為什么我配置了彈性伸縮策略,還是可以看到性能毛刺?
可以考慮使用更為激進的彈性伸縮策略,提早彈出節點來規避突發請求帶來的性能擠兌。
為什么我所追蹤的指標已經上漲超過所配置的彈性策略水位,但是沒有看到實例數增長?
函數計算統計的指標是分鐘級別,水位需要上漲并維持一段時間后,才會觸發擴容機制。