本文為您介紹如何將Table/SQL JAR作業遷移至Flink全托管的SQL作業中。
背景信息
本文將使用開源JDBC Connector寫阿里云RDS的方式進行Table/SQL JAR遷移至SQL,因此需要額外配置附加依賴文件選項。實時計算Flink全托管版集群內置了商業化的RDS Connector,您也可以替換為開源JDBC Connector。商業化的RDS Connector詳情請參見云數據庫RDS MySQL結果表。
本文介紹的遷移場景如下圖所示。
前提條件
本地已安裝Maven 3.x。
已在Maven資源中心下載了開源JDBC Connector包,包括mysql-connector-java-8.0.27.jar和flink-connector-jdbc_2.11-1.13.0.jar。
重要依賴文件的版本需要與Flink集群的引擎版本保持一致。
已下載了代碼示例,下載的flink2vvp-main包中的文件說明如下:
Table/SQL類型:TableJobKafka2Rds.java
Datastream類型:DataStreamJobKafka2Rds.java
已構建自建集群測試作業并跑通。詳情請參見構建自建集群測試作業。
自建Flink遷移Flink全托管
在RDS控制臺創建新結果表rds_new_table1。
在左側已登錄實例下,鼠標左鍵雙擊test_db。
將以下創建表的命令復制到SQL執行窗口。
CREATE TABLE `rds_new_table1` ( `window_start` timestamp NOT NULL, `window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `order_type` varchar(8) NOT NULL, `order_number` bigint NULL, `order_value_sum` double NULL, PRIMARY KEY ( `window_start`, `window_end`, `order_type` ) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8;單擊執行(F8)。
新建Flink SQL作業。
在Flink開發控制臺上,新建Flink SQL流作業sql_kafka1rds,詳情請參見SQL作業開發。
在作業開發頁面,編寫DDL和DML代碼。
根據自建集群Table/SQL代碼對應的業務邏輯,編寫純SQL代碼,代碼示例如下。
CREATE TEMPORARY TABLE kafkatable ( order_id varchar, order_time timestamp (3), order_type varchar, order_value float, WATERMARK FOR order_time AS order_time - INTERVAL '2' SECOND ) WITH ( 'connector' = 'kafka', 'topic' = 'kafka-order', 'properties.bootstrap.servers' = '192.*.*.76:9092,192.*.*.75:9092,192.*.*.74:9092', 'properties.group.id' = 'demo-group_new1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' ); CREATE TEMPORARY TABLE rdstable ( window_start timestamp, window_end timestamp, order_type varchar, order_number bigint, order_value_sum double, PRIMARY KEY (window_start, window_end, order_type) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://rm-**********.mysql.rds.aliyuncs.com:3306/test_db', 'table-name' = 'rds_new_table1', 'driver' = 'com.mysql.jdbc.Driver', 'username' = 'flinK*****', 'password' = 'Test****' ); INSERT INTO rdstable SELECT TUMBLE_START (order_time, INTERVAL '5' MINUTE) as window_start, TUMBLE_END (order_time, INTERVAL '5' MINUTE) as window_end, order_type, COUNT (1) as order_number, SUM (order_value) as order_value_sum FROM kafkatable GROUP BY TUMBLE (order_time, INTERVAL '5' MINUTE), order_type;修改Kafka和RDS參數配置信息。
類別
參數
說明
Kafka
topic
Kafka Topic名稱。本示例Topic名稱為kafka-order。
properties.bootstrap.servers
Kafka Broker地址。
格式為
host:port,host:port,host:port,以英文逗號(,)分割。properties.group.id
Kafka消費組ID。本示例為消費者ID為demo-group_new1。
說明為了避免消費組ID沖突,您可以在Kafka控制臺上,創建新的消費組,并在此處使用新的Kafka消費組ID。
RDS
url
URL的格式為:
jdbc:mysql://<內網地址>/<databaseName>,其中<databaseName>為對應的數據庫名稱。云數據庫RDS版專有網絡VPC地址,即內網地址,詳情請?參見查看和管理實例連接地址和端口。
table-name
表名。本示例表名稱為test_db。
username
用戶名。
password
密碼。
請填寫為Kafka實例詳情的接入點信息中查看到的Kafka接入點信息。
(可選)在頁面右上角,單擊深度檢查,進行語法檢查。
在頁面右上角,單擊部署。
在頁面,單擊目標作業名稱。
修改Flink SQL配置。
在部署詳情頁簽基礎配置區域的附加依賴文件選項中,上傳已下載的mysql-connector-java-8.0.27.jar和flink-connector-jdbc_2.11-1.13.0.jar兩個JAR包。
在資源配置區域,配置作業的并發度。
本示例參考自建Flink集群作業運行命令,設置作業并發度為2。
單擊保存。
在頁面,單擊啟動。
如果作業的狀態變為運行中,則表示作業已正常運行。
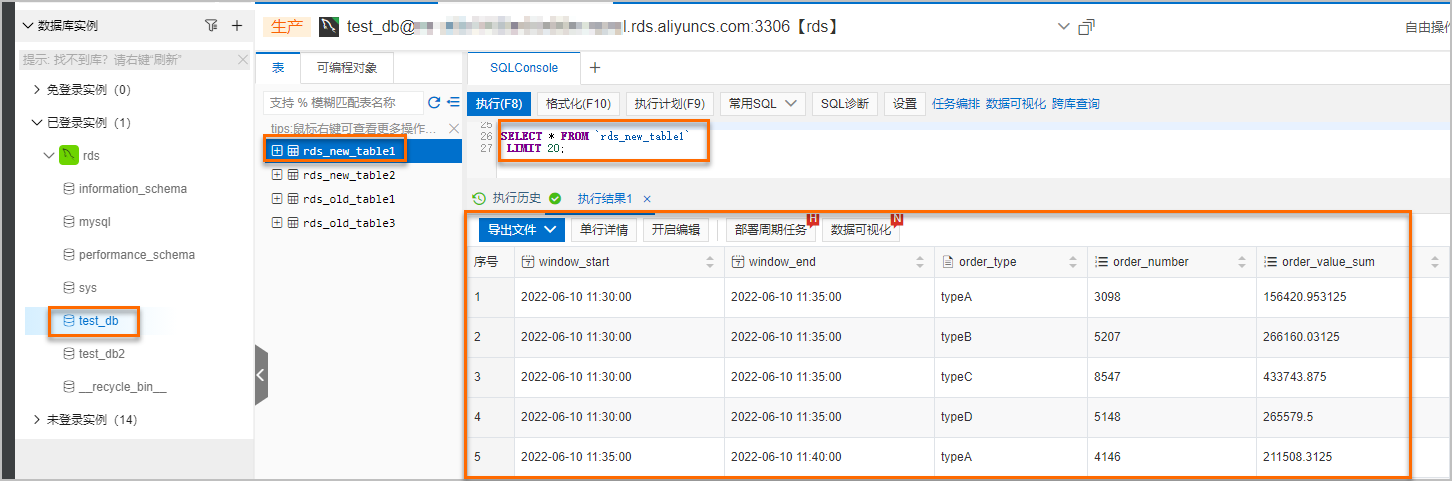
在RDS控制臺上,雙擊rds_new_table1表后,單擊執行(F8),查詢對應的計算結果。
 說明
說明如果上游Kafka有持續的流數據,則5分鐘后即可到RDS控制臺上查詢到對應的計算結果。
構建自建集群測試作業
本文使用EMR-Flink作為用戶自建Flink集群來運行遷移前的作業,以此來對比驗證自建Flink遷移后的作業運行結果。如果您已經有了自建Flink集群,可以忽略此步驟。
在RDS控制臺,創建自建集群的sink表rds_old_table1。
登錄RDS控制臺。
單擊登錄數據庫。
填寫實例信息。
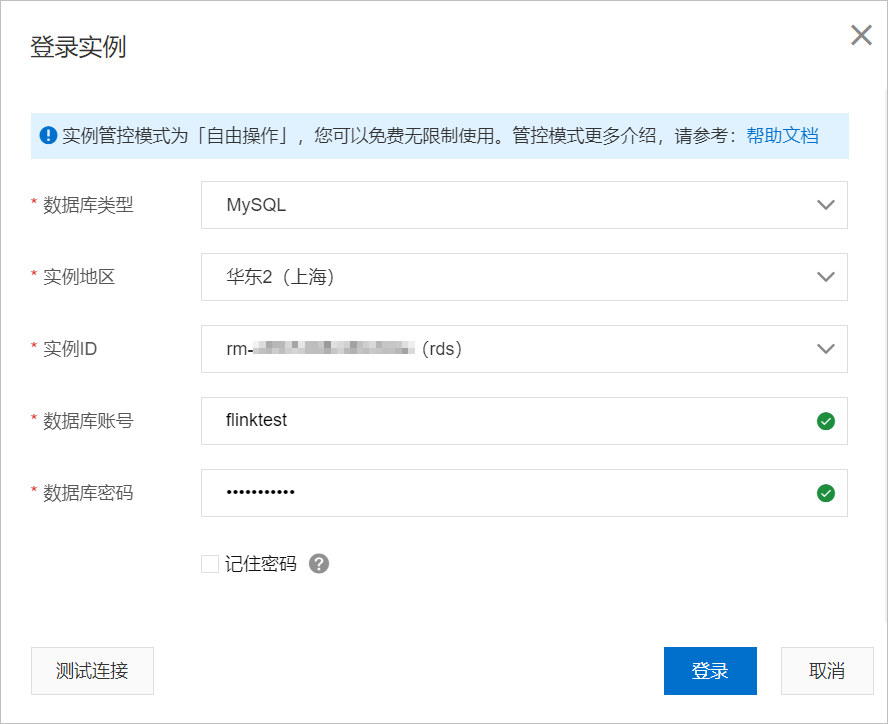
單擊登錄。
單擊復制IP網段。
將復制的IP網段添加到實例白名單中。
詳情請參見添加DMS IP地址。
鼠標左鍵雙擊test_db。
將以下創建表的命令復制到SQL執行窗口。
CREATE TABLE `rds_old_table1` ( `window_start` timestamp NOT NULL, `window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `order_type` varchar(8) NOT NULL, `order_number` bigint NULL, `order_value_sum` double NULL, PRIMARY KEY ( `window_start`, `window_end`, `order_type` ) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8;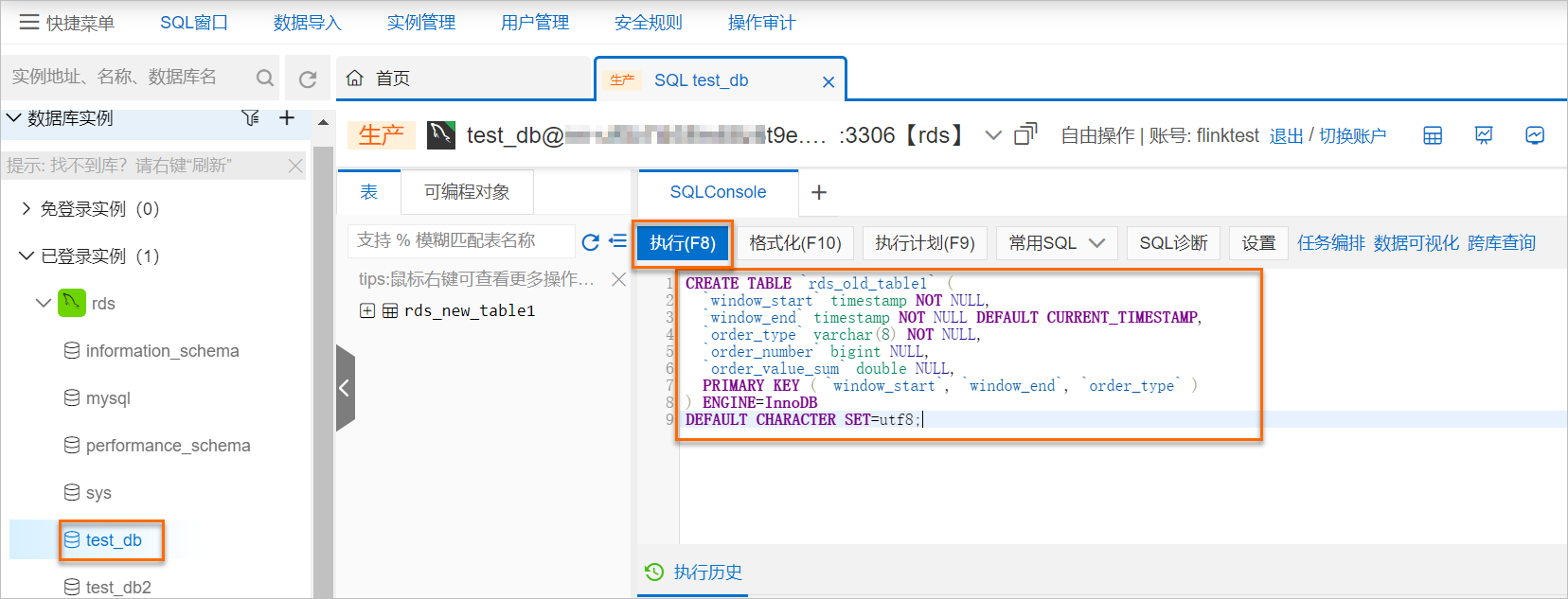
單擊執行(F8)。
在Maven中修改以下配置信息并構建新JAR。
在IntelliJ IDEA中,選擇,打開下載并解壓縮完成的flink2vvp-main包。
鼠標左鍵雙擊打開TableJobKafka2Rds。
修改Kafka和RDS的連接信息。
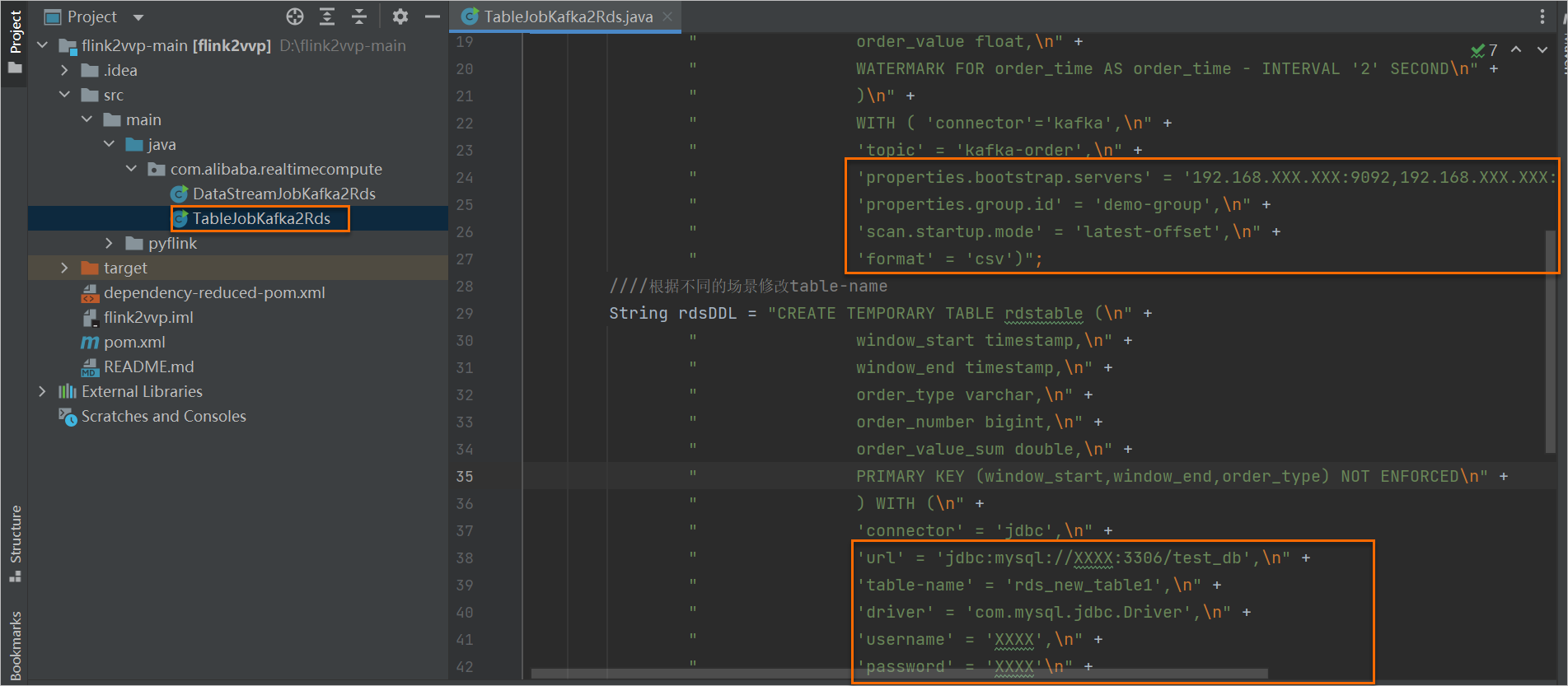
類別
參數
說明
Kafka
topic
Kafka Topic名稱。本示例Topic名稱為kafka-order。
properties.bootstrap.servers
Kafka Broker地址。
格式為
host:port,host:port,host:port,以英文逗號(,)分割。properties.group.id
Kafka消費組ID。
說明為了避免消費組ID沖突,您可以在Kafka控制臺上,創建新的消費組,并在此處使用新的Kafka消費組ID。
RDS
url
URL的格式為:
jdbc:mysql://<內網地址>/<databaseName>,其中<databaseName>為對應的數據庫名稱。云數據庫RDS版專有網絡VPC地址,即內網地址,詳情請?參見查看和管理實例連接地址和端口。
table-name
表名。本示例表名稱為rds_old_table1。
username
用戶名。
password
密碼。
在pom.xml文件中,添加以下兩部分依賴信息。
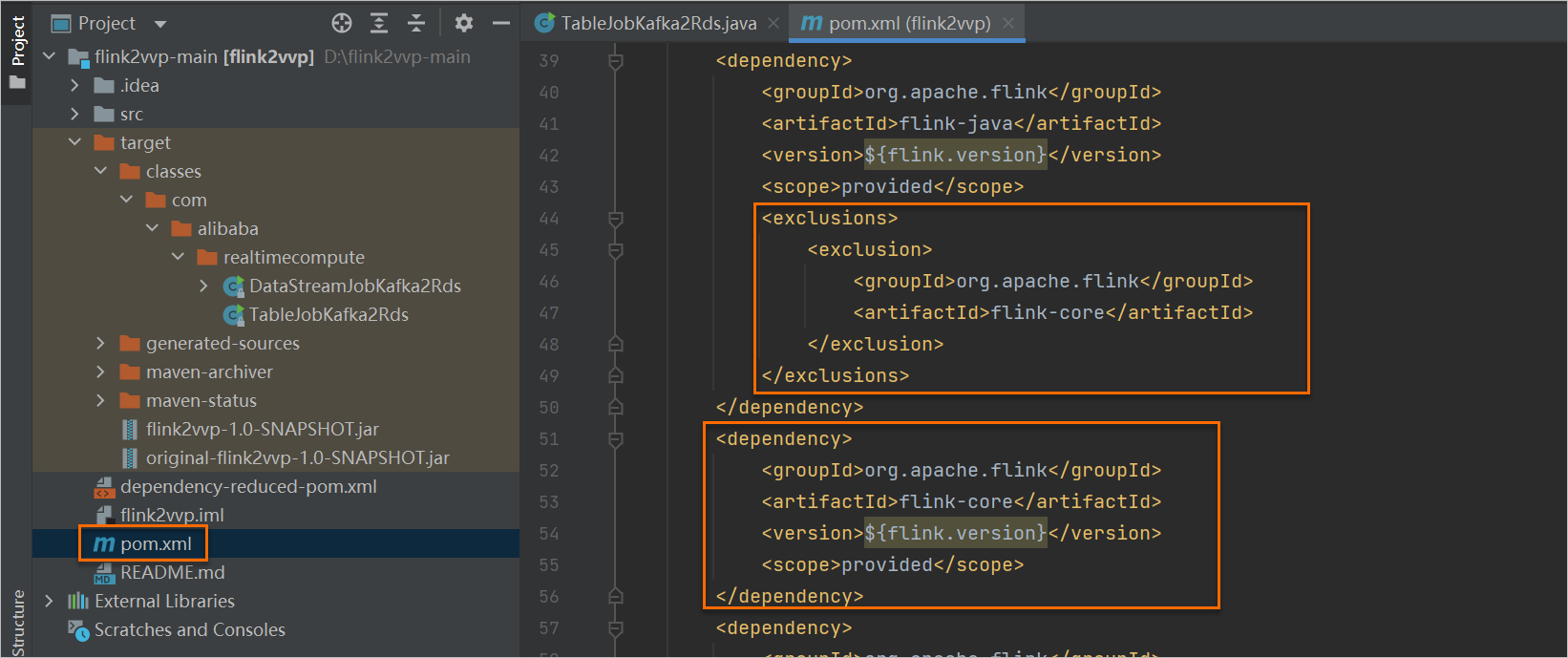
<exclusions> <exclusion> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> </exclusion> </exclusions><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency>
使用
mvn clean package命令構建JAR包。
構建成功后可以在target目錄下找到相應的JAR包。
拷貝新構建的JAR包到自建EMR-Flink集群。
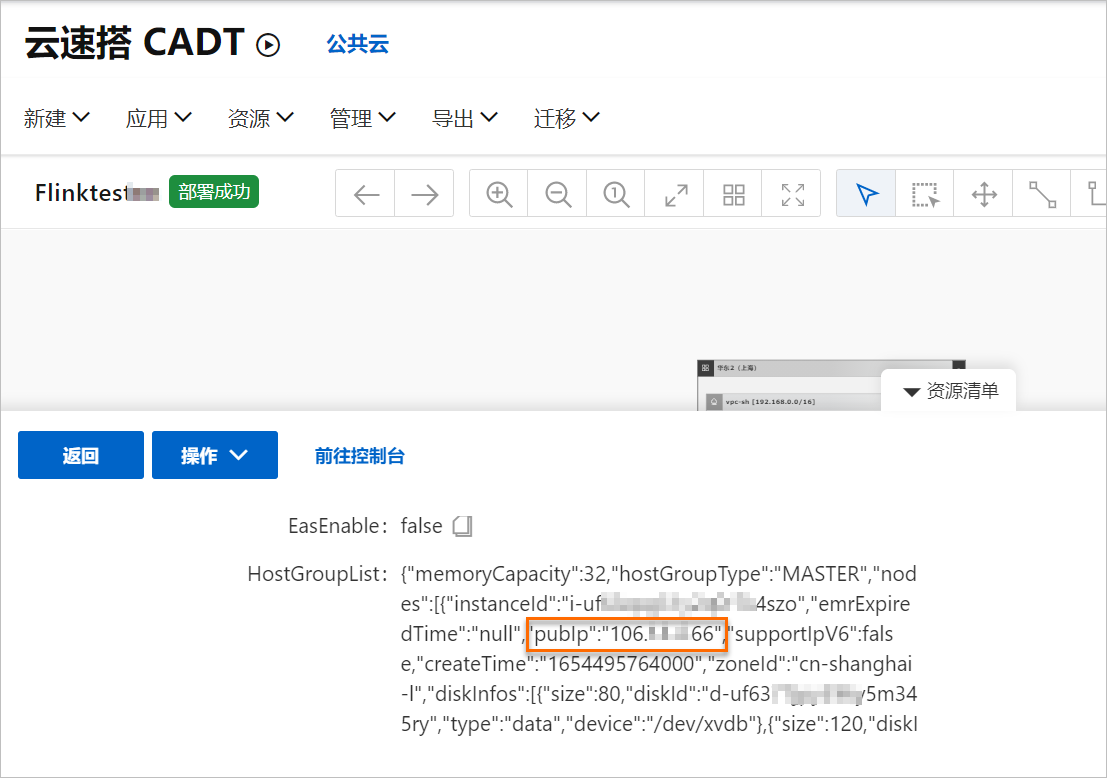
鼠標左鍵雙擊EMR-Flink圖標。
查看publp信息,即自建flink master ip。
使用以下命令拷貝構建的新JAR包到EMR-Flink集群。
scp {jar包路徑} root@{自建flink master ip}:/
上個步驟獲取的publp即為自建flink master ip。
連接EMR-Flink集群后,執行以下命令運行Flink作業。
連接方式詳情請參見ECS遠程連接方式概述。
cd / flink run -d -t yarn-per-job -p 2 -ynm 'tablejobkafka2rds' -yjm 1024m -ytm 2048m -yD yarn.appmaster.vcores=1 -yD yarn.containers.vcores=1 -yD state.checkpoints.dir=hdfs:///flink/flink-checkpoints -yD execution.checkpointing.interval="180s" -c com.alibaba.realtimecompute.TableJobKafka2Rds ./flink2vvp-1.0-SNAPSHOT.jar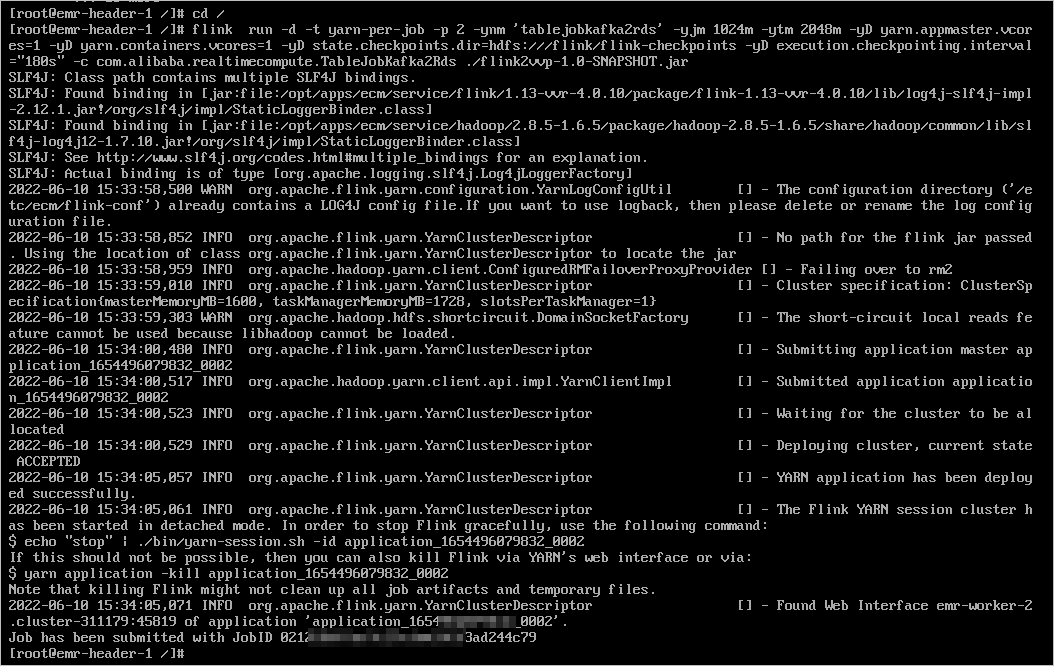
在DMS控制臺,查看寫入RDS的結果。
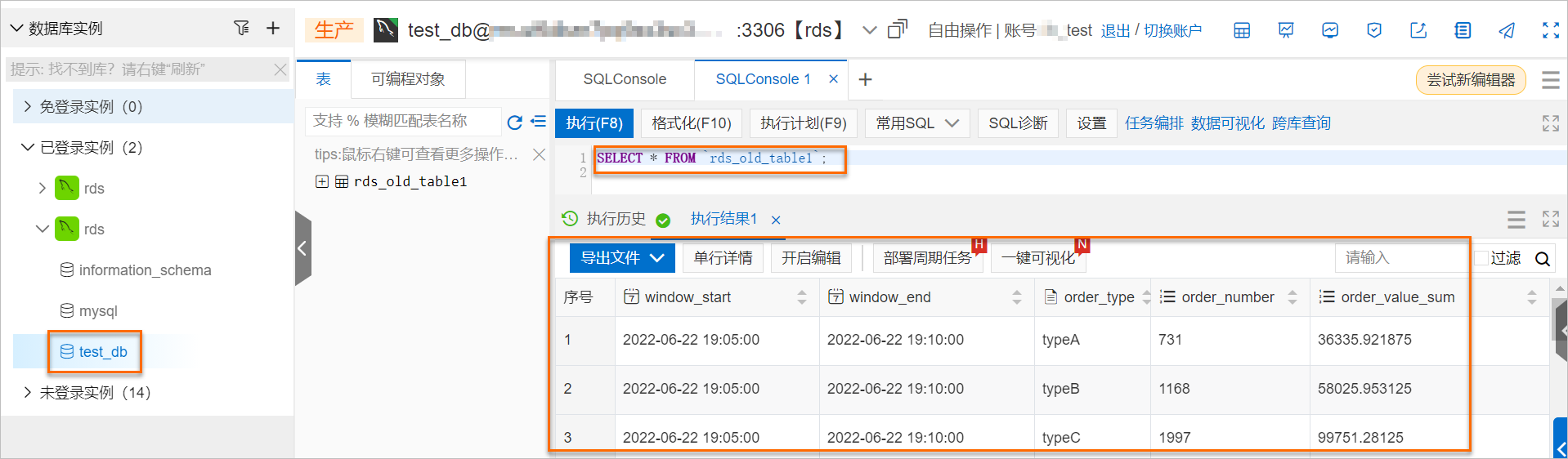
由上圖可見,自建Flink作業能正常消費Kafka數據并成功寫入RDS結果表。