消息隊(duì)列Kafka
本文為您介紹如何使用消息隊(duì)列Kafka連接器。
背景信息
Apache Kafka是一款開源的分布式消息隊(duì)列系統(tǒng),廣泛用于高性能數(shù)據(jù)處理、流式分析、數(shù)據(jù)集成等大數(shù)據(jù)領(lǐng)域。Kafka連接器基于開源Apache Kafka客戶端,為阿里云實(shí)時計算Flink提供高性能的數(shù)據(jù)吞吐、多種數(shù)據(jù)格式的讀寫和精確一次語義的支持。
類別 | 詳情 |
支持類型 | 源表和結(jié)果表,數(shù)據(jù)攝入目標(biāo)端 |
運(yùn)行模式 | 流模式 |
數(shù)據(jù)格式 |
說明
|
特有監(jiān)控指標(biāo) |
說明 指標(biāo)含義詳情,請參見監(jiān)控指標(biāo)說明。 |
API種類 | SQL,Datastream和數(shù)據(jù)攝入YAML |
是否支持更新或刪除結(jié)果表數(shù)據(jù) | 不支持更新和刪除結(jié)果表數(shù)據(jù),只支持插入數(shù)據(jù)。 說明 如果您需要更新和刪除結(jié)果表數(shù)據(jù),相關(guān)功能請參見Upsert Kafka。 |
前提條件
您可以根據(jù)需求選擇以下任意一種方式連接集群:
連接阿里云云消息隊(duì)列Kafka版集群
云消息隊(duì)列 Kafka 版集群已創(chuàng)建。詳情請參見創(chuàng)建資源。
Flink工作空間與Kafka集群處于同一VPC內(nèi),且云消息隊(duì)列 Kafka 版已對Flink開放白名單,具體操作請參見配置白名單。
重要寫入阿里云Kafka的限制:
阿里云Kafka不支持zstd壓縮格式寫入。
阿里云Kafka不支持冪等和事務(wù)寫入,無法使用Kafka結(jié)果表提供的精確一次語義exactly-once semantic功能。在使用實(shí)時計算引擎VVR 8.0.0及以上時,需要在結(jié)果表中添加配置項(xiàng)
properties.enable.idempotence=false以關(guān)閉冪等寫入功能。阿里云Kafka的存儲引擎對比與功能限制參見存儲引擎對比。
連接自建Apache Kafka集群
自建Apache Kafka集群版本在0.11及以上。
Flink與自建Apache Kafka集群之間的網(wǎng)絡(luò)已打通。如何通過公網(wǎng)連接自建集群,詳情請參見實(shí)時計算Flink版如何訪問公網(wǎng)?
僅支持Apache Kafka 2.8版本的客戶端配置項(xiàng),詳情請參見Apache Kafka消費(fèi)者和生產(chǎn)者配置項(xiàng)文檔。
使用限制
CREATE TABLE AS(CTAS)的使用限制
僅Flink計算引擎vvr-4.0.12-flink-1.13及以上版本支持Kafka作為CREATE TABLE AS(CTAS)的同步數(shù)據(jù)源。
僅支持JSON格式的類型推導(dǎo)和schema變更,其它數(shù)據(jù)格式暫不支持。
僅支持Kafka中value部分的類型推導(dǎo)和表結(jié)構(gòu)變更。如果您需要同步Kafka key部分的列,則需要您手動在DDL中進(jìn)行指定。詳情請參見示例三。
數(shù)據(jù)攝入YAML的使用限制
僅支持Debezium JSON和Canal JSON格式的類型推導(dǎo)和表結(jié)構(gòu)變更,其他數(shù)據(jù)格式暫不支持。
對于數(shù)據(jù)源,僅支持同一張表的數(shù)據(jù)在同一分區(qū),不支持單表數(shù)據(jù)分布在多個分區(qū)。
網(wǎng)絡(luò)連接排查
如果您的Flink作業(yè)在啟動時出現(xiàn)Timed out waiting for a node assignment錯誤,一般是Flink和Kafka之間的網(wǎng)絡(luò)連通問題導(dǎo)致的。
Kafka客戶端與服務(wù)端建立連接的過程如下所示。
客戶端使用您指定的properties.bootstrap.servers地址連接Kafka服務(wù)端,Kafka服務(wù)端根據(jù)配置向客戶端返回集群中各臺broker的元信息,包括各臺broker的連接地址。
客戶端使用第一步broker返回的連接地址連接各臺broker進(jìn)行讀取或?qū)懭搿?/p>
如果Kafka服務(wù)端沒有正確配置,客戶端在第一步收到的連接地址有誤,即使properties.bootstrap.servers配置的地址可以連接上,也無法正常讀取或?qū)懭霐?shù)據(jù)。該問題經(jīng)常在Flink與Kafka之間存在代理、端口轉(zhuǎn)發(fā)、專線等網(wǎng)絡(luò)轉(zhuǎn)發(fā)機(jī)制時發(fā)生。
您可以按照以下步驟檢查Kafka集群是否配置正確。
使用Zookeeper命令行工具(zkCli.sh或zookeeper-shell.sh)登錄到您Kafka所使用的Zookeeper集群。
根據(jù)您的集群實(shí)際情況執(zhí)行正確的命令,來獲取您的Kafka broker元信息。通常可以使用
get /brokers/ids/0命令來獲取Kafka broker元信息。Kafka broker的連接地址位于endpoints字段中,該地址即為上述連接過程中服務(wù)端向客戶端返回的連接地址,信息如下圖所示。
使用ping或telnet等命令來測試endpoint中顯示的地址與Flink的連通性。如果無法連通該地址,請聯(lián)系您的Kafka運(yùn)維修改Kafka配置,為Flink單獨(dú)配置listeners和advertised.listeners。
更多關(guān)于Kafka客戶端與服務(wù)端的連接信息,請參見Troubleshoot Connectivity。
SQL
Kafka連接器可以在SQL作業(yè)中使用,作為源表或者結(jié)果表。
語法結(jié)構(gòu)
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)元信息列
您可以在源表和結(jié)果表中定義元信息列,以獲取或?qū)懭隟afka消息的元信息。例如,當(dāng)WITH參數(shù)中定義了多個topic時,如果在Kafka源表中定義了元信息列,那么Flink讀取到的數(shù)據(jù)就會被標(biāo)識是從哪個topic中讀取的數(shù)據(jù)。元信息列的使用示例如下。
CREATE TABLE kafka_source (
--讀取消息所屬的topic作為`record_topic`字段
`record_topic` STRING NOT NULL METADATA FROM 'topic' VIRTUAL,
--讀取ConsumerRecord中的時間戳作為`ts`字段
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
--讀取消息的offset作為`record_offset`字段
`record_offset` BIGINT NOT NULL METADATA FROM 'offset' VIRTUAL,
...
) WITH (
'connector' = 'kafka',
...
);
CREATE TABLE kafka_sink (
--將`ts`字段中的時間戳作為ProducerRecord的時間戳寫入Kafka
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
...
) WITH (
'connector' = 'kafka',
...
);下表列出了Kafka源表和結(jié)果表所支持的元信息列。
Key | 數(shù)據(jù)類型 | 說明 | 源表或結(jié)果表 |
topic | STRING NOT NULL METADATA VIRTUAL | Kafka消息所在的Topic名稱。 | 源表 |
partition | INT NOT NULL METADATA VIRTUAL | Kafka消息所在的Partition ID。 | 源表 |
headers | MAP<STRING, BYTES> NOT NULL METADATA VIRTUAL | Kafka消息的消息頭(header)。 | 源表和結(jié)果表 |
leader-epoch | INT NOT NULL METADATA VIRTUAL | Kafka消息的Leader epoch。 | 源表 |
offset | BIGINT NOT NULL METADATA VIRTUAL | Kafka消息的偏移量(offset)。 | 源表 |
timestamp | TIMESTAMP(3) WITH LOCAL TIME ZONE NOT NULL METADATA VIRTUAL | Kafka消息的時間戳。 | 源表和結(jié)果表 |
timestamp-type | STRING NOT NULL METADATA VIRTUAL | Kafka消息的時間戳類型:
| 源表 |
WITH參數(shù)
通用
參數(shù)
說明
數(shù)據(jù)類型
是否必填
默認(rèn)值
備注
connector
表類型。
String
是
無
固定值為kafka。
properties.bootstrap.servers
Kafka broker地址。
String
是
無
格式為host:port,host:port,host:port,以英文逗號(,)分割。
properties.*
對Kafka客戶端的直接配置。
String
否
無
后綴名必須是Kafka官方文檔中定義的生產(chǎn)者和消費(fèi)者配置。
Flink會將properties.前綴移除,并將剩余的配置傳遞給Kafka客戶端。例如可以通過
'properties.allow.auto.create.topics'='false'來禁用自動創(chuàng)建topic。不能通過該方式修改以下配置,因?yàn)樗鼈儠籏afka連接器覆蓋:
key.deserializer
value.deserializer
format
讀取或?qū)懭隟afka消息value部分時使用的格式。
String
否
無
支持的格式
csv
json
avro
debezium-json
canal-json
maxwell-json
avro-confluent
raw
說明更多format參數(shù)設(shè)置請參見Format參數(shù)。
key.format
讀取或?qū)懭隟afka消息key部分時使用的格式。
String
否
無
支持的格式
csv
json
avro
debezium-json
canal-json
maxwell-json
avro-confluent
raw
說明使用該配置時,key.options配置是必填的。
key.fields
Kafka消息key部分對應(yīng)的源表或結(jié)果表字段。
String
否
無
多個字段名以分號(;)分隔。例如
field1;field2key.fields-prefix
為所有Kafka消息key部分指定自定義前綴,以避免與消息value部分格式字段重名。
String
否
無
該配置項(xiàng)僅用于源表和結(jié)果表的列名區(qū)分,解析和生成Kafka消息key部分時,該前綴會被移除。
說明使用該配置時,value.fields-include必須配置為EXCEPT_KEY。
value.format
讀取或?qū)懭隟afka消息value部分時使用的格式。
String
否
無
該配置等同于format,因此format和value.format 只能配置其中一個,如果同時配置兩個會產(chǎn)生沖突
value.fields-include
在解析或生成Kafka消息value部分時,是否要包含消息key部分對應(yīng)的字段。
String
否
ALL
參數(shù)取值如下:
ALL(默認(rèn)值):所有列都會作為Kafka消息value部分處理
EXCEPT_KEY:除去key.fields定義的字段,剩余字段作為Kafka消息value部分處理
源表
參數(shù)
說明
數(shù)據(jù)類型
是否必填
默認(rèn)值
備注
topic
讀取的topic名稱。
String
否
無
以英文分號 (;) 分隔多個topic名稱,例如topic-1和topic-2
說明topic和topic-pattern兩個選項(xiàng)只能指定其中一個。
topic-pattern
匹配讀取topic名稱的正則表達(dá)式。所有匹配該正則表達(dá)式的topic在作業(yè)運(yùn)行時均會被讀取。
String
否
無
說明僅VVR 3.0.0及以上版本支持該參數(shù)。
topic和topic-pattern兩個選項(xiàng)只能指定其中一個。
properties.group.id
消費(fèi)組ID。
String
否
KafkaSource-{源表表名}
如果指定的group id為首次使用,則必須將properties.auto.offset.reset設(shè)置為earliest或latest以指定首次啟動位點(diǎn)。
scan.startup.mode
Kafka讀取數(shù)據(jù)的啟動位點(diǎn)。
String
否
group-offsets
取值如下:
earliest-offset:從Kafka最早分區(qū)開始讀取。
latest-offset:從Kafka最新位點(diǎn)開始讀取。
group-offsets(默認(rèn)值):從指定的properties.group.id已提交的位點(diǎn)開始讀取。
timestamp:從scan.startup.timestamp-millis指定的時間戳開始讀取。
specific-offsets:從scan.startup.specific-offsets指定的偏移量開始讀取。
說明該參數(shù)在作業(yè)無狀態(tài)啟動時生效。作業(yè)在從checkpoint重啟或狀態(tài)恢復(fù)時,會優(yōu)先使用狀態(tài)中保存的進(jìn)度恢復(fù)讀取。
scan.startup.specific-offsets
specific-offsets啟動模式下,指定每個分區(qū)的啟動偏移量。
String
否
無
例如
partition:0,offset:42;partition:1,offset:300scan.startup.timestamp-millis
timestamp啟動模式下,指定啟動位點(diǎn)時間戳。
Long
否
無
單位為毫秒
scan.topic-partition-discovery.interval
動態(tài)檢測Kafka topic和partition的時間間隔。
Duration
否
5分鐘
分區(qū)檢查間隔默認(rèn)為5分鐘。需要顯式地設(shè)置分區(qū)檢查間隔為非正數(shù)才能關(guān)閉此功能。開啟動態(tài)分區(qū)發(fā)現(xiàn)后,Kafka Source 可以自動地發(fā)現(xiàn)新增的分區(qū)并自動讀取對應(yīng)分區(qū)上的數(shù)據(jù)。在topic-pattern模式下,不僅讀取已有topic的新增分區(qū)數(shù)據(jù),也會讀取符合正則匹配的新增topic的所有分區(qū)數(shù)據(jù)。
說明在實(shí)時計算引擎VVR 6.0.x版本中,動態(tài)分區(qū)檢測默認(rèn)為關(guān)閉。自8.0版本起該功能默認(rèn)打開,檢測間隔默認(rèn)設(shè)置為5分鐘。
scan.header-filter
根據(jù)Kafka數(shù)據(jù)是否包含指定的消息頭(Header)對數(shù)據(jù)進(jìn)行條件過濾。
String
否
無
Header key和value使用冒號(:)分隔,多個header條件之間使用邏輯運(yùn)算符(&、|)連接,支持取反邏輯運(yùn)算符(!)。例如
depart:toy|depart:book&!env:test表示保留header中包含depart=toy或depart=book,且不包含env=test的Kafka數(shù)據(jù)。說明僅實(shí)時計算引擎VVR 8.0.6及以上版本支持配置該參數(shù)。
暫不支持括號運(yùn)算。
邏輯運(yùn)算順序?yàn)閺淖笾劣摇?/p>
Header value會以UTF-8格式轉(zhuǎn)換為字符串,與參數(shù)指定的header value進(jìn)行比較。
scan.check.duplicated.group.id
是否檢查通過
properties.group.id指定的消費(fèi)者組有重復(fù)。Boolean
否
false
參數(shù)取值如下:
true:在啟動作業(yè)前檢查消費(fèi)者組是否有重復(fù),如有重復(fù)作業(yè)將會報錯,避免與現(xiàn)有的消費(fèi)者組產(chǎn)生沖突。
false:直接啟動作業(yè),不檢查消費(fèi)者組沖突。
說明僅VVR 6.0.4及以上版本支持該參數(shù)。
結(jié)果表
參數(shù)
說明
數(shù)據(jù)類型
是否必填
默認(rèn)值
備注
topic
寫入的topic名稱。
String
是
無
無
sink.partitioner
從Flink并發(fā)到Kafka分區(qū)的映射模式。
String
否
default
取值如下:
default(默認(rèn)值):使用Kafka默認(rèn)的分區(qū)模式
fixed:每個Flink并發(fā)對應(yīng)一個固定的Kafka分區(qū)。
round-robin:Flink并發(fā)中的數(shù)據(jù)將被輪流分配至Kafka的各個分區(qū)。
自定義分區(qū)映射模式:如果fixed和round-robin不滿足您的需求,您可以創(chuàng)建一個FlinkKafkaPartitioner的子類來自定義分區(qū)映射模式。例如org.mycompany.MyPartitioner
sink.delivery-guarantee
Kafka結(jié)果表的語義模式。
String
否
at-least-once
取值如下:
none:不保證任何語義,數(shù)據(jù)可能會丟失或重復(fù)。
at-least-once(默認(rèn)值):保證數(shù)據(jù)不丟失,但可能會重復(fù)。
exactly-once:使用Kafka事務(wù)保證數(shù)據(jù)不會丟失和重復(fù)。
說明在使用exactly-once語義時,sink.transactional-id-prefix是必填的。
sink.transactional-id-prefix
在exactly-once語義下使用的Kafka事務(wù)ID前綴。
String
否
無
只有sink.delivery-guarantee配置為exactly-once時該配置才會生效。
sink.parallelism
Kafka結(jié)果表算子的并發(fā)數(shù)。
Integer
否
無
上游算子的并發(fā),由框架決定。
CTAS同步數(shù)據(jù)源
參數(shù)
說明
數(shù)據(jù)類型
是否必填
默認(rèn)值
備注
json.infer-schema.flatten-nested-columns.enable
是否遞歸式地展開JSON中的嵌套列。
Boolean
否
false
參數(shù)取值如下:
true:遞歸式展開。對于被展開的列,F(xiàn)link使用索引該值的路徑作為名字。例如,對于
JSON {"nested": {"col": true}}中的列col,它展開后的名字為nested.col。false(默認(rèn)值):將嵌套類型當(dāng)作String處理。
json.infer-schema.primitive-as-string
是否推導(dǎo)所有基本類型為String類型。
Boolean
否
false
參數(shù)取值如下:
true:推導(dǎo)所有基本類型為String。
false:按照基本規(guī)則進(jìn)行推導(dǎo)。
所有Kafka consumer和producer支持的配置項(xiàng)均可在配置前添加
properties.前綴后在WITH參數(shù)中使用。例如需要配置Kafka consumer或producer的超時時間request.timeout.ms為60000毫秒,則可以在WITH參數(shù)中配置'properties.request.timeout.ms'='60000'。Kafka consumer和Kafka producer的配置項(xiàng)詳情請參見Apache Kafka官方文檔。
安全與認(rèn)證
如果您的Kafka集群要求安全連接或認(rèn)證,請將相關(guān)的安全與認(rèn)證配置添加properties.前綴后設(shè)置在WITH參數(shù)中。配置Kafka表以使用PLAIN作為SASL機(jī)制,并提供JAAS配置的示例如下。
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
...
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="username" password="password";'
)使用SASL_SSL作為安全協(xié)議,并使用SCRAM-SHA-256作為SASL機(jī)制的示例如下。
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
...
'properties.security.protocol' = 'SASL_SSL',
/*SSL配置*/
/*配置服務(wù)端提供的truststore (CA 證書) 的路徑*/
'properties.ssl.truststore.location' = '/flink/usrlib/kafka.client.truststore.jks',
'properties.ssl.truststore.password' = 'test1234',
/*如果要求客戶端認(rèn)證,則需要配置keystore (私鑰) 的路徑*/
'properties.ssl.keystore.location' = '/flink/usrlib/kafka.client.keystore.jks',
'properties.ssl.keystore.password' = 'test1234',
/*客戶端驗(yàn)證服務(wù)器地址的算法,空值表示禁用服務(wù)器地址驗(yàn)證*/
'properties.ssl.endpoint.identification.algorithm' = '',
/*SASL配置*/
/*將SASL機(jī)制配置為as SCRAM-SHA-256*/
'properties.sasl.mechanism' = 'SCRAM-SHA-256',
/*配置JAAS*/
'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'
)示例中提到的CA證書和私鑰可使用實(shí)時計算控制臺的資源上傳功能上傳至平臺,上傳后文件存放在/flink/usrlib目錄下。例如,需要使用的CA證書文件名為my-truststore.jks,則上傳后您可以在WITH參數(shù)中指定'properties.ssl.truststore.location' = '/flink/usrlib/my-truststore.jks'來使用該證書。
上文中的示例僅適用于大多數(shù)配置情況。在配置Kafka連接器前,請與您的Kafka服務(wù)端運(yùn)維人員聯(lián)系,以獲取正確的安全與認(rèn)證配置信息。
與開源Flink不同,實(shí)時計算Flink版的SQL編輯器默認(rèn)已經(jīng)對雙引號(")進(jìn)行轉(zhuǎn)義處理,因此您在配置
properties.sasl.jaas.config時無需對用戶名和密碼中的雙引號(")添加額外的轉(zhuǎn)義符(\)。
源表起始位點(diǎn)
啟動模式
Kafka源表可通過配置scan.startup.mode來指定初始讀取位點(diǎn):
最早位點(diǎn)(earliest-offset):從當(dāng)前分區(qū)的最早位點(diǎn)開始讀取。
最末尾位點(diǎn)(latest-offset):從當(dāng)前分區(qū)的最末尾位點(diǎn)開始讀取。
已提交位點(diǎn)(group-offsets):從指定group id的已提交位點(diǎn)開始讀取,group id通過properties.group.id指定。
指定時間戳(timestamp):從時間戳大于等于指定時間的第一條消息開始讀取,時間戳通過scan.startup.timestamp-millis指定。
特定位點(diǎn)(specific-offsets):從您指定的分區(qū)位點(diǎn)開始消費(fèi),位點(diǎn)通過scan.startup.specific-offsets指定。
如果您不指定啟動位點(diǎn),則默認(rèn)會從已提交位點(diǎn)(group-offsets)啟動消費(fèi)。
scan.startup.mode只針對無狀態(tài)啟動的作業(yè)生效,有狀態(tài)作業(yè)啟動時會從狀態(tài)中存儲的位點(diǎn)開始消費(fèi)。
代碼示例如下:
CREATE TEMPORARY TABLE kafka_source (
...
) WITH (
'connector' = 'kafka',
...
--從最早位點(diǎn)開始消費(fèi)
'scan.startup.mode' = 'earliest-offset',
--從最末尾位點(diǎn)開始消費(fèi)
'scan.startup.mode' = 'latest-offset',
--從消費(fèi)者組"my-group"的已提交位點(diǎn)開始消費(fèi)
'properties.group.id' = 'my-group',
'scan.startup.mode' = 'group-offsets',
'properties.auto.offset.reset' = 'earliest', -- 如果 "my-group" 為首次使用,則從最早位點(diǎn)開始消費(fèi)
'properties.auto.offset.reset' = 'latest', -- 如果 "my-group" 為首次使用,則從最末尾位點(diǎn)開始消費(fèi)
--從指定的毫秒時間戳1655395200000開始消費(fèi)
'scan.startup.mode' = 'timestamp',
'scan.startup.timestamp-millis' = '1655395200000',
--從指定位點(diǎn)開始消費(fèi)
'scan.startup.mode' = 'specific-offsets',
'scan.startup.specific-offsets' = 'partition:0,offset:42;partition:1,offset:300'
);起始位點(diǎn)優(yōu)先級
源表起始位點(diǎn)的優(yōu)先級為:
Checkpoint或Savepoint中存儲的位點(diǎn)。
您在實(shí)時計算控制臺指定的啟動時間。
您在WITH參數(shù)中通過scan.startup.mode指定的啟動位點(diǎn)。
未指定scan.startup.mode的情況下使用group-offsets。
在以上任何一個步驟中,如果位點(diǎn)過期或Kafka集群發(fā)生問題等原因?qū)е挛稽c(diǎn)無效,則會使用properties.auto.offset.reset指定的策略進(jìn)行位點(diǎn)重置,如果您未設(shè)置該配置項(xiàng),則會產(chǎn)生異常要求您介入。
一種常見情況是使用全新的group id開始消費(fèi)。首先源表會向Kafka集群查詢該group的已提交位點(diǎn),由于該group id是第一次使用,不會查詢到有效位點(diǎn),所以會通過properties.auto.offset.reset參數(shù)配置的策略進(jìn)行重置。因此在使用全新group id進(jìn)行消費(fèi)時,必須配置properties.auto.offset.reset來指定位點(diǎn)重置策略。
源表位點(diǎn)提交
Kafka源表只在checkpoint成功后將當(dāng)前消費(fèi)位點(diǎn)提交至Kafka集群。如果您的checkpoint間隔設(shè)置較長,您在Kafka集群側(cè)觀察到的消費(fèi)位點(diǎn)會有延遲。在進(jìn)行checkpoint時,Kafka源表會將當(dāng)前讀取進(jìn)度存儲在狀態(tài)中,并不依賴于提交到集群上的位點(diǎn)進(jìn)行故障恢復(fù),提交位點(diǎn)僅僅是為了在Kafka側(cè)能夠監(jiān)控到讀取進(jìn)度,位點(diǎn)提交失敗不會對數(shù)據(jù)正確性產(chǎn)生任何影響。
結(jié)果表自定義分區(qū)器
如果內(nèi)置的Kafka Producer分區(qū)模式無法滿足您的需求,您可以實(shí)現(xiàn)自定義分區(qū)模式將數(shù)據(jù)寫入對應(yīng)的分區(qū)。自定義分區(qū)器需要繼承FlinkKafkaPartitioner,開發(fā)完成后編譯JAR包,使用資源上傳功能上傳至實(shí)時計算控制臺。上傳并引用完成后,請在WITH參數(shù)中設(shè)置sink.partitioner參數(shù),參數(shù)值為分區(qū)器完整的類路徑,如org.mycompany.MyPartitioner。
Kafka、Upsert Kafka或Kafka JSON catalog的選擇
Kafka是一種只能添加數(shù)據(jù)的消息隊(duì)列系統(tǒng),無法進(jìn)行數(shù)據(jù)的更新和刪除操作,因此在流式SQL計算中無法處理上游的CDC變更數(shù)據(jù)和聚合、聯(lián)合等算子的回撤邏輯。如果您需要將含有變更或回撤類型的數(shù)據(jù)寫入Kafka,請使用對變更數(shù)據(jù)進(jìn)行特殊處理的Upsert Kafka結(jié)果表。
為了方便您將上游數(shù)據(jù)庫中一個或多個數(shù)據(jù)表中的變更數(shù)據(jù)批量同步到Kafka中,您可以使用Kafka JSON catalog。如果您的Kafka中存儲的數(shù)據(jù)格式為JSON,使用Kafka JSON catalog可以省去定義schema和WITH參數(shù)的步驟。詳情可參見管理Kafka JSON Catalog。
作為CTAS數(shù)據(jù)源
CTAS語句支持將消息隊(duì)列Kafka,且format為JSON的表作為數(shù)據(jù)源。在數(shù)據(jù)同步過程中,如果某些字段并未出現(xiàn)在預(yù)定義的表結(jié)構(gòu)中,F(xiàn)link會嘗試自動推導(dǎo)該列的類型。如果自動推導(dǎo)的類型不能滿足您的使用需求,您也可以通過輔助推導(dǎo)的方式對某些列的解析類型進(jìn)行聲明。
關(guān)于JSON Format的詳細(xì)描述,詳情請參見JSON Format。
類型推導(dǎo)
在類型推導(dǎo)過程中,F(xiàn)link默認(rèn)只展開JSON文本中的第一層數(shù)據(jù),根據(jù)其類型和數(shù)值,按照基本規(guī)則進(jìn)行類型推導(dǎo)。類型映射基本規(guī)則如下表所示。
JSON類型
Flink SQL類型
BOOLEAN
BOOLEAN
STRING
DATE、TIMESTAMP、TIMESTAMP_LTZ、TIME或 STRING
INT或LONG
BIGINT
BIGINT
DECIMAL或STRING
說明Flink中DECIMAL的類型存在精度限制。因此,如果整數(shù)的實(shí)際取值超過了DECIMAL類型最大精度,F(xiàn)link會自動推導(dǎo)其類型為STRING,避免精度的損失。
FLOAT、DOUBLE或BIG DECIMAL
DOUBLE
ARRAY
STRING
OBJECT
STRING
示例
JSON文本
{ "id": 101, "name": "VVP", "properties": { "owner": "阿里云", "engine": "Flink" } "type": ["大數(shù)據(jù)"] }Flink寫入到下游存儲的表信息為
id
name
properties
type
101
VVP
{ "owner": "阿里云", "engine": "Flink" }["大數(shù)據(jù)"]
輔助推導(dǎo)
當(dāng)基本規(guī)則不符合您的實(shí)際需要時,您可以在源表的DDL中聲明特定列的解析類型。通過該方式,F(xiàn)link會優(yōu)先使用您聲明的列類型去解析目標(biāo)字段。針對以下示例,F(xiàn)link會使用DECIMAL的方式去解析price字段,而不是使用默認(rèn)的基本規(guī)則將其轉(zhuǎn)換為DOUBLE類型。
CREATE TABLE evolvingKafkaSource ( price DECIMAL(18, 2) ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'localhost:9092', 'topic' = 'evolving_kafka_demo', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json' );但是,當(dāng)您在DDL中指定的類型和實(shí)際數(shù)據(jù)中的類型不一致時,可以按照以下方式進(jìn)行處理:
在聲明的類型比實(shí)際類型更寬泛時,以聲明的類型自動去解析。例如,聲明為DOUBLE,遇到的數(shù)據(jù)類型為BIGINT,則會以DOUBLE類型去解析。
在實(shí)際的類型比聲明的類型更為寬泛或者兩種類型不兼容時,由于當(dāng)前CTAS不支持類型變更,因此會報錯提示您相關(guān)信息,您需要重新啟動作業(yè)并聲明準(zhǔn)確的類型去解析數(shù)據(jù)。
類型的寬泛的程度以及兼容性如下圖所示。
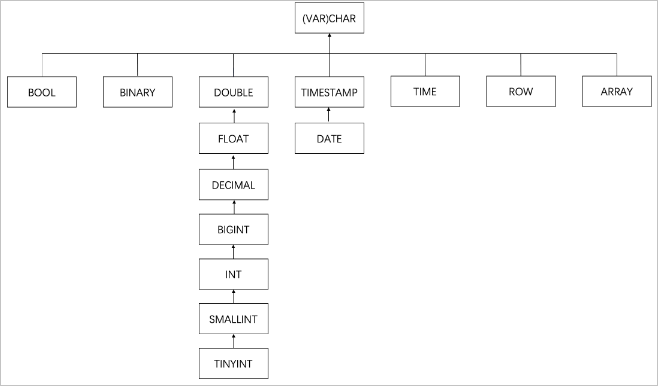 說明
說明上圖表示越靠近根節(jié)點(diǎn),其類型越寬泛。如果兩個類型在不同的分支上,則表示這兩個類型不兼容。
不支持輔助推導(dǎo)復(fù)雜類型,包括ROW、ARRAY、MAP和MULTISET。
對于復(fù)雜類型,F(xiàn)link在默認(rèn)情況下會處理為STRING。
通常,Kafka topic中的JSON文本帶有嵌套結(jié)構(gòu)。如果您需要提取JSON文本中的嵌套列,則可以通過以下兩種方式:
在源表DDL中聲明
'json.infer-schema.flatten-nested-columns.enable'='true',來展開嵌套列中的所有元素至頂層。通過該方式,所有的嵌套列都會被依次展開。為了避免列名沖突,F(xiàn)link采用索引到該列的路徑作為展開后列名字。重要目前不支持解決列名沖突。如果發(fā)生列名沖突,請在源表的DDL中聲明json.ignore-parse-errors為true,來忽略存在沖突的數(shù)據(jù)。
在DDL中CTAS語法中添加計算列
`rowkey` AS JSON_VALUE(`properties`, `$.rowkey`),來指定要展開的列。詳情請參見示例四:同步表結(jié)構(gòu)和數(shù)據(jù)并進(jìn)行計算。
使用示例
示例一:從Kafka中讀取數(shù)據(jù)后寫入Kafka
從名稱為源表的Topic中讀取Kafka數(shù)據(jù),再寫入名稱為結(jié)果表的Topic,數(shù)據(jù)使用CSV格式。
CREATE TEMPORARY TABLE kafka_source (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'kafka',
'topic' = 'source',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'properties.group.id' = '<yourKafkaConsumerGroupId>',
'format' = 'csv'
);
CREATE TEMPORARY TABLE kafka_sink (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'kafka',
'topic' = 'sink',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'properties.group.id' = '<yourKafkaConsumerGroupId>',
'format' = 'csv'
);
INSERT INTO kafka_sink SELECT id, name, age FROM kafka_source;示例二:同步表結(jié)構(gòu)以及數(shù)據(jù)
將Kafka Topic中的消息實(shí)時同步到Hologres中。在該情況下,您可以將Kafka消息的offset和partition id作為主鍵,從而保證在Failover時,Hologres中不會有重復(fù)消息。
CREATE TEMPORARY TABLE kafkaTable (
`offset` INT NOT NULL METADATA,
`part` BIGINT NOT NULL METADATA FROM 'partition',
PRIMARY KEY (`part`, `offset`) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'topic' = 'kafka_evolution_demo',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.infer-schema.flatten-nested-columns.enable' = 'true'
--可選,將嵌套列全部展開。
);
CREATE TABLE IF NOT EXISTS hologres.kafka.`sync_kafka`
WITH (
'connector' = 'hologres'
) AS TABLE vvp.`default`.kafkaTable;示例三:同步表結(jié)構(gòu)以及Kafka消息的key和value數(shù)據(jù)
Kafka消息中的key部分已經(jīng)存儲了相關(guān)信息,您可以同時同步Kafka中的key和value。
CREATE TEMPORARY TABLE kafkaTable (
`key_id` INT NOT NULL,
`val_name` VARCHAR(200)
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'topic' = 'kafka_evolution_demo',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'json',
'value.format' = 'json',
'key.fields' = 'key_id',
'key.fields-prefix' = 'key_',
'value.fields-prefix' = 'val_',
'value.fields-include' = 'EXCEPT_KEY'
);
CREATE TABLE IF NOT EXISTS hologres.kafka.`sync_kafka`(
WITH (
'connector' = 'hologres'
) AS TABLE vvp.`default`.kafkaTable;Kafka消息中的key部分不支持表結(jié)構(gòu)變更和類型推導(dǎo),需要您手動聲明。
示例四:同步表結(jié)構(gòu)和數(shù)據(jù)并進(jìn)行計算
在同步Kafka數(shù)據(jù)到Hologres時,往往需要一些輕量級的計算。
CREATE TEMPORARY TABLE kafkaTable (
`distinct_id` INT NOT NULL,
`properties` STRING,
`timestamp` TIMESTAMP_LTZ METADATA,
`date` AS CAST(`timestamp` AS DATE)
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'topic' = 'kafka_evolution_demo',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'json',
'value.format' = 'json',
'key.fields' = 'key_id',
'key.fields-prefix' = 'key_'
);
CREATE TABLE IF NOT EXISTS hologres.kafka.`sync_kafka` WITH (
'connector' = 'hologres'
) AS TABLE vvp.`default`.kafkaTable
ADD COLUMN
`order_id` AS COALESCE(JSON_VALUE(`properties`, '$.order_id'), 'default');
--使用COALESCE處理空值情況。Datastream API
通過DataStream的方式讀寫數(shù)據(jù)時,則需要使用對應(yīng)的DataStream連接器連接實(shí)時計算Flink版,DataStream連接器設(shè)置方法請參見DataStream連接器使用方法。
構(gòu)建Kafka Source
Kafka Source提供了構(gòu)建類來創(chuàng)建Kafka Source的實(shí)例。我們將通過以下示例代碼為您介紹如何構(gòu)建Kafka Source來消費(fèi)input-topic最早位點(diǎn)的數(shù)據(jù),消費(fèi)組名稱為my-group,并將Kafka消息體反序列化為字符串。
Java
KafkaSource<String> source = KafkaSource.<String>builder() .setBootstrapServers(brokers) .setTopics("input-topic") .setGroupId("my-group") .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");XML
Maven中央庫中已經(jīng)放置了Kafka DataStream連接器。
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>ververica-connector-kafka</artifactId> <version>${vvr-version}</version> </dependency>在構(gòu)建KafkaSource時,必須指定以下參數(shù)。
參數(shù)
說明
BootstrapServers
Kafka Broker地址,通過setBootstrapServers(String)方法配置。
GroupId
消費(fèi)者組ID,通過setGroupId(String)方法配置。
Topics或Partition
訂閱的Topic或Partition名稱。Kafka Source提供了以下三種Topic或Partition的訂閱方式:
Topic列表,訂閱Topic列表中所有Partition。
KafkaSource.builder().setTopics("topic-a","topic-b")正則表達(dá)式匹配,訂閱與正則表達(dá)式所匹配的Topic下的所有Partition。
KafkaSource.builder().setTopicPattern("topic.*")Partition列表,訂閱指定的Partition。
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList( new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a" new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b" KafkaSource.builder().setPartitions(partitionSet)
Deserializer
解析Kafka消息的反序列化器。
反序列化器通過setDeserializer(KafkaRecordDeserializationSchema)來指定,其中KafkaRecordDeserializationSchema定義了如何解析Kafka的ConsumerRecord。如果只解析Kafka消息中的消息體(Value)的數(shù)據(jù),則您可以通過以下任何一種方式實(shí)現(xiàn):
使用Flink提供的KafkaSource構(gòu)建類中的setValueOnlyDeserializer(DeserializationSchema)方法,其中DeserializationSchema定義了如何解析Kafka消息體中的二進(jìn)制數(shù)據(jù)。
使用Kafka提供的解析器,包括多種實(shí)現(xiàn)類。例如,您可以使用StringDeserializer來將Kafka消息體解析成字符串。
import org.apache.kafka.common.serialization.StringDeserializer; KafkaSource.<String>builder() .setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
說明如果需要完整地解析ConsumerRecord,則需要您自己實(shí)現(xiàn)KafkaRecordDeserializationSchema接口。
在使用Kafka DataStream連接器時,您還需要了解以下Kafka屬性:
起始消費(fèi)位點(diǎn)
Kafka Source能夠通過位點(diǎn)初始化器(OffsetsInitializer)來指定從不同的偏移量開始消費(fèi)。內(nèi)置的位點(diǎn)初始化器包括以下內(nèi)容。
位點(diǎn)初始化器
代碼設(shè)置
從最早位點(diǎn)開始消費(fèi)。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.earliest())從最末尾位點(diǎn)開始消費(fèi)。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.latest())從時間戳大于等于指定時間的數(shù)據(jù)開始消費(fèi),單位為毫秒。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.timestamp(1592323200000L))從消費(fèi)組提交的位點(diǎn)開始消費(fèi),如果提交位點(diǎn)不存在,使用最早位點(diǎn)。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))從消費(fèi)組提交的位點(diǎn)開始消費(fèi),不指定位點(diǎn)重置策略。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.committedOffsets())說明如果以上內(nèi)置的初始化器不能滿足需求,您也可以自己實(shí)現(xiàn)自定義的位點(diǎn)初始化器。
如果您未指定位點(diǎn)初始化器,則默認(rèn)使用OffsetsInitializer.earliest(),即最早位點(diǎn)。
流模式和批模式
Kafka Source支持流式和批式兩種運(yùn)行模式。默認(rèn)情況下,Kafka Source設(shè)置為以流模式運(yùn)行,因此作業(yè)永遠(yuǎn)不會停止,直到Flink作業(yè)失敗或被取消。如果要配置Kafka Source在批模式下運(yùn)行,您可以使用setBounded(OffsetsInitializer)指定停止偏移量,當(dāng)所有分區(qū)都達(dá)到其停止偏移量時,Kafka Source會退出運(yùn)行。
說明通常,流模式下Kafka Source沒有停止偏移量。為了方便對代碼進(jìn)行調(diào)試,流模式下您也可以使用 setUnbounded(OffsetsInitializer) 指定停止偏移量。請留意指定流模式和批模式停止偏移量的方法名(setUnbounded 和 setBounded)是不同的。
動態(tài)分區(qū)檢查
為了在不重啟Flink作業(yè)的情況下,處理Topic擴(kuò)容或新建Topic等場景,您可以在提供的Topic或Partition訂閱模式下,啟用動態(tài)分區(qū)檢查功能。
說明默認(rèn)開啟動態(tài)分區(qū)檢查功能,分區(qū)檢查間隔默認(rèn)為5分鐘。需要顯式地設(shè)置分區(qū)檢查間隔為非正數(shù)才能關(guān)閉此功能。代碼示例如下。
KafkaSource.builder() .setProperty("partition.discovery.interval.ms", "10000") // 每10秒檢查一次新分區(qū)。事件時間和水印
Kafka Source默認(rèn)使用Kafka消息中的時間戳作為事件時間。您可以自定義水印策略(Watermark Strategy)以從消息中提取事件時間,并向下游發(fā)送水印。
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy")如果您需要了解自定義水印策略(Watermark Strategy),請參見Generating Watermarks。
消費(fèi)位點(diǎn)提交
Kafka Source在Checkpoint完成時,提交當(dāng)前的消費(fèi)位點(diǎn),以保證Flink的Checkpoint狀態(tài)和Kafka Broker上的提交位點(diǎn)一致。如果未開啟Checkpoint,Kafka Source依賴于Kafka Consumer內(nèi)部的位點(diǎn)定時自動提交邏輯,自動提交功能由enable.auto.commit和 auto.commit.interval.ms兩個Kafka Consumer配置項(xiàng)進(jìn)行配置。
說明Kafka Source不依賴于Broker上提交的位點(diǎn)來恢復(fù)失敗的作業(yè)。提交位點(diǎn)只是為了上報Kafka Consumer和消費(fèi)組的消費(fèi)進(jìn)度,以在Broker端進(jìn)行監(jiān)控。
其他屬性
除了上述屬性之外,您還可以使用setProperties(Properties) 和setProperty(String, String) 為Kafka Source和Kafka Consumer設(shè)置任意屬性。KafkaSource通常有以下配置項(xiàng)。
配置項(xiàng)
說明
client.id.prefix
指定用于Kafka Consumer的客戶端ID前綴。
partition.discovery.interval.ms
定義Kafka Source檢查新分區(qū)的時間間隔。
說明partition.discovery.interval.ms會在批模式下被覆蓋為-1。
register.consumer.metrics
指定是否在Flink中注冊Kafka Consumer的指標(biāo)。
其他Kafka Consumer配置
Kafka Consumer的配置詳情,請參見Apache Kafka。
重要Kafka Connector會強(qiáng)制覆蓋部分您手動配置的參數(shù)項(xiàng),覆蓋詳情如下:
key.deserializer始終被覆蓋為ByteArrayDeserializer。
value.deserializer始終被覆蓋為ByteArrayDeserializer。
auto.offset.reset.strategy被覆蓋為OffsetsInitializer#getAutoOffsetResetStrategy()。
以下示例為您展示如何配置Kafka Consumer,以使用PLAIN作為SASL機(jī)制并提供JAAS配置。
KafkaSource.builder() .setProperty("sasl.mechanism", "PLAIN") .setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";")監(jiān)控
Kafka Source在Flink中注冊指標(biāo),用于監(jiān)控和診斷。
指標(biāo)范圍
Kafka source reader的所有指標(biāo)都注冊在KafkaSourceReader指標(biāo)組下,KafkaSourceReader是operator指標(biāo)組的子組。與特定主題分區(qū)相關(guān)的指標(biāo)注冊在KafkaSourceReader.topic.<topic_name>.partition.<partition_id>指標(biāo)組中。
例如Topic "my-topic"、分區(qū)1的當(dāng)前消費(fèi)位點(diǎn)(currentOffset)注冊在<some_parent_groups>.operator.KafkaSourceReader.topic.my-topic.partition.1.currentOffset。成功提交位點(diǎn)的次數(shù)(commitsSucceeded)注冊在<some_parent_groups>.operator.KafkaSourceReader.commitsSucceeded。
指標(biāo)列表
指標(biāo)名稱
描述
范圍
currentOffset
當(dāng)前消費(fèi)位點(diǎn)
TopicPartition
committedOffset
當(dāng)前提交位點(diǎn)
TopicPartition
commitsSucceeded
成功提交的次數(shù)
KafkaSourceReader
commitsFailed
失敗的提交次數(shù)
KafkaSourceReader
Kafka Consumer指標(biāo)
Kafka Consumer的指標(biāo)注冊在指標(biāo)組KafkaSourceReader.KafkaConsumer。例如Kafka Consumer指標(biāo)records-consumed-total注冊在<some_parent_groups>.operator.KafkaSourceReader.KafkaConsumer.records-consumed-total。
您可以使用配置項(xiàng)register.consumer.metrics配置是否注冊Kafka消費(fèi)者的指標(biāo)。默認(rèn)此選項(xiàng)設(shè)置為true。對于Kafka Consumer的指標(biāo),您可以參見Apache Kafka。
構(gòu)建Kafka Sink
Flink Kafka Sink可以實(shí)現(xiàn)將流數(shù)據(jù)寫入一個或多個Kafka Topic。
DataStream<String> stream = ... Properties properties = new Properties(); properties.setProperty("bootstrap.servers", ); KafkaSink<String> kafkaSink = KafkaSink.<String>builder() .setKafkaProducerConfig(kafkaProperties) // // producer config .setRecordSerializer( KafkaRecordSerializationSchema.builder() .setTopic("my-topic") // target topic .setKafkaValueSerializer(StringSerializer.class) // serialization schema .build()) .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // fault-tolerance .build(); stream.sinkTo(kafkaSink);您需要配置以下參數(shù)。
參數(shù)
說明
Topic
數(shù)據(jù)寫入的默認(rèn)Topic名稱。
數(shù)據(jù)序列化
構(gòu)建時需要提供
KafkaRecordSerializationSchema來將輸入數(shù)據(jù)轉(zhuǎn)換為 Kafka 的ProducerRecord。Flink 提供了 schema 構(gòu)建器 以提供一些通用的組件,例如消息鍵(key)/消息體(value)序列化、topic 選擇、消息分區(qū),同樣也可以通過實(shí)現(xiàn)對應(yīng)的接口來進(jìn)行更豐富的控制。ProducerRecord<byte[], byte[]> serialize(T element, KafkaSinkContext context, Long timestamp)方法會在每條數(shù)據(jù)流入的時候調(diào)用,來生成ProducerRecord寫入Kafka。用戶可以對每條數(shù)據(jù)如何寫入Kafka進(jìn)行細(xì)粒度地控制。通過ProducerRecord可以進(jìn)行以下操作:
設(shè)置寫入的Topic名稱。
定義消息鍵(Key)。
指定數(shù)據(jù)寫入的Partition。
Kafka客戶端屬性
bootstrap.servers必填,以逗號分隔的Kafka Broker列表。
容錯語義
啟用Flink的Checkpoint后,F(xiàn)link Kafka Sink可以保證精確一次的語義。除了啟用Flink的Checkpoint外,您還可以通過DeliveryGuarantee參數(shù)來指定不同的容錯語義,DeliveryGuarantee參數(shù)詳情如下:
DeliveryGuarantee.NONE:(默認(rèn)設(shè)置)Flink不做任何保證,數(shù)據(jù)可能會丟失或重復(fù)。
DeliveryGuarantee.AT_LEAST_ONCE:保證不會丟失任何數(shù)據(jù),但可能會重復(fù)。
DeliveryGuarantee.EXACTLY_ONCE:使用Kafka事務(wù)提供精確一次的語義保證。
說明使用EXACTLY_ONCE語義時,需要注意的事項(xiàng)請參見EXACTLY_ONCE語義注意事項(xiàng)。
數(shù)據(jù)攝入
Kafka連接器可以用于數(shù)據(jù)攝入YAML作業(yè)開發(fā),作為源端讀取或目標(biāo)端寫入。
語法結(jié)構(gòu)
source:
type: kafka
name: Kafka source
properties.bootstrap.servers: localhost:9092
topic: ${kafka.topic}sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: localhost:9092配置項(xiàng)
通用
參數(shù)
說明
是否必填
數(shù)據(jù)類型
默認(rèn)值
備注
type
源端或目標(biāo)端類型。
是
String
無
固定值為kafka
name
源端或目標(biāo)端名稱。
否
String
無
無
properties.bootstrap.servers
Kafka broker地址。
是
String
無
格式為
host:port,host:port,host:port,以英文逗號(,)分割。properties.*
對Kafka客戶端的直接配置。
否
String
無
后綴名必須是Kafka官方文檔中定義的生產(chǎn)者和消費(fèi)者配置。
Flink會將properties.前綴移除,并將剩余的配置傳遞給Kafka客戶端。例如可以通過
'properties.allow.auto.create.topics' = 'false'來禁用自動創(chuàng)建topic。value.format
讀取或?qū)懭隟afka消息value部分時使用的格式。
否
String
debezium-json
取值如下:
debezium-json
canal-json
重要作為數(shù)據(jù)源時,需要保證同一張表數(shù)據(jù)在同一分區(qū)中。不支持單表數(shù)據(jù)分布在多個分區(qū)。
源表
參數(shù)
說明
是否必填
數(shù)據(jù)類型
默認(rèn)值
備注
topic
讀取的topic名稱。
否
String
無
以英文分號 (;) 分隔多個topic名稱,例如topic-1和topic-2
說明topic和topic-pattern兩個選項(xiàng)只能指定其中一個。
topic-pattern
匹配讀取topic名稱的正則表達(dá)式。所有匹配該正則表達(dá)式的topic在作業(yè)運(yùn)行時均會被讀取。
否
String
無
說明topic和topic-pattern兩個選項(xiàng)只能指定其中一個。
properties.group.id
消費(fèi)組ID。
否
String
無
如果指定的group id為首次使用,則必須將properties.auto.offset.reset設(shè)置為earliest或latest以指定首次啟動位點(diǎn)。
scan.startup.mode
Kafka讀取數(shù)據(jù)的啟動位點(diǎn)。
否
String
group-offsets
取值如下:
earliest-offset:從Kafka最早分區(qū)開始讀取。
latest-offset:從Kafka最新位點(diǎn)開始讀取。
group-offsets(默認(rèn)值):從指定的properties.group.id已提交的位點(diǎn)開始讀取。
timestamp:從scan.startup.timestamp-millis指定的時間戳開始讀取。
specific-offsets:從scan.startup.specific-offsets指定的偏移量開始讀取。
說明該參數(shù)在作業(yè)無狀態(tài)啟動時生效。作業(yè)在從checkpoint重啟或狀態(tài)恢復(fù)時,會優(yōu)先使用狀態(tài)中保存的進(jìn)度恢復(fù)讀取。
scan.startup.specific-offsets
specific-offsets啟動模式下,指定每個分區(qū)的啟動偏移量。
否
String
無
例如
partition:0,offset:42;partition:1,offset:300scan.startup.timestamp-millis
timestamp啟動模式下,指定啟動位點(diǎn)時間戳。
否
Long
無
單位為毫秒
scan.topic-partition-discovery.interval
動態(tài)檢測Kafka topic和partition的時間間隔。
否
Duration
5分鐘
分區(qū)檢查間隔默認(rèn)為5分鐘。需要顯式地設(shè)置分區(qū)檢查間隔為非正數(shù)才能關(guān)閉此功能。開啟動態(tài)分區(qū)發(fā)現(xiàn)后,Kafka Source 可以自動地發(fā)現(xiàn)新增的分區(qū)并自動讀取對應(yīng)分區(qū)上的數(shù)據(jù)。在topic-pattern模式下,不僅讀取已有topic的新增分區(qū)數(shù)據(jù),也會讀取符合正則匹配的新增topic的所有分區(qū)數(shù)據(jù)。
scan.check.duplicated.group.id
是否檢查通過
properties.group.id指定的消費(fèi)者組有重復(fù)。否
Boolean
false
參數(shù)取值如下:
true:在啟動作業(yè)前檢查消費(fèi)者組是否有重復(fù),如有重復(fù)作業(yè)將會報錯,避免與現(xiàn)有的消費(fèi)者組產(chǎn)生沖突。
false:直接啟動作業(yè),不檢查消費(fèi)者組沖突。
scan.max.pre.fetch.records
解析消息時,對每個分區(qū)最多嘗試消費(fèi)的消息數(shù)量
否
Int
50
在每個分區(qū)開始讀取數(shù)據(jù)前,提前消費(fèi)一定數(shù)量的消息用于初始化表結(jié)構(gòu)信息。
源表 Debezium JSON
參數(shù)
是否必填
數(shù)據(jù)類型
默認(rèn)值
描述
debezium-json.schema-include
否
Boolean
false
設(shè)置Debezium Kafka Connect時,可以啟用Kafka配置value.converter.schemas.enable,以在消息中包含schema。此選項(xiàng)表明Debezium JSON消息是否包含schema。
參數(shù)取值如下:
true:Debezium JSON消息包含schema。
false:Debezium JSON消息不包含schema。
debezium-json.ignore-parse-errors
否
Boolean
false
參數(shù)取值如下:
true:當(dāng)解析異常時,跳過當(dāng)前行。
false(默認(rèn)值):報出錯誤,作業(yè)啟動失敗。
debezium-json.infer-schema.primitive-as-string
否
Boolean
false
解析表結(jié)構(gòu)時,是否推導(dǎo)所有類型為String類型。
參數(shù)取值如下:
true:推導(dǎo)所有基本類型為String。
false(默認(rèn)值):按照基本規(guī)則進(jìn)行推導(dǎo)。
源表 Canal JSON
參數(shù)
是否必填
數(shù)據(jù)類型
默認(rèn)值
描述
canal-json.database.include
否
String
無
一個可選的正則表達(dá)式,通過正則匹配Canal記錄中的database元字段,僅讀取指定數(shù)據(jù)庫的changelog記錄。正則字符串與Java的Pattern兼容。
canal-json.table.include
否
String
無
一個可選的正則表達(dá)式,通過正則匹配Canal記錄中的table元字段,僅讀取指定表的changelog記錄。正則字符串與Java的Pattern兼容。
canal-json.ignore-parse-errors
否
Boolean
false
參數(shù)取值如下:
true:當(dāng)解析異常時,跳過當(dāng)前行。
false(默認(rèn)值):報出錯誤,作業(yè)啟動失敗。
canal-json.infer-schema.primitive-as-string
否
Boolean
false
解析表結(jié)構(gòu)時,是否推導(dǎo)所有類型為String類型。
參數(shù)取值如下:
true:推導(dǎo)所有基本類型為String。
false(默認(rèn)值):按照基本規(guī)則進(jìn)行推導(dǎo)。
結(jié)果表
參數(shù)
說明
是否必填
數(shù)據(jù)類型
默認(rèn)值
備注
type
目標(biāo)端類型。
是
String
無
固定值為kafka
name
目標(biāo)端名稱。
否
String
無
無
key.format
寫入Kafka消息key部分時使用的格式。
否
String
無
取值如下:
csv
json
topic
Kafka Topic名稱。
否
String
無
開啟時,所有的數(shù)據(jù)都會寫入這個Topic。
說明如果沒有開啟,每條數(shù)據(jù)會寫入到其TableID對應(yīng)字符串(通過
.拼接生成)的Topic,例如databaseName.tableName。partition.strategy
數(shù)據(jù)寫入Kafka分區(qū)的策略。
否
String
all-to-zero
取值如下:
all-to-zero(默認(rèn)值):將所有數(shù)據(jù)寫入 0 號分區(qū)。
hash-by-key:根據(jù)主鍵的哈希值將數(shù)據(jù)寫到多個分區(qū)。保證同一個主鍵的數(shù)據(jù)在同一個分區(qū)并且有序。
使用示例
使用 Kafka 作為數(shù)據(jù)攝入源端:
source: type: kafka name: Kafka source properties.bootstrap.servers: ${kafka.bootstraps.server} topic: ${kafka.topic} value.format: ${value.format} scan.startup.mode: ${scan.startup.mode} sink: type: hologres name: Hologres sink endpoint: <yourEndpoint> dbname: <yourDbname> username: ${secret_values.ak_id} password: ${secret_values.ak_secret} sink.type-normalize-strategy: BROADEN使用 Kafka 作為數(shù)據(jù)攝入目標(biāo)端:
source: type: mysql name: MySQL Source hostname: ${secret_values.mysql.hostname} port: ${mysql.port} username: ${secret_values.mysql.username} password: ${secret_values.mysql.password} tables: ${mysql.source.table} server-id: 8601-8604 sink: type: kafka name: Kafka Sink properties.bootstrap.servers: ${kafka.bootstraps.server} route: - source-table: ${mysql.source.table} sink-table: ${kafka.topic}其中,使用route模塊以設(shè)置源表寫入Kafka的Topic名稱。
阿里云Kafka默認(rèn)不開啟自動創(chuàng)建Topic功能,參見自動化創(chuàng)建Topic相關(guān)問題,寫入到阿里云Kafka時,需要預(yù)先創(chuàng)建對應(yīng)的Topic,詳情請參見步驟三:創(chuàng)建資源。
表結(jié)構(gòu)推導(dǎo)和變更同步策略
分區(qū)消息預(yù)消費(fèi)和表結(jié)構(gòu)初始化
Kafka連接器會維護(hù)當(dāng)前已知的所有表的Schema。在讀取Kafka中Debezium JSON或Canal JSON格式的數(shù)據(jù)前,Kafka連接器會預(yù)先在每個分區(qū)中嘗試消費(fèi)最多scan.max.pre.fetch.records條消息,解析每條數(shù)據(jù)的Schema,再將這些Schema合并,用于初始化表結(jié)構(gòu)信息。后續(xù)在實(shí)際消費(fèi)數(shù)據(jù)前會根據(jù)初始化的Schema產(chǎn)生對應(yīng)的建表事件。
說明對于Debezium JSON和Canal JSON格式,表信息在具體消息中,提前消費(fèi)的scan.max.pre.fetch.records條消息中可能包含了若干個表的數(shù)據(jù),因此對每張表而言,提前消費(fèi)的數(shù)據(jù)條數(shù)無法確定。預(yù)消費(fèi)和初始化表結(jié)構(gòu)信息只會在實(shí)際消費(fèi)和處理每個分區(qū)的消息前進(jìn)行一次,若后續(xù)有新表數(shù)據(jù),該表的第一條數(shù)據(jù)解析出的表結(jié)構(gòu)會作為初始表結(jié)構(gòu),不會重新預(yù)消費(fèi)和初始化對應(yīng)的表結(jié)構(gòu)。
重要目前僅支持同一張表數(shù)據(jù)在同一分區(qū),不支持單表數(shù)據(jù)分布在多個分區(qū)。
主鍵信息
對于Canal JSON格式,會根據(jù)JSON中的pkNames字段定義表的主鍵。
對于Debezium JSON格式,JSON中不包含主鍵信息,可以通過transform規(guī)則手動為表添加主鍵:
transform: - source-table: \.*.\.* projection: \* primary-keys: key1, key2
Schema推導(dǎo)和Schema變更
在表結(jié)構(gòu)初始化完成后,Kafka連接器會解析每個Kafka消息的消息體(Value),推導(dǎo)出消息的物理列,并與當(dāng)前維護(hù)的Schema比對,若推導(dǎo)出的Schema與當(dāng)前Schema不一致時,會嘗試將Schema合并,同時生成對應(yīng)的表結(jié)構(gòu)變更事件,合并規(guī)則如下:
如果推導(dǎo)出的物理列中包含當(dāng)前Schema中沒有的字段,則會將這些字段加入到Schema中,同時產(chǎn)生新增可空列事件。
如果推導(dǎo)出的物理列中不包含當(dāng)前Schema中已有的字段,該字段仍會保留,該列的數(shù)據(jù)會填充為NULL,不產(chǎn)生刪除列事件。
如果兩者出現(xiàn)了同名列,則按照以下場景進(jìn)行處理:
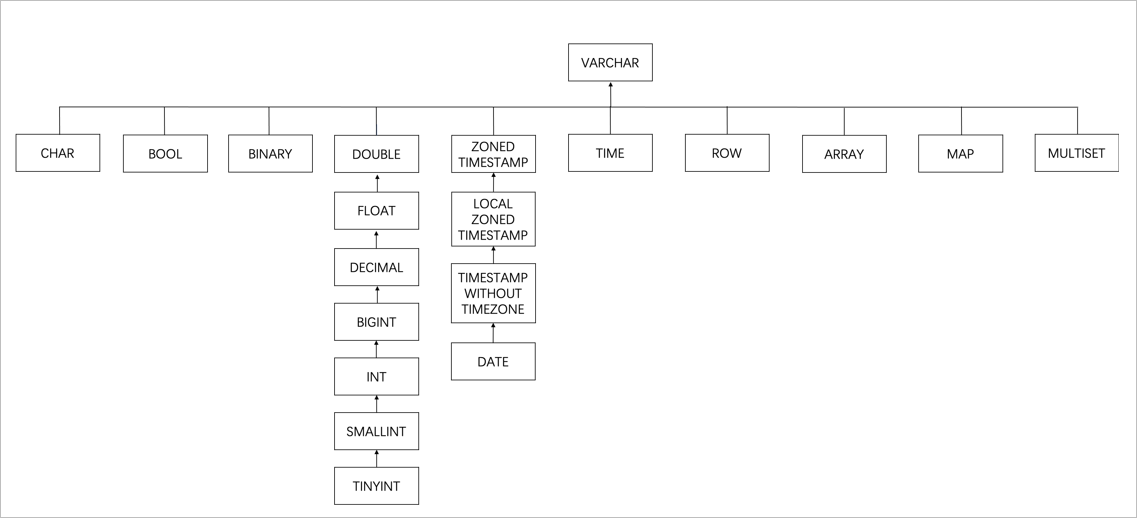
當(dāng)類型相同且精度不同時,會取兩者中較大精度的類型,同時產(chǎn)生列類型變更事件。
當(dāng)類型不同時,會按照如下圖的樹形結(jié)構(gòu)找到最小父節(jié)點(diǎn),作為該同名列的類型,同時產(chǎn)生列類型變更事件。
當(dāng)前支持的Schema變更策略如下:
添加列:會在當(dāng)前Schema末尾添加對應(yīng)的列,并同步新增列的數(shù)據(jù),新增的列會設(shè)置為可空列。
刪除列:不會產(chǎn)生刪除列事件,而是后續(xù)將該列的數(shù)據(jù)自動填充為NULL值。
重命名列:被看作為添加列和刪除列,在當(dāng)前Schema末尾添加重命名后的列,并將重命名前的列數(shù)據(jù)填充為NULL值。
列類型變更:
對于支持列類型變更的下游系統(tǒng),在下游Sink支持處理列類型變更后,數(shù)據(jù)攝入作業(yè)支持普通列的類型變更,例如,從INT類型變更到BIGINT類型。此類變更依賴于下游Sink支持的列類型變更規(guī)則,不同的結(jié)果表支持的列類型變更規(guī)則也不相同,請參考結(jié)果表文檔獲取其支持的列類型變更規(guī)則。
對于不支持列類型變更的下游系統(tǒng),比如Hologres,此類場景可以使用寬類型映射,即作業(yè)啟動時在下游系統(tǒng)建立類型更加寬泛的表,在列類型變更發(fā)生時判斷該類型變更下游Sink是否可以接受從而實(shí)現(xiàn)寬容的列類型變更支持。
當(dāng)前暫不支持的Schema變更:
主鍵或索引等約束的變更。
從NOT NULL轉(zhuǎn)為NULLABLE變更。
EXACTLY_ONCE語義注意事項(xiàng)
當(dāng)使用事務(wù)寫入Kafka時,請為所有消費(fèi)Kafka數(shù)據(jù)的應(yīng)用配置isolation.level參數(shù)。該參數(shù)取值如下:
read_committed:只讀取已提交的數(shù)據(jù)。
read_uncommitted(默認(rèn)值):可以讀取未提交的數(shù)據(jù)。
DeliveryGuarantee.EXACTLY_ONCE模式依賴于在從某個Checkpoint恢復(fù)后,且在該Checkpoint開始之前所提交的事務(wù)。如果Flink作業(yè)崩潰與完成重啟之間的時間大于Kafka的事務(wù)超時時間,則會有數(shù)據(jù)丟失,因?yàn)镵afka會自動中止超過超時時間的事務(wù)。因此,請根據(jù)您的預(yù)期停機(jī)時間適當(dāng)?shù)嘏渲媚氖聞?wù)超時。
Kafka Broker默認(rèn)的transaction.max.timeout.ms設(shè)置為15分鐘,Producer設(shè)置的事務(wù)超時不能超過Broker指定的時間。Flink Kafka Sink默認(rèn)會將Kafka Producer配置中的transaction.timeout.ms屬性設(shè)置為1小時,因此在使用DeliveryGuarantee.EXACTLY_ONCE模式前,需要增加Broker端的transaction.max.timeout.ms值。
DeliveryGuarantee.EXACTLY_ONCE模式為在Flink Kafka Producer實(shí)例中使用一個固定大小的Kafka Producer池。每個Checkpoint會使用池中的一個Kafka Producer。如果并發(fā)的Checkpoint數(shù)量超過Producer池的大小,F(xiàn)link Kafka Producer會拋出異常并使整個作業(yè)失敗。請相應(yīng)地配置Producer池大小和最大并發(fā)的Checkpoint數(shù)量。
DeliveryGuarantee.EXACTLY_ONCE會盡可能清除阻止Consumer從Kafka topic中讀取數(shù)據(jù)的殘留事務(wù)。但如果Flink作業(yè)在第一個 Checkpoint之前就出現(xiàn)故障,則在重啟該作業(yè)后并不會保留重啟前Producer池的信息。因此,在第一個Checkpoint完成之前縮減Flink作業(yè)的并行度是不安全的,即使要縮減并行度,也不能小于FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR。
對于在read_committed模式下運(yùn)行的Kafka Consumer,任何未結(jié)束(既未中止也未完成)的事務(wù)都將阻塞對該Kafka Topic的所有讀取。如果您按照以下步驟進(jìn)行了操作:
用戶開啟事務(wù)1并通過該事務(wù)寫入了一些數(shù)據(jù)。
用戶開啟事務(wù)2并通過該事務(wù)寫入了更多的數(shù)據(jù)。
用戶提交事務(wù)2。
即使來自事務(wù)2的數(shù)據(jù)已經(jīng)提交,在事務(wù)1提交或中止之前,事務(wù)2的數(shù)據(jù)對消費(fèi)者是不可見的。因此:
在Flink作業(yè)正常工作期間,您可以預(yù)期寫入Kafka topic的數(shù)據(jù)會有延遲,約為Checkpoint的平均間隔。
在Flink作業(yè)失敗的情況下,該作業(yè)正在寫入的Topic將會阻塞Consumer的讀取,直到作業(yè)重新啟動或事務(wù)超時。