當您需要將Azure Event Hubs事件中心中的數據同步到阿里云Elasticsearch中時,可使用阿里云Logstash的管道配置功能實現。本文介紹具體的實現方法。
操作流程
步驟一:準備環境與實例
步驟二:創建并配置Logstash管道
- 單擊下一步,配置管道參數。
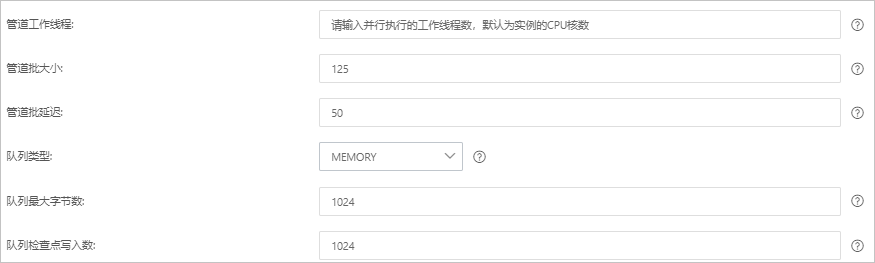
參數 說明 管道工作線程 并行執行管道的Filter和Output的工作線程數量。當事件出現積壓或CPU未飽和時,請考慮增大線程數,更好地使用CPU處理能力。默認值:實例的CPU核數。 管道批大小 單個工作線程在嘗試執行Filter和Output前,可以從Input收集的最大事件數目。較大的管道批大小可能會帶來較大的內存開銷。您可以設置LS_HEAP_SIZE變量,來增大JVM堆大小,從而有效使用該值。默認值:125。 管道批延遲 創建管道事件批時,將過小的批分派給管道工作線程之前,要等候每個事件的時長,單位為毫秒。默認值:50ms。 隊列類型 用于事件緩沖的內部排隊模型。可選值: - MEMORY:默認值。基于內存的傳統隊列。
- PERSISTED:基于磁盤的ACKed隊列(持久隊列)。
隊列最大字節數 請確保該值小于您的磁盤總容量。默認值:1024 MB。 隊列檢查點寫入數 啟用持久性隊列時,在強制執行檢查點之前已寫入事件的最大數目。設置為0,表示無限制。默認值:1024。 警告 配置完成后,需要保存并部署才能生效。保存并部署操作會觸發實例重啟,請在不影響業務的前提下,繼續執行以下步驟。
步驟三:驗證結果
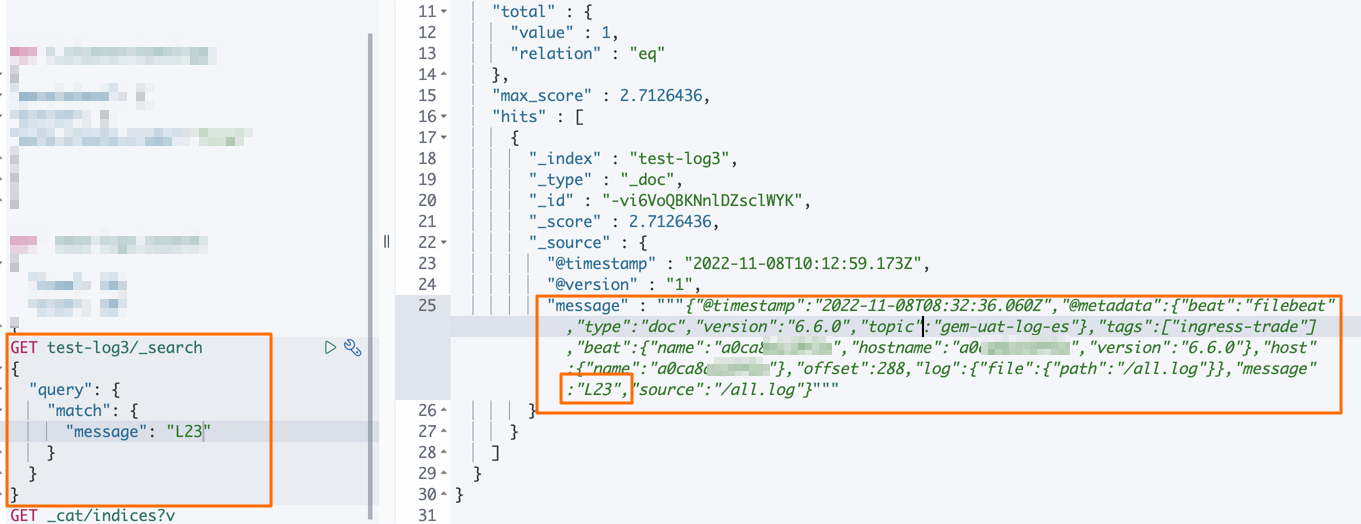
- 在Console中,執行如下命令,查看同步后數據。
GET test-log3/_search { "query":{ "match":{ "message":"L23" } } }預期結果如下。