本文介紹在阿里云Elasticsearch集群上,通過生命周期管理ILM(Index Lifecycle Management)功能,實現冷熱數據分離的實踐流程。通過本實踐,您既可以實現在保證集群讀寫性能的基礎上,自動維護集群上的冷熱數據,又能通過優化集群架構,降低企業生產成本。
背景信息
| 階段 | 描述 |
|---|---|
| hot | 熱數據階段。主要處理時序數據的實時寫入,可根據索引的文檔數、大小、時長決定是否調用rollover API來滾動更新索引。 |
| warm | warm階段。索引不再寫入,主要用來提供查詢。 |
| cold | 冷數據階段。索引不再更新,查詢很少,查詢速度會變慢。 |
| delete | 刪除數據階段。索引將被刪除。 |
您可以通過兩種方式為索引添加生命周期管理策略:
- 為索引模板添加生命周期管理策略:將策略應用到整個別名覆蓋的索引下,本文以此為例。
- 為單個索引添加生命周期管理策略:只能覆蓋當前索引,新滾動的索引不再受策略影響。
在時序和冷熱數據場景上應用ILM,可以大幅度節約存儲成本。本文以冷熱數據場景為例,介紹如何使用ILM功能。配置場景如下:
- 將索引數據實時寫入Elasticsearch。當索引數據增加到一定量時,數據自動寫入新索引。
- 舊索引在hot階段停留30分鐘,進入warm階段。
- warm階段完成Merge及Shrink操作后,索引等待1小時(從滾動更新時算起),進入cold階段。
- cold階段將熱節點數據遷移到冷節點,實現冷熱數據分離后,索引會在2個小時(從滾動更新時算起)后被刪除。
注意事項
- Elasticsearch索引生命周期策略需密切貼近業務模型。例如,對多個不同結構的索引進行生命周期管理,建議各個索引配置獨立的別名和生命周期策略,以便于管理。
- 使用rollover滾動索引,初始索引應以自增數字結尾(-000001),否則策略不生效,長度要求為6。例如,定義初始索引為myindex-000001,則rollover后的索引是myindex-000002,以此類推進行遞增。如果集群中索引名不符合規范,建議進行索引重建。
- hot階段主要處理數據寫入。業務中需保證數據是按照時間順序寫入的,處于warm和cold階段的索引不建議進行數據寫入。例如,在warm階段配置actions為shrink或read only,那么索引進入warm階段后將處于只讀狀態,數據無法寫入。
操作流程
步驟一:創建冷熱集群并查看節點的冷熱屬性
冷熱集群是指在集群中包含冷、熱兩種屬性的節點,可以提高Elasticsearch的處理性能和服務穩定性。兩者區別如下。
| 節點類型 | 存儲數據要求 | 讀寫性能要求 | 規格要求 | 存儲要求 |
|---|---|---|---|---|
| 熱節點(hot) | 近期數據,例如最近2天的日志數據。 | 高 | 高,例如32核64 GB | 建議使用SSD云盤存儲數據,存儲空間大小需根據數據大小進行設置。 |
| 冷節點(warm) | 歷史數據,例如2天之前的日志數據。 | 低 | 低,例如8核32 GB |
|
- 在Console中,執行如下命令,查看集群冷熱節點屬性。
GET _cat/nodeattrs?v&h=host,attr,value結果顯示集群中包含3個hot節點,2個warm節點,支持冷熱架構。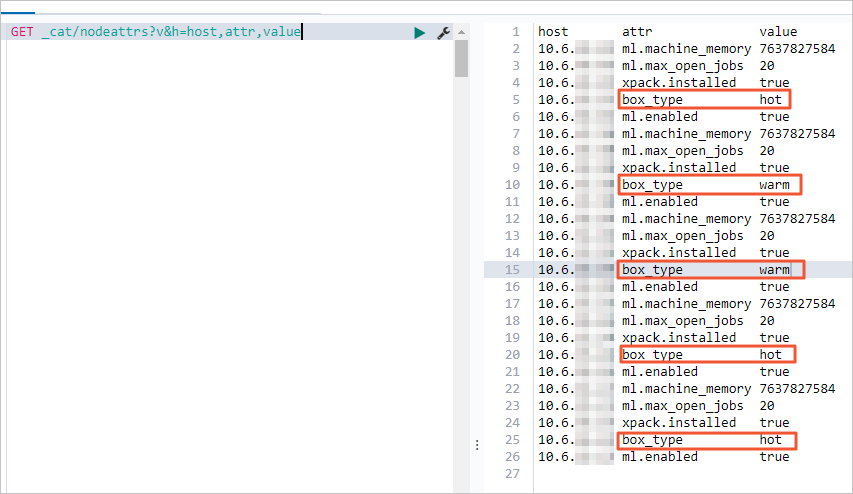
步驟二:為索引配置生命周期管理策略
- 根據生命周期階段過濾索引,并查看索引詳細配置。
- 在Index management中,單擊Lifecycle status右側的Lifecycle phase,從下拉列表中選擇生命周期階段進行過濾。
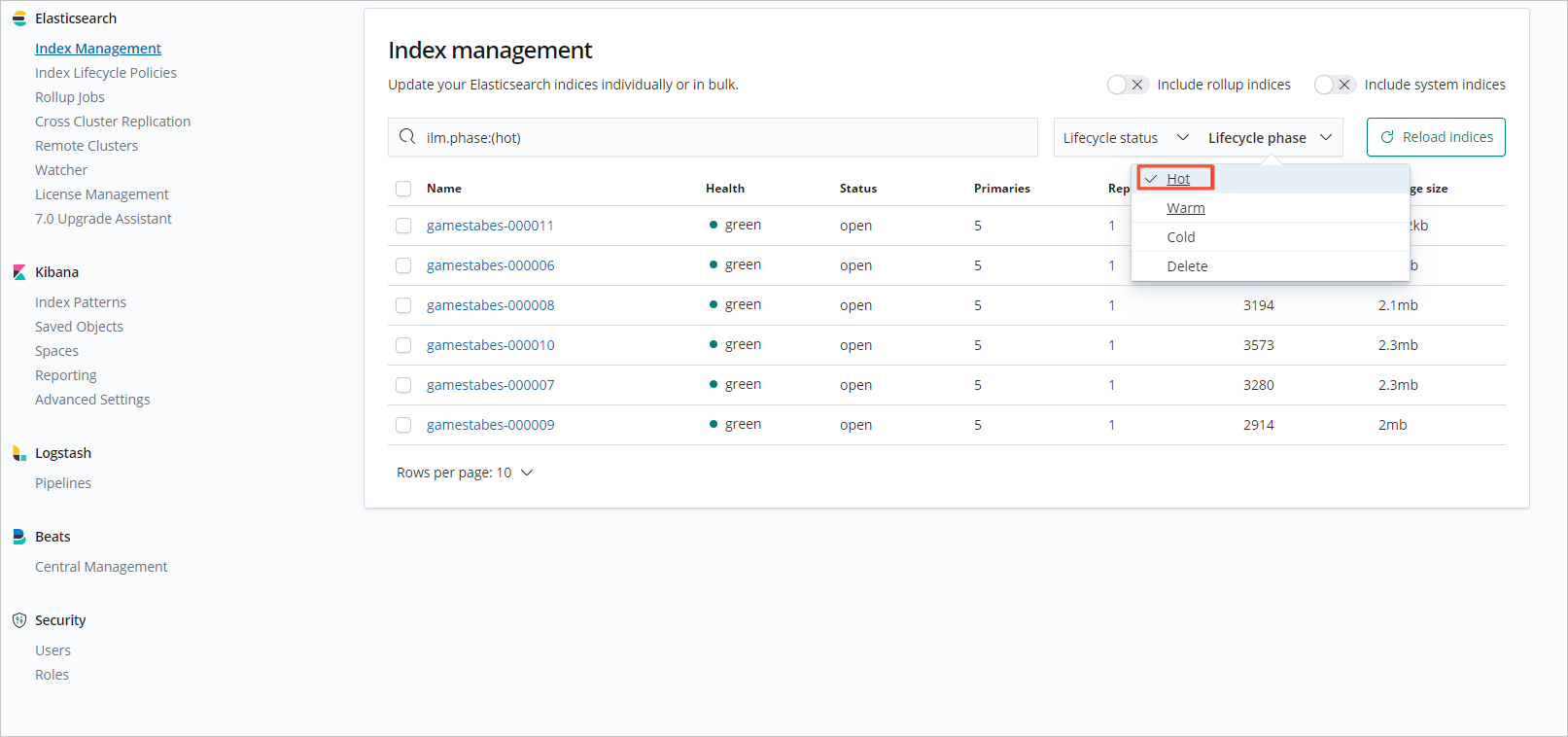
- 單擊過濾后的索引,查看索引詳細信息。
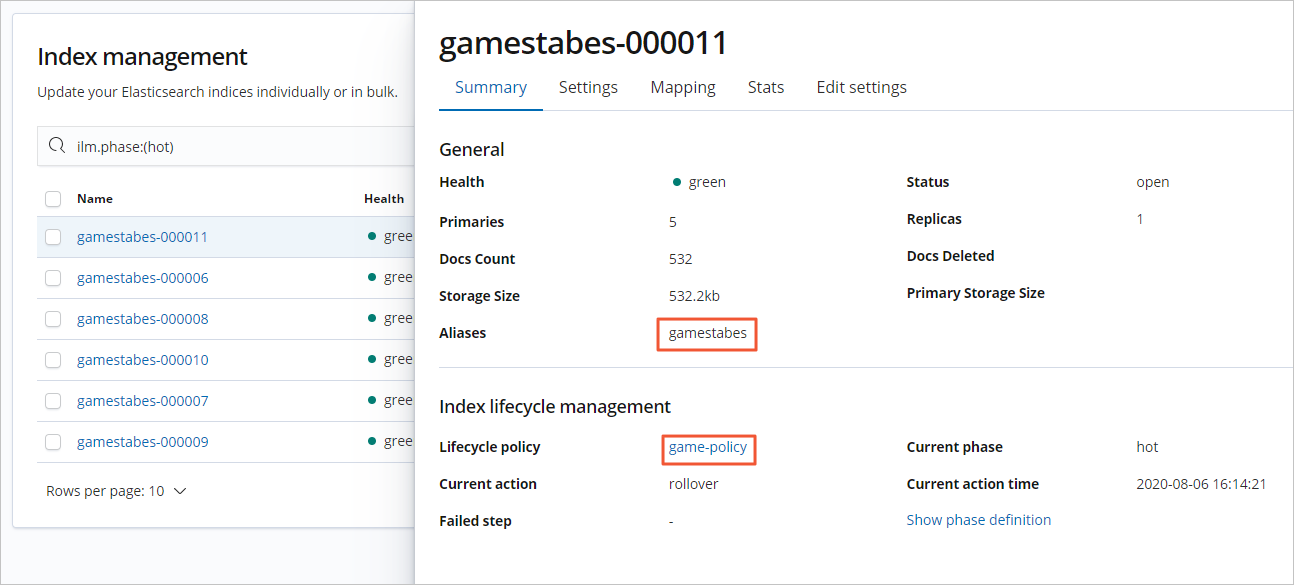
- 在Index management中,單擊Lifecycle status右側的Lifecycle phase,從下拉列表中選擇生命周期階段進行過濾。
步驟三:驗證數據分布
- 查詢進入cold階段的索引,并查看其配置信息。
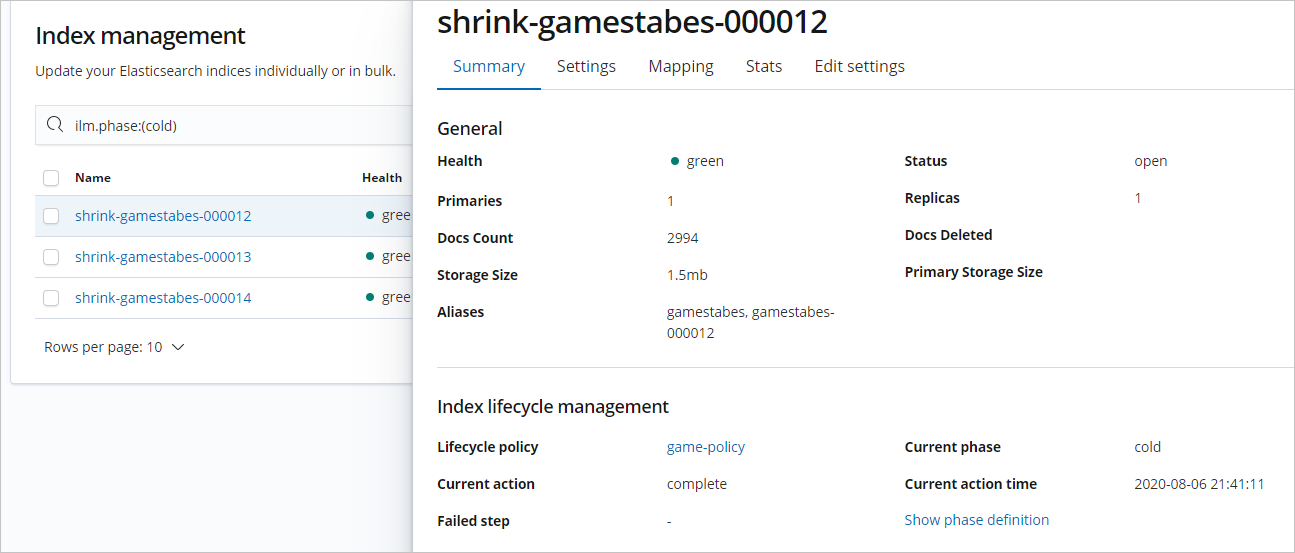
- 查詢處于cold階段索引的shard分布。
GET _cat/shards?shrink-gamestables-000012返回結果如下。根據返回結果可知,cold階段的索引數據主要分布在冷數據節點上。
步驟四:更新ILM策略
- 更新正在運行的ILM策略。
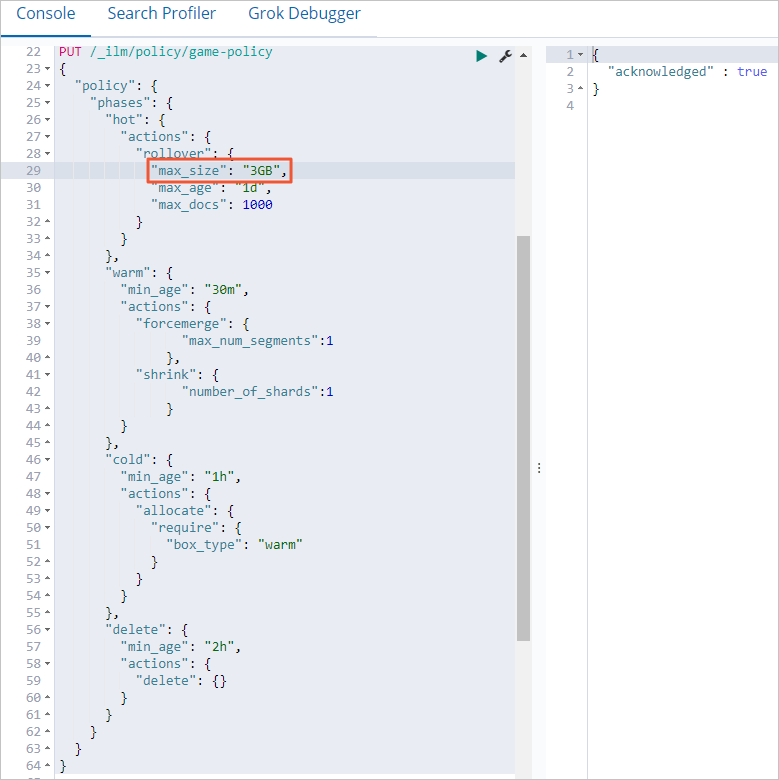
- 查看更新后的策略版本。
- 在Index lifecycle policies中,查看更新后的策略版本。更新后策略的版本號增加1,此時正在滾動寫入的索引依舊使用舊策略,新策略將在下次滾動更新時生效。
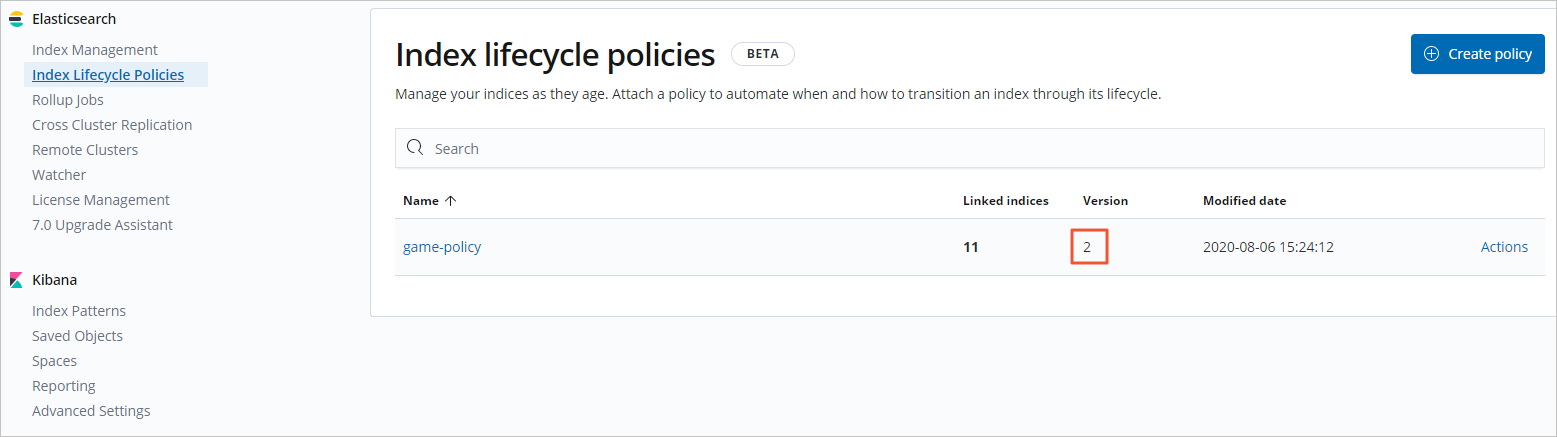
- 在Index lifecycle policies中,查看更新后的策略版本。
步驟五:切換ILM策略
常見問題
Q:如何設置ILM策略周期?
A:由于索引生命周期策略默認是10分鐘檢查一次符合策略的索引,因此在這10分鐘內索引中的數據可能會超出指定的閾值。例如在步驟二:為索引配置生命周期管理策略時,設置max_docs為1000,但doc數量在超過1000后才觸發索引滾動更新,此時可通過修改indices.lifecycle.poll_interval參數來控制檢查頻率,使索引在閾值范圍內滾動更新。
注意 請慎重修改該參數值,避免時間間隔太短給節點增加不必要的負載,本測試中將其改成了1m。
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval":"1m"
}
}