通過指標報警,您可以設置多維度的監控指標和Tags,幫助您快速定位Elasticsearch的性能問題,提高運維排查效率。本文以配置集群shard數監控報警、節點個數監控報警和查詢隊列監控報警為例,為您介紹如何將指標報警配置應用到具體的業務中。
集群shard數監控報警
Elasticsearch 7.x版本開始對單機分片數進行了限制,默認單機分片數不能超過1000。高級監控報警提供的集群分片數監控報警能力,可以對單實例分片總數進行報警。您可以參見評估Shard規劃單機分片數,當單機分片總數達到閾值建議優化索引。
- 登錄阿里云Elasticsearch控制臺。
在左側導航欄,單擊高級監控報警。
在左側導航欄的報警模塊,定義集群shard數監控報警規則及報警聯系人,請參見管理報警組、配置報警規則和管理報警聯系人。
本文以2核4 GB,3個數據節點的集群為例。按照shard評估,建議單節點的shard數在120~200之間,三個節點的總shard數在360~600之間。當集群shard數大于600時進行WARNING報警,超過900時進行CRITICAL報警。對應的報警規則配置如下。
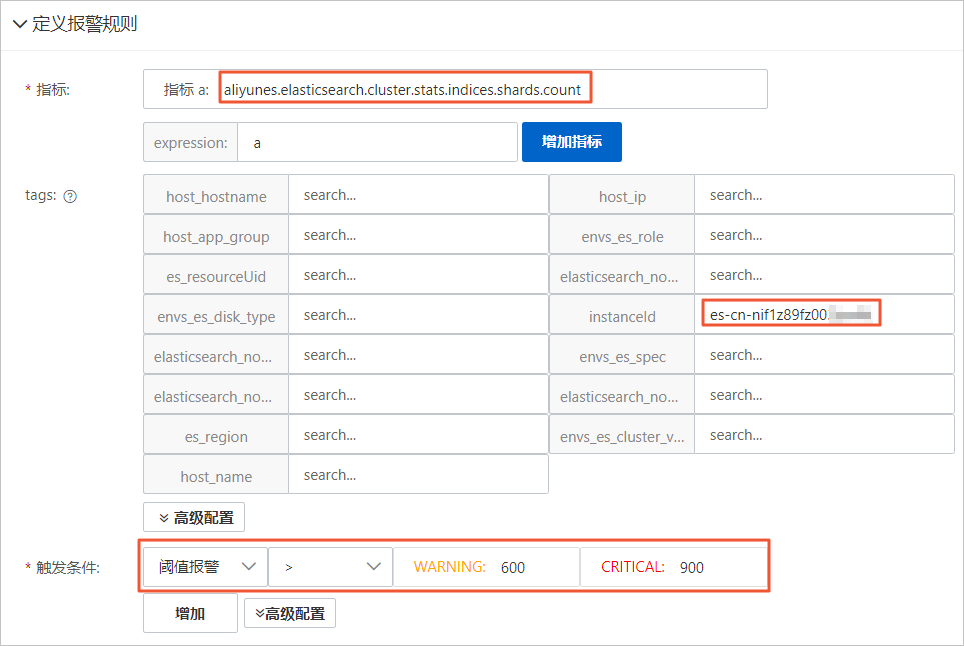
規則配置的詳細參數說明,請參見配置報警規則。本示例的部分參數配置如下。
參數
配置
指標
選擇aliyunes.elasticsearch.cluster.stats.indices.shards.count。
tags
instanceId設置為待監控的實例ID。
觸發條件
選擇閾值報警。設置集群shard數>600進行WARNING報警,>900進行CRITICAL報警。
驗證結果。
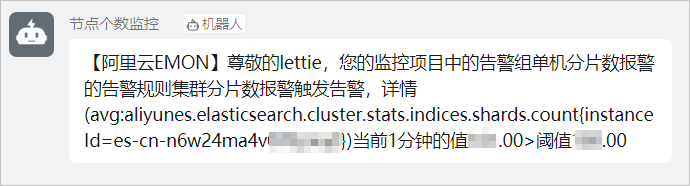
報警配置成功后,當集群shard數超過設定閾值時,您指定的報警通知人就可以通過釘釘群接收到報警通知,詳細信息請參見通過釘釘群接收報警通知。
節點個數監控報警
節點脫離集群后不易被發現,脫離時間太久節點會自動從集群隔離。為解決此問題,您可以配置高級監控報警,對集群中的節點個數進行監控。
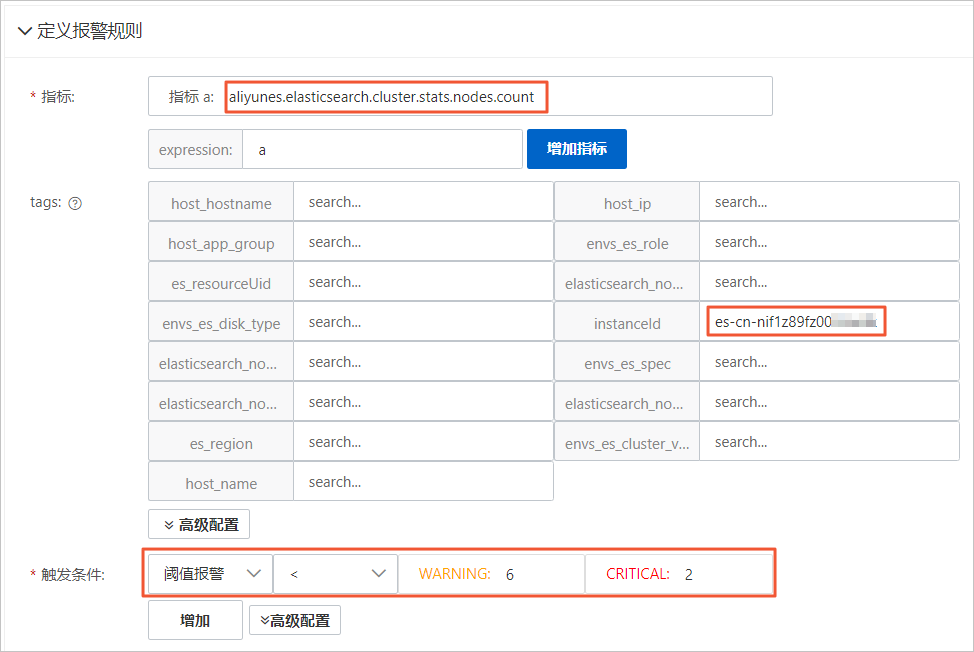
規則配置的詳細參數說明,請參見配置報警規則。本示例的部分參數配置如下。
參數 | 配置 |
指標 | 選擇aliyunes.elasticsearch.cluster.stats.nodes.count。 |
tags | instanceId設置為待監控的實例ID。 |
觸發條件 | 選擇閾值報警。設置集群節點個數<6進行WARNING報警,<2進行CRITICAL報警。 |
報警配置成功后,當集群中的節點個數小于設定閾值時,您指定的報警通知人就可以通過釘釘群接收到報警通知,詳細信息請參見通過釘釘群接收報警通知。
查詢隊列監控報警
Elasticsearch的查詢隊列大小默認為1000,當隊列堆積嚴重時,新的請求將被中止。您可以通過阿里云Elasticsearch的高級監控報警功能,對數據節點查詢隊列的等待任務數進行監控報警。
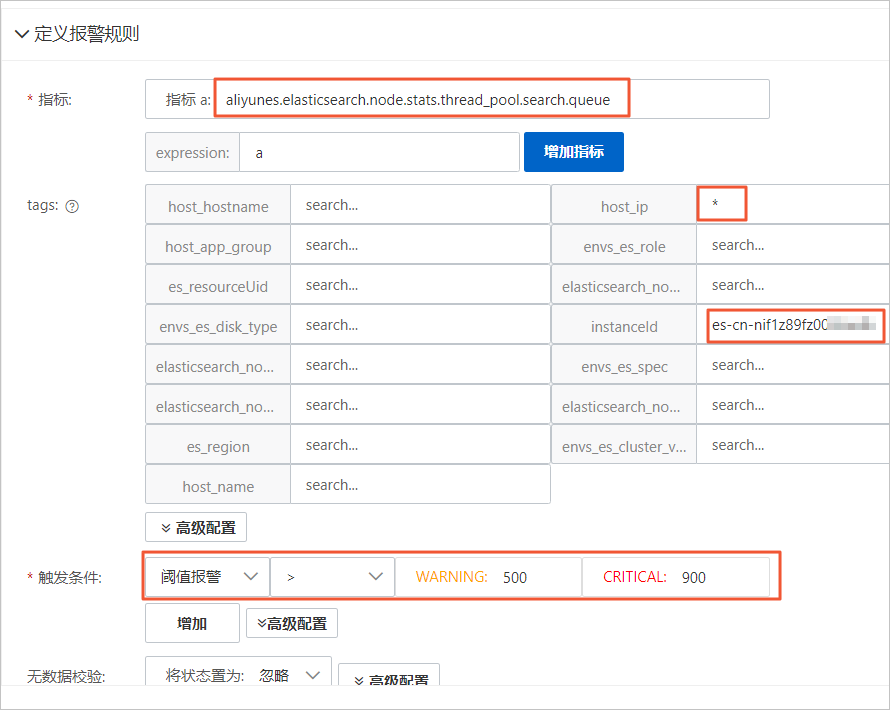
規則配置的詳細參數說明,請參見配置報警規則。本示例的部分參數配置如下。
參數 | 配置 |
指標 | 選擇aliyunes.elasticsearch.node.stats.thread_pool.search.queue。 |
tags |
|
觸發條件 | 選擇閾值報警。設置數據節點查詢隊列等待任務數>500進行WARNING報警,>900進行CRITICAL報警。 |
報警配置成功后,當數據節點查詢隊列等待任務數大于設定閾值時,報警通知人就可以通過釘釘群接收到報警通知,詳細信息請參見通過釘釘群接收報警通知。