本文介紹E-MapReduce Serverless StarRocks提供的健康報告內容,并通過示例闡明其潛在的應用場景。該健康報告提供了前一天(T+1)的數據,并包括SQL查詢、表分析和導入任務三個核心部分。
查看健康報告
進入EMR Serverless StarRocks實例列表頁面。
在左側導航欄,選擇。
在頂部菜單欄處,根據實際情況選擇地域。
單擊目標實例ID。
單擊健康報告頁簽。
在健康報告頁面,您可以查看SQL查詢、表分析和導入任務等報表。
SQL查詢
該頁面展示了SQL查詢分析和參數化SQL分析兩部分內容。您可以通過選擇特定的日期和SQL類型,按照天來查看不同SQL類型的TOP SQL指標。
支持以下SQL類型:
DML:用于數據的查詢和變更操作。例如,SELECT、UPDATE、DELETE等語句。
DDL:用于定義和修改數據結構的語句。例如,CREATE、ALTER等。
其他:包括非DML和DDL類的SQL命令。例如,SHOW等輔助命令語句。
SQL查詢分析
該部分內容是對StarRocks執行的SQL語句的查詢時間、CPU消耗以及內存消耗等維度進行排序,從而獲取TOP SQL并展現相應的執行指標。您可以基于這些指標對潛在的性能問題進行優化。 例如,可以從慢SQL Top10中查看指定日期日執行時間最長的10條SQL語句。然后,根據Profile查詢分析提供的詳細信息來優化這些慢執行的SQL語句,Profile分析詳情請參見Query Profile介紹。
報表主要字段說明如下。
字段名稱 | 說明 |
查詢ID | StarRocks中每次SQL執行產生的唯一標識符。每一次SQL執行都會生成新的ID。 |
用戶 | 執行SQL的StarRocks數據庫用戶。 |
查詢時間 | SQL執行過程中消耗的時間。單位:ms。 |
CPU執行時間 | SQL執行過程中消耗的CPU時間,是所有參與執行的CPU核數的CPU時間匯總。單位:ns。 |
內存占用 | SQL執行過程中消耗的內存。單位:bytes。 |
掃描字節數 | SQL執行過程中訪問的數據量大小。單位:bytes。 |
掃描行數 | SQL執行過程中訪問的數據行數。 |
返回行數 | SQL執行后返回的結果行數。 |
SQL文本 | 被執行的具體SQL語句文本。 |
參數化SQL分析
參數化SQL是指將SQL語句中的常量替換成?參數,同時保留原有語法結構,并刪除注釋、調整空格,生成新的SQL語句。參數化SQL將原始SQL的語法結構映射成相同的參數化SQL語句,有助于對同類型的SQL進行綜合分析。
例如,對于以下兩個SQL語句,當它們經過參數化處理后,它們屬于同一類SQL。
原始SQL
SELECT * FROM orders WHERE customer_id=10 AND quantity>20 SELECT * FROM orders WHERE customer_id=20 AND quantity>100參數化后SQL
SELECT * FROM orders WHERE customer_id=? AND quantity>?
參數化SQL分析從SQL執行頻次、SQL執行總耗時、SQL耗時離散度、SQL CPU資源總消耗、SQL內存資源總消耗、SQL執行失敗頻次等維度進行排序,獲取相應的TOP SQL并展現相關指標。
通過參數化SQL分析,您可以:
獲取StarRocks數據庫整體的SQL執行情況。
通過優化執行次數較多、執行時間較長以及CPU和內存消耗較多的SQL,以獲取更大的優化收益。
通過查詢時間變異系數來衡量SQL執行的時間穩定性,可以發現潛在的性能問題。例如,同類SQL執行時間變長可能是由于數據傾斜、資源不足導致的pending等原因。

涉及字段說明如下。
字段
說明
參數化SQL ID
參數化SQL的哈希值,用于標記參數化SQL。
查詢時間變異系數
SQL查詢執行時間標準差與其平均值的比值。通常變異系數越大,代表同類SQL每次執行的時間差別越大。
執行次數
參數化SQL的總執行次數。
參數化SQL文本
參數化后的SQL文本語句。
通過執行失敗次數查找對應的SQL失敗原因,來發現潛在的問題。

涉及字段說明如下。
字段
說明
參數化SQL ID
參數化SQL的哈希值,用于標記參數化SQL。
執行失敗次數
參數化SQL執行失敗的次數。
執行次數
參數化SQL的執行總次數。
參數化SQL文本
參數化后的SQL文本語句。
表分析
該頁面展示數據表的查詢熱度、查詢SQL類型、數據分布均衡度等相關的指標,為優化數據表提供判斷依據。主要指標如下表所示。
指標 | 說明 |
SQL執行次數 | 是指包含這張表的SQL的總執行次數。一般的,表的執行次數越多,越需要對表設計進行精心的優化來改善Starrocks實例的使用。 |
關聯的參數化SQL個數 | 這里指的是這張表關聯了幾個參數化SQL。您可以分析表的查詢SQL類型模式來優化表的設計。更進一步的,您可以從不同的查詢類型中識別共性,看是否需要創建物化視圖來加速對這張表中數據的查詢。 |
Tablet數據大小變異系數 | 是指同一個分區內的tablet數據大小變異系數,代表了一個表的數據的tablet分布均衡程度。計算方式為:同一個分區內tablet數據大小的標準差除以平均值。一般來說,變異系數越大,這個分區越有可能存在數據傾斜的情況。 |
導入任務
該頁面展示導入任務的統計信息,并從多個角度對導入任務進行分析。
目前系統僅能支持統計和分析存算一體實例下的導入任務情況。
Top導入熱表潛在小文件分析
針對表級別的數據導入情況,系統將會對每個表的所有導入任務生成的數據文件進行深入分析,以評估其潛在的小文件問題嚴重程度,并據此計算出一個影響得分。根據該得分從高至低排序,選出Top 20個受小文件問題影響最大的表。小文件問題的存在可能導致查詢性能下降以及Compaction操作效率降低。針對此問題,建議您:
結合表的實際數據規模,科學合理地選擇分區與分桶的數量,以有效避免小文件問題的發生。
通過適度增大批量處理的規模,可以在提高整體數據處理吞吐量的同時,有效減少對象存儲中的小文件數量。
雖然Compaction能夠整合數據文件、提升系統性能,但其運行過程中會占用一定的系統資源。因此,在資源較為緊張的情況下,建議適當調整Compaction頻率以平衡資源使用效率。
以下是用于評估小文件影響得分的具體算法:
主鍵表:計算公式為
寫入文件總數÷寫入文件的平均大小。若平均文件大小較小,同時文件數量較多,則表明此類表的小文件問題潛在影響也越大。非主鍵表:計算公式改為
寫入文件總數平均÷寫入單個文件所需時間。當平均寫入文件耗時較短,同時文件數量較大時,此類表的小文件問題潛在影響也越大。
通過上述算法,我們可以量化表的小文件問題,從而有針對性地對Top 20的表進行優化處理,以改善整體集群性能。
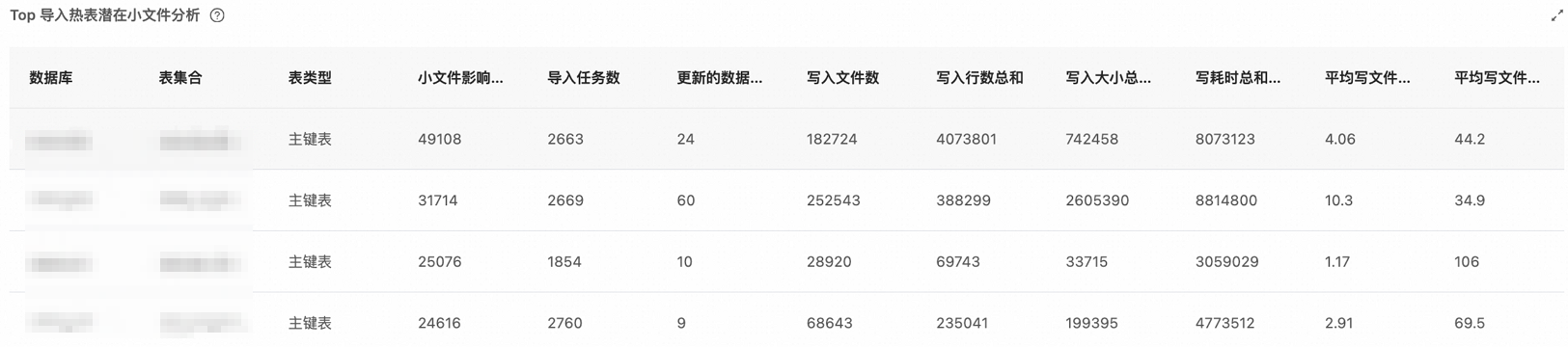
主要字段說明如下。
字段 | 說明 |
表集合 | 記錄導入任務可能同時寫入的所有相關表信息,表現為一個包含多個表的集合。 |
表類型 | 用于區分不同類型的表,主要分為主鍵表和非主鍵表兩類。非主鍵表包括明細表、聚合表和更新表。 |
小文件影響得分 | 通過算法評估潛在小文件問題的影響得分,評分值越高代表潛在的小文件問題越嚴重。 |
更新的數據分桶數 | 統計在導入任務過程中涉及到的需要更新的Tablet的總量。 |
寫入文件數 | 寫入的Segment文件的總數量。 |
平均寫文件大小 | 總寫入數據大小除以寫入文件總數,用以表示每個文件的平均寫入數據量。 |
平均寫文件耗時 | 文件寫入總耗時除以文件總數,反映了每次文件寫入操作的平均所需時間。 |
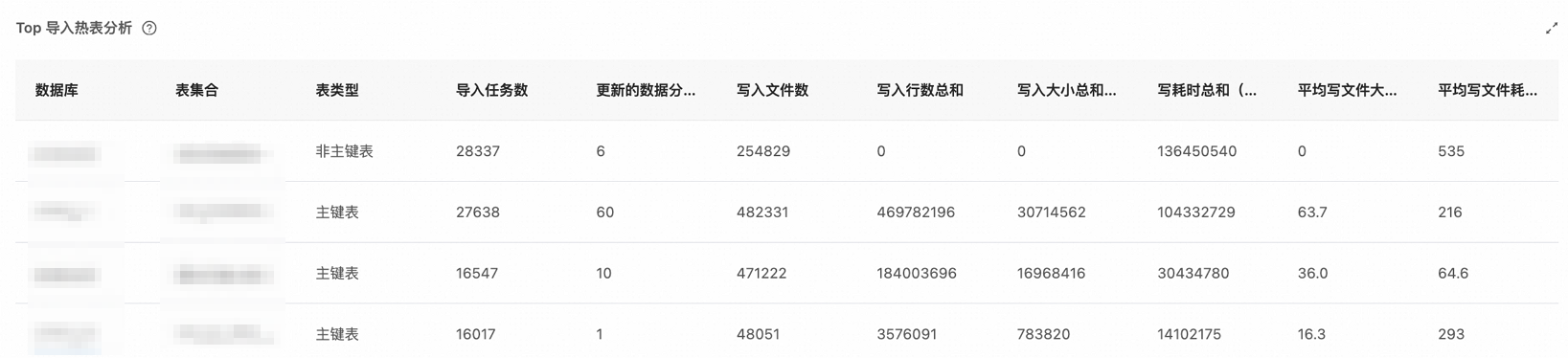
Top導入熱表分析
按表粒度對導入任務數量進行排序并選取Top 20的表,這些表的導入任務執行最為頻繁且涉及的數據導入事務最多。
導入熱節點分析
可以通過對各節點的統計數據進行導入,來分析數據的均衡度。例如,您可以從寫入總大小指標分析各個broker的寫入是否均衡。
