Trino
Trino(即原PrestoSQL)是一個開源的分布式SQL查詢引擎,適用于交互式分析查詢。EMR-3.44.0和EMR-5.10.0版本開始改用社區正式名稱Trino,之前各版本控制臺顯示為Presto,其內核其實是Trino,使用時請注意區分。
基本特性
Trino使用Java語言進行開發,具備易用、高性能和強擴展能力等特點,具體如下:
完全支持ANSI SQL。
支持豐富的數據源:
Hive
Cassandra
Kafka
MongoDB
MySQL
PostgreSQL
SQL Server
Redis
Redshift
本地文件
支持高級數據結構,具體如下:
數組和Map數據
JSON數據
GIS數據
顏色數據
功能擴展能力強,提供了多種擴展機制:
擴展數據連接器
自定義數據類型
自定義SQL函數
流水線:基于Pipeline處理模型數據在處理過程中實時返回給用戶。
監控接口完善:
提供友好的Web UI,可視化的呈現查詢任務執行過程。
支持JMX協議。
系統組成
Trino的系統組成如下圖所示。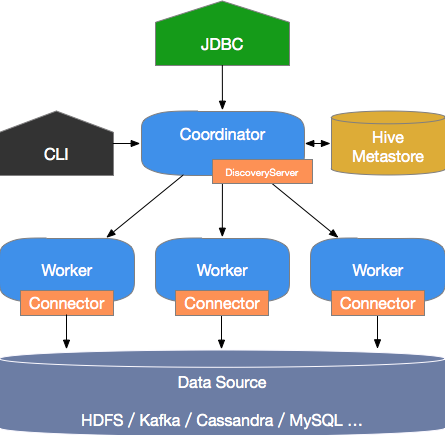
Trino是典型的M/S架構的系統,由一個Coordinator節點和多個Worker節點組成。 Coordinator負責如下工作:
接收用戶查詢請求,解析并生成執行計劃,下發Worker節點執行。
監控Worker節點運行狀態,各個Worker節點與Coordinator節點保持心跳連接,匯報節點狀態。
維護MetaStore數據。
Worker節點負責執行下發到任務,通過連接器讀取外部存儲系統到數據,進行處理,并將處理結果發送給Coordinator節點。
應用場景
Trino是定位在數據倉庫和數據分析業務的分布式SQL引擎,適合以下應用場景:
ETL
Ad-Hoc查詢
海量結構化數據或半結構化數據分析
海量多維數據聚合或報表分析
Trino是一個數倉類產品,因為其對事務支持有限,所以不適合在線業務場景。
產品優勢
E-MapReduce(簡稱EMR)中的Trino與開源Trino比較,還具備如下優勢:
即買即用,快速完成上百節點的Trino集群搭建。
彈性擴容簡單操作。
與EMR軟件棧完美結合,支持處理存儲在OSS的數據。
無需運維,EMR提供一站式服務。
基本概念
數據模型
數據模型即數據的組織形式。Trino使用Catalog、Schema和Table三層結構來管理數據。
Catalog
一個Catalog可以包含多個Schema,物理上指向一個外部數據源,可以通過Connector訪問該數據源。一次查詢可以訪問一個或多個Catalog。
Schema
相當于一個數據庫實例,一個Schema包含多張數據表。
Table
數據表,與一般意義上的數據庫表相同。
Connector
Trino通過各種Connector來接入多種外部數據源。Trino提供了一套標準的SPI接口,用戶可以使用這套接口開發自己的Connector,以便訪問自定義的數據源。
一個Catalog通常會綁定一種類型的Connector,在Catalog的Properties文件中設置。Trino內置了多種Connector。
更多參考
請根據Trino組件的版本號,修改http://trino.io/docs/3XX/中的版本號,在瀏覽器訪問該鏈接,查看開源Trino文檔。
例如,當Trino版本是331時,訪問https://trino.io/docs/331/,詳情請參見Trino 331 Documentation。