DataServing是阿里云E-MapReduce提供的基于Apache HBase的數(shù)據(jù)服務(wù)集群類型。本文為您介紹數(shù)據(jù)服務(wù)集群支持的特性,適用場景以及技術(shù)架構(gòu)。
特性介紹
Apache HBase是具有高可靠性、高性能、列存儲、可伸縮、實時讀寫的開源NoSQL分布式系統(tǒng)。特別適用于需要實時讀寫隨機訪問超大規(guī)模數(shù)據(jù)集的場景。
Apache HBase和Apache Hadoop生態(tài)系統(tǒng)無縫集成,并且可以和Apache Phoenix搭配使用以對HBase表進行類似于SQL的查詢。
Apache HBase基于HDFS作為底層存儲系統(tǒng),在云上的場景可以使用對象存儲(例如OSS)來提供更好的靈活性以及更低的成本。
Apache HBase支持海量數(shù)據(jù)存儲,具有很高的存儲和計算擴展性,以及很好的讀寫性能,支持動態(tài)列、數(shù)據(jù)多版本存儲,以及數(shù)據(jù)的生命周期管理等特點。
適用場景
基于Apache HBase的優(yōu)勢和特點,DataServing適用于以下場景:
- 風(fēng)控或畫像等需要支持動態(tài)列的場景。
- 圖片、視頻、網(wǎng)頁等中對象,物聯(lián)網(wǎng)的時序數(shù)據(jù)和車聯(lián)網(wǎng)的空間數(shù)據(jù)等需要支持海量數(shù)據(jù)和較高寫入性的數(shù)據(jù)存儲場景。
- DataServing基于讀寫延遲低,并發(fā)高等特點,支持Feed流場景。
技術(shù)架構(gòu)
EMR HBase目前支持兩種架構(gòu),一種是傳統(tǒng)的基于HDFS存算一體架構(gòu),另外一種是基于OSS-HDFS服務(wù)的存算分離架構(gòu),詳情請參見JindoData概述和OSS-HDFS服務(wù)概述。
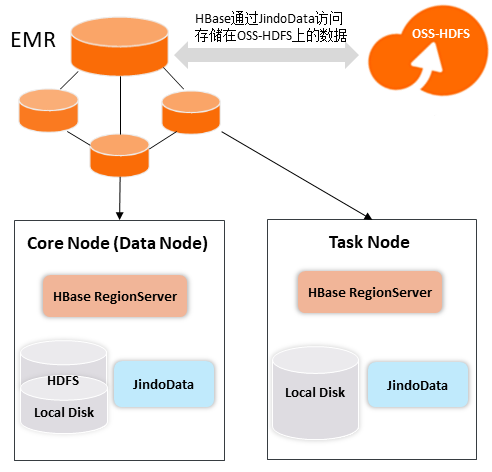
上圖是一個基于OSS-HDFS服務(wù)的存算分離架構(gòu),圖中EMR是一個已安裝HBase和HDFS等組件的EMR集群。
- EMR HBase的HFile和表的元數(shù)據(jù)都存儲到OSS-HDFS中,EMR HBase通過JindoData來訪問存儲在OSS-HDFS上的數(shù)據(jù)。
- Core節(jié)點除了部署HBase進程和JindoData進程外,還會部署HDFS進程用于存儲HBase的WAL數(shù)據(jù),Core節(jié)點不支持自由伸縮。
- Task節(jié)點上除了部署HBase進程和JindoData進程外,不會部署HDFS進程,Task節(jié)點支持自由伸縮。
- Core節(jié)點和Task節(jié)點的HBase RegionServer將數(shù)據(jù)塊緩存在節(jié)點內(nèi)存或本地磁盤中。如果緩存在本地盤,需要開啟Bucket Cache。
- EMR HBase存算分離架構(gòu)下,除了HBase自身的Block Cache外,還支持基于Jindofsx分布式緩存服務(wù)來充分利用集群本地磁盤來加速讀訪問。
存算分離優(yōu)勢如下:
- 更低的存儲成本:OSS存儲。
- 更低的運維成本:存儲全托管。
- 支持彈性伸縮:按需擴縮容計算資源。
- 更容易升級:無狀態(tài)(HBase表的元數(shù)據(jù)和數(shù)據(jù)存在OSS中,本地只有計算,升級版本時不用考慮數(shù)據(jù)遷移問題),更容易升級HBase版本。