EMR-3.42及后續版本或EMR-5.8.0及后續版本的集群,支持OSS-HDFS(JindoFS服務)作為數據存儲,提供緩存加速服務和Ranger鑒權功能,使得在Hive或Spark等大數據ETL場景將獲得更好的性能和HDFS平遷能力。本文為您介紹E-MapReduce(簡稱EMR)Hive或Spark如何操作OSS-HDFS。
背景信息
OSS-HDFS服務是一款云原生數據湖存儲產品,基于統一的元數據管理能力,在完全兼容HDFS文件系統接口的同時,提供充分的POSIX能力支持,能更好的滿足大數據和AI領域豐富多樣的數據湖計算場景,詳細信息請參見OSS-HDFS服務概述。
前提條件
已在EMR上創建集群,具體操作請參見創建集群。
操作流程
步驟一:開啟OSS-HDFS
開通并授權訪問OSS-HDFS服務,具體操作請參見開通并授權訪問OSS-HDFS服務。
步驟二:獲取HDFS服務域名
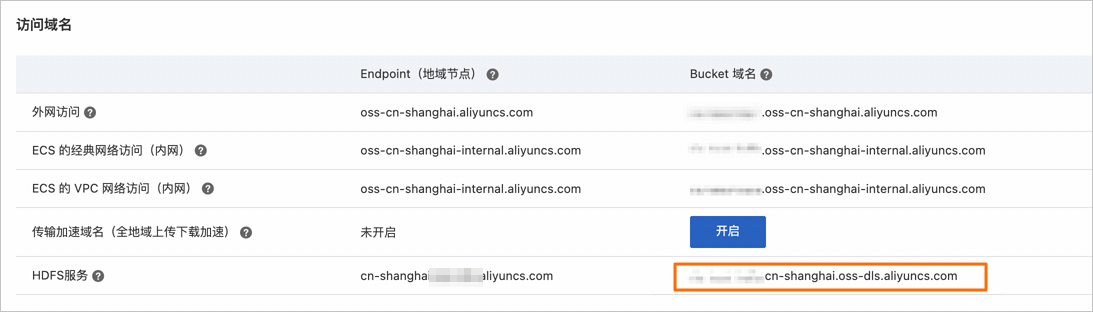
步驟三:在EMR集群中使用OSS-HDFS
說明 本示例以Hive操作OSS-HDFS為例介紹。您也可以參照此方式使用Spark操作OSS-HDFS。
為EMR集群授權
如果您的EMR集群不是使用的默認AliyunECSInstanceForEMRRole實例角色,則需要為EMR集群授權。
當前EMR的實例角色AliyunECSInstanceForEMRRole,其關聯的AliyunECSInstanceForEMRRolePolicy默認已經添加了oss:PostDataLakeStorageFileOperation策略,因此默認情況下,您無需重新對EMR授權訪問OSS-HDFS服務。