本文介紹多表合并算子的使用方法及注意事項。
用途
多表合并算子可以將多張數據表按照設置的對齊字段進行數據合并。多表合并算子是兩表并集算子的高級版本,滿足多張數據表合并的需求。
適用場景
計算鏈路 | 計算引擎 | 是否支持 |
離線 | MaxCompute | 是 |
Hive | 是 | |
HiveStorage | 是 | |
RDS/MySQL | 是 | |
Spark | 是 |
使用說明
來源節點
多表合并算子必須指定2個或者2個以上的來源節點(又稱為輸入節點,每個來源節點可視為一張表),以求取這些來源節點數據合并的結果。
對齊字段
指定全部來源節點的1個或者多個字段作為數據合并的對齊字段。數據合并的結果中將包含全部來源節點中的指定對齊字段的所有記錄。
示例如下所示,假設三個輸入節點分別為A、B、C,設置兩個對齊條件為"A.ID <=> B.ID <=> C.ID"、 "A.NAME <=> B.NAME <=> C.NAME",則多表合并默認運算結果、去重合并后的運算結果如下圖右側所示。
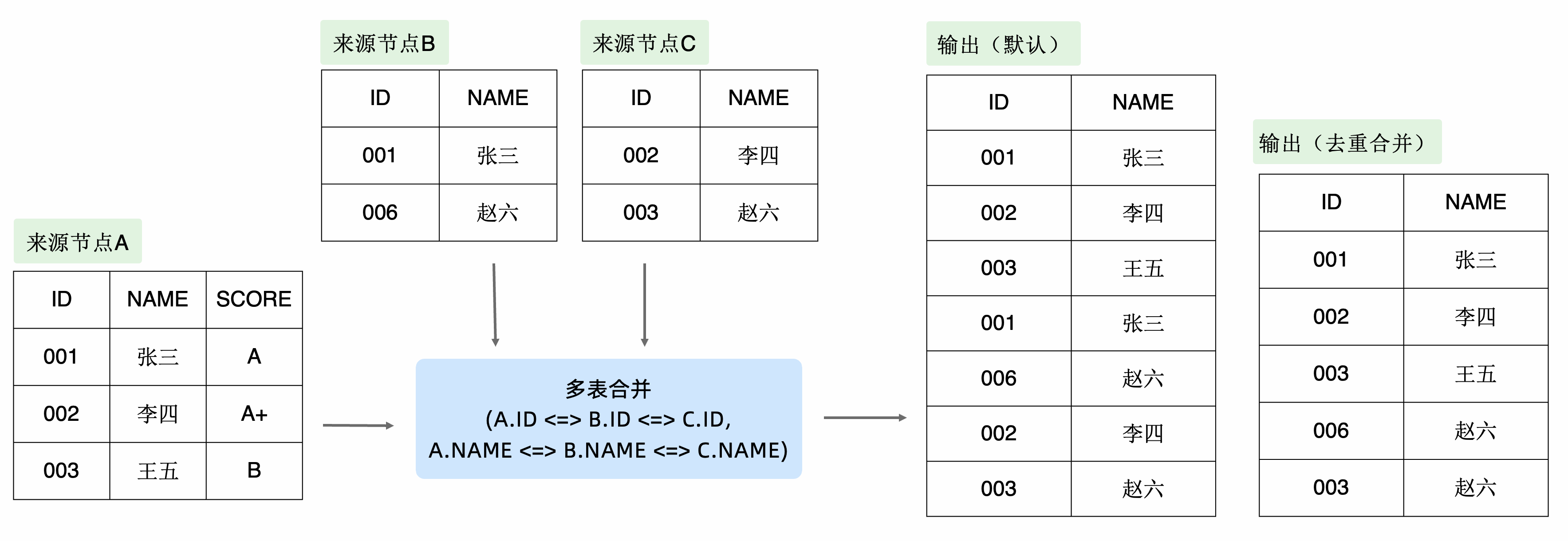
快速對齊
系統提供快速填充對齊條件的輔助工具,點擊快速對齊后,系統自動將來源節點中相同的字段配置為對齊字段。
輸出字段
對齊字段列表將自動作為當前節點的輸出字段,輸出到下游節點。可以對字段名稱和字段代碼進行重新命名。
去重合并
多表合并算子默認不做去重合并,輸出的數據包含來源節點的所有記錄。勾選去重合并后,節點的輸出數據將會過濾重復的記錄。去重合并的效果示例參考對齊字段中的示意圖。
文檔內容是否對您有幫助?