電商管理者希望能夠按商品類別統計并查看前一天的訂單數量和金額,本文通過在任務編排中創建跨庫Spark任務,實現定期將在線庫中的訂單表和商品表同步到OSS中進行數據分析,管理者可以在OSS中查看分析結果。
前提條件
背景信息
購物平臺會產生大量的數據,對這些數據進行分析時,如果直接在在線庫進行分析,輕則會使在線庫響應變慢,重則會導致在線庫無法響應業務處理。一般通過把業務數據同步到離線庫或存儲的方式對在線業務進行分析,如果您不需要將分析結果同步回在線庫,可以將在線業務的數據同步到專用于數據存儲的OSS中進行數據加工,您可以直接在OSS中查看數據加工結果。
阿里云對象存儲OSS是阿里云提供的海量、安全、低成本、高持久的云存儲服務。
如果您需要將分析結果同步回在線庫,請參見通過任務編排實現跨庫數據同步。
操作步驟
準備工作
在線庫MySQL中創建訂單表、商品表。
- 登錄數據管理DMS 5.0。
單擊控制臺左上角的
 圖標,選擇。說明
圖標,選擇。說明若您使用的是非極簡模式的控制臺,在頂部菜單欄中,選擇。
在請先選擇數據庫彈框中,搜索并選擇MySQL數據庫,單擊確認。
在MySQL數據庫中新建訂單表t_order、商品表t_product。
創建表名為t_order的訂單表。將下列建表SQL語句粘貼到SQL書寫區域,單擊執行。
創建訂單表t_order的SQL語句:
CREATE TABLE `t_order` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `product_id` bigint(20) NOT NULL COMMENT '產品id', `gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間', `gmt_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改時間', `customer_id` bigint(20) NOT NULL COMMENT '客戶id', `price` decimal(14,2) NOT NULL COMMENT '價格', `status` varchar(64) NOT NULL COMMENT '訂單狀態', `province` varchar(256) DEFAULT NULL COMMENT '交易省份', PRIMARY KEY (`id`), KEY `idx_product_id` (`product_id`), KEY `idx_customer_id` (`customer_id`), KEY `idx_status` (`status`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='訂單表' ;創建表名為t_product的商品表。將下列建表SQL語句粘貼到SQL書寫區域,單擊執行。
創建商品表t_product的SQL語句:
CREATE TABLE `t_product` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `name` varchar(128) NOT NULL COMMENT '產品名', `type` varchar(64) NOT NULL COMMENT '產品類別', `gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '創建時間', `gmt_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改時間', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='產品表' ;
訂單表t_order和商品表t_product中寫入測試數據。使用測試數據構建功能生成數據,具體請參見測試數據構建。
構建訂單表t_order的數據,數據量為2000萬行。
說明自由操作模式的實例,每個工單最大生成數據行數為100萬行。
構建商品表t_product的數據,數據量為1萬行。
新增跨庫Spark SQL任務
- 登錄數據管理DMS 5.0。
單擊控制臺左上角的
圖標,選擇。說明若您使用的是非極簡模式的控制臺,在頂部菜單欄中,選擇。
新增任務流。
單擊新增任務流。
選擇任務流所在業務場景,輸入任務流名稱和描述,再單擊確認。
在畫布左側任務類型列表中,拖拽跨庫Spark SQL節點到畫布空白區域。
配置跨庫Spark SQL任務
在任務流詳情頁面,雙擊跨庫Spark SQL節點。
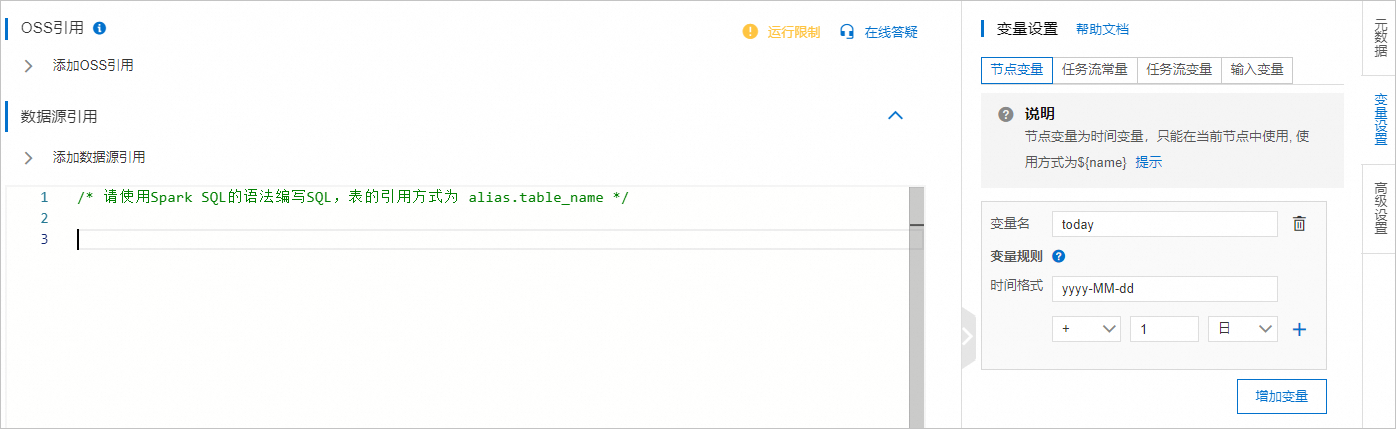
在配置頁面,配置當前日期變量${today}。關于變量的詳細介紹,請參見變量。
在界面右側,單擊變量設置。
在節點變量頁簽下,輸入變量。
添加用于數據存儲和分析的OSS。
在OSS引用區域,單擊添加OSS引用。
選擇目標OSS Bucket。
說明如果OSS未登錄,在登錄實例對話框中,輸入AccessKey ID和AccessKey Secret登錄OSS實例。
指定數據保存在OSS Bucket上的路徑。
說明如果路徑不存在,將自動創建。
路徑中支持使用變量,例如/path/${foldername}。
輸入OSS在Spark SQL語句中的引用別名為oss。
單擊保存。
添加商品訂單所在的MySQL數據庫。
在數據庫引用區域,單擊添加數據庫引用。
選擇數據庫類型,搜索并選擇數據庫,輸入數據庫在Spark SQL語句中的引用別名為demo_id。關于配置項的詳細介紹,請參見數據庫配置表。
說明如果數據庫未登錄,在登錄實例對話框中,輸入數據庫賬號和密碼登錄數據庫實例。
單擊保存。
在SQL區域,編寫Spark SQL語句,并單擊保存。
bizdate為系統變量,無需您手動配置。
/* 請使用Spark SQL的語法編寫SQL,表的引用方式為 alias.table_name */ /*創建oss t_order表引用,添加dt作為分區字段*/ CREATE TABLE oss.t_order ( id bigint COMMENT '主鍵', product_id bigint COMMENT '產品id', gmt_create timestamp COMMENT '創建時間', gmt_modified timestamp COMMENT '修改時間', customer_id bigint COMMENT '客戶id', price decimal(38,8) COMMENT '價格', status string COMMENT '訂單狀態', province string COMMENT '交易省份', dt string comment '業務日期分區' ) partitioned by (dt) COMMENT '訂單表'; insert overwrite oss.t_order partition(dt='${bizdate}') select id, product_id, gmt_create, gmt_modified, customer_id, price, status, province from demo_id.t_order o where o.gmt_create>= '${bizdate}' and o.gmt_create< '${today}'; /*創建oss t_product表引用*/ CREATE TABLE oss.t_product ( id bigint COMMENT '主鍵', name string COMMENT '產品名', type string COMMENT '產品類別', gmt_create timestamp COMMENT '創建時間', gmt_modified timestamp COMMENT '修改時間' ) COMMENT '產品表'; /*全量同步商品表數據*/ insert overwrite oss.t_product select id, name, type, gmt_create, gmt_modified from demo_id.t_product; /*創建oss t_order_report_daily表引用,以dt字段作為分區字段*/ CREATE TABLE oss.t_order_report_daily( dt string comment '業務日期', product_type string comment '商品類別', order_cnt bigint comment '訂單數', order_amt decimal(38, 8) comment '訂單金額' ) partitioned by (dt) comment '訂單統計日表'; /*按分區插入數據*/ insert overwrite oss.t_order_report_daily partition(dt='${bizdate}') select p.type as product_type, count(*) order_cnt, sum(price) order_amt from oss.t_product p join oss.t_order o on o.product_id= p.id where o.gmt_create>= '${bizdate}' and o.gmt_create< '${today}' group by product_type;OSS支持4種文件存儲格式:CSV、Parquet、ORC、JSON,默認使用CSV格式。您可以在CREATE TABLE語句中通過
USING指定。例如,將表的存儲格式指定為Parquet:
CREATE TABLE oss.t_order ( id bigint COMMENT '主鍵', product_id bigint COMMENT '產品id', gmt_create timestamp COMMENT '創建時間', gmt_modified timestamp COMMENT '修改時間', customer_id bigint COMMENT '客戶id', price decimal(38,8) COMMENT '價格', status string COMMENT '訂單狀態', province string COMMENT '交易省份', dt string comment '業務日期分區' ) USING PARQUET partitioned by (dt) COMMENT '訂單表';
運行及發布跨庫Spark SQL任務
在任務流詳情頁面,單擊畫布左上角的試運行。
單擊執行日志頁簽,查看執行結果。
如果執行日志的最后一行出現
status SUCCEEDED,表明任務流試運行成功。如果執行日志的最后一行出現
status FAILED,表明任務流試運行失敗。說明如果試運行失敗,在執行日志中查看執行失敗的節點和原因,修改節點的配置后重新嘗試。
執行成功后,您可以在DMS首頁的左側實例列表中,右鍵單擊OSS的Bucket名稱,單擊查詢,查看OSS中同步和分析的數據。
配置周期調度。
單擊畫布空白區域。
單擊任務流信息頁簽。
在調度配置區域,打開開啟調度開關,配置調度。具體配置,請參見調度周期配置表。
發布任務流。任務流發布后,此任務流會根據設置的調度周期自動執行任務。
單擊畫布左上角的發布。
輸入備注信息,再單擊發布。