本文為您介紹如何通過DataWorks數據集成將MySQL全增量數據一體化同步至MaxCompute表中。
前提條件
已完成MaxCompute和MySql數據源配置。您需要將數據庫添加至DataWorks上,以便在同步任務配置時,可通過選擇數據源名稱來控制同步讀取和寫入的數據庫。本實踐中創建的數據源名為
doc_mysql1,詳情請參見配置MySQL數據源、配置MaxCompute數據源。說明數據源相關能力介紹詳情請參見:數據源概述。
已購買合適規格的獨享數據集成資源組。詳情請參見:新增和使用獨享數據集成資源組。
已完成獨享數據集成資源組與數據源的網絡連通。詳情請參見:網絡連通方案。
已完成數據源環境準備。
需求分析
數據:將MySQL全量數據一次性同步至MaxCompute,增量數據實時同步MaxCompute Log表,全增量數據定時Merge。
表:將源端所有
doc_前綴的表名,在寫入目標端時統一更新為ods_前綴。字段:目標表在原有表結構基礎上,增加
execute_time字段用于記錄源端表某個記錄發生變更的時間。
綜合如上分析結果,最終的表對應關系如下所示:
源端數據庫 | 源端待同步表 | 寫入的目標表 | 目標表新增字段 |
doc_demo1 | doc_tb1 | ods_tb1 | execute_time |
doc_tb2_nopk | ods_tb2_nopk |
操作流程
創建同步任務
選擇同步方案。
創建同步解決方案任務,選擇需要同步的源端數據源MySQL,目標端數據源MaxCompute,并選擇一鍵實時同步至MaxCompute方案。
配置網絡連通。
源端選擇已創建的數據源
doc_mysql1,目標數據源為DataWorks工作空間創建的MaxCompute數據源,并測試連通性。設置同步來源與規則。
在基本配置區域,配置同步解決方案的名稱、任務存放位置等信息。
在數據來源區域,確認需要同步的源端數據源相關信息。
在選擇同步的源表區域,選中需要同步的源表,單擊
 圖標,將其移動至已選源表。
圖標,將其移動至已選源表。本案例中選擇
doc_demo1下的表doc_tb1、doc_tb2_nopk。在設置表(庫)名的映射規則區域,單擊添加規則,選擇相應的規則進行添加。
同步時默認將源端數據表寫入目標端同名表中,您可以通過添加映射規則定義最終寫入目的端的表名稱。本案例通過源表名和目標表名轉換規則,將源端
doc_前綴的表在寫入目標端時替換為ods_前綴。
設置目標表。
設置寫入模式。
目前支持將增量數據實時寫入MaxCompute的Log表,Log表中的增量數據再定期與目標端Base表全量數據進行合并(Merge),最終將結果寫入Base表中。
時間自動分區設置。
您可以在時間自動分區設置配置該任務寫入MaxCompute分區表或是非分區表,并定義分區字段的名稱,本案例中選擇寫入分區表,分區字段為
ds。說明若選擇寫入分區表,可單擊
 圖標定義目標表分區字段名稱。
圖標定義目標表分區字段名稱。刷新源表與目標表映射。
單擊刷新源表和MaxCompute表映射將根據您在步驟三配置的目標文件映射規則來生成目標表,若步驟三未配置映射規則,將默認寫入與源表同名的目標表,若目標端不存在該同名表,將默認新建。同時,您可以修改表建立方式、為目標表在源有表字段基礎上增加附加字段。
說明目標表名將根據您在設置表(庫)名的映射規則階段配置的表名轉換規則自動轉換。
功能
描述
為非主鍵表選擇主鍵
由于當前方案不支持無主鍵表同步,所以您需要單擊同步主鍵列的
 按鈕,為無主鍵表設置自選主鍵,即選擇表中一個或部分字段作為主鍵,寫入目標端時將會使用該主鍵進行去重。
按鈕,為無主鍵表設置自選主鍵,即選擇表中一個或部分字段作為主鍵,寫入目標端時將會使用該主鍵進行去重。本案例為無主鍵表
doc_tb2_nopk選擇id列承擔主鍵作用。選擇表建立方式
支持自動建表和使用已有表。
當表建立方式選擇使用已有表時,MaxComputeBase 表名列顯示自動創建的表名稱。您也可以在下拉列表中選擇需要使用的表名稱。
當表建立方式選擇自動建表時,顯示自動創建的表名稱。您可以單擊表名稱,查看和修改建表語句。
本案例選擇自動建表。
是否全量同步
您可以在全量同步列選擇是否需要在實時同步前先將全量數據同步至目標端。
如果關閉全量同步,則對應的表將不進行離線全量同步。適用于已經通過其他方式將全量數據同步至目標端的場景。
本案例開啟所有表的全量同步。
為目標字段添加附加字段
單擊操作列的編輯附加字段,可以為目標表在源端字段的基礎上增加字段并為字段賦值。支持手動賦值常量與變量。
說明僅在表建立方式為自動建表時,可以使用此功能。
本案例新增字段
execute_time并為字段賦值變量_execute_time_,用于記錄操作的執行時間。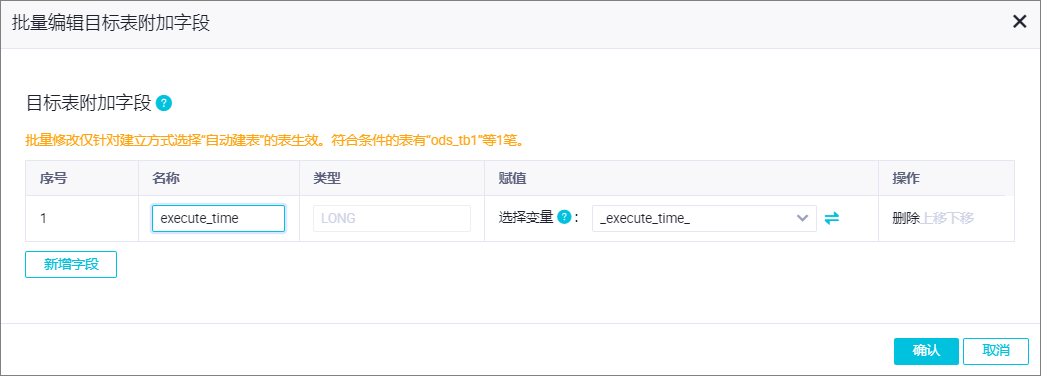
目標表、字段及數據讀取寫入關系確認無誤后,單擊下一步。
表粒度同步規則設置。
對目標表進行單獨配置DML和批量配置DML規則,配置項有插入(INSERT)、更新(UPDATE)和刪除(DELETE)。可配置的策略如下:
正常處理:此DML消息將會繼續下發給目標數據源,由目標數據源來處理。
忽略:丟棄掉此DML消息,不再向目標數據源發送此消息,對應數據不會改變。
有條件的正常處理:按過濾表達式進行條件過濾,滿足過濾條件的數據會被正常處理,不滿足的會被忽略掉。
如不設置,則默認為正常處理。
說明修改DML為非正常處理時,將導致源端和目標端數據不一致。
DDL消息處理策略。
來源數據源會包含許多DDL操作,數據集成體提供默認處理策略,您也可以根據業務需求,對不同的DDL消息設置同步至目標端的處理策略。不同DDL消息處理策略請參見:DDL消息處理規則。
本方案使用默認處理規則。
設置任務運行資源。
當前方案創建后將分別生成全量數據離線同步子任務和增量數據實時同步子任務。您需要在運行資源設置界面配置離線同步任務和實時同步任務的相關屬性。
包括實時增量同步及離線全量同步使用的獨享數據集成資源組、離線全量同步使用的調度資源組,同時,單擊高級配置可配置是否容忍臟數據、任務最大并發數、源庫允許支持的最大連接數等參數。
說明DataWorks的離線同步任務通過調度資源組將其下發到數據集成任務執行資源組上執行,所以離線同步任務除了涉及數據集成任務執行資源組外,還會占用調度資源組資源。如果使用了獨享調度資源組,將會產生調度實例費用。您可通過任務下發機制對該機制進行了解。
離線和實時同步任務推薦使用不同的資源組,以便任務分開執行。如果選擇同一個資源組,任務混跑會帶來資源搶占、運行態互相影響等問題。例如,CPU、內存、網絡等互相影響,可能會導致離線任務變慢或實時任務延遲等問題,甚至在資源不足的極端情況下,可能會出現任務被OOM KILLER殺掉等問題。
執行同步任務
提交并發布任務。
單擊左上角的
 后,選擇進入運維中心頁面。
后,選擇進入運維中心頁面。在運維中心的左邊菜單內單擊進入頁面,對已發布的實時任務在操作欄里單擊提交即可。
您可重點關注以下步驟中創建的表及節點任務名稱以便進行后續運維。例如,創建MaxCompute Log表、創建MaxCompute Base表、創建數據集成實時同步任務、提交發布增全量Merge Into節點。
同步任務運維
同步至MaxCompute全增量Merge分為3個階段:
任務配置當天,執行全量數據初始化的離線同步任務。
任務配置當天,待全量數據初始化完成后,啟動實時同步任務,將增量數據實時同步至MaxCompute Log表。
任務配置第二天,Merge任務將Base表全量數據與實時同步任務的增量數據進行Merge,最后將結果寫入Base表。目前Merge周期為1天。
為避免上述階段出現異常導致數據未產出,我們需要分別為實時同步子任務及Merge節點進行監控。
附:查詢數據
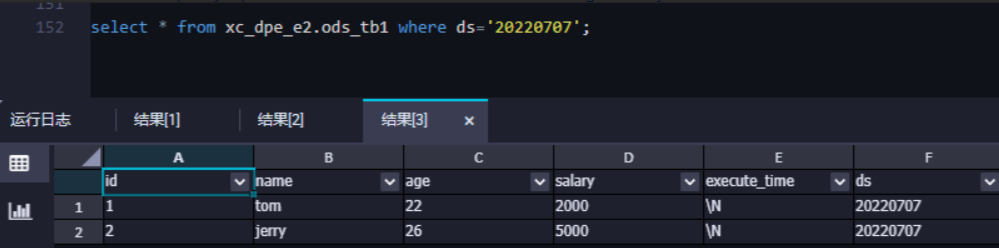
由于目前全增量Merge周期為一天,所以任務配置當天,我們只能在目標表查詢到同步的全量數據,待第二天后,可查詢到全增量Merge后的數據。
查看全量數據寫入情況
在數據開發界面找到ODPS SQL節點,通過命令查詢表數據,查詢數據前請先在數據集成>任務運維界面確認執行步驟中,啟動全量數據初始化同步任務運行步驟已執行成功。創建ODPS SQL臨時查詢節點,詳情請參見創建臨時查詢。