本文以使用MaxCompute數據源,在DataWorks上運行MaxCompute作業任務為例,為您介紹開發人員如何使用數據開發(DataStudio)創建一個周期調度任務,幫助您快速了解數據開發(DataStudio)模塊的基本使用。
前提條件
已完成開發前的環境準備,詳情請參見DataWorks準備工作流程。
本文以創建ODPS SQL任務為例,因此,工作空間需綁定MaxCompute類型數據源。
操作賬號需擁有開發權限,即阿里云主賬號,或擁有空間管理員、開發角色權限的RAM用戶。
背景信息
DataWorks的數據開發(DataStudio)面向各引擎(MaxCompute、Hologres、EMR、CDH等)提供可視化開發界面,包括智能代碼開發、數據清洗加工、規范化任務開發與發布等,保證數據開發的高效與穩定。更多數據開發模塊的使用,詳情請參見數據開發概述。
通常,寫入原始業務數據至DataWorks,并加工為最終結果表的過程如下:
在DataWorks創建多個數據表。例如:
源表:存儲從其他數據源同步過來的數據。
結果表:存儲經DataWorks清洗加工過的數據。
創建同步任務,將業務數據同步至上述源表。
創建計算節點,對同步任務產出的表數據進行清洗、逐層加工,并將每層結果寫入對應結果表。
您也可以在創建表后,使用直接上傳方式,將本地數據上傳至DataWorks的源表,再通過計算節點進行清洗加工,將加工后的數據存儲至結果表。本文使用直接上傳本地數據,并通過計算類型節點清洗該表數據為例進行說明。
進入數據開發
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
操作流程
數據開發基于業務流程組織與開發代碼,您需要先新建業務流程,才可進行后續的開發工作。
DataWorks支持使用可視化方式創建表,并以目錄結構方式在界面展示。數據開發前,您需先在引擎創建用于接收數據清洗結果的表。
DataWorks基于節點進行任務開發,不同類型的引擎任務在DataWorks上被封裝為不同類型的節點。您可根據業務需要,選擇合適的節點進行引擎任務開發。
根據節點類型,在節點編輯頁面通過對應數據庫的語法編寫業務代碼。
用于定義該節點的調度相關屬性,周期性調度運行節點。
您可使用DataWorks提供的代碼片段快捷運行、運行、高級運行三種方式調試代碼,驗證代碼邏輯是否正確。
節點調試無誤后,您需要保存并提交節點。
為保障生產任務高效運行,避免計算資源浪費。任務發布上線前,您可將任務提交至開發環境進行冒煙測試,保障任務的正確性。
DataWorks僅支持自動調度發布至生產環境的任務,因此在冒煙測試無誤后,您需將任務發布至生產環境調度系統進行周期調度。
步驟一:新建業務流程
DataWorks以業務流程為中心組織數據開發,通過各類型開發節點的容器看板,將相關工具、優化及管理操作圍繞看板對象進行組織,使開發管理更加方便智能。您可根據業務需求,將同類型業務統一放置一個業務流程。
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
創建業務流程。
您可使用如下兩種方式創建:
方式一:鼠標懸停至
 圖標,單擊新建業務流程。
圖標,單擊新建業務流程。方式二:右鍵單擊數據開發左側目錄樹的業務流程,選擇新建業務流程。
配置業務流程的名稱及描述,單擊新建。
本文示例創建名為
創建第一個周期調度任務的業務流程。實際開發時,請根據您的業務進行規劃。說明更多業務流程的使用,詳情請參見創建及管理業務流程。
步驟二:新建表
DataWorks的數據開發節點會對您的源數據進行清洗加工,因此,您需先在引擎創建用于接收數據清洗結果的表,并定義表結構。
創建表。
在步驟一創建的業務流程中,展開子目錄,右鍵單擊,選擇新建表。
配置表名稱、引擎實例等信息。
配置表結構。
進入表編輯頁面,切換至DDL模式,通過DDL語句配置表結構。生成表結構后,在基本屬性區域輸入表的中文名,并將其提交至開發環境與生產環境,提交成功后可在對應環境的數據源項目查看該表。查看各環境綁定的數據源信息,詳情請參見創建MaxCompute數據源。
說明表的新增、更新等操作均需要提交至對應環境后,才會在引擎側生效。
您也可以使用可視化方式,根據業務需求及界面引導配置所需表結構。可視化建表,詳情請參見創建并使用MaxCompute表。
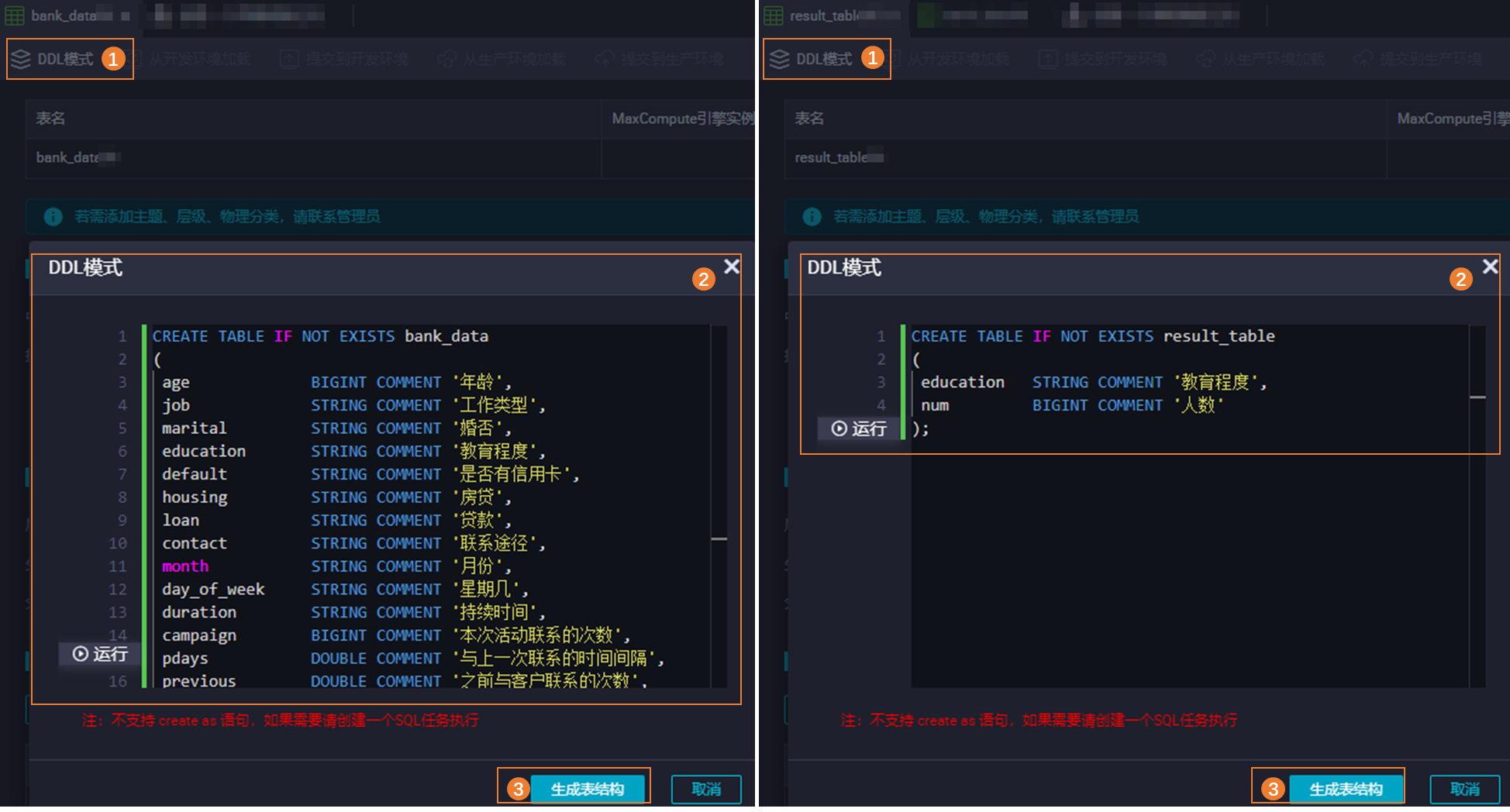 生成bank_data表結構的參考語句如下。
生成bank_data表結構的參考語句如下。CREATE TABLE IF NOT EXISTS bank_data ( age BIGINT COMMENT '年齡', job STRING COMMENT '工作類型', marital STRING COMMENT '婚否', education STRING COMMENT '教育程度', default STRING COMMENT '是否有信用卡', housing STRING COMMENT '房貸', loan STRING COMMENT '貸款', contact STRING COMMENT '聯系途徑', month STRING COMMENT '月份', day_of_week STRING COMMENT '星期幾', duration STRING COMMENT '持續時間', campaign BIGINT COMMENT '本次活動聯系的次數', pdays DOUBLE COMMENT '與上一次聯系的時間間隔', previous DOUBLE COMMENT '之前與客戶聯系的次數', poutcome STRING COMMENT '之前市場活動的結果', emp_var_rate DOUBLE COMMENT '就業變化速率', cons_price_idx DOUBLE COMMENT '消費者物價指數', cons_conf_idx DOUBLE COMMENT '消費者信心指數', euribor3m DOUBLE COMMENT '歐元存款利率', nr_employed DOUBLE COMMENT '職工人數', y BIGINT COMMENT '是否有定期存款' );生成result_table表結構的參考語句如下。
CREATE TABLE IF NOT EXISTS result_table ( education STRING COMMENT '教育程度', num BIGINT COMMENT '人數' ) PARTITIONED BY ( day STRING, hour STRING );上傳數據。
將原始業務數據存儲至DataWorks的表(本文示例為
bank_data表)中。本文示例采用直接上傳方式,導入本地文件banking.txt至DataWorks,通過上傳數據模擬實際數據寫入情況。操作圖示如下。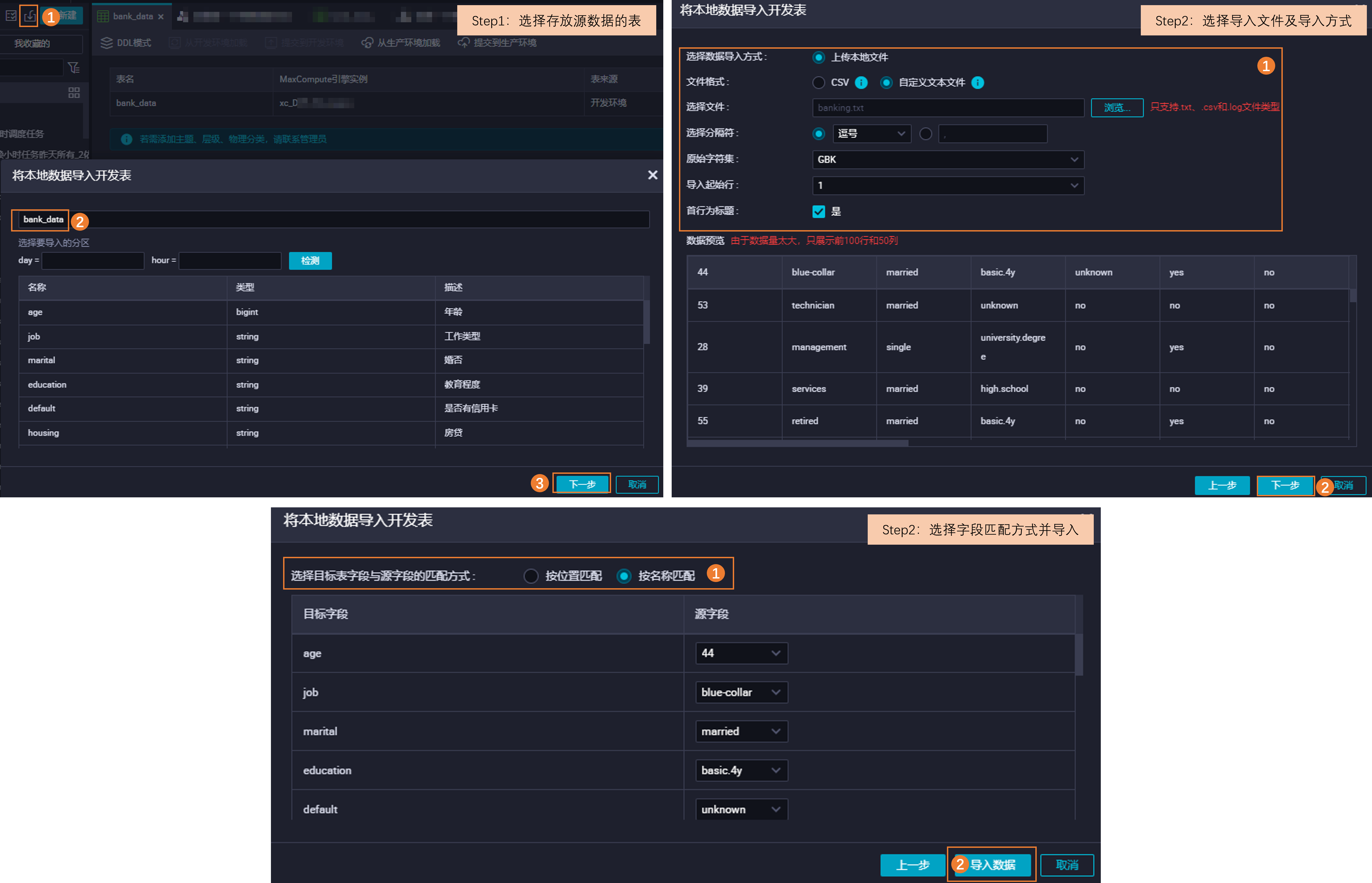 更多上傳數據內容,請參考本地數據上傳至bank_data。
更多上傳數據內容,請參考本地數據上傳至bank_data。
步驟三:新建節點
根據業務需求,選擇合適的節點類型進行開發。
目前DataWorks的節點分為數據同步類型節點與計算類型節點兩大類,實際開發過程中,您通常需要先通過離線同步任務將業務數據庫中的數據同步至數倉中,再通過DataWorks計算節點對數倉中的表數據進行清洗加工。
創建節點。
您可通過如下兩種方式創建:
方式一:基于目錄樹創建。
在目錄樹的業務流程中找到步驟一創建的業務流程。
右鍵單擊所需引擎,在新建節點下選擇合適節點。
方式二:基于業務流程面板創建。
在目錄樹的業務流程中找到步驟一創建的業務流程。
雙擊該業務流程,進入業務流程面板。
在面板左側導航欄單擊所需節點,或將所需節點拖拽至面板。
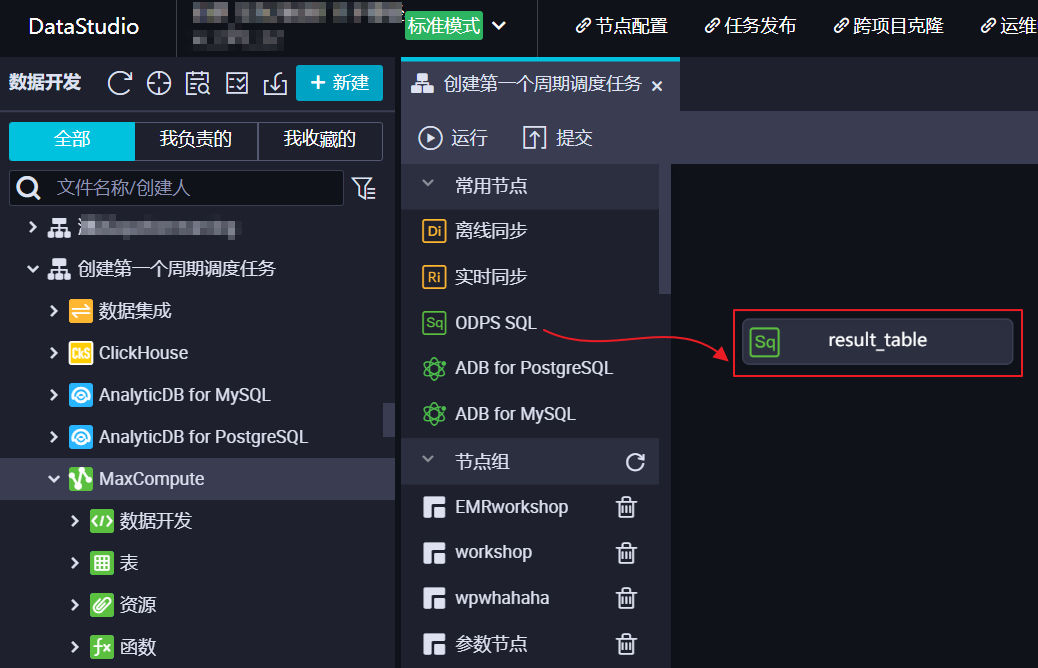
配置節點引擎實例、名稱等信息。
本文示例創建名為
result_table(與步驟二創建的結果表名稱相同)的ODPS SQL節點。說明使用DataWorks節點進行數據開發時,通過開發節點清洗數據,再將清洗結果存放至結果表。建議您將結果表名稱作為節點的名稱,以便快速定位該節點產出的表數據。
步驟四:編輯節點
在業務流程目錄樹或業務流程面板中找到步驟三創建的節點,雙擊進入節點編輯頁面。根據節點類型,通過對應數據庫的語法編寫業務代碼。
本文示例在result_table節點中,將bank_data表中指定分區的數據寫入result_table表對應的分區中,并通過變量(day、hour)定義寫入的分區。
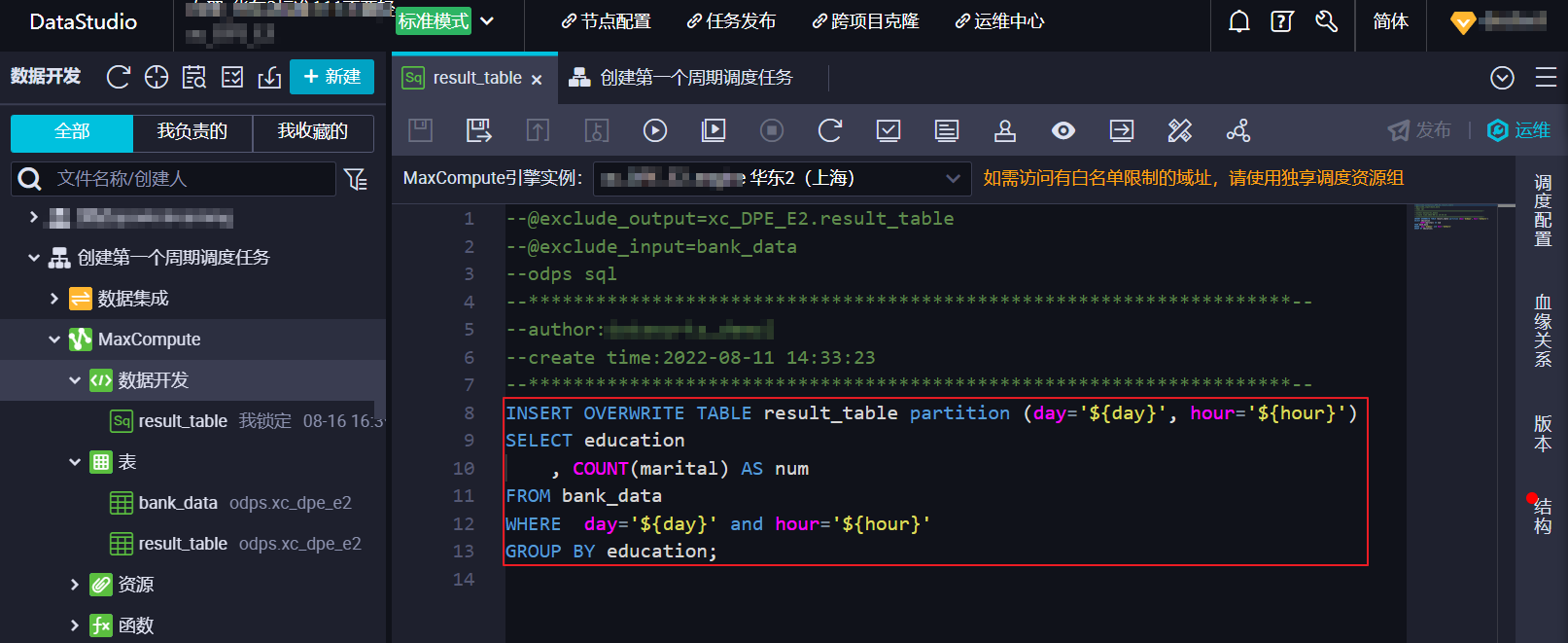 代碼參考如下。
代碼參考如下。
INSERT OVERWRITE TABLE result_table partition (day='${day}', hour='${hour}')
SELECT education
, COUNT(marital) AS num
FROM bank_data
GROUP BY education;步驟五:定義節點調度屬性
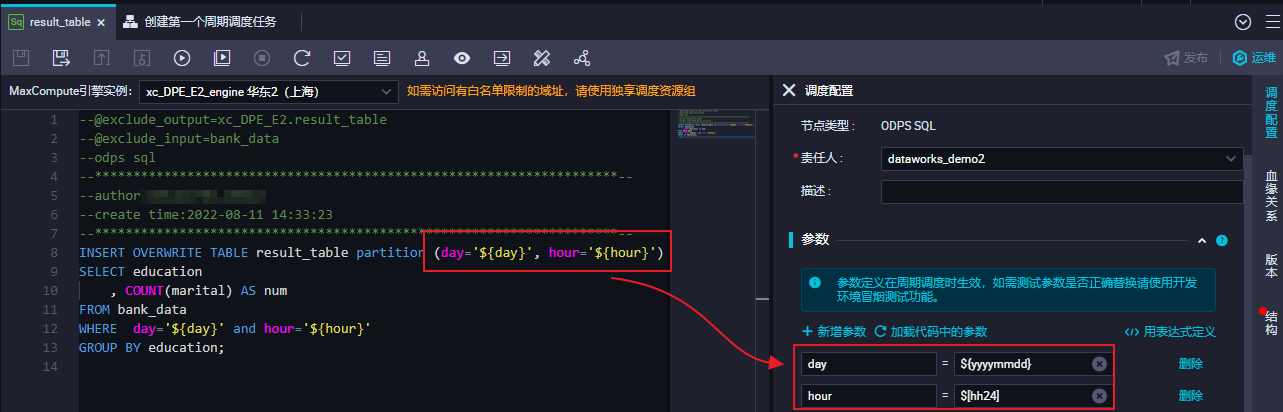
通過定義節點的調度相關屬性,實現周期調度運行目標節點。在節點編輯頁面右側導航欄的調度配置,根據業務需求配置相關屬性。
參數 | 描述 |
節點的名稱、ID、類型、責任人會自動展示,此處無需單獨配置。 說明
| |
用于定義節點調度時使用的參數。 DataWorks提供內置參數及相關自定義參數,可供任務調度時實現參數動態賦值。若步驟四編輯代碼時定義了變量,您可在此處對該變量進行賦值。 本文示例為步驟四的如下變量賦值,用于將
| |
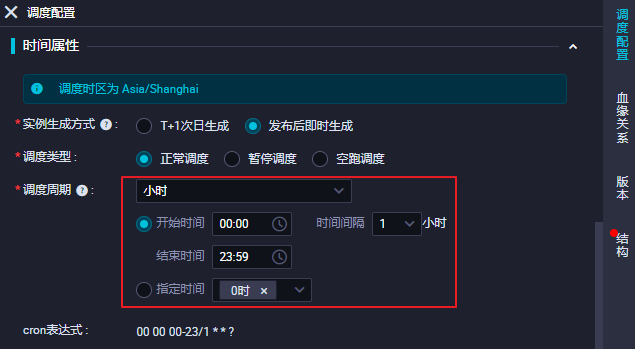
通過調度配置的時間屬性,配置節點生成周期實例的方式,實例調度周期與執行時間,是否支持重跑,任務執行超過多長時間自動退出等。 說明
本文示例設置 | |
用于配置任務發布至生產調度時使用的調度資源組。本文示例使用開通DataWorks時默認提供的Serverless資源組。詳情請參見新增和使用Serverless資源組。 | |
用于定義節點調度的上下游依賴關系。建議您根據血緣關系來設置節點依賴,通過上游任務執行成功來確定當前節點依賴的表數據已順利產出,當前節點可正常查詢該上游表數據。 說明
本文示例,假設 | |
用于定義節點上下游間的參數傳遞,實現下游節點通過參數獲取上游節點傳遞過來的取值。 |
步驟六:調試代碼
您可使用如下方式調試代碼邏輯,保障代碼編寫的正確性。
方式 | 使用說明 | 選擇建議 |
用于快速運行選中的代碼片段。 | 需要快捷運行代碼片段時,可選擇此方式。 | |
工具欄:運行( | 支持為代碼指定測試場景下的變量賦值常量。 說明 新建的節點第一次單擊運行時,需要您在彈框中手動為代碼中變量賦值常量,此次賦值會被記錄,下次操作無需再重復賦值。 | 若您需要頻繁調試全量代碼,可選擇此方式。 |
工具欄:高級運行( | 每次單擊此按鈕都需為指定測試場景下的變量賦值常量。 | 若您需要修改代碼中的變量賦值,可選擇此方式。 |
本文示例使用高級運行測試2022.09.07 14:00的運行結果。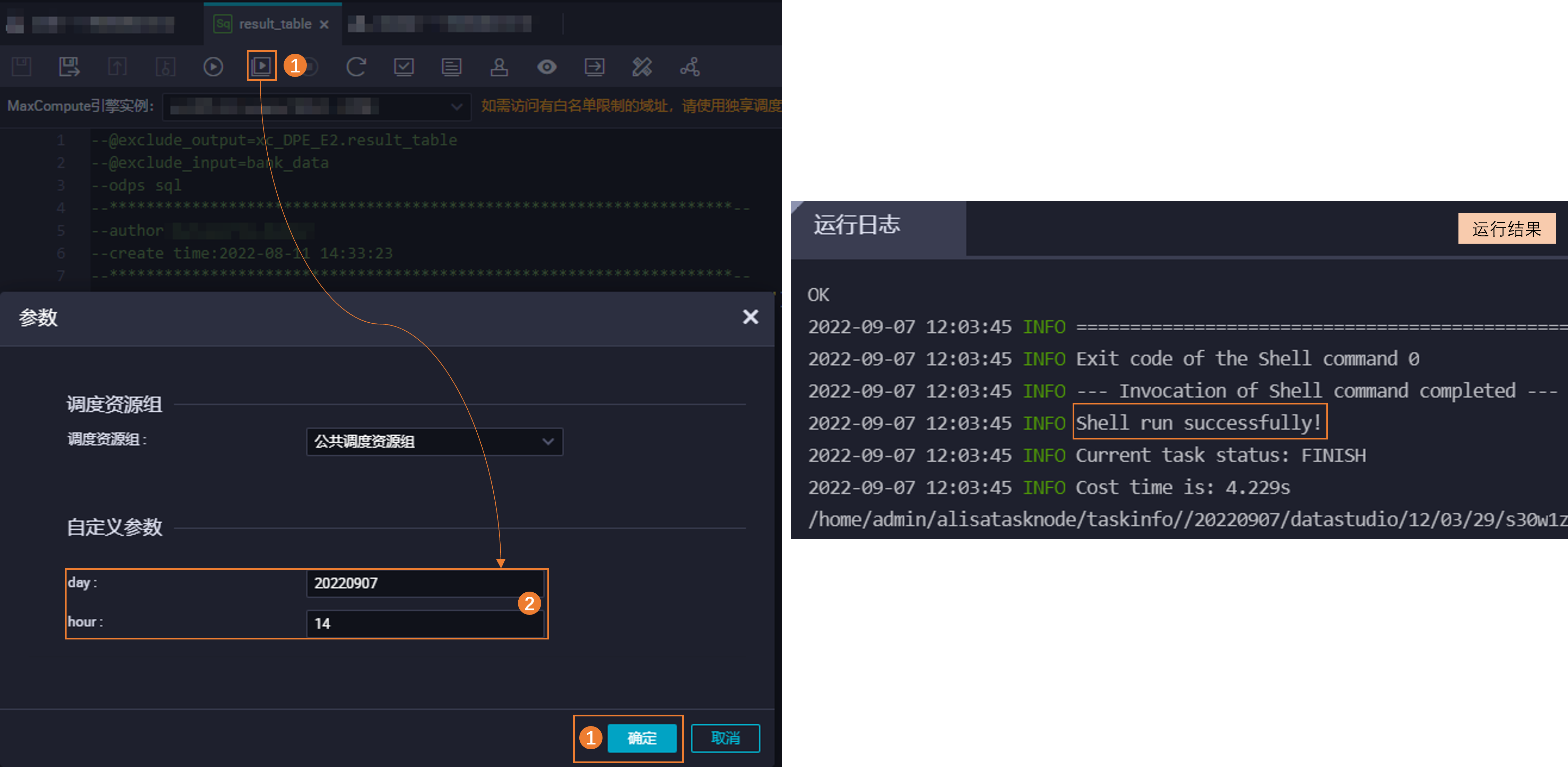
步驟七:保存并提交節點
節點配置并測試完成后,您需要保存節點配置,并提交節點至開發環境。
僅當節點在步驟五中配置了重跑屬性及依賴的上游節點后才可提交。
單擊工具欄的
 圖標,保存節點配置。
圖標,保存節點配置。單擊工具欄的
 圖標,提交節點至開發環境。
圖標,提交節點至開發環境。
步驟八:冒煙測試
為保障生產任務高效運行,避免計算資源浪費,建議您在任務發布前先對任務進行冒煙測試。冒煙測試需在開發環境執行,因此您需將節點提交至開發環境,提交后:
單擊工具欄中的
 圖標,在冒煙測試彈框配置業務日期。
圖標,在冒煙測試彈框配置業務日期。冒煙測試執行完成后,單擊工具欄的
 圖標,查看測試結果。
圖標,查看測試結果。
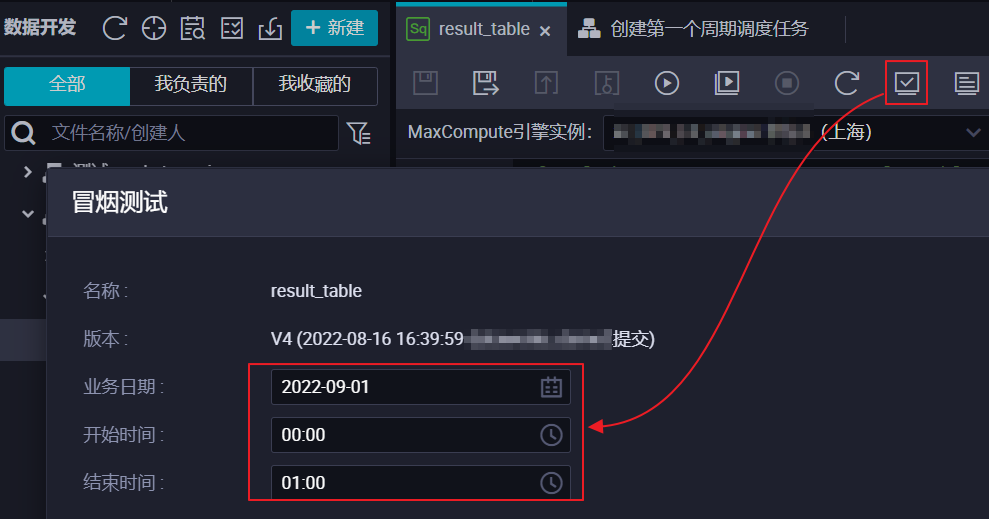
本文示例測試調度參數配置是否符合預期。result_table調度節點00:00到23:59每小時執行一次,因此下圖配置中將生成兩個小時實例,實例定時運行時間分別為00:00、01:00。
實例是周期任務根據調度周期運行時生成的任務快照。
由于
result_table節點設置為小時調度任務,除配置冒煙測試的業務日期外,您還需選擇運行哪一時間段的實例。更多冒煙測試介紹,詳情請參見執行冒煙測試。
步驟九:發布任務
若當前工作空間為簡單模式工作空間,任務提交后便可周期性調度;若當前工作空間為標準模式工作空間,任務提交后僅處于待發布狀態,您需參考該步驟將任務發布生產,發布后該任務才可進行周期性調度。
DataWorks僅支持自動調度發布生產環境的任務。因此,在冒煙測試無誤后,您需將任務發布至生產環境調度系統進行周期調度。
關于簡單模式與標準模式工作空間的說明,詳情請參見必讀:簡單模式和標準模式的區別。
在標準模式工作空間下,數據開發(DataStudio)界面提交的操作(包括數據開發節點、資源、函數的新增、更新、刪除等)都將進入任務發布界面等待發布。您需進入將相關操作通過發布流程發布至生產環境,發布后才可生效。發布詳情請參見發布任務。
發布流程相關說明如下。
發布相關 | 說明 |
發布流程管控 | 發布操作受角色權限和流程控制約束,執行發布操作后請確保發布包狀態為成功。 說明
|
發布生效時間控制 | 全量轉實例時間( 說明 該限制針對T+1次日生成和發布后即時生成實例生成方式均生效。實例生成方式,詳情請參見實例生成方式。 |
后續步驟
您可進入查看發布至生產環境的離線調度任務,并執行相關運維操作。詳情請參見周期任務基本運維操作。