數據保護傘基于敏感字段類型來配置敏感數據識別規則,規則配置完成后,即可用于識別租戶內相應類型的敏感數據。DataWorks為您提供了多種內置敏感字段類型及識別規則,若內置規則不滿足您的業務需要,您也可自定義敏感字段類型及識別規則。本文為您介紹如何新建敏感字段類型并配置數據識別規則。
背景信息
DataWorks支持您按照數據的敏感級別和所屬分類定義數據識別規則,幫助您識別組織內的敏感數據,對于識別結果不準確的數據,您可以手動修正數據,并在敏感數據概況模塊為您展示最近的通過數據識別規則命中的、按照項目細分的全部敏感字段分布情況,數據識別規則的使用邏輯如下圖所示。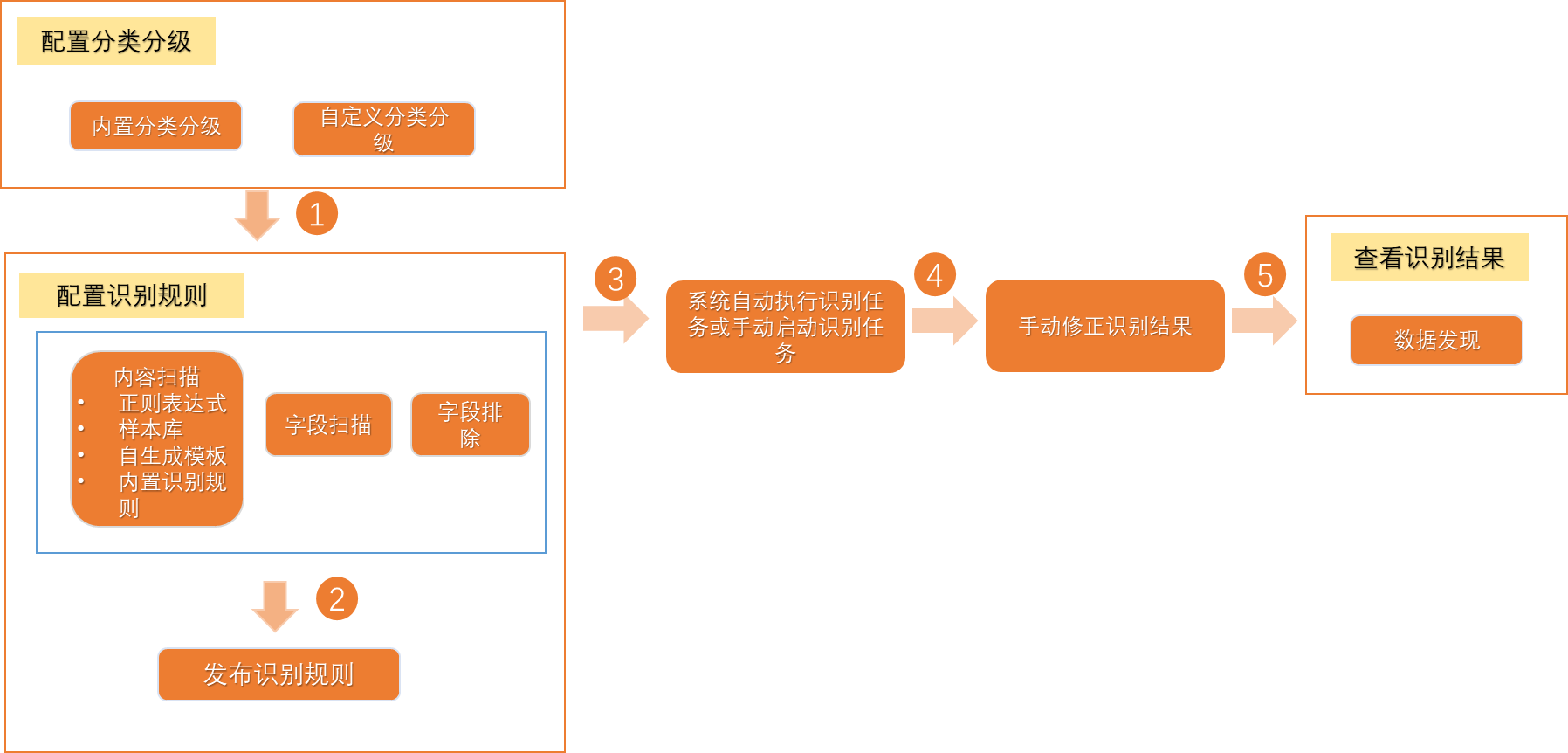
對CDH集群中的數據進行識別和脫敏時,您需要通過DataWorks的數據抽樣采集器功能,從CDH Hive表中隨機抽取表的部分數據用于數據保護傘的敏感數據識別,抽樣采集的數據不會存儲至DataWorks中,沒有數據泄漏風險。詳情請參見CDH Hive數據抽樣采集器。
進入數據識別規則頁面
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
單擊左上方的
 圖標,選擇,單擊立即體驗,進入數據保護傘。說明
圖標,選擇,單擊立即體驗,進入數據保護傘。說明若阿里云主賬號已授權,則直接進入數據保護傘的首頁。
若阿里云主賬號未授權,則進入數據保護傘的授權頁面。授權后才可使用保護傘的相關功能。
單擊左側導航欄的,進入數據識別規則頁面。
步驟一:配置敏感字段所屬分類
敏感字段類型需歸屬于某個數據分類下并定義相應的敏感級別。因此,新增敏感字段類型并配置敏感數據識別規則前,您需先完成敏感數據分類分級配置。
如果您是首次使用數據保護傘的新用戶,進入數據識別規則頁面后,會在左側區域展示內置分類分級模板的默認分類,您可輸入分類名稱進行搜索;也可單擊分類名稱后的
 圖標,執行添加同級分類、添加子分類、重命名和刪除分類等操作。
圖標,執行添加同級分類、添加子分類、重命名和刪除分類等操作。如果您是已使用過數據保護傘的老用戶,進入數據識別規則頁面后,您可在左側區域按需創建數據分類。
分類名稱必須唯一,僅支持中英文、數字,長度限制1~30個字符。
刪除分類時,請先確認該分類下是否有已發布的敏感字段識別規則。如果有,請將該分類下全部規則下架后再刪除。詳情請參見管理數據識別規則。
敏感數據分級配置,請參見配置敏感數據分類分級。
步驟二:配置敏感數據識別規則
敏感數據識別規則需基于敏感字段類型配置,本文以新增敏感字段類型并配置數據識別規則示例,介紹配置詳情。您也可基于平臺內置的敏感字段類型配置數據識別規則。
在數據識別規則頁面,單擊右上角的+敏感字段類型,新增敏感字段類型。
配置敏感字段類型的基本信息。
在基本信息頁簽,配置敏感字段的類型、分類分級等信息。
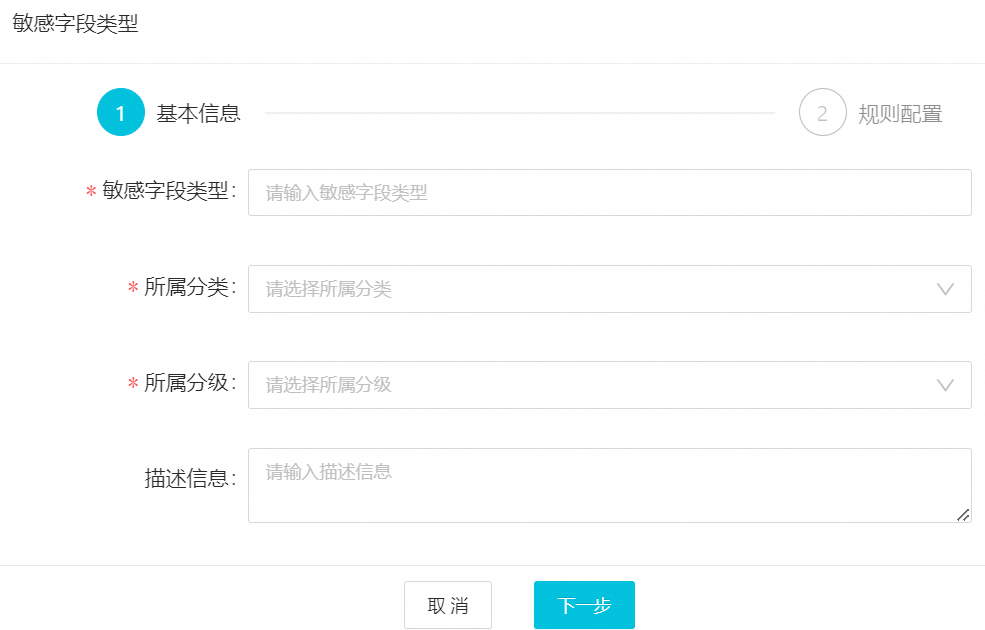
主要參數說明如下。
參數
描述
敏感字段類型
自定義敏感字段類型的名稱,例如:姓名、身份證號、手機號等。名稱必須唯一。
所屬分類
選擇敏感字段類型所屬的分類。若現有分類不滿足需求,請進入數據分類分級頁面進行設置,詳情請參見配置敏感數據分類分級。
所屬分級
選擇敏感字段類型所屬的級別,數字越大,敏感級別越高。若現有分級不滿足需求,請進入數據分類分級頁面進行設置,詳情請參見配置敏感數據分類分級。
單擊下一步。
配置敏感字段類型的識別規則。
在規則配置頁簽,配置敏感字段識別規則及規則的命中條件,并測試規則準確性。
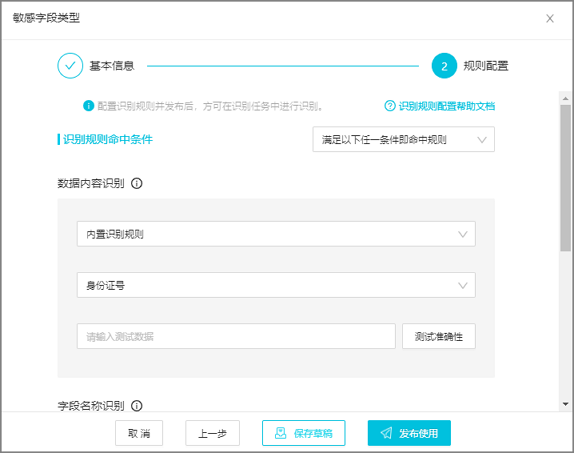
參數
描述
識別規則命中條件
在右側下拉列表中選擇識別規則的命中條件:
滿足以下任一條件即命中規則:滿足
數據內容識別或字段名稱識別中的任何一個條件,即可命中識別規則。同時滿足以下條件即命中規則:需同時滿足
數據內容識別和字段名稱識別的所有條件,才可命中識別規則。
說明識別規則命中條件僅對
數據內容識別和字段名稱識別規則生效。數據內容識別
用于識別字段的內容(即字段的取值)。例如,
name字段取值為張三,則規則將識別張三。說明僅DataWorks專業版及以上版本,才可使用內容掃描功能。若您使用的是低版本的DataWorks,請升級至專業版及以上版本。升級詳情,請參見DataWorks版本服務計費說明。
根據規則類型定義敏感數據識別規則的內容,用于匹配敏感數據文本。規則類型具體如下:
字段名稱識別
用于識別字段的名稱。例如,
name字段取值為張三,則規則將識別name。輸入需要識別為敏感數據的字段,支持多個字段匹配,各字段間為
或關系。不同數據源的輸入格式如下:EMR、CDH:
project.table.columnMaxCompute:
project.schema.table.column(schema不填則默認為default)。Hologres:
instance_id.project.table.column
輸入格式中,任意一段都可使用*作為通配符。例如:
a.b.*:表示a項目的b表中所有字段都會被識別為敏感數據。
ab*.c*.salary:表示ab開頭的項目中,c開頭的表的所有salary字段都會被識別為敏感數據。
*cd.ef*.sa*ry :表示cd結尾的項目下,ef開頭的表中,所有以sa開頭、ry結尾的字段都會被識別為敏感數據。
字段注釋識別
用于識別字段的注釋。例如,配置手機號類型敏感字段對應的字段注釋為手機號、聯系方式。當識別到某數據的注釋信息包含聯系方式時,該數據將被識別為手機號。
在輸入框中輸入字段注釋,字符長度0~100,字符不限,可添加多個輸入框,最多10個。
排除字段注釋識別
在輸入框中輸入需要排除的字段,符合字段排除規則的字段將不會被該識別規則命中。支持多個字段匹配,各字段間為
或關系。不同數據源的輸入格式如下:EMR、CDH:
project.table.columnMaxCompute:
project.schema.table.column(schema不填則默認為default)。Hologres:
instance_id.project.table.column
輸入格式中,任意一段都可使用*作為通配符。例如:
a.b.*:表示a項目的b表中所有字段都會被識別為敏感數據。
ab*.c*.salary:表示ab開頭的項目中,c開頭的表的所有salary字段都會被識別為敏感數據。
*cd.ef*.sa*ry :表示cd結尾的項目下,ef開頭的表中,所有以sa開頭、ry結尾的字段都會被識別為敏感數據。
命中率配置
用于自定義規則命中率,即配置一列數據中的非空數據,符合
數據內容識別條件的數據占比超過多少時(例如,50%),認為命中該識別規則。默認為50%。命中率的計算公式為:
100%*該列中命中識別規則的數據條數/該列數據的總條數。說明命中率僅對
數據內容識別規則生效。發布數據識別規則。
單擊發布使用,即可發布當前數據識別規則。規則發布后,才可使用該規則在識別任務中識別相應敏感數據。
若您暫時無需使用該規則,也可單擊保存草稿,保存數據識別規則。
若某列數據命中多個敏感字段類型的識別規則,規則的生效順序如下:
當這些敏感字段類型的命中條件僅個數相同時,識別順序為。
當這些敏感字段類型的命中條件個數和類型都相同時,優先命中分級等級高的敏感字段類型識別規則。
步驟三:授權并啟動敏感數據識別任務
敏感數據識別規則配置完成后,您需要授權并啟動敏感數據識別任務,啟動后,平臺才會基于敏感數據識別規則識別租戶內的敏感數據。
為敏感數據識別任務授權。
單擊敏感數據識別頁面左上方的開啟任務,按照界面指引授權。
說明敏感數據識別任務啟動后,單擊敏感數據識別頁面右上角的授權記錄,即可查看授權詳情。
啟動敏感數據識別任務。
配置敏感數據識別任務。
在開啟敏感數據識別任務對話框,配置任務類型、掃描方式及范圍。
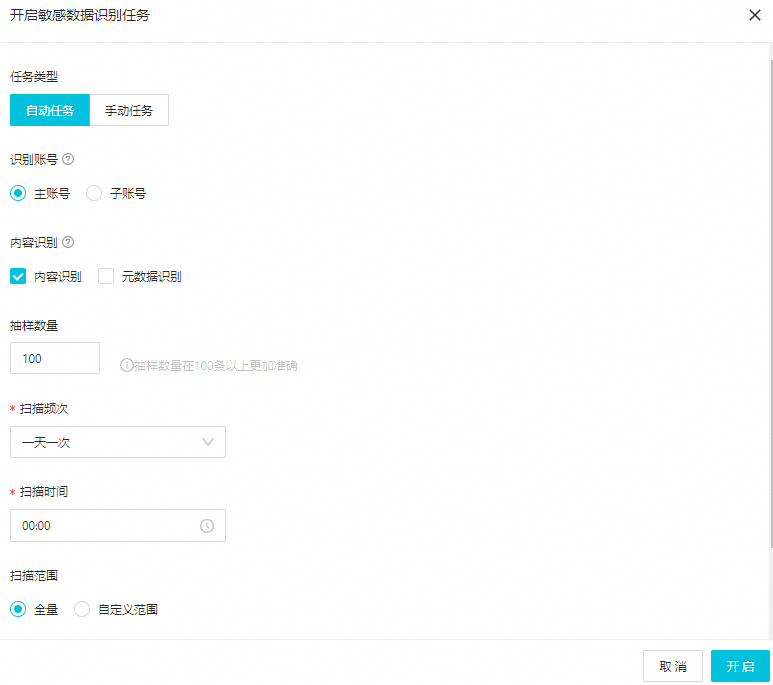
參數說明如下。
參數
描述
任務類型
選擇敏感數據識別任務的執行類型。
自動任務:啟動任務后,平臺將按照任務定義的掃描范圍及時間周期性自動執行。
手動任務:啟動任務后,平臺僅根據此次任務定義的掃描范圍進行數據掃描。該類型為一次性任務,任務執行完成,則本次任務結束。
識別賬號
配置通過主賬號或某個子賬號抽樣及掃描數據。賬號的權限不同,可抽樣及掃描的數據范圍存在差異。
內容識別
配置敏感數據識別規則中的內容識別及元數據識別是否生效。勾選后,相應規則才會生效。
說明若不勾選內容識別,則數據保護傘將不會對數據進行抽樣和掃描,敏感數據識別規則中的內容識別規則將不生效,但是字段名稱、字段注釋規則依然生效。
抽樣數量
配置內容識別的抽樣數量,建議數量大于100。
當勾選內容識別后,需配置該參數。
掃描頻次及掃描時間
定義自動任務的掃描周期。
僅當任務類型選擇自動任務時,需配置該參數。
掃描范圍
配置敏感數據識別任務掃描的數據范圍。
全量:掃描當前租戶所授權賬號下的全部數據。
自定義范圍:可選擇掃描指定項目空間下的表數據。
說明項目空間范圍默認為全部數據引擎的所有項目空間。
目前僅支持選擇掃描ODPS項目的指定表的數據。
表名總長度為
0~100,字符不限,不填代表掃描全部表。支持
.*通配符。例如,.*name表示以name為后綴;private.*表示以private為前綴。多個表名或字段名請用英文逗號(,)分隔。
單擊添加自定義范圍,即可添加多個自定義掃描范圍,最終掃描范圍取多個自定義范圍的并集。
單擊開啟,啟動掃描任務。
啟動后,任務狀態將變更如下:
手動任務:變更為任務進度條,待進度達到100%后表示任務掃描完成。進度計算方式為=(本次任務中已識別的表數量/本次任務中全部要識別的表數量)*100%。
自動任務:變更為開啟中。到達任務配置的掃描時間后,平臺將按照相關配置進行敏感數據識別。
說明識別規則修改后,新規則將在下一次自動任務(非實時)中啟用,若需要實時觸發新任務,您需要手動啟動任務。
掃描任務結束后,任務狀態將更新為無任務。
管理數據識別規則
復制規則:若您需快速復制已有規則,可單擊
 圖標。新生成的規則名稱默認添加后綴
圖標。新生成的規則名稱默認添加后綴-副本,且狀態為草稿,您可按需配置。編輯規則:若您需修改規則信息,可單擊
 圖標。說明
圖標。說明通過內置敏感字段類型配置的規則,不支持修改基本信息。
規則被修改后,歷史規則命中的字段識別結果將被清理。
刪除規則:若某規則后續無需再使用,可單擊
 圖標刪除。重要
圖標刪除。重要刪除某敏感數據類型的識別規則影響較大,請仔細閱讀以下影響后再確認是否刪除。
識別結果中該敏感字段類型的記錄將會刪除。詳情請參見手動修正數據。
數據發現中的敏感數據分布信息將不統計該敏感字段類型。詳情請參見敏感數據概況。
已配置的風險識別規則中有對應配置項的將會取消該敏感字段類型。詳情請參見風險識別管理(舊版)
批量發布規則:規則發布后,平臺才會使用該規則識別相應敏感數據。若規則較多,可通過批量功能發布。
在數據識別規則頁面,單擊批量發布,勾選需要發布的規則。
說明僅支持勾選草稿狀態的規則。
單擊發布。發布后,對應規則的狀態將置為已發布。
說明若無需發布,可單擊取消,該敏感字段即可恢復原始草稿狀態。
批量下架規則:下架對應規則后,平臺將不再進行該類敏感數據的識別。數據發現、手動修正數據等模塊中的該類敏感字段類型的記錄將會刪除。執行下架操作前,請確認該敏感字段類型的識別規則是否被數據脫敏規則及風險識別規則引用,若已使用,則需先將數據脫敏規則置為失效,并取消風險識別規則中的引用。詳情請參見創建數據脫敏規則和風險識別管理(舊版)。
在數據識別規則頁面,單擊批量下架,勾選需要下架的規則。
說明僅支持勾選已發布狀態的規則。
單擊下架。下架后,對應規則的狀態將置為草稿。
說明若無需下架,可單擊取消,該規則即可恢復原始已發布狀態。
后續操作:查看任務執行記錄
會保留近1周已完成任務的記錄(不包含當前正在進行中的記錄),您可查看任務的開始時間,結束時間,耗時,任務類型,責任人和數據范圍等詳情。