DataWorks的數據上傳功能支持將本地文件、數據分析的電子表格、OSS文件、HTTP文件等數據上傳至MaxCompute、EMR Hive、Hologres等引擎進行分析及管理,為您提供便捷的數據傳輸服務,助力您快速實現數據驅動業務。本文為您介紹如何使用數據上傳功能上傳數據。
注意事項
如您涉及跨境操作數據上傳(例如,數據從中國境內傳輸至中國境外、數據在不同國家/地區間傳輸等),請提前了解相關合規聲明,否則可能導致數據上傳失敗并將承擔相應法律責任。詳情請參見附錄:跨境操作數據上傳的合規聲明。
功能說明
數據上傳功能僅支持將本地文件、DataWorks數據分析的電子表格、阿里云對象存儲OSS、HTTP文件的數據上傳至MaxCompute、EMR Hive、Hologres引擎的表中。不同數據來源的規則要求如下:
本地文件:
支持
CSV、XLS、XLSX、JSON格式,CSV文件最大支持上傳的數據量為5GB,其他文件最大支持上傳的數據量為100MB。默認上傳文件的第一個Sheet。如需上傳某個文件的多個Sheet數據,則需將每個Sheet創建一個表格且作為表格的首個Sheet。
OSS:僅支持上傳與當前DataWorks工作空間同地域的Bucket數據。
使用限制
資源組限制:數據上傳功能需指定調度資源組和數據集成資源組。
上傳數據至MaxCompute引擎:
支持使用Serverless資源組(推薦)、舊版資源組(獨享調度資源組或獨享數據集成資源組),且需確保數據上傳任務使用的數據源與所選資源組網絡連通。
所選Serverless資源組和獨享資源組需綁定至待接收數據的表所在的DataWorks工作空間。
上傳數據至EMR Hive、Hologres引擎:
僅支持使用Serverless資源組(推薦)和獨享資源組(獨享調度資源組或獨享數據集成資源組),即必須在中為相應引擎配置Serverless資源組或獨享資源組。
所選資源組需綁定至待接收數據的表所在的DataWorks工作空間,且需確保數據上傳任務使用的數據源與所選資源組網絡連通。
說明通過數據分析配置引擎使用的資源組,請參見系統管理。
配置數據源與資源組網絡連通,請參見網絡連通方案。
配置獨享資源組綁定的歸屬工作空間,請參見使用獨享調度資源組、使用獨享數據集成資源組。
表限制:僅支持將目標數據上傳至自己名下的表(即您為表的Owner)。具體表現為以下場景:
計費說明
數據上傳會產生如下費用:
數據傳輸費用。
若涉及新建表,會收取計算和存儲費用。
以上費用均由引擎側收取,具體費用請參見相應引擎的計費文檔MaxCompute計費、Hologres計費、E-MapReduce計費。
前提條件
已創建所需引擎數據源,用于存放待上傳數據。后續您可在該數據源中進行相關數據的分析及管理操作。請按需創建MaxCompute數據源、EMR Hive數據源(阿里云實例模式)或Hologres數據源。
(可選)上傳阿里云對象存儲OSS數據,需滿足如下條件:
進入數據上傳
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
單擊左上角的
 圖標,選擇。
圖標,選擇。在上傳與下載頁面單擊左側導航欄的
 圖標,進入數據上傳頁面。
圖標,進入數據上傳頁面。單擊數據上傳,根據界面指引上傳目標數據。
上傳目標數據
DataWorks支持將本地文件數據、數據分析的電子表格數據、對象存儲OSS、HTTP文件數據上傳至MaxCompute、EMR Hive、Hologres引擎,不同數據的上傳配置存在差異,具體如下。
上傳本地文件數據
選擇待上傳數據。
數據來源:選擇本地文件。
指定待上傳數據:根據界面指引將本地文件拖拽至選擇文件區域,并設置是否需要剔除臟數據。
是:如遇臟數據,平臺會自動忽略,繼續上傳數據。
否:如遇臟數據,平臺不會自動忽略,此次數據上傳將被阻斷。
說明支持
CSV、XLS、XLSX、JSON格式,CSV文件最大支持上傳的數據量為5GB,其他文件最大支持上傳的數據量為100MB。默認上傳文件的第一個Sheet。如需上傳某個文件的多個Sheet數據,則需將每個Sheet創建一個表格且作為表格的首個Sheet。
臟數據:例如,文件里某個單元格的數據為字符串類型,但映射到了目標表的INT類型字段,則該行數據會寫入失敗,該行數據為臟數據。具體的臟數據請以平臺的實際判斷邏輯為準。
配置存放待上傳數據的目標表。
您可選擇將待上傳數據存放至目標引擎數據源的已有表或新建表。
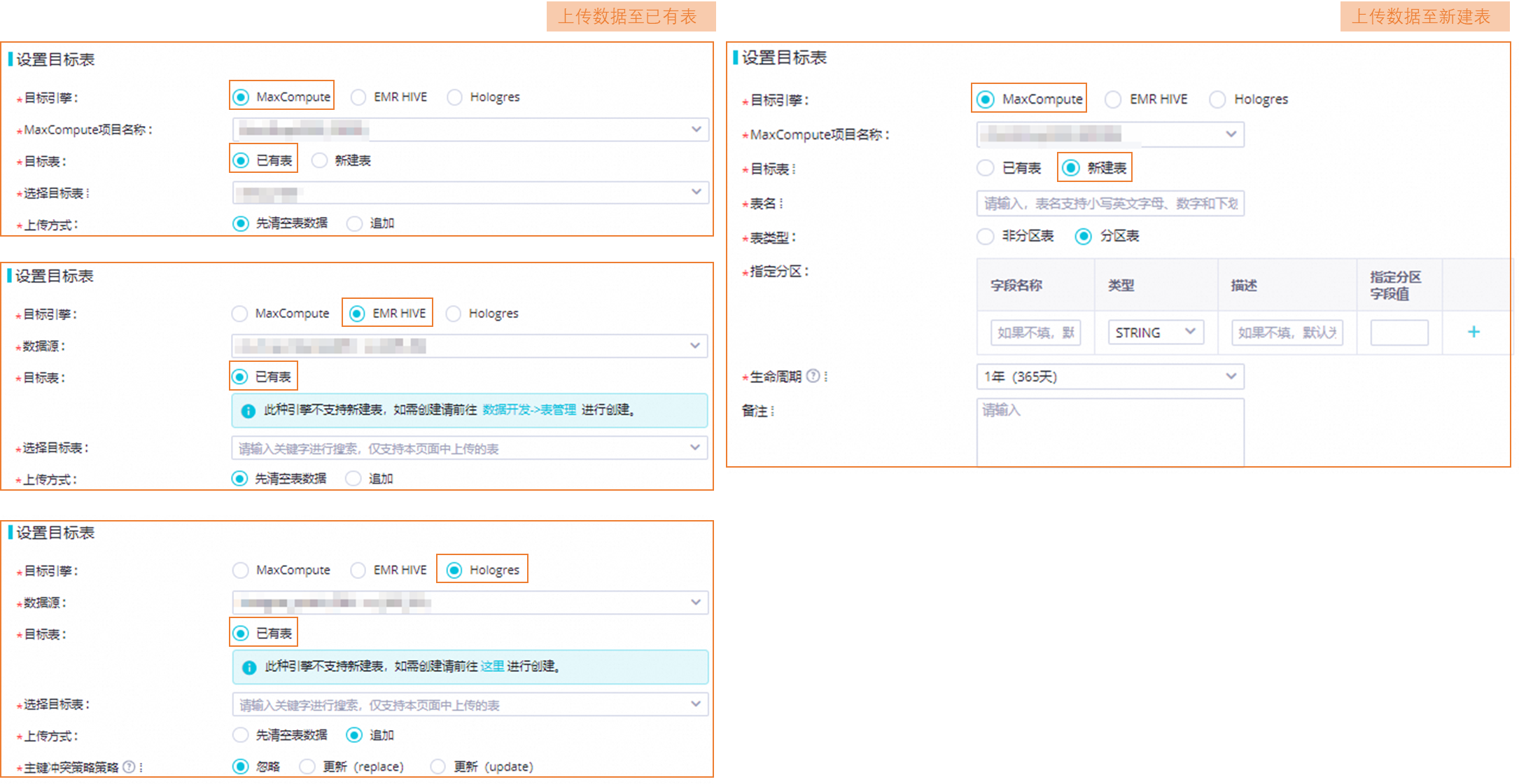
參數說明如下。
參數
描述
目標引擎
僅支持將數據上傳至MaxCompute、EMR Hive、Hologres引擎。
MaxCompute項目名稱或數據源
存放待上傳數據的項目或數據源,不同引擎需要配置的參數不同,具體參考實際界面。
說明EMR Hive僅支持選擇阿里云實例模式創建的數據源。
區分生產項目(PROD)及開發項目(DEV):
選擇生產項目:目標表僅支持選擇生產表。
選擇開發項目:目標表僅支持選擇開發表。
目標表(上傳數據至已有表)
選擇目標表:存放待上傳數據的表。支持通過關鍵字匹配搜索。
說明僅支持將目標數據上傳至自己名下的表(即您為表的Owner)。詳情請參見使用限制。
上傳方式:選擇以哪種方式將待上傳數據添加至目標表中。該參數需要與步驟3(配置的源文件與目標表的映射關系)配合使用。
先清空表數據:先清空目標表數據,再全量將數據導入至目標表中相應的映射字段。
追加:將待上傳數據追加至目標表相應映射字段中。
主鍵沖突策略:若上傳數據導致目標表主鍵沖突,可采取如下處理策略。
忽略:忽略上傳的數據,目標表中的數據不會更新。
更新(replace):上傳的數據會全量覆蓋目標表的舊數據,未配置列映射的字段強制寫為NULL。
更新(update):上傳的數據覆蓋目標表的舊數據,但僅覆蓋配置有列映射的字段數據。
說明僅Hologres引擎需要配置該參數。
目標表(上傳數據至新建表)
表名:自定義表名稱。
表類型:根據需要選擇非分區表或分區表。若選擇分區表,則需指定分區字段及其取值。
說明EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
MaxCompute引擎新建表過程,使用的是DataWorks數據源里面配置的MaxCompute賬號信息,然后在MaxCompute對應項目中進行建表操作。
預覽待上傳數據并設置目標表字段。
選擇待上傳數據及存放該數據的目標表后,您可預覽數據詳情,并配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。
說明目前僅支持預覽前20條數據。
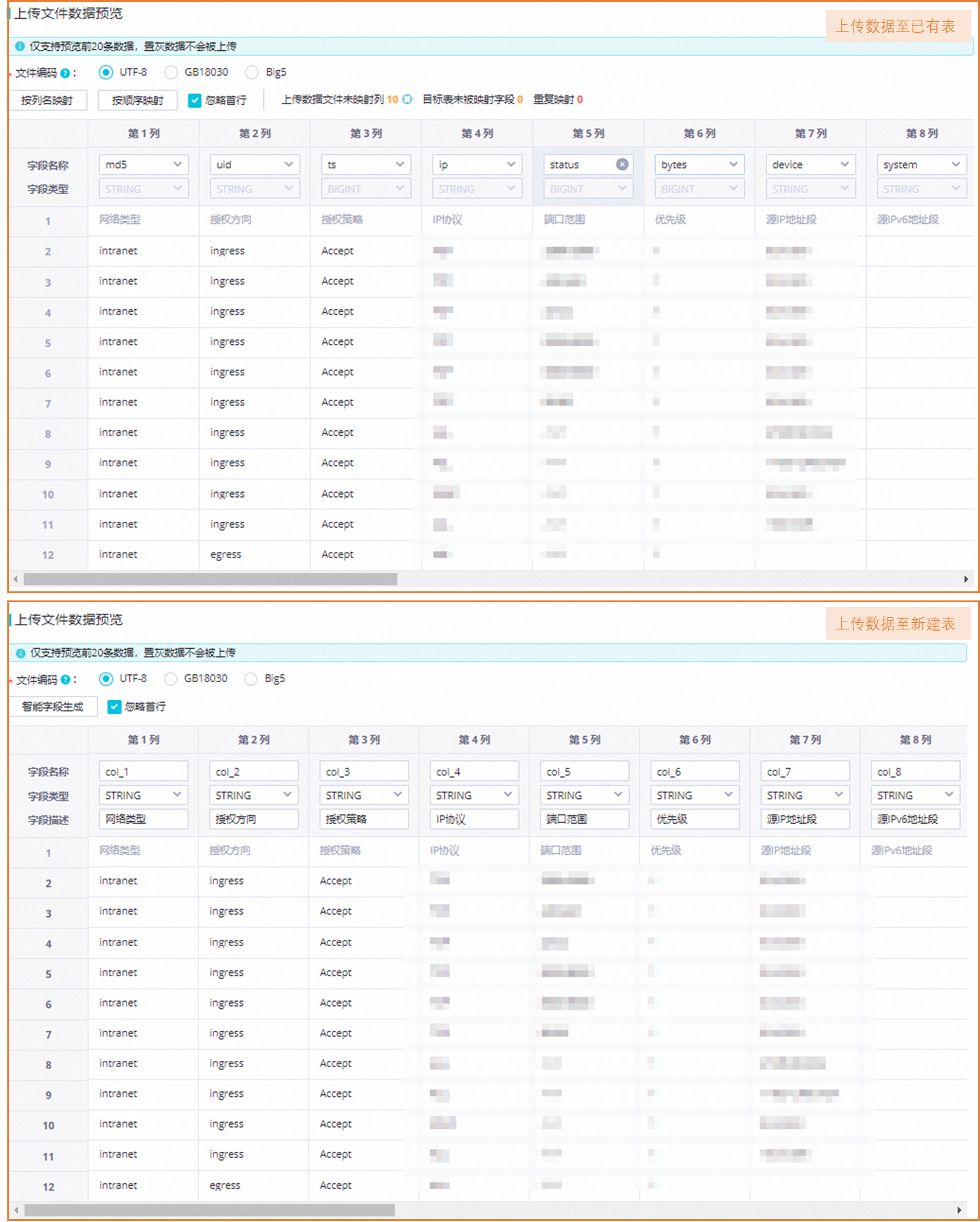 參數說明如下。
參數說明如下。參數
描述
預覽數據并設置目標表字段(上傳數據至已有表)
需配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。映射方式包括按列名映射及按順序映射。映射后您也可自定義目標表的字段名稱。
說明若待上傳數據與目標表字段不存在映射關系,則該數據將會被置灰,且不會被上傳。
待上傳數據與目標表字段不能存在重復映射關系。
字段名稱和字段類型不能為空,否則數據無法上傳。
預覽數據并設置目標表字段(上傳數據至新建表)
可通過智能字段生成自動填充字段信息,也可手動修改字段信息。
說明字段名稱和字段類型不能為空,否則數據無法上傳。
EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
文件編碼
若數據存在亂碼,則可切換編碼格式。支持選擇
UTF-8、GB18030、Big5。忽略首行
是否將文件數據的首行(通常為列名稱)上傳至目標表中。
勾選:文件首行不上傳至目標表中。
不勾選:文件首行將上傳至目標表中。
單擊數據上傳,開始上傳數據。
上傳數據分析電子表格數據
選擇待上傳數據。
數據來源:選擇電子表格。
指定待上傳數據:選擇已創建的電子表格,并設置是否需要剔除臟數據。
是:如遇臟數據,平臺會自動忽略,繼續上傳數據。
否:如遇臟數據,平臺不會自動忽略,此次數據上傳將被阻斷。
配置存放待上傳數據的目標表。
您可選擇將待上傳數據存放至目標引擎數據源的已有表或新建表。
參數說明如下。
參數
描述
目標引擎
僅支持將數據上傳至MaxCompute、EMR Hive、Hologres引擎。
MaxCompute項目名稱或數據源
存放待上傳數據的項目或數據源,不同引擎需要配置的參數不同,具體參考實際界面。
說明EMR Hive僅支持選擇阿里云實例模式創建的數據源。
區分生產項目(PROD)及開發項目(DEV):
選擇生產項目:目標表僅支持選擇生產表。
選擇開發項目:目標表僅支持選擇開發表。
目標表(上傳數據至已有表)
選擇目標表:存放待上傳數據的表。支持通過關鍵字匹配搜索。
說明僅支持將目標數據上傳至自己名下的表(即您為表的Owner)。詳情請參見使用限制。
上傳方式:選擇以哪種方式將待上傳數據添加至目標表中。該參數需要與步驟3(配置的源文件與目標表的映射關系)配合使用。
先清空表數據:先清空目標表數據,再全量將數據導入至目標表中相應的映射字段。
追加:將待上傳數據追加至目標表相應映射字段中。
主鍵沖突策略:若上傳數據導致目標表主鍵沖突,可采取如下處理策略。
忽略:忽略上傳的數據,目標表中的數據不會更新。
更新(replace):上傳的數據會全量覆蓋目標表的舊數據,未配置列映射的字段強制寫為NULL。
更新(update):上傳的數據覆蓋目標表的舊數據,但僅覆蓋配置有列映射的字段數據。
說明僅Hologres引擎需要配置該參數。
目標表(上傳數據至新建表)
表名:自定義表名稱。
表類型:根據需要選擇非分區表或分區表。若選擇分區表,則需指定分區字段及其取值。
說明EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
MaxCompute引擎新建表過程,使用的是DataWorks數據源里面配置的MaxCompute賬號信息,然后在MaxCompute對應項目中進行建表操作。
預覽待上傳數據并設置目標表字段。
選擇待上傳數據及存放該數據的目標表后,您可預覽數據詳情,并配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。
說明目前僅支持預覽前20條數據。
參數說明如下。參數
描述
預覽數據并設置目標表字段(上傳數據至已有表)
需配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。映射方式包括按列名映射及按順序映射。映射后您也可自定義目標表的字段名稱。
說明若待上傳數據與目標表字段不存在映射關系,則該數據將會被置灰,且不會被上傳。
待上傳數據與目標表字段不能存在重復映射關系。
字段名稱和字段類型不能為空,否則數據無法上傳。
預覽數據并設置目標表字段(上傳數據至新建表)
可通過智能字段生成自動填充字段信息,也可手動修改字段信息。
說明字段名稱和字段類型不能為空,否則數據無法上傳。
EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
文件編碼
若數據存在亂碼,則可切換編碼格式。支持選擇
UTF-8、GB18030、Big5。忽略首行
是否將文件數據的首行(通常為列名稱)上傳至目標表中。
勾選:文件首行不上傳至目標表中。
不勾選:文件首行將上傳至目標表中。
單擊數據上傳,根據界面指引上傳目標數據。
上傳對象存儲OSS數據
選擇待上傳數據。
數據來源:選擇阿里云對象存儲OSS。
指定待上傳數據:選擇已創建的Bucket文件,并設置是否需要剔除臟數據。
是:如遇臟數據,平臺會自動忽略,繼續上傳數據。
否:如遇臟數據,平臺不會自動忽略,此次數據上傳將被阻斷。
說明僅支持上傳與當前DataWorks工作空間同地域的Bucket數據。創建Bucket,詳情請參見創建存儲空間。
臟數據:例如,文件里某個單元格的數據為字符串類型,但映射到了目標表的INT類型字段,則該行數據會寫入失敗,該行數據為臟數據。具體的臟數據請以平臺的實際判斷邏輯為準。
配置存放待上傳數據的目標表。
您可選擇將待上傳數據存放至目標引擎數據源的已有表或新建表。
參數說明如下。
參數
描述
目標引擎
僅支持將數據上傳至MaxCompute、EMR Hive、Hologres引擎。
MaxCompute項目名稱或數據源
存放待上傳數據的項目或數據源,不同引擎需要配置的參數不同,具體參考實際界面。
說明EMR Hive僅支持選擇阿里云實例模式創建的數據源。
區分生產項目(PROD)及開發項目(DEV):
選擇生產項目:目標表僅支持選擇生產表。
選擇開發項目:目標表僅支持選擇開發表。
目標表(上傳數據至已有表)
選擇目標表:存放待上傳數據的表。支持通過關鍵字匹配搜索。
說明僅支持將目標數據上傳至自己名下的表(即您為表的Owner)。詳情請參見使用限制。
上傳方式:選擇以哪種方式將待上傳數據添加至目標表中。該參數需要與步驟3(配置的源文件與目標表的映射關系)配合使用。
先清空表數據:先清空目標表數據,再全量將數據導入至目標表中相應的映射字段。
追加:將待上傳數據追加至目標表相應映射字段中。
主鍵沖突策略:若上傳數據導致目標表主鍵沖突,可采取如下處理策略。
忽略:忽略上傳的數據,目標表中的數據不會更新。
更新(replace):上傳的數據會全量覆蓋目標表的舊數據,未配置列映射的字段強制寫為NULL。
更新(update):上傳的數據覆蓋目標表的舊數據,但僅覆蓋配置有列映射的字段數據。
說明僅Hologres引擎需要配置該參數。
目標表(上傳數據至新建表)
表名:自定義表名稱。
表類型:根據需要選擇非分區表或分區表。若選擇分區表,則需指定分區字段及其取值。
說明EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
MaxCompute引擎新建表過程,使用的是DataWorks數據源里面配置的MaxCompute賬號信息,然后在MaxCompute對應項目中進行建表操作。
預覽待上傳數據并設置目標表字段。
選擇待上傳數據及存放該數據的目標表后,您可預覽數據詳情,并配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。
說明目前僅支持預覽前20條數據。
參數說明如下。參數
描述
預覽數據并設置目標表字段(上傳數據至已有表)
需配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。映射方式包括按列名映射及按順序映射。映射后您也可自定義目標表的字段名稱。
說明若待上傳數據與目標表字段不存在映射關系,則該數據將會被置灰,且不會被上傳。
待上傳數據與目標表字段不能存在重復映射關系。
字段名稱和字段類型不能為空,否則數據無法上傳。
預覽數據并設置目標表字段(上傳數據至新建表)
可通過智能字段生成自動填充字段信息,也可手動修改字段信息。
說明字段名稱和字段類型不能為空,否則數據無法上傳。
EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
文件編碼
若數據存在亂碼,則可切換編碼格式。支持選擇
UTF-8、GB18030、Big5。忽略首行
是否將文件數據的首行(通常為列名稱)上傳至目標表中。
勾選:文件首行不上傳至目標表中。
不勾選:文件首行將上傳至目標表中。
單擊數據上傳,開始上傳數據。
上傳HTTP文件數據
選擇待上傳數據。
數據來源:選擇HTTP文件。
指定待上傳數據:文件地址選擇已創建的HTTP文件,文件類型會根據您所上傳的文件類型進行自動識別,您可在此選擇請求Method為GET、POST或PUT,并設置是否需要剔除臟數據。
是:如遇臟數據,平臺會自動忽略,繼續上傳數據。
否:如遇臟數據,平臺不會自動忽略,此次數據上傳將被阻斷。
說明您也可根據業務情況,在高級參數里面設置請求Header、請求Body信息。
配置存放待上傳數據的目標表。
您可選擇將待上傳數據存放至目標引擎數據源的已有表或新建表。
參數說明如下。
參數
描述
目標引擎
僅支持將數據上傳至MaxCompute、EMR Hive、Hologres引擎。
MaxCompute項目名稱或數據源
存放待上傳數據的項目或數據源,不同引擎需要配置的參數不同,具體參考實際界面。
說明EMR Hive僅支持選擇阿里云實例模式創建的數據源。
區分生產項目(PROD)及開發項目(DEV):
選擇生產項目:目標表僅支持選擇生產表。
選擇開發項目:目標表僅支持選擇開發表。
目標表(上傳數據至已有表)
選擇目標表:存放待上傳數據的表。支持通過關鍵字匹配搜索。
說明僅支持將目標數據上傳至自己名下的表(即您為表的Owner)。詳情請參見使用限制。
上傳方式:選擇以哪種方式將待上傳數據添加至目標表中。該參數需要與步驟3(配置的源文件與目標表的映射關系)配合使用。
先清空表數據:先清空目標表數據,再全量將數據導入至目標表中相應的映射字段。
追加:將待上傳數據追加至目標表相應映射字段中。
主鍵沖突策略:若上傳數據導致目標表主鍵沖突,可采取如下處理策略。
忽略:忽略上傳的數據,目標表中的數據不會更新。
更新(replace):上傳的數據會全量覆蓋目標表的舊數據,未配置列映射的字段強制寫為NULL。
更新(update):上傳的數據覆蓋目標表的舊數據,但僅覆蓋配置有列映射的字段數據。
說明僅Hologres引擎需要配置該參數。
目標表(上傳數據至新建表)
表名:自定義表名稱。
表類型:根據需要選擇非分區表或分區表。若選擇分區表,則需指定分區字段及其取值。
說明EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
MaxCompute引擎新建表過程,使用的是DataWorks數據源里面配置的MaxCompute賬號信息,然后在MaxCompute對應項目中進行建表操作。
預覽待上傳數據并設置目標表字段。
選擇待上傳數據及存放該數據的目標表后,您可預覽數據詳情,并配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。
說明目前僅支持預覽前20條數據。
參數說明如下。參數
描述
預覽數據并設置目標表字段(上傳數據至已有表)
需配置數據所在文件的列與目標表字段的映射關系,配置后相關數據才可被成功上傳。映射方式包括按列名映射及按順序映射。映射后您也可自定義目標表的字段名稱。
說明若待上傳數據與目標表字段不存在映射關系,則該數據將會被置灰,且不會被上傳。
待上傳數據與目標表字段不能存在重復映射關系。
字段名稱和字段類型不能為空,否則數據無法上傳。
預覽數據并設置目標表字段(上傳數據至新建表)
可通過智能字段生成自動填充字段信息,也可手動修改字段信息。
說明字段名稱和字段類型不能為空,否則數據無法上傳。
EMR Hive、Hologres引擎不支持在數據上傳新建表。您需在數據開發(DataStudio)新建表后,才可在數據上傳中選擇目標表。創建表,詳情請參見表管理。
文件編碼
若數據存在亂碼,則可切換編碼格式。支持選擇
UTF-8、GB18030、Big5。忽略首行
是否將文件數據的首行(通常為列名稱)上傳至目標表中。
勾選:文件首行不上傳至目標表中。
不勾選:文件首行將上傳至目標表中。
單擊數據上傳,開始上傳數據。
后續操作
數據上傳成功后,您可根據需要執行如下操作:
附錄:跨境操作數據上傳的合規聲明
如您涉及跨境操作數據上傳(例如,數據從中國境內傳輸至中國境外、數據在不同國家/地區間傳輸等),請提前了解相關合規聲明,否則可能導致數據上傳失敗并將承擔相應法律責任。
數據跨境操作將導致您的云上業務數據傳輸至您所選擇的區域或產品部署區域,您應確保相關操作遵循如下要求:
擁有相關云上業務數據的處理權限。
采取充分的數據安全保護技術及策略。
數據傳輸行為符合相關法律法規的要求。例如,傳輸的數據不含任何所適用法律限制、禁止傳輸或披露的內容。
阿里云特別提示您,若您的數據上傳操作可能導致數據跨境傳輸,請在開展相關操作前咨詢專業的法律或合規人員,確保數據跨境傳輸行為符合所適用的法律法規及監管政策的要求(例如,獲得個人信息主體的有效授權、完成相關合同條款的簽署及備案、完成相關安全評估等法定義務)。
若未遵守該合規聲明便開展數據跨境操作,您將承擔對應的法律后果。同時,導致阿里云及其關聯公司遭受的任何損失,您應承擔賠償責任。
相關文檔
DataStudio(數據開發)也支持上傳本地CSV文件或文本文件數據至MaxCompute表,詳情請參見上傳數據。
MaxCompute表的更多操作,請參見創建并使用MaxCompute表。
Hologres表的更多操作,請參見創建Hologres表。
EMR表的更多操作,請參見創建EMR表。