普通維度邏輯表用于描述實體對象,包含對實體對象的各方面描述。例如會員普通維度邏輯表,包含會員名稱、會員ID、會員郵件等數據。本文為您介紹如何創建并配置普通維度邏輯表。
使用限制
若您未購買數據標準模塊,不支持設置表中的數據標準字段。
若您未購買資產安全模塊,不支持設置表中的數據分級、數據分類字段。
若您未購買資產質量模塊,不支持實現主鍵字段的唯一和非空校驗。
前提條件
已完成業務實體的創建。更多信息,請參見創建并管理業務實體。
操作步驟
步驟一:創建普通維度邏輯表
在Dataphin首頁的頂部菜單欄中,選擇研發 > 數據研發。
在頂部菜單欄中選擇項目(Dev-Prod模式還需要選擇環境)。
在左側導航欄中需選擇規范建模 > 維度邏輯表。
在右側維度邏輯表列表中,單擊
 新建圖標。
新建圖標。在新建維度邏輯表對話框中,配置以下參數。
參數
描述
業務對象
選擇普通對象。
表類型
業務對象選擇普通對象,表類型為普通維度邏輯表,不支持修改。
數據板塊
默認為項目關聯的數據板塊,不支持修改。
主題域
默認為業務對象所在的主題域,不支持修改。
計算引擎
設置Dataphin實例為Hadoop計算引擎的租戶支持選擇計算引擎,包括Hive、Impala、Spark。
重要對應的計算引擎需要在開啟后,才可以支持進行選擇。更多信息,請參見創建Hadoop計算源。
當計算引擎為TDH 6.x或TDH 9.3.x時,不支持配置此項。
計算引擎存在以下限制,詳情如下:
Hive:不可讀取存儲為Kudu格式的來源表。
Impala:可讀取存儲為Kudu格式的來源表,暫不支持將邏輯表存儲為Kudu。如果沒有Kudu格式的來源表,不建議使用。
Spark:Spark不可讀取存儲為Kudu格式的來源表。
數據時效
數據時效用于定義后續該維度邏輯表的數據時效。普通維度邏輯表的數據時效支持選擇T+1(天表)、T+h(小時表)和T+m(分鐘表)。
說明ArgoDB、StarRocks計算引擎僅支持離線T+1(天表)。
邏輯表名
填寫邏輯表名,表名稱總長度需要在100個字符以內。選擇業務對象后,系統將自動填充邏輯表名,填充規則為
<數據板塊名稱>.dim_<業務對象編碼>_<數據時效>。重要僅允許填寫字母,數字和下劃線(_),且首位必須為字母,大小寫不敏感,輸入大寫字母時,系統將自動轉為小寫。
label_為系統保留前綴,不允許開頭為label_。AnalyticDB for PostgreSQL表名稱總長度需要在50個字符以內。
根據上述選擇的數據時效,
<數據時效>展示信息不同,詳細說明如下:df:T+1時效,日全量,每天存儲歷史截止當天的全量數據。
hf:T+h時效,小時全量,每小時存儲歷史截止當前小時的全量數據。
mf:T+m時效,分鐘全量,每15分鐘存儲歷史截止最近15分鐘的全量數據。
中文名稱
命名規則如下:
不能超過128個字符。
支持任何字符。
描述信息
填寫對維度邏輯表的簡單描述,1000個字符以內。
單擊確定,完成普通維度邏輯表創建。
步驟二:配置普通維度邏輯表字段信息
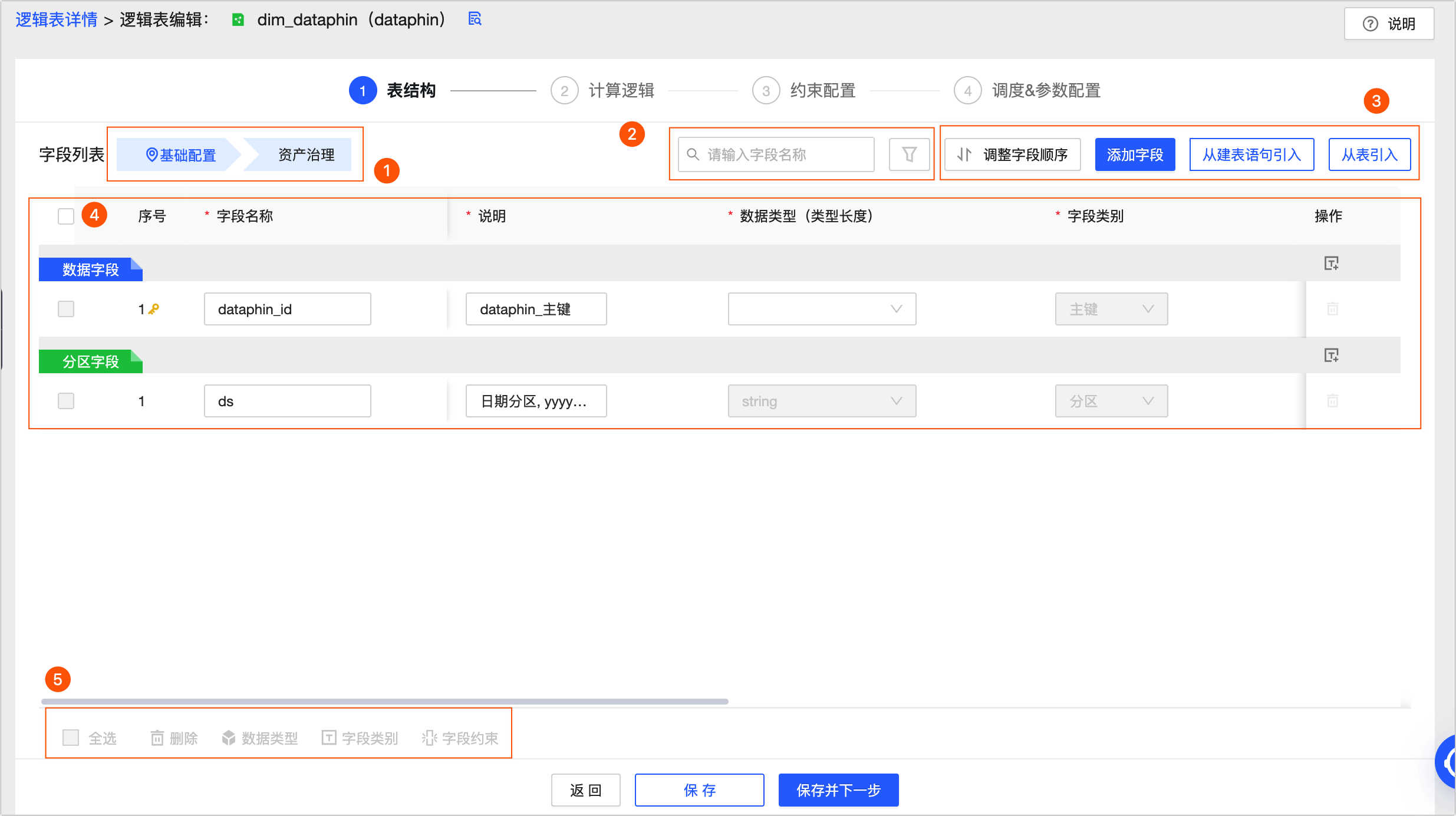
在表結構配置頁面配置當前普通維度邏輯表的表字段、數據類型、字段類別等結構信息。
 說明
說明單擊邏輯表名稱后的
 圖標,可查看邏輯表的基本信息。
圖標,可查看邏輯表的基本信息。區塊
說明
①表字段定位
單擊可定位字段列表的基本配置或資產治理配置。
②搜索與篩選
您可以通過表字段名稱搜索所需字段。
單擊
 可以根據數據類型、字段類別、有無關聯維度、關聯維度、字段約束、數據分級條件進行篩選。
可以根據數據類型、字段類別、有無關聯維度、關聯維度、字段約束、數據分級條件進行篩選。③字段列表操作
調整字段順序:調整字段順序前,請確保引用該邏輯表的下游沒有使用
select *查詢本邏輯表, 避免造成數據錯誤。引入字段:為表引入新字段。支持從建表語句引入和從表引入。具體操作,請參見為維度邏輯表引入字段。
添加字段:支持添加數據字段和分區字段,您可根據業務情況編輯字段的名稱、說明、數據類型、字段類別、關聯維度、字段標準、字段約束、數據分類、數據分級及備注信息。
說明MaxCompute引擎下支持創建不超過6級的分區字段。
ArgoDB、StarRocks計算引擎不支持添加分區字段。
④字段列表
字段列表為您展示字段的序號、字段名稱、說明、數據類型、字段類別、關聯維度、字段標準、字段約束、數據分類、數據分級及備注等字段的詳細信息。
序號:表字段序號。每新增1個字段,自增+1。
字段名稱:表字段名稱。您可輸入字段名稱或中文關鍵詞,將自動匹配標準預置的字段名。
說明:表字段說明信息,僅限填寫512個字符以內。
數據類型:支持string、bigint、double、timestamp、decimal、文本、數值、日期時間及其他數據類型。
字段類別:支持設置為主鍵、分區、屬性。
說明僅允許一個主鍵字段。
僅支持string、varchar、bigint、int、tinyint、smallint類型字段作為分區字段。
關聯維度:具體操作,請參見添加關聯維度。
字段標準:選擇字段的字段標準。如需創建標準,請參見新建和管理數據標準。
字段約束:選擇字段的字段約束。支持唯一和非空約束。
數據分類:選擇字段的數據分類。如需創建數據分類,請參見新建數據分類。
數據分級:選擇數據分類后,系統將自動識別數據級別。
備注:填寫字段的備注信息。僅限填寫2048個字符以內。
同時您可以在操作列下對字段進行刪除操作。
說明字段刪除后不可撤銷。
維度邏輯表主鍵和系統分區字段不支持刪除。
⑤批量操作
您可以批量選擇表字段,進行以下操作。
刪除:單擊
 圖標,批量刪除已經選中的數據字段。
圖標,批量刪除已經選中的數據字段。數據類型:單擊
 圖標,批量修改已經選中的數據類型。
圖標,批量修改已經選中的數據類型。字段類別:單擊
圖標,批量修改已經選中的字段類別。詞根命名:單擊
 圖標,系統將對字段的說明內容進行分詞并匹配已經創建的詞根,進行字段名稱推薦。您可以在詞根命名對話框中,將選中字段的名稱替換為修改后的值。如下圖所示:
圖標,系統將對字段的說明內容進行分詞并匹配已經創建的詞根,進行字段名稱推薦。您可以在詞根命名對話框中,將選中字段的名稱替換為修改后的值。如下圖所示: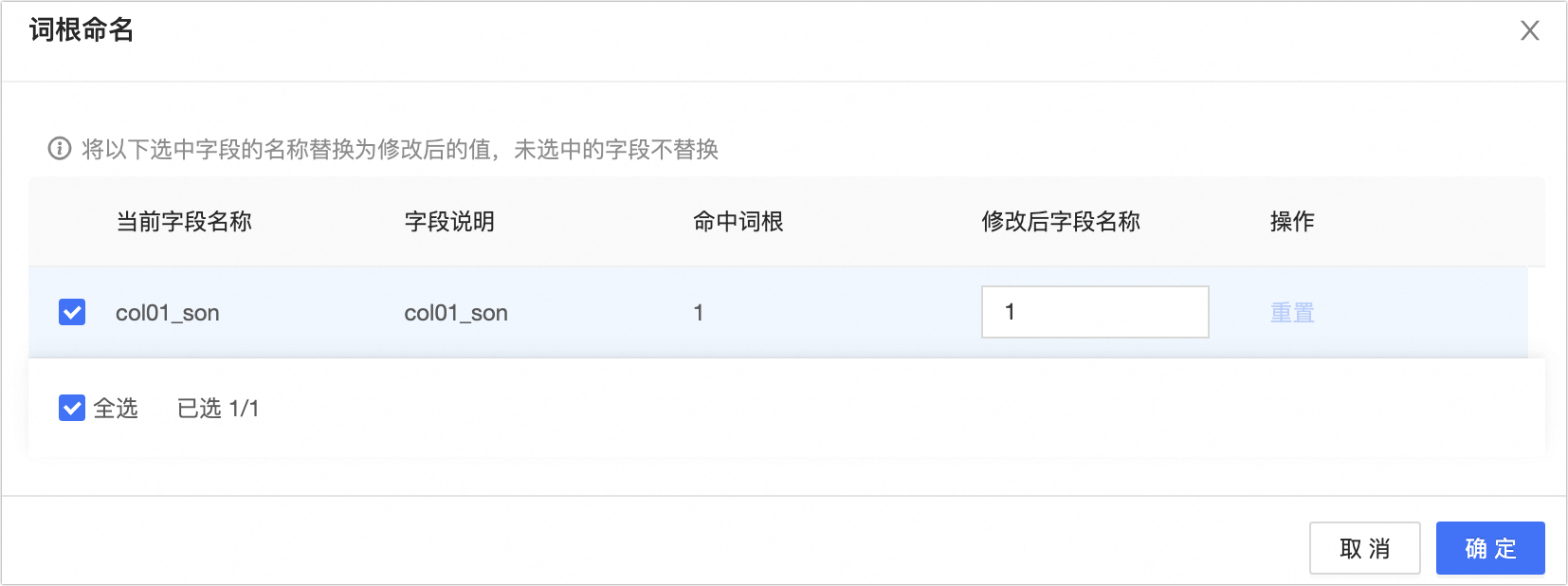 說明
說明若推薦的字段名稱均不滿足需求,您可以在修復后字段名稱輸入框中進行修改。
單擊重置將重置修改后字段名稱為系統的命中詞根。
字段標準:單擊
 圖標,系統將根據字段名稱進行字段標準推薦。您可以在字段標準對話框中,將字段設置為推薦的字段標準。
圖標,系統將根據字段名稱進行字段標準推薦。您可以在字段標準對話框中,將字段設置為推薦的字段標準。字段約束:單擊
 圖標,批量設置字段約束。重要
圖標,批量設置字段約束。重要子維度邏輯表不支持設置字段約束。
單擊保存并下一步。
為維度邏輯表引入字段
從表引入
在上述創建的維度邏輯表的配置頁面,單擊從表引入。
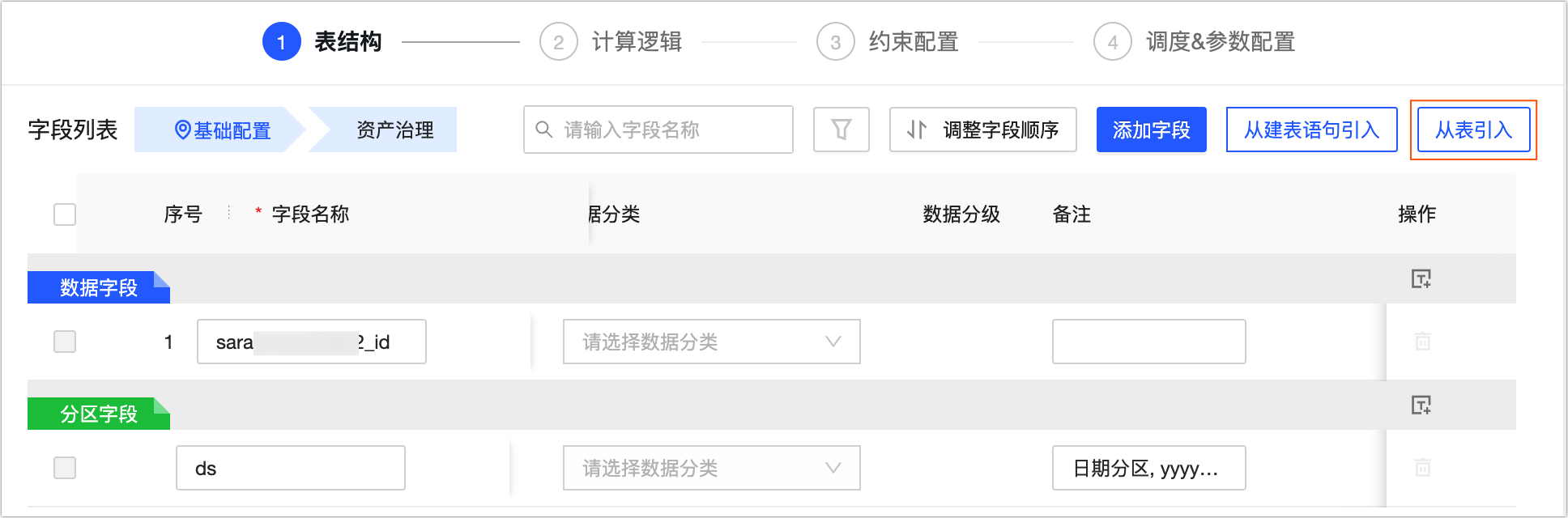
在從表引入對話框,選擇來源表后,選擇您所需添加的字段。
參數
描述
來源表
支持選擇當前租戶下所有具有讀取權限的物理表(非Dataphin自動生成的物理表)、邏輯表、視圖(非參數化視圖)。
如何獲取物理表的讀取權限,請參見申請、續期和交還表權限。
字段列表
選擇您需要添加的字段。
說明您可通過切換來源表方式選擇多個來源表中的字段。
已選擇字段
添加的字段將被添加到已選擇字段。您可對已選擇字段進行刪除操作。
單擊添加,為維度邏輯表引入某物理表的字段。
添加至新建字段區域后,您可以根據業務情況編輯字段的名稱、數據類型、字段類別及關聯維度。
從建表語句引入
在上述創建的維度邏輯表的配置頁面,單擊從建表語句引入。
在從建表語句引入對話框,填寫建表語句并單擊解析SQL。
在字段列表選擇您需要的字段,并單擊添加為維度邏輯表新建字段。
添加關聯維度
在維度邏輯表的配置頁面,單擊關聯維度列中的
 圖標,進入編輯模型關系對話框。
圖標,進入編輯模型關系對話框。在編輯模型關系對話框中,配置參數。
區塊
參數
描述
空值替換值
如果主表(當前維度邏輯表)和需要關聯的維度邏輯表關聯不上,則Dataphin自動對關聯字段補值為-110。
維度邏輯表
關聯實體、維度邏輯表
選擇您已創建的關聯實體和維度邏輯表。
編輯關聯邏輯
關聯邏輯
默認展示需要關聯維度的字段及關聯的維度邏輯表的主鍵,不支持修改。
維表版本策略
定義主表(當前維度邏輯表)與關聯維度邏輯表的分區,默認使用與當前維度邏輯表相同調度周期。更多說明如下:
使用同周期維度(主表與維表使用同周期分區):主表和關聯維度邏輯表計算時使用相同周期的時間分區。
例如,業務日期是20220101,需要查詢主表的ds=20220101分區的數據,同時關聯維度邏輯表的時間分區也是20220101,則就需要選擇為使用同周期維表。
使用最新維表(維表使用最新分區):數據計算時使用最新關聯維度邏輯表的最新分區。
例如,某商品類目經常會調整,10天前是手機類目,今天是電器類目。如果業務上需要按照電器類目重跑10天前的數據,則維表版本策略需要選擇為使用最新維表(維表使用最新分區)。
缺聯策略
缺聯策略用于定義來源主表(左表)中存在的字段,但在維度邏輯表(右表)中不存在的字段,即無法關聯的字段的計算邏輯。您可以選擇保留原始缺聯數據和缺聯數據使用默認值代替:
保留原始缺聯數據: 創建派生指標時,保留左表原始數據。
缺聯數據使用默認值代替:主表中的字段沒有與維度邏輯表關聯上,則使用默認值-110。
編輯維度角色
角色英文名、角色名稱
維度角色具有維度別名作用。多次引用同一維度時不可重名定義,起到角色扮演效果。您需要定義角色英文名和角色名稱:
角色英文名的前綴默認為
dim,自定義部分的命名規則為:包含字母、數字或下劃線(_)。
不能超過64個字符。
角色名稱的命名規則:
包含中文、數字、字母、下劃線(_)或短劃線(-)。
不能超過64個字符。
單擊確定。
步驟三:配置普通維度邏輯表計算邏輯
計算邏輯配置頁面用于配置維度邏輯表的來源數據與主鍵間的映射關系。
單擊來源配置,進入來源配置對話框并單擊+添加來源對象按鈕,配置來源參數。
說明建議不要在過濾條件或自定義SQL中額外設置對事件時間的過濾。
參數
描述
來源類型
支持物理表、自定義SQL、邏輯表三種來源類型。
來源表類型說明:
有主鍵來源表:有主鍵的邏輯表允許配置多個來源,第一個固定為主來源,邏輯表的數據總量(行數)由此來源決定。
無主鍵來源表:無主鍵的邏輯表僅允許配置一個來源,。若來源是多個表,請使用自定義SQL預先完成多表的關聯。
說明若您需要配置多個來源對象,您可單擊添加來源對象進行新增。
來源對象
選擇物理表:支持選擇當前租戶下所有具有讀取權限的物理表(非Dataphin自動生成的物理表)、物理視圖(非參數化視圖)。
如何獲取物理表的讀取權限,請參見申請、續期和交還表權限。
選擇自定義SQL:單擊
 圖標,在編輯框輸入內容,例如:
圖標,在編輯框輸入內容,例如:select id, name from project_name_dev.table_name1 t1 join project_name2_dev.table_name2 t2 on t1.id = t2.id選擇邏輯表:支持選擇當前租戶下所有具有讀取權限的邏輯表。
如何獲取物理表的讀取權限,請參見申請、續期和交還表權限。
重要使用邏輯表作為另一個邏輯表的數據來源, 會增加計算邏輯的復雜度和運維難度。
對象別名
自定義來源表別名。例如:t1,t2。
對象描述
請輸入對象的描述信息。僅1000個字符以內。
過濾條件
自定義SQL的過濾條件。
單擊
圖標,在編輯框輸入內容,例如:ds=${bizdate} and condition1=value1。關聯字段
來源對象中與邏輯表主鍵相對應的字段,與主鍵可以做等值關聯。
刪除
主來源不支持刪除。
無主鍵邏輯表,刪除來源將清空字段的計算邏輯。
單擊確定,完成來源配置。
完成來源配置后, 將來源字段拖入計算邏輯中,您也可以單擊同名字段快速映射按鈕,批量將數據來源字段置入同名的邏輯表字段的計算邏輯中。
單擊
 圖標,在編輯框中可以編輯計算邏輯表達式(表達式不支持聚合函數:sum,count,min等),例如:
圖標,在編輯框中可以編輯計算邏輯表達式(表達式不支持聚合函數:sum,count,min等),例如:示例1:
substr(t1.column2, 3, 10)示例2:
case when t1.column2 != '1' then 'Y' else 'N' end示例3:
t1.column2 + t2.column1
完成計算邏輯配置后,單擊底部
 圖標,可校驗表達式的有效性。
圖標,可校驗表達式的有效性。單擊預覽SQL按鈕,可查看計算邏輯SQL。
單擊保存并下一步。
步驟四:配置約束
基于字段約束, 系統將在質量模塊中為當前邏輯表創建質量規則。您可在此處設置字段的規則強度,包括強規則和弱規則。更多信息,請參見數據表質量規則。
說明邏輯表字段約束只可在此配置規則強度,不支持在質量模塊中編輯。
單擊保存并下一步。
步驟五:配置普通維度邏輯表調度
在調度&參數配置頁面,配置維度邏輯表的數據延遲、調度屬性、調度依賴、調度參數、運行配置。
參數
描述
數據延遲
開啟數據延遲,系統將自動重跑本邏輯表在最大延遲天數周期內的全部數據。詳細說明,請參見配置邏輯表數據延遲。
調度屬性
用于定義維度邏輯表在生產環境的調度方式。您可以通過調度屬性,配置維度邏輯表的調度類型、調度周期、調度邏輯與執行等等。詳情說明,請參見配置邏輯表調度屬性。
上游依賴
用于定義邏輯表在調度任務中的節點。Dataphin通過各個節點的調度依賴的配置結果,有序地運行業務流程中各個節點,保障業務數據有效、適時地產出。詳情說明,請參見配置邏輯表上游依賴。
參數配置
參數配置是對代碼中所用的變量進行賦值,從而支持節點調度時,參數變量可以自動被替換為相應的變量值。在調度參數配置頁面,您可以對參數配置進行忽略或轉為全局變量的操作。詳情說明,請參見邏輯表參數配置。
運行配置
您可根據業務場景為該維度邏輯表配置任務級的運行超時時間和任務運行失敗時的重跑策略,杜絕因計算任務長時間資源占用造成資源浪費的同時提高計算任務運行的可靠性。詳情說明,請參見邏輯表運行配置。
資源配置
您可為當前邏輯表任務配置調度資源組,邏輯表任務調度時將占用該資源組的資源配額。配置說明,請參見邏輯表資源配置。
單擊保存并提交。
步驟六:保存并提交邏輯表
完成普通維度邏輯表配置后,單擊保存并提交。
系統將對表結構、計算邏輯、調度依賴、運行參數進行配置校驗。您可根據未通過的檢查結果,檢查配置信息并完成配置。
檢查結果全部通過后,填寫提交備注,并單擊確定并提交。
提交時,Dataphin將進行任務的血緣解析及提交檢查。更多信息,請參見規范建模任務提交說明。
后續步驟
如果項目的模式為Dev-Prod,則您需要將邏輯表發布至生產環境。具體操作,請參見管理發布任務。
邏輯表發布至生產環境后,您可在運維中心查看并運維邏輯表任務。具體操作,請參見運維中心概述。