在DataHub發布的最新版本中,DataHub序列化相關的模塊進行了一次重大升級,在性能、成本、資源使用方面都有較大的優化,同時DataHub技術升級所帶來的成本紅利會輻射到每個用戶身上,根據我們實際的調研發現,大部分用戶的使用成本都可以達到30%以上的降幅,部分用戶使用成本降幅可以達到90%,本文將會詳細介紹這次改動的具體內容,以及相關的最佳實踐。
主要升級內容
1、支持zstd壓縮
zstd是一種高性能壓縮算法,由Facebook開發,并于2016年開源。zstd在壓縮速度和壓縮比兩方面都有不俗的表現,非常契合datahub的使用場景,因此datahub在新版本中對zstd壓縮算法做了支持,相較于DataHub目前支持的lz4和deflate壓縮算法,整體效果會好很多。
2、序列化改造
DataHub因為在設計上是存在TUPLE這種強schema結構的,我們最初為了防止臟數據,在服務端校驗了數據的有效性,這就導致了需要在服務端解析出來完整的數據,然后根據schema做個校驗,如果類型不匹配,那么會返回錯誤。隨著版本的迭代發展,我們我發現這樣的做法并沒有起到很有效的避免臟數據的效果(因為臟數據更多是業務層面的臟數據而不是數據類型),反倒是給服務端增加了巨大的cpu開銷,同時讀寫延遲也更大。
歷史經驗告訴我們,讀寫操作在服務端感知用戶的數據內容是一個相對冗余的操作,所以我們讓數據使用一個大的buffer來交互,不再去感知真正的數據內容,真正需要用到數據內容的地方再解析出來(例如同步任務),寫入時的數據校驗全部推到客戶端上來做,實際上客戶端本來就有校驗的,所以對客戶端而言其實并沒有增加開銷,然后服務端通過crc校驗來保證數據buffer的正確性,這樣既節省了服務端的資源消耗,也提供了更好的性能。
這個就是我們引入的batch序列化,batch序列化本質上就是DataHub數據傳輸中數據的定義的一種組織方式,batch并不是特指某種序列化的方式,而是對序列化的數據做了一個二次封裝,比如我一次發送100條數據,那我把這100條數據序列化后得到一個buffer,給這個buffer選擇一個壓縮算法得到壓縮后的buffer,這個時候給這個壓縮后的buffer添加一個header記錄這個buffer的大小、數據條數、壓縮算法、crc等信息,這個時候就是一條完整的batch的buffer。
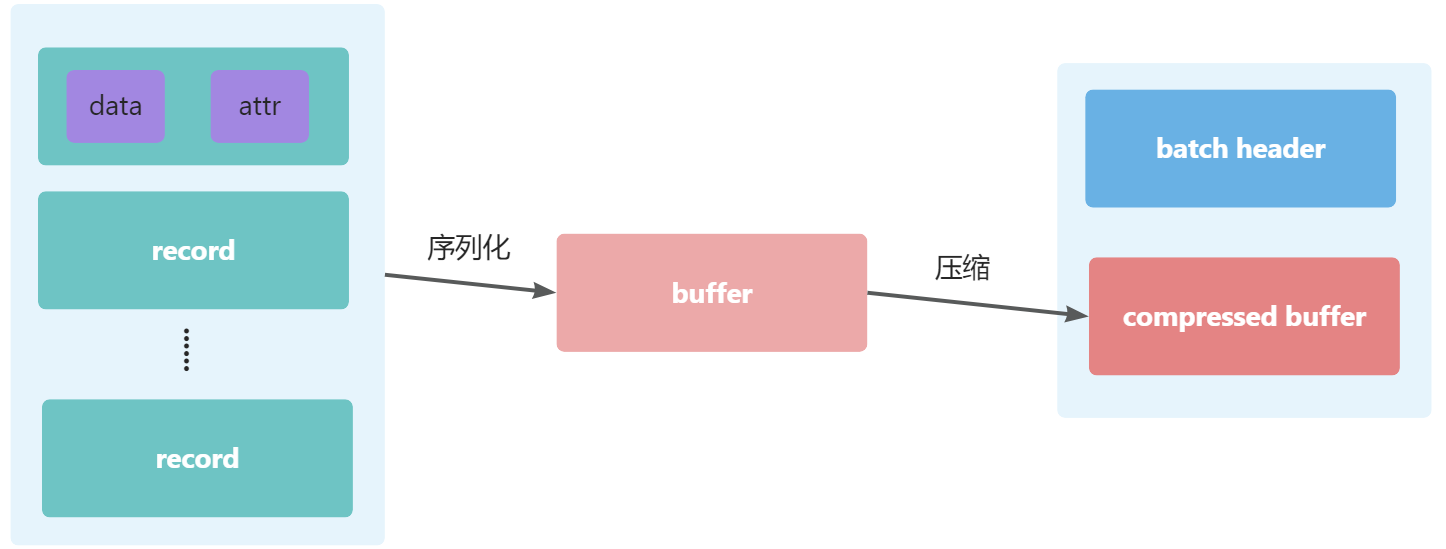
這個batch的buffer發送到服務端后,因為客戶端已經做了充分的數據有效性的校驗,所以服務端只檢驗一下數據中的crc確認為有效buffer后,便可以直接落盤,省去了序列化反序列化、加解壓以及校驗的操作,服務端性能提升超過80%,因為是多條數據一起壓縮的,所以壓縮率也提高了,存儲成本也降低了。
主要費用對比
為了驗證batch所帶來的實際效果,我們拿一些數據進行了對比測試
測試數據為廣告投放相關的數據,大約200列,數據中null比例大約20%~30%
1000條數據一個batch
batch內部的序列化使用的是avro
lz4是之前版本默認的壓縮算法,壓縮使用zstd來替代lz4
測試結果如下表所示
數據原大小(Byte) | lz4壓縮(Byte) | zstd壓縮(Byte) | |
protobuf序列化 | 11,506,677 | 3,050,640 | 1,158,868 |
batch序列化 | 11,154,596 | 2,931,729 | 1,112,693 |
就以上面的測試結果為準,我們可以評估一下從費用角度來評估一下使用batch后可以節省多少,根據線上的運行情況來看,之前一般都是lz4的壓縮居多,所以我們就假設由protobuf+lz4替換到了batch+zstd。費用就從存儲和流量兩個角度來考慮,因為Datahub的收費項主要是這兩個維度,其他主要是為了防止濫用而設置的懲罰性質的收費項,正常使用情況下可以直接忽略不計。
從存儲成本上來看,Datahub的protobuf序列化是沒有存儲壓縮的(只是http傳輸環節壓縮),如果替換為batch+zstd,那么存儲會由11506KB,降為1112KB,也就是說,存儲成本下降幅度達到約90%!
從流量成本上來看,Datahub的protobuf+lz4后的大小為3050KB,batch+zstd的大小為1112KB,也就是說,流量成本會降低約60%!
以上為樣本數據測試結果,不同數據測試效果有差異,請您根據您業務實際情況進行測試。
如何使用
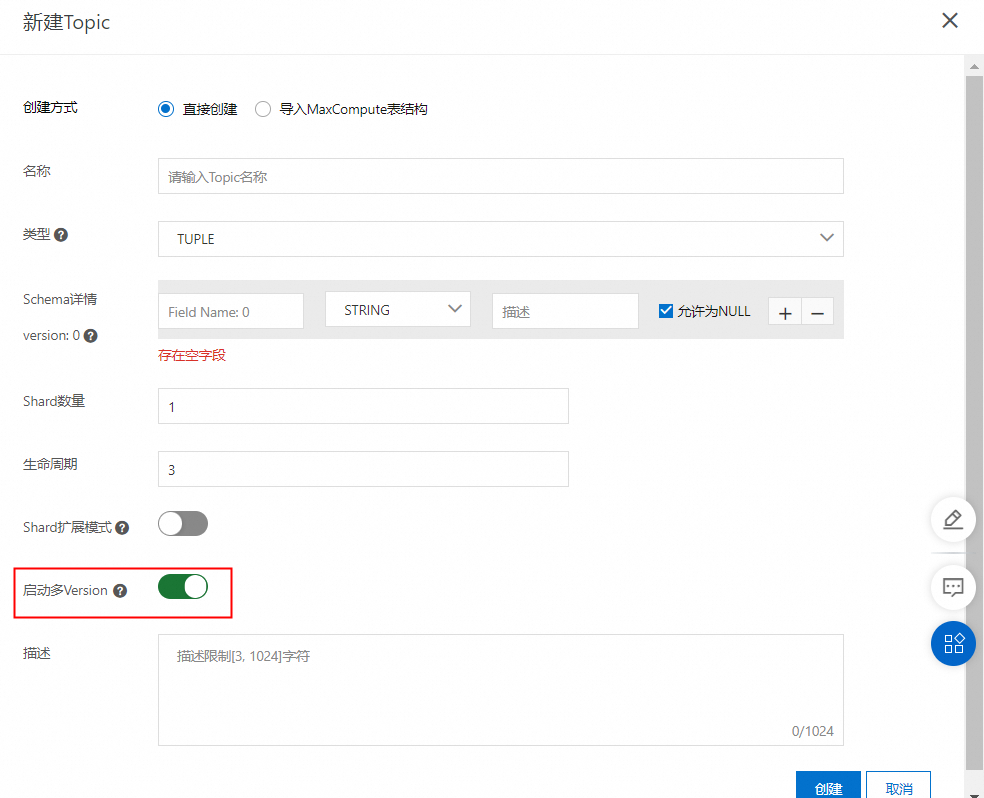
只有開啟了多version的才能使用batch
多version示例:
控制臺開啟示例:
新建Topic時點擊啟動多Version 按鈕開啟
SDK開啟示例:
public static void createTopicWithOption() {
try {RecordSchema recordSchema = new RecordSchema() {{
this.addField(new Field("field1", FieldType.STRING));
this.addField(new Field("field2", FieldType.BIGINT));
}};
TopicOption option = new TopicOption();
//開啟多version
option.setEnableSchemaRegistry(true);
option.setComment(Constant.TOPIC_COMMENT);
option.setExpandMode(ExpandMode.ONLY_EXTEND);
option.setLifeCycle(Constant.LIFE_CYCLE);
option.setRecordType(RecordType.TUPLE);
option.setRecordSchema(recordSchema);
option.setShardCount(Constant.SHARD_COUNT);
datahubClient.createTopic(Constant.PROJECT_NAME, Constant.TOPIC_NAME, option);
LOGGER.info("create topic successful");
} catch (ResourceAlreadyExistException e) {
LOGGER.info("topic already exists, please check if it is consistent");
} catch (ResourceNotFoundException e) {
// project not found
e.printStackTrace();
throw e;
} catch (DatahubClientException e) {
// other error
e.printStackTrace();
throw e;
}
}本文使用Java為例,介紹batch如何使用。
使用batch要求使用client-library 1.4及以上的版本,如果服務端已經支持,DataHub會默認使用batch,服務端沒有支持(例如服務端還未升級到新版本或者專有云較老的版本),那么會自動回退到原來的序列化方式,客戶端自適應,用戶無需增加額外配置。下面已1.4.1版本為例給出一個簡單示例。壓縮算法也會自適應選擇一個較優的方案,目前1.4版本以后會默認選擇zstd算法。
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.25.3</version>
</dependency>
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>datahub-client-library</artifactId>
<version>1.4.3</version>
</dependency>ProducerConfig config = new ProducerConfig(endpoint, accessId, accessKey);
DatahubProducer producer = new DatahubProducer(projectName, topicName, config);
RecordSchema schema = producer.getTopicSchema();
List<RecordEntry> recordList = new ArrayList<>();
// 為了達到更好的性能,建議在RecordList中添加盡可能多的Record;
// 盡可能使整個RecordList大小為512KB~1M
for (int i = 0; i < 1000; ++i) {
RecordEntry record = new RecordEntry();
TupleRecordData data = new TupleRecordData(schema);
// 假設schema為 {"fields":[{"name":"f1", "type":"STRING"},{"name":"f2", "type":"BIGINT"}]}
data.setField("f1", "value" + i);
data.setField("f2", i);
record.setRecordData(data);
// 添加用戶自定義屬性,可選
record.addAttribute("key1", "value1");
recordList.add(record);
}
try {
// 循環寫入1000遍
for (int i = 0; i < 1000; ++i) {
try {
String shardId = datahubProducer.send(recordList);
LOGGER.info("Write shard {} success, record count:{}", shardId, recordList.size());
} catch (DatahubClientException e) {
if (!ExceptionChecker.isRetryableException(e)) {
LOGGER.info("Write data fail", e);
break;
}
// sleep重試
Thread.sleep(1000);
}
}
} finally {
// 關閉producer相關資源
datahubProducer.close();
}注意事項
batch寫入最大的優勢需要充分攢批,如果客戶端無法攢批,或者攢批的數據較少,可能帶來的效果提升并不顯著。
為了讓用戶遷移更加方便,我們在各種讀寫方式之間做了兼容,保證用戶中間狀態可以更平滑的過渡,即batch寫入的依舊可以使用原方式讀取,原方式寫入依舊可以使用batch讀取。所以在寫入端更新為batch寫入之后,最好消費端也更新為batch,寫入和消費不對應反倒會降低性能。
目前只有Java的SDK支持了batch寫入,其他語言的客戶端和相關云產品(如Flink、數據集成等)仍在努力開發中,如果您想要盡快切換到batch寫入,可以直接提需求給我們。
總結
本文介紹了DataHub新版本帶來的改動,其中介紹了batch的原理和實現,以及使用batch后所帶來的性能的提升和費用的減少。切換為batch后,對于DataHub而言,服務端的資源消耗會明顯降低,同時,性能會明顯提升,使用費用也會大幅降低,所以是一個服務側和用戶側同時受益的改動。如果您在使用中有任何問題或者疑問,歡迎提工單聯系我們或者加入用戶群來提問,群號:33517130。