Spark/Hive/HDFS使用JindoSDK訪問OSS-HDFS服務
本文介紹如何通過在CDP集群中部署JindoSDK(4.5.0),訪問OSS-HDFS服務相關操作。
背景信息
OSS-HDFS服務是一款云原生數據湖存儲產品,基于統一的元數據管理能力,在完全兼容HDFS文件系統接口的同時,提供充分的POSIX能力支持,能更好的滿足大數據和AI領域豐富多樣的數據湖計算場景,詳細信息請參見OSS-HDFS服務概述。
前提條件
已創建CDP環境。具體步驟,請參見創建CDP運行環境。
操作流程
步驟一:開啟OSS-HDFS
步驟二:獲取HDFS服務域名
步驟三:在CDP集群中使用OSS-HDFS
步驟一:開啟OSS-HDFS
開通并授權訪問OSS-HDFS服務,具體操作請參見開通并授權訪問OSS-HDFS服務。
步驟二:查看HDFS服務域名(endpoint)
在OSS管理控制臺的概覽頁面,可以查看HDFS服務的域名

步驟三:在CDP集群中使用OSS-HDFS
登錄CDP集群服務器
下載并解壓JindoSDK JAR包。
執行以下命令,下載4.5.0版本JindoSDK JAR包。
wget https://jindodata-binary.oss-cn-shanghai.aliyuncs.com/release/4.5.0/jindosdk-4.5.0.tar.gz解壓JindoSDK JAR包。
sudo tar zxvf jindosdk-4.5.0.tar.gz -C /usr/lib/
將已下載的JindoSDK JAR包安裝到class path下(所有節點都要執行)
#hadoop sudo cp /usr/lib/jindosdk-4.5.0/lib/*.jar /opt/cloudera/parcels/CDH/lib/hadoop/lib/ #spark sudo cp /usr/lib/jindosdk-4.5.0/lib/*.jar /opt/cloudera/parcels/CDH/lib/spark/jars/ #hive sudo cp /usr/lib/jindosdk-4.5.0/lib/*.jar /opt/cloudera/parcels/CDH/lib/hive/auxlib/在CM管控core-site.xml中配置OSS-HDFS服務實現類及AccessKey。
<configuration> <property> <name>fs.AbstractFileSystem.oss.impl</name> <value>com.aliyun.jindodata.oss.JindoOSS</value> </property> <property> <name>fs.oss.impl</name> <value>com.aliyun.jindodata.oss.JindoOssFileSystem</value> </property> <property> <name>fs.oss.accessKeyId</name> <value>LTAI5t7h6SgiLSganP2m****</value> </property> <property> <name>fs.oss.accessKeySecret</name> <value>KZo149BD9GLPNiDIEmdQ7d****</value> </property> </configuration>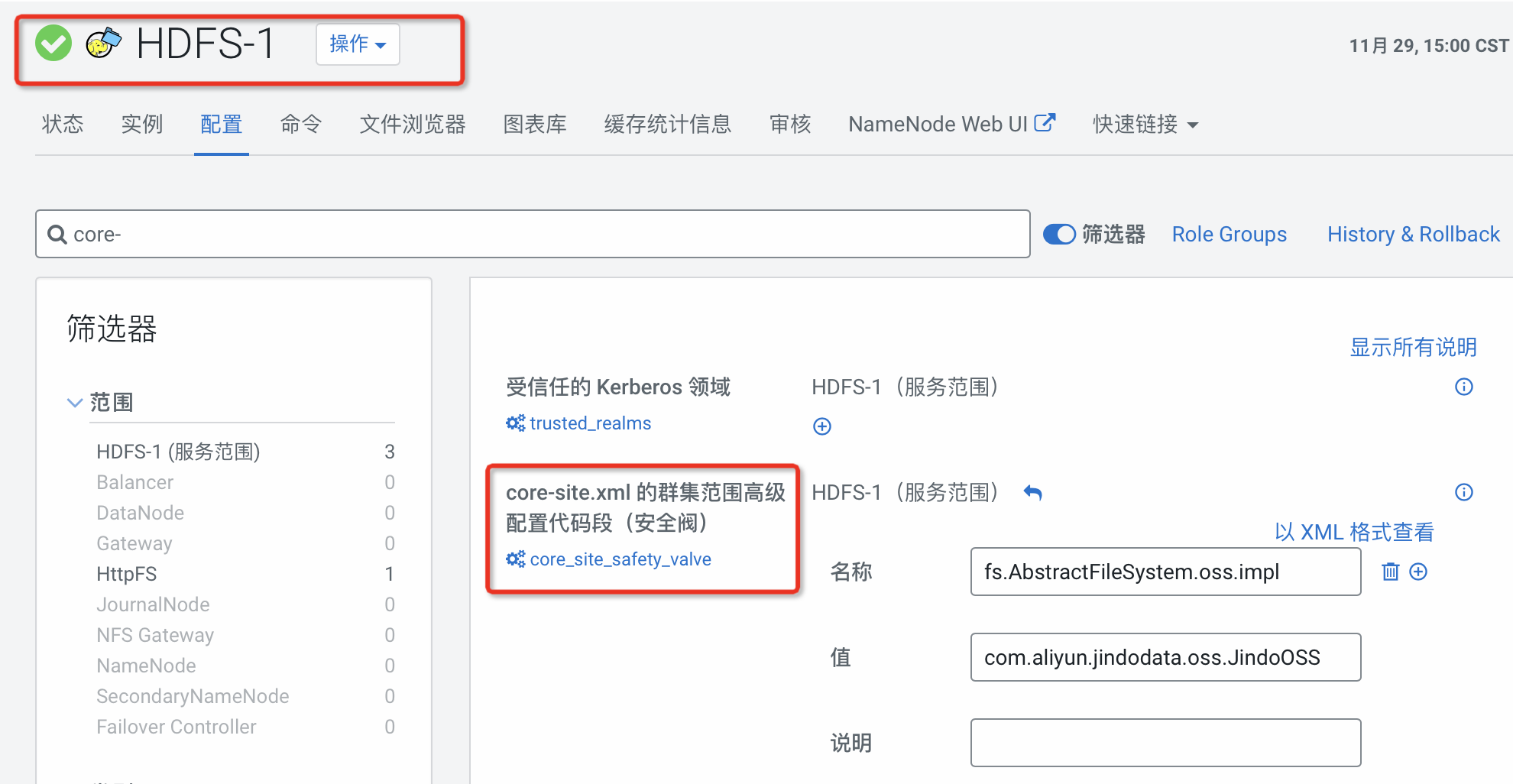
重啟Hive/Hive-on-Tez/Spark/HDFS服務
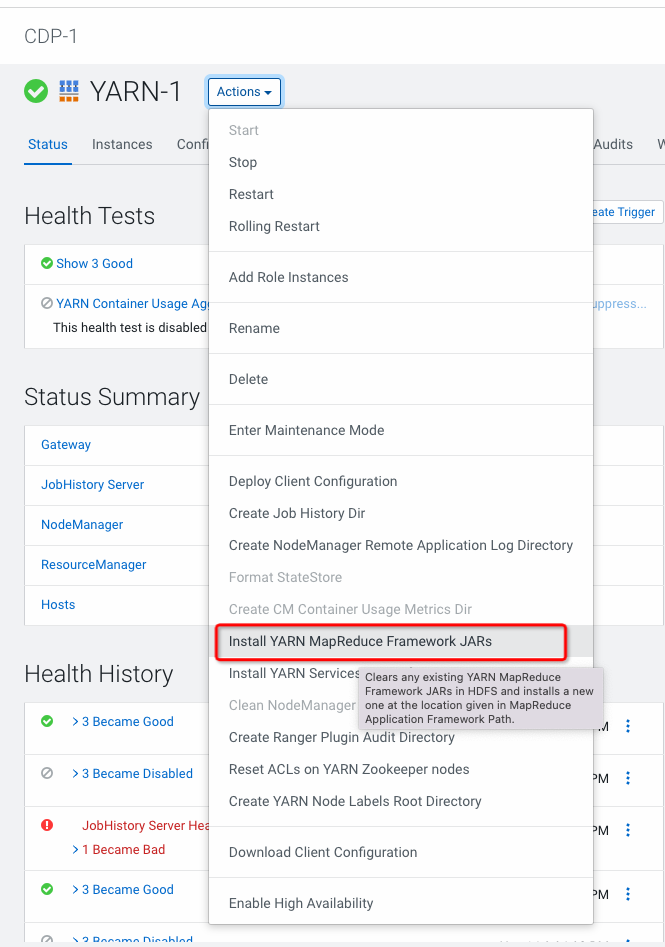
配置Yarn MR 分發JARS
使用HDFS Shell訪問OSS-HDFS服務
# 上傳文件
hdfs dfs -put WordCount.txt oss://examplebucket.cn-shanghai.oss-dls.aliyuncs.com/dir/
# 新建目錄
hdfs dfs -mkdir oss://examplebucket.cn-shanghai.oss-dls.aliyuncs.com/dir/
# 查看文件或目錄信息
hdfs dfs -ls oss://examplebucket.cn-shanghai.oss-dls.aliyuncs.com/
# 使用Hadoop distcp上傳hdfs文件到oss
hadoop distcp -skipcrccheck /warehouse/tablespace/external/hive/ oss://<yourBucketName>.<yourBucketEndpoint>/<path>/ 使用Hive訪問OSS-HDFS服務
-- 創建數據庫時指定OSS-HDFS服務路徑
CREATE DATABASE db_on_oss LOCATION 'oss://<yourBucketName>.<yourBucketEndpoint>/<path>/';
-- 創建表時指定OSS-HDFS服務路徑
CREATE TABLE db_on_oss.table_on_oss ... LOCATION 'oss://<yourBucketName>.<yourBucketEndpoint>/<path>/';
-- 向表中插入數據
insert into table db_on_oss.table_on_oss values ("***");使用Spark訪問OSS-HDFS服務
使用Spark-shell訪問OSS-HDFS
# 讀取txt文件執行WordCount val text_file = sc.textFile("oss://<yourBucketName>.<yourBucketEndpoint>/data/WordCount.txt") val counts = text_file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) counts.collect().foreach(println) # 將結果 counts.saveAsTextFile("oss://<yourBucketName>.<yourBucketEndpoint>/data/result/")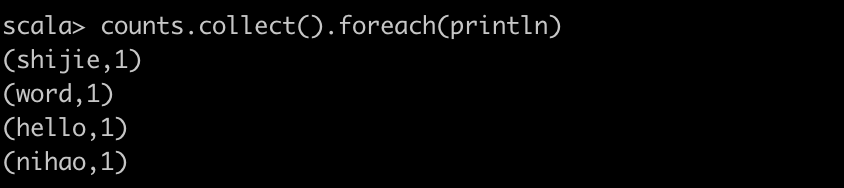

在提交spark-submit任務時除了可以在core-site.xml配置,還可以直接在conf中配置
spark-submit --conf spark.hadoop.fs.AbstractFileSystem.oss.impl=com.aliyun.jindodata.oss.OSS --conf spark.hadoop.fs.oss.impl=com.aliyun.jindodata.oss.JindoOssFileSystem --conf spark.hadoop.fs.oss.accessKeyId=LTAI5t7h6SgiLSganP2m**** --conf spark.hadoop.fs.oss.accessKeySecret=KZo149BD9GLPNiDIEmdQ7d****
上述文本中
<yourBucketName>.<yourBucketEndpoint>為步驟二:獲取HDFS服務域名中您獲取到的HDFS服務的域名。本示例使用OSS-HDFS的域名作為路徑的前綴。如果您希望只使用Bucket名稱來指向OSS-HDFS,則可以配置Bucket級別的Endpoint或全局Endpoint,具體操作請參見附錄一:配置Endpoint的其他方式。