Cromwell 是 Broad Institute 開發的工作流管理系統,當前已獲得阿里云批量計算服務的支持。通過 Cromwell 可以將 WDL 描述的 workflow 轉化為批量計算的作業(Job)運行。用戶將為作業運行時實際消耗的計算和存儲資源付費,不需要支付資源之外的附加費用。本文將介紹如何使用 Cromwell 在阿里云批量計算服務上運行工作流。
開通批量計算服務
要使用批量計算服務,請根據官方文檔里面的指導開通批量計算和其依賴的相關服務,如OSS等。
下載 Cromwell
開通 ECS 作為 Cromwell server
當前批量計算提供了 Cromwell server 的 ECS 鏡像,用戶可以用此鏡像開通一臺 ECS 作為 server。鏡像中提供了 Cromwell 官網要求的基本配置和常用軟件。在此鏡像中,Cromwell 的工作目錄位于/home/cromwell,上一步下載的 Crowwell jar 包可以放置在 /home/cromwell/cromwell 目錄下。
配置文件
Cromwell 運行的配置文件,包括:
- Cromwell 公共配置。
- 批量計算相關配置,包含了批量計算作為后端需要的存儲、計算等資源配置。
關于配置參數的詳細介紹請參考 Cromwell 官方文檔。如下是一個批量計算配置文件的例子 bcs.conf:
include required(classpath("application"))
database {
profile = "slick.jdbc.MySQLProfile$"
db {
driver = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://localhost/db_cromwell?rewriteBatchedStatements=true&useSSL=false&allowPublicKeyRetrieval=true"
user = "user_cromwell"
#Your mysql password
password = ""
connectionTimeout = 5000
}
}
workflow-options {
workflow-log-dir = "/home/cromwell/cromwell/logs/"
}
call-caching {
# Allows re-use of existing results for jobs you've already run
# (default: false)
enabled = false
# Whether to invalidate a cache result forever if we cannot reuse them. Disable this if you expect some cache copies
# to fail for external reasons which should not invalidate the cache (e.g. auth differences between users):
# (default: true)
invalidate-bad-cache-results = true
}
docker {
hash-lookup {
enabled = false
# Set this to match your available quota against the Google Container Engine API
#gcr-api-queries-per-100-seconds = 1000
# Time in minutes before an entry expires from the docker hashes cache and needs to be fetched again
#cache-entry-ttl = "20 minutes"
# Maximum number of elements to be kept in the cache. If the limit is reached, old elements will be removed from the cache
#cache-size = 200
# How should docker hashes be looked up. Possible values are "local" and "remote"
# "local": Lookup hashes on the local docker daemon using the cli
# "remote": Lookup hashes on docker hub and gcr
method = "remote"
#method = "local"
alibabacloudcr {
num-threads = 5
#aliyun CR credentials
auth {
#endpoint = "cr.cn-shanghai.aliyuncs.com"
access-id = ""
access-key = ""
}
}
}
}
engine {
filesystems {
oss {
auth {
endpoint = "oss-cn-shanghai.aliyuncs.com"
access-id = ""
access-key = ""
}
}
}
}
backend {
default = "BCS"
providers {
BCS {
actor-factory = "cromwell.backend.impl.bcs.BcsBackendLifecycleActorFactory"
config {
root = "oss://your-bucket/cromwell_dir"
region = "cn-shanghai"
access-id = ""
access-key = ""
filesystems {
oss {
auth {
endpoint = "oss-cn-shanghai.aliyuncs.com"
access-id = ""
access-key = ""
}
caching {
# When a cache hit is found, the following duplication strategy will be followed to use the cached outputs
# Possible values: "copy", "reference". Defaults to "copy"
# "copy": Copy the output files
# "reference": DO NOT copy the output files but point to the original output files instead.
# Will still make sure than all the original output files exist and are accessible before
# going forward with the cache hit.
duplication-strategy = "reference"
}
}
}
default-runtime-attributes {
failOnStderr: false
continueOnReturnCode: 0
autoReleaseJob: false
cluster: "OnDemand ecs.sn1.medium img-ubuntu-vpc"
#cluster: cls-6kihku8blloidu3s1t0006
vpc: "192.168.0.0/16"
}
}
}
}
}如果使用前面章節中的鏡像開通 ECS 作為 Cromwell server,配置文件位于 /home/cromwell/cromwell/bcs_sample.conf,只需要填寫自己的配置即可使用 Cromwell。
- OSS 的內網 endpoint :
- engine.filesystems.oss.auth.endpoint =
"oss-cn-shanghai-internal.aliyuncs.com" - backend.providers.BCS.config.filesystems.oss.auth.endpoint =
"oss-cn-shanghai-internal.aliyuncs.com"
- engine.filesystems.oss.auth.endpoint =
- 添加批量計算的內網 endpoint:
- backend.providers.BCS.config.user-defined-region =
"cn-shanghai-vpc" - backend.providers.BCS.config.user-defined-domain =
"batchcompute-vpc.cn-shanghai.aliyuncs.com"
- backend.providers.BCS.config.user-defined-region =
- 添加容器鏡像服務的內網 endpoint:docker.hash-lookup.alibabacloudcr.auth.endpoint =
"cr-vpc.cn-shanghai.aliyuncs.com"
運行模式
Cromwell支持兩種模式:
- run 模式
- server 模式
關于兩種模式的詳細描述,請參考 Cromwell 官網文檔。下面重點介紹這兩種模式下如何使用批量計算。
run模式
run模式適用于本地運行一個單獨的 WDL 文件描述的工作流,命令行如下:java -Dconfig.file=bcs.conf -jar cromwell.jar run echo.wdl --inputs echo.inputs
- WDL 文件:描述詳細的工作流。工作流中每個 task 對應批量計算的一個作業(Job)。
- inputs文件:是 WDL 中定義的工作流的輸入信息inputs 文件是用來描述 WDL 文件中定義的工作流及其 task 的輸入文件。如下所示:
{ "workflow_name.task_name.input1": "xxxxxx" }
運行成功后,WDL 文件中描述的工作流中的一個 task 會作為批量計算的一個作業(Job)來提交。此時登錄批量計算的控制臺就可以看到當前的 Job 狀態。
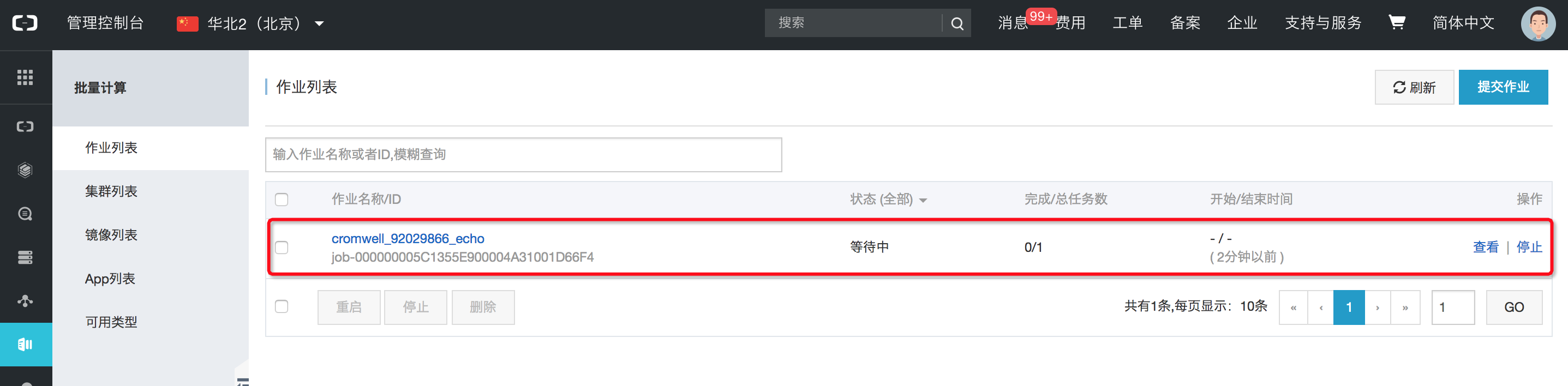
當 workflow 中所有的 task 對應的作業運行完成后,工作流運行完成。
server 模式
啟動 server
相比 run 模式一次運行只能處理一個 WDL 文件,server 模式可以并行處理多個 WDL 文件。關于 server 模式的更多信息,請參考 Cromwell 官方文檔。可以采用如下命令行啟動 server:java -Dconfig.file=bsc.conf -jar cromwell.jar serverserver 啟動成功后,就可以接收來自 client 的工作流處理請求。下面分別介紹如何使用 API 和 CLI 的方式向 server 提交工作流。
使用 API 提交工作流
39.105.xxx.yyy,則在瀏覽器中輸入http://39.105.xxx.yyy:8000,通過如下圖所示的界面提交任務: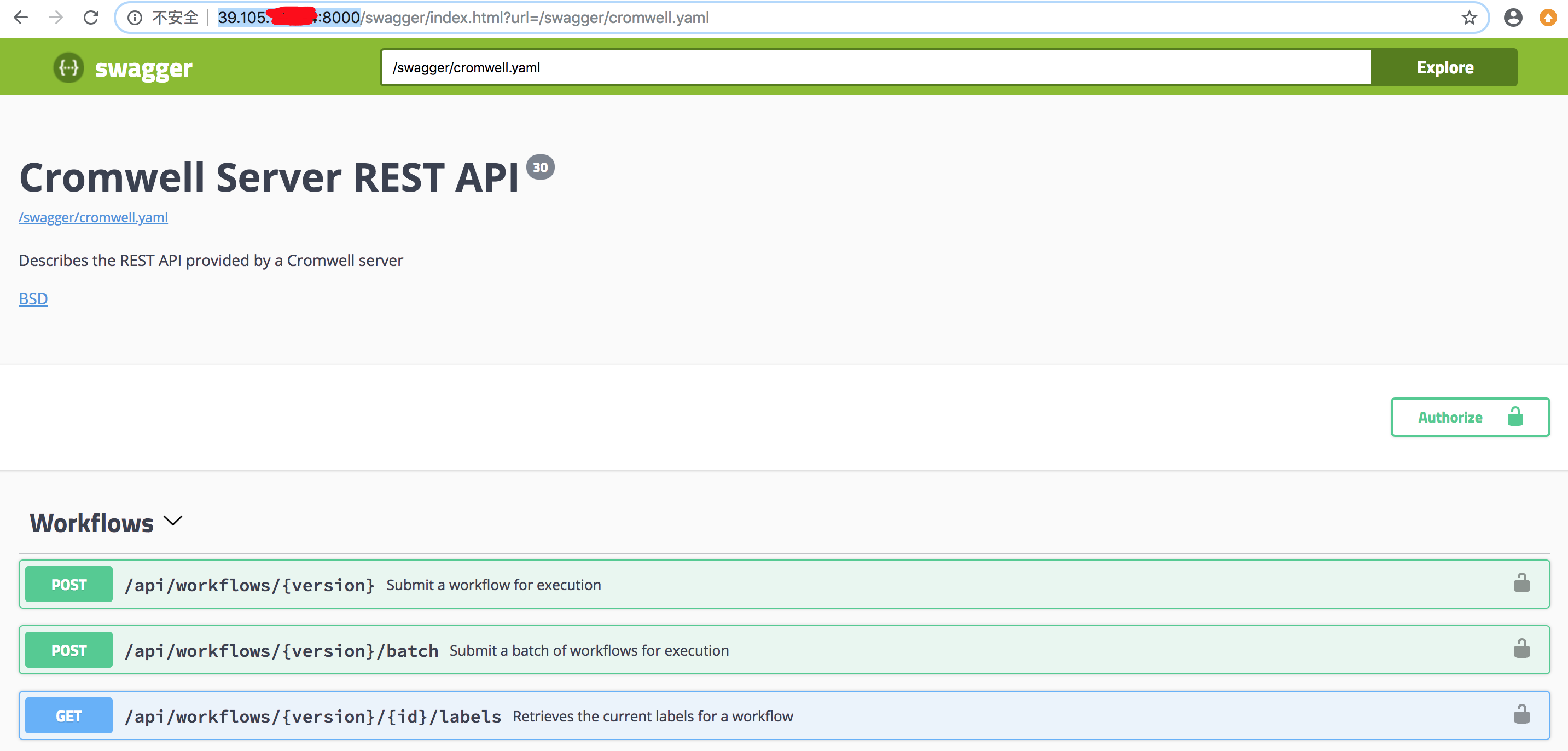 更多API接口及用法,請參考 Cromwell 官網文檔。
更多API接口及用法,請參考 Cromwell 官網文檔。
使用 CLI 提交工作流[推薦]
除了可以使用 API 提交工作流以外,Cromwell 官方還提供了一個開源的 CLI 命令行工具 widder。可以使用如下的命令提交一個工作流:
python widdler.py run echo.wdl echo.inputs -o bcs_workflow_tag:tagxxx -S localhost其中-o key:value是用于設置option,批量計算提供了 bcs_workflow_tag:tagxxx 選項,用于配置作業輸出目錄的tag(下一節查看運行結果中會介紹)。
如果使用前面章節中的鏡像開通 ECS 作為 Cromwell server,鏡像中已經安裝了 widdler,位于 /home/cromwell/widdler。可以使用如下的命令提交工作流:
widdler run echo.wdl echo.inputs -o bcs_workflow_tag:tagxxx -S localhost更多命令用法可使用widdler -h命令查看,或參考官方文檔。
查看運行結果
工作流運行結束后,輸出結果被上傳到了配置文件或 WDL 中定義的 OSS 路徑下。在OSS路徑上面的目錄結構如下:
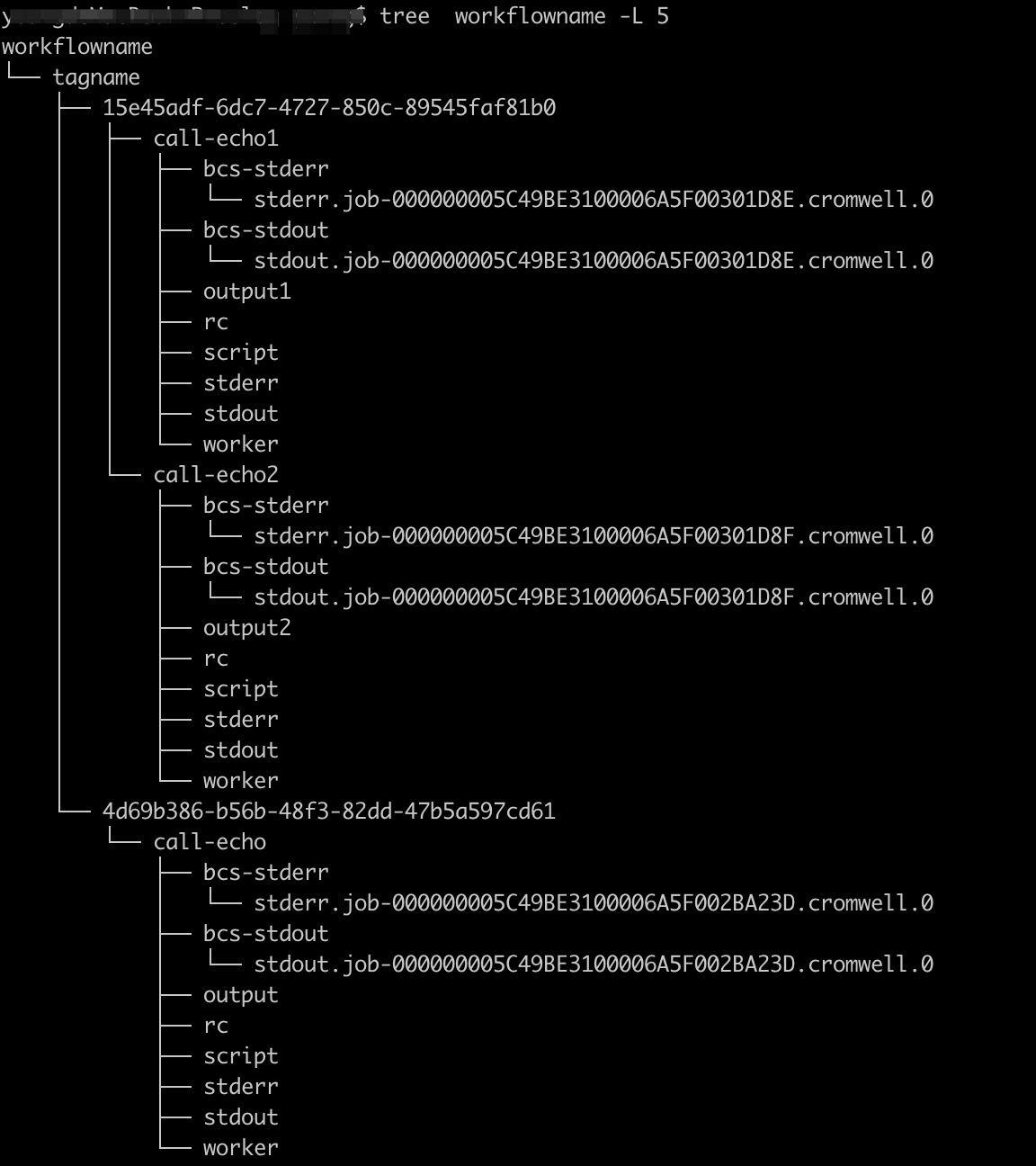
如上圖所示,在配置文件中的config.root目錄下有如下輸出目錄:
- 第一層:workflowname 工作流的名稱
- 第二層:通過上一節中 CLI 命令的
-o設置的目錄tag - 第三層:workflow id,每次運行會生成一個
- 第四層:workflow 中每個 task 的運行輸出,比如上圖中的 workflow
15e45adf-6dc7-4727-850c-89545faf81b0有兩個 task,每個task對應的目錄命名是call-taskname,目錄中包含三部分內容:- 批量計算的日志,包括 bcs-stdout 和 bcs-stderr
- 當前 task 的輸出,比如圖中的 output1/output2 等
- 當前 task 執行的 stdout 和 stderr
使用建議
在使用過程中,關于 BCS 的配置,有如下的建議供參考:
使用集群
批量計算提供了兩種使用集群的方式:
- 自動集群
- 固定集群
自動集群
在config配置文件中指定默認的資源類型、實例類型以及鏡像類型,在提交批量計算 Job 時就會使用這些配置自動創建集群,比如:
default-runtime-attributes {
cluster : "OnDemand ecs.sn1ne.large img-ubuntu-vpc"
}如果在某些 workflow 中不使用默認集群配置,也可以通過inputs文件中指定 workflow 中某個 task 的對應的批量計算的集群配置(將 cluster_config 作為 task 的一個輸入),比如:
{
"workflow_name.task_name.cluster_config": "OnDemand ecs.sn2ne.8xlarge img-ubuntu-vpc"
}然后在 task 中重新設置運行配置:
task task_demo {
String cluster_config
runtime {
cluster: cluster_config
}
}就會覆蓋默認配置,使用新的配置信息創建集群。
固定集群
使用自動集群時,需要創建新集群,會有一個等待集群的時間。如果對于啟動時間有要求,或者有了大量的作業提交,可以考慮使用固定集群。比如:
default-runtime-attributes {
cluster : "cls-xxxxxxxxxx"
}注意:使用固定集群時,如果使用完畢,請及時釋放集群,否則集群中的實例會持續收費。
Cromwell Server 配置建議
- 大壓力作業時,建議使用較高配置的機器作為 Cromwell Server,比如ecs.sn1ne.8xlarge等32核64GB的機器。
- 大壓力作業時,修改 Cromwell Server 的最大打開文件數。比如在ubuntu下可以通過修改
/etc/security/limits.conf文件,比如修改最大文件數為100萬:root soft nofile 1000000 root hard nofile 1000000 * soft nofile 1000000 * hard nofile 1000000 - 確認 Cromwell Server 有配置數據庫,防止作業信息丟失。
- 設置 bcs.conf 里面的并發作業數,比如
system.max-concurrent-workflows = 1000
開通批量計算相關配額
如果有大壓力場景,可能需要聯系批量計算服務開通對應的配額,比如:
- 一個用戶所有作業的數量(包括完成的、運行的、等待的等多種狀態下);
- 同時運行的作業的集群的數量(包括固定集群和自動集群);
使用 NAS
使用 NAS 時要注意以下幾點:
- NAS 必須在 VPC 內使用,要求添加掛載點時,必須指定 VPC;
- 所以要求在 runtime 中必須包含:
- VPC 信息
- mounts 信息
下面的例子可供參考:
runtime {
cluster: cluster_config
mounts: "nas://1f****04-xkv88.cn-beijing.nas.aliyuncs.com:/ /mnt/ true"
vpc: "192.168.0.0/16 vpc-2zexxxxxxxx1hxirm"
}如果是有多個目錄需要mount,可采用下面的方式
runtime {
mounts: "nas://1f****04-xkv88.cn-beijing.nas.aliyuncs.com:/ /mnt1/ true, nas://1f****04-xkv99.cn-beijing.nas.aliyuncs.com:/ /mnt2/ true"
}即兩組mount之間用逗號隔開。
高級特性支持
Glob
Cromwell 支持使用 glob 來指定工作流中多個文件作為 task 的輸出,比如:
task globber {
command <<<
for i in `seq 1 5`
do
mkdir out-$i
echo globbing is my number $i best hobby out-$i/$i.txt
done
>>>
output {
Array[File] outFiles = glob("out-*/*.txt")
}
}
workflow test {
call globber
}當 task 執行結束時,通過 glob 指定的多個文件會作為輸出,上傳到 OSS 上。
Call Caching
Call Caching 是 Cromwell 提供的高級特性,如果檢測到工作流中某個 task(對應一個批量計算的 job)和之前已經執行過的某個 task 具有相同的輸入和運行時等條件,則不需要再執行,直接取之前的運行結果,這樣可以為客戶節省時間和費用。一個常見的場景是如果一個工作流有 n 個 task,當執行到中間某一個 task 時由于某些原因失敗了,排除了錯誤之后,再次提交這個工作流運行后,Cromwell 判斷如果滿足條件,則已經完成的幾個 task 不需要重新執行,只需要從出錯的 task 開始繼續運行。
配置 Call Caching
要在 BCS 后端情況下使用 Call Caching 特性,需要如下配置項:
database {
profile = "slick.jdbc.MySQLProfile$"
db {
driver = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://localhost/db_cromwell?rewriteBatchedStatements=true&useSSL=false"
user = "user_cromwell"
password = "xxxxx"
connectionTimeout = 5000
}
}
call-caching {
# Allows re-use of existing results for jobs you have already run
# (default: false)
enabled = true
# Whether to invalidate a cache result forever if we cannot reuse them. Disable this if you expect some cache copies
# to fail for external reasons which should not invalidate the cache (e.g. auth differences between users):
# (default: true)
invalidate-bad-cache-results = true
}
docker {
hash-lookup {
enabled = true
# How should docker hashes be looked up. Possible values are local and remote
# local: Lookup hashes on the local docker daemon using the cli
# remote: Lookup hashes on alibab cloud Container Registry
method = remote
alibabacloudcr {
num-threads = 10
auth {
access-id = "xxxx"
access-key = "yyyy"
}
}
}
}
engine {
filesystems {
oss {
auth {
endpoint = "oss-cn-shanghai.aliyuncs.com"
access-id = "xxxx"
access-key = "yyyy"
}
}
}
}
backend {
default = "BCS"
providers {
BCS {
actor-factory = "cromwell.backend.impl.bcs.BcsBackendLifecycleActorFactory"
config {
#其他配置省略
filesystems {
oss {
auth {
endpoint = "oss-cn-shanghai.aliyuncs.com"
access-id = "xxxx"
access-key = "yyyy"
}
caching {
# When a cache hit is found, the following duplication strategy will be followed to use the cached outputs
# Possible values: copy, reference. Defaults to copy
# copy: Copy the output files
# reference: DO NOT copy the output files but point to the original output files instead.
# Will still make sure than all the original output files exist and are accessible before
# going forward with the cache hit.
duplication-strategy = "reference"
}
}
}
default-runtime-attributes {
failOnStderr: false
continueOnReturnCode: 0
cluster: "OnDemand ecs.sn1.medium img-ubuntu-vpc"
vpc: "192.168.0.0/16"
}
}
}
}
}- database 配置:Cromwell 將 workflow 的執行元數據存儲在數據庫中,所以需要添加數據庫配置,詳細情況參考Cromwell 官網指導。
- call-caching 配置:Call Caching 的開關配置等;
- docker.hash-lookup 配置: 設置 Hash 查找開關及阿里云 CR 等信息,用于查找鏡像的 Hash 值。
- backend.providers.BCS.config.filesystems.oss.caching 配置:設置 Call Caching命中后,使用原來輸出的方式,批量計算在這里支持 reference 模式,不需要拷貝原有的結果,節省時間和成本。
命中條件
使用批量計算作為后端時,Cromwell 通過如下條件判斷一個 task 是否需要重新執行:
| 條件 | 解釋 |
|---|---|
| inputs | task 的輸入,比如 OSS 上的樣本文件 |
| command | task 定義中的命令行 |
| continueOnReturnCode | 公共運行時參數,可以繼續執行的返回碼 |
| docker | 公共運行時參數,后端的Docker配置 |
| failOnStderr | 公共運行時參數,stderr非空時是否失敗 |
| imageId | 批量計算后端運行時參數,標識作業運行的 ECS 鏡像,如果使用的官方鏡像如img-ubuntu-vpc可不用填寫此項
|
| userData | 批量計算后端,用戶自定義數據 |
如果一個 task 的上述參數未發生改變,Cromwell 會判定為不需要執行的 task,直接獲取上次執行的結果,并繼續工作流的執行。