本文將對Java線程棧分析中,CPU利用率持續升高這一常見場景進行分析。
異常現象
某日接到業務同學反饋異常如下:
1.業務放量過程中,cpu持續升高,不清楚具體的原因。
2.系統代碼主要在等待下游返回結果,本地并沒有復雜的處理邏輯。
線程棧分析
業務同學保留了現場的jstack log(線程棧日志)。上傳線程棧日志并通過ATP線程棧分析。打開方法熱度視圖,它會聚合出那一刻Java進程內所有線程調用方法的熱度信息:
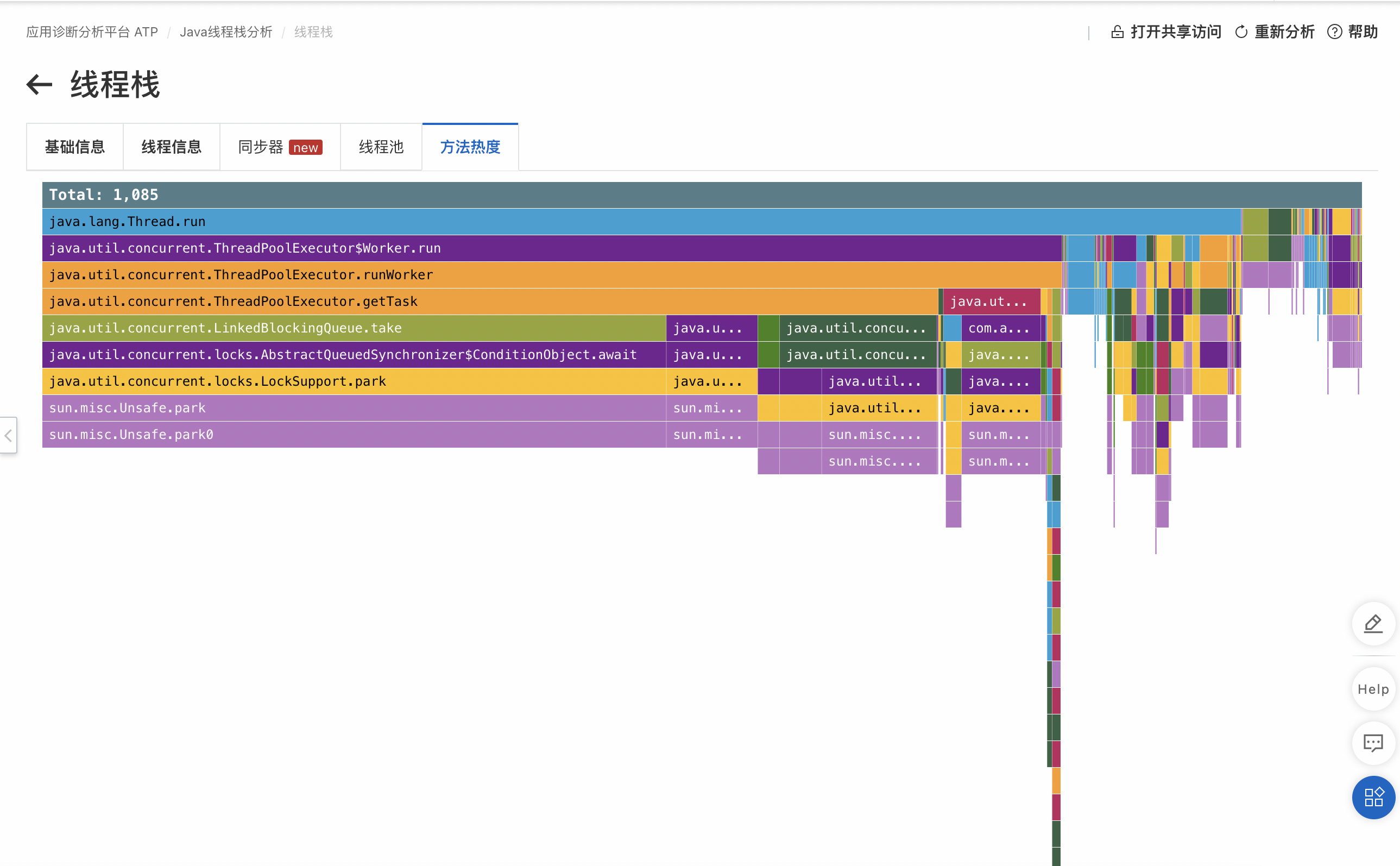 選擇最熱的方法(即最深的那條柱):
選擇最熱的方法(即最深的那條柱):
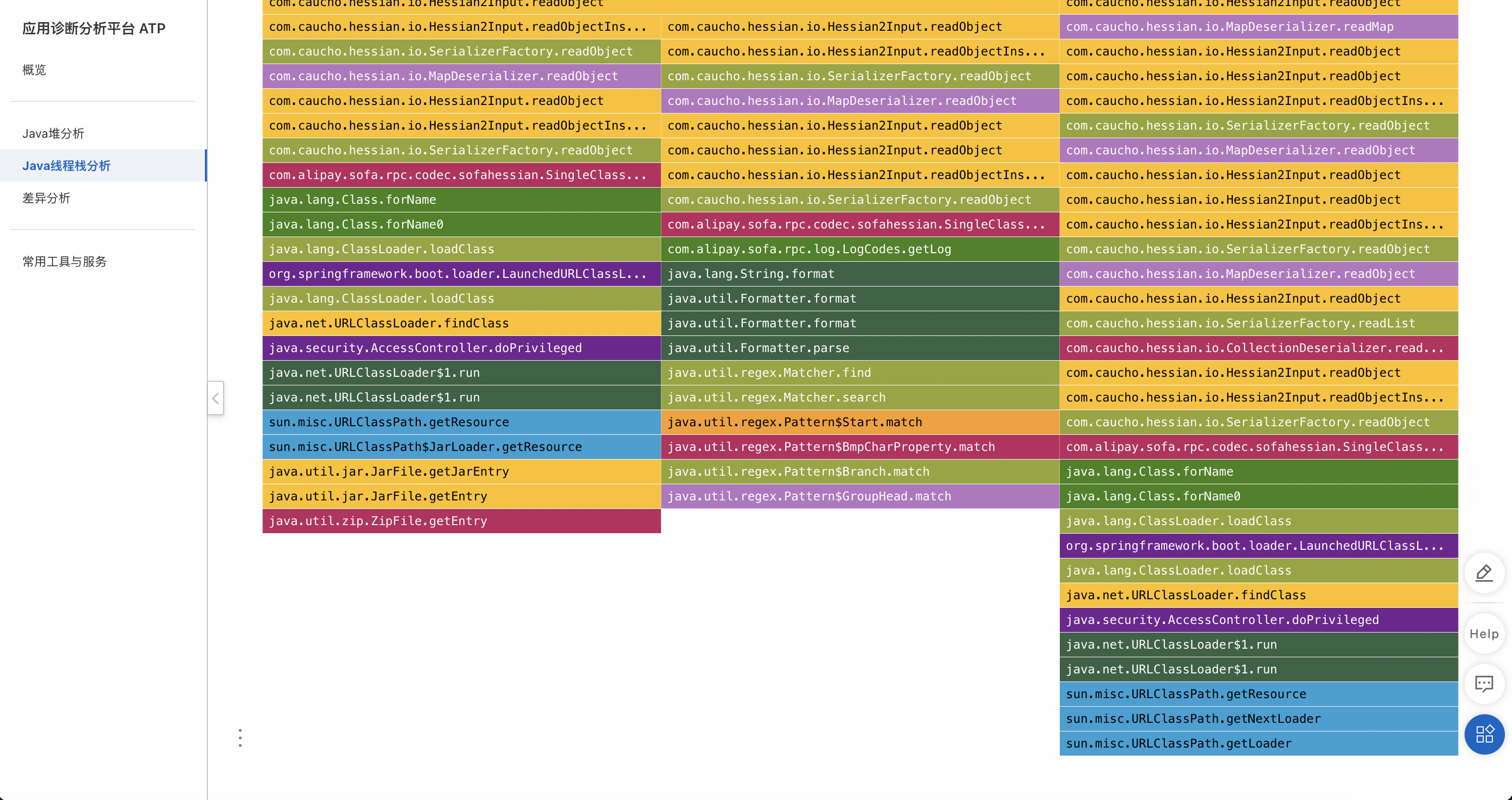
根據方法名可以看出最熱的方法是反序列化,序列化過程中會使用URLClassLoader加載類:
Hessian2Input.readObject();
...
ClassLoader.loadClass();
URLClassLoader.loadClass();
URLClassPath.getResource();
URLClassPath.getNextLoader();
URLClassPath.getLoader();URLClassLoader里面有個ucp(URLClassPath),它記錄了當前URLClassLoader類加載器加載了哪些jar包,在類加載過程中,它會遍歷所有jar包,然后逐個打開jar包并查找里面是否存在期望的類。再結合業務同學的反饋,大概有500多個jar包,所以根據線程棧分析得出的初步猜測是:在反序列化過程中遇到未加載的類,然后觸發URLClassLoader從500多個jar包中遍歷查找類,這個查找過程導致了CPU利用率持續升高。
根據上述的棧名稱,我們從jstack log中找到對應線程:
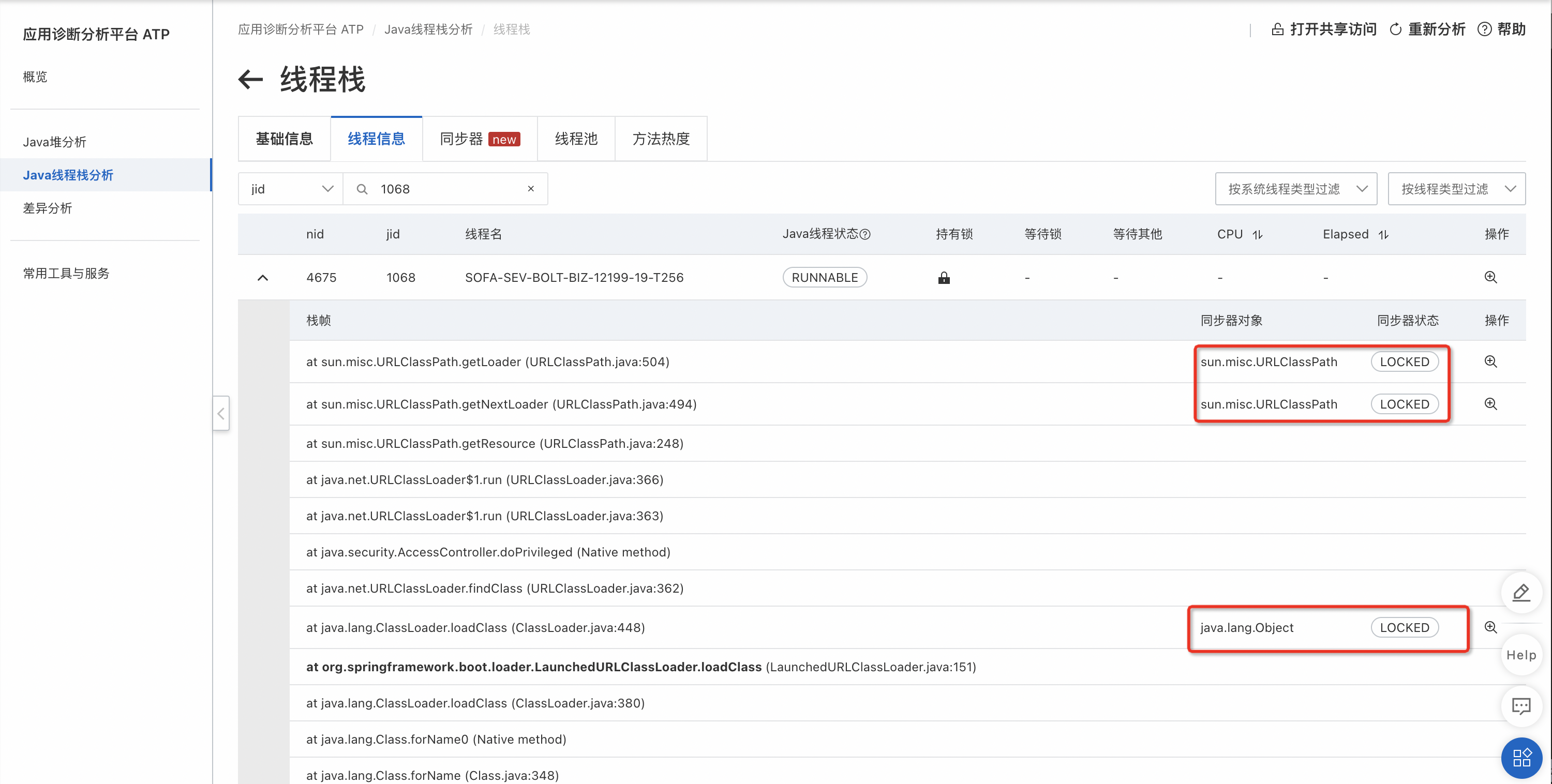
可以看到類加載過程中有三個地方加鎖了,查看這些鎖:
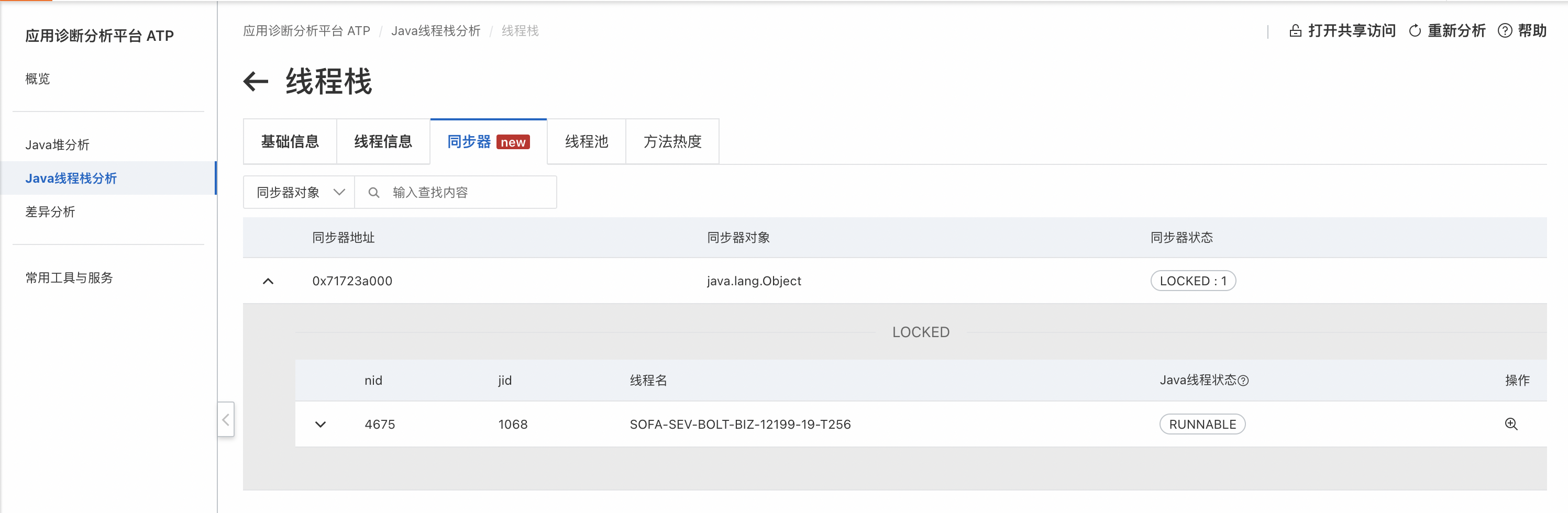
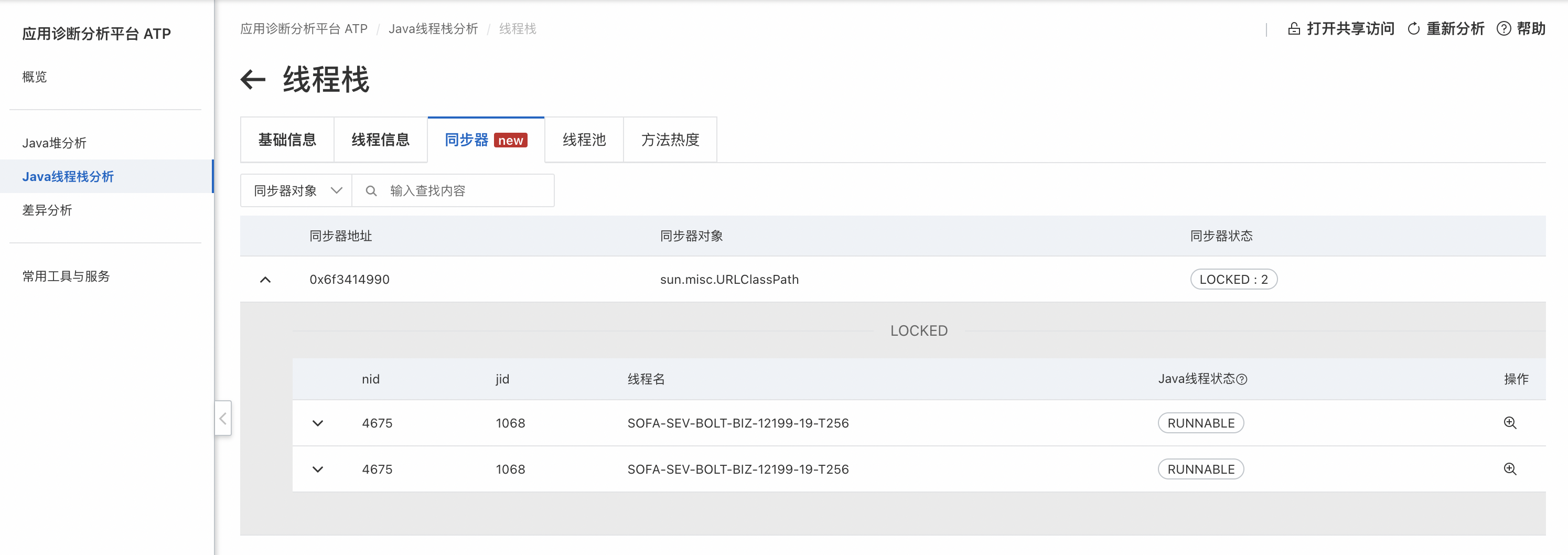
會發現實際上有兩把鎖,其中一個被遞歸加鎖,更重要的是鎖的持有者都是1068線程,另外沒有其他線程在等待該鎖,說明鎖沒有競爭,類查找過程僅1068一個線程在進行。
分析結論
所以我們可以更進一步得知,只有一個線程在執行高頻的jar包遍歷尋找類操作。根據這個猜測的結論,只要類找到,或者說反序列化結束,CPU利用率就應該會下降。和業務同學反饋后得知,序列化在持續進行。這也驗證了我們的猜測,因為只有反序列化在持續進行,CPU利用率才會持續上漲。
將這個猜測反饋給業務同學,他們從日志中發現,確實是因為有個類一直找不到,然后每次都在反序列化的時候再重新找,找不到也只會打個日志。到此,分析基本就結束了,剩下的工作是業務同學優化代碼,解決該類找不到的問題。
