在Service Mesh中,不同的服務可能需要采集不同的可觀測性數據,因此需要支持針對網格代理與網關Pod分別定義采集配置規則,并統一標準化采集配置規則,以便更好地支持云原生應用的可觀測性。可觀測性在云原生應用中扮演著非常重要的角色,它可以幫助我們實時監控服務的運行情況和性能指標,發現并解決服務故障和瓶頸,從而提高應用的可靠性和性能。阿里云服務網格ASM提供了統一標準化方式,為您提供一種收斂后的可觀測數據生成與采集配置模式,以更好地支持云原生應用的可觀測性。本文介紹可觀測的概念及相關功能。
可觀測介紹
隨著應用系統的復雜度越來越高,就越來越難保證所有的系統都一直處于穩健狀態,有可能某些部分會因問題而處于降級狀態。因此不僅需要將應用程序構建得更可靠且更具彈性,還需要通過可觀測性工具了解應用服務和基礎設施在運行時發生的情況。如果能夠了解實際發生的情況,就可以學會檢測故障并在觀察到某些意外情況時進行深入調試。這將有助于降低平均恢復時間,快速恢復對業務的影響。
可觀測性是一個包含各種級別的系統特征,必須結合應用程序的指標采集、網絡的指標采集、以及基礎設施(例如數據庫存儲等)來篩選存儲大量的數據,以便在發生不可預測的情況時拼湊出一個完整的視圖。Service Mesh在可觀測性方面可以有效提升應用程序級別的網絡指標采集。從實際應用的角度來看,在系統中需要重視其穩定性,需要理解什么時候系統運行良好或出現問題,從而可以更快地識別錯誤,并實施正確的自動化及手動控制來維護系統的可用性。
Service Mesh的數據平面代理位于服務之間的網絡請求路徑中,通過捕獲代理的可觀測性數據可以在運行時了解應用程序網絡和網格的運行情況。

在Service Mesh中實現可觀測性,涉及了日志、監控指標、鏈路追蹤這些可觀測性數據的生成規則配置和采集配置,以及如何將這些可觀測數據采集到云托管服務或者自建服務中。同時,還需要考慮如何支持針對網格代理與網關Pod分別定義采集配置,以支持不同的場景訴求。ASM提供了統一標準化方式,為您提供一種收斂后的可觀測數據生成與采集配置模式,以更好地支持云原生應用的可觀測性。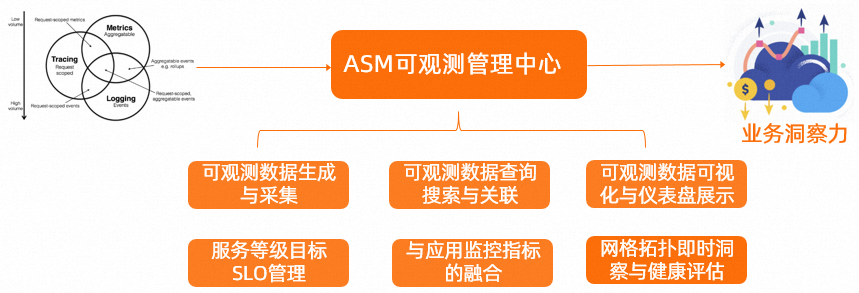
內置最佳實踐
Telemetry CRD允許在多個命名空間內創建多個對象,但隨意定義可能造成沖突等,導致實際執行的結果與預期不符。基于實際操作得出的最佳實踐如下:
在根命名空間istio-system中定義多個網格范圍的Telemetry資源對象無效,即只能存在一個Telemetry資源對象。ASM中已經內置了該最佳實踐,在istio-system命名空間內只允許存在一個名稱為default的Telemetry資源對象。
所有的命名空間下約束只存在一個Telemetry資源對象允許工作負載的選擇器selector為空,且名稱為default。
可以通過使用工作負載選擇器selector在所需命名空間中應用新的Telemetry資源對象來實現特定工作負載的覆蓋。
如果存在具有相同的工作負載選擇器selector的兩個Telemetry資源對象,即這兩個Telemetry資源對象選擇了相同的工作負載,則不確定這兩個Telemetry資源對象中的哪一個會被執行。
當根命名空間istio-system下的全局Telemetry資源對象中,未定位監控指標部分,默認對應不啟用生成指標。
日志
在Service Mesh中,日志的采集是實現可觀測性的重要手段之一。將所有服務的日志聚合到一處,便于統一管理和檢索。為了實現這個目標,需要將每個服務的日志打印到stdout或stderr,并使用日志代理將它們收集到中心日志系統中。ASM提供了日志過濾和日志格式化功能,可以根據需要對日志進行過濾和格式化,以便更好地檢索和分析日志。
日志格式規則配置
在實際應用中,不同服務的日志格式可能不同,因此需要設置生成規則來控制日志的生成方式。部署在數據平面(即加入網格的Kubernetes集群)的Envoy Proxy可以輸出所有訪問日志。ASM支持自定義Envoy Proxy輸出的訪問日志內容。
基于Telemetry CRD,ASM提供了如下圖所示的圖形化界面,簡化日志數據格式的配置。具體操作,請參見自定義數據面訪問日志。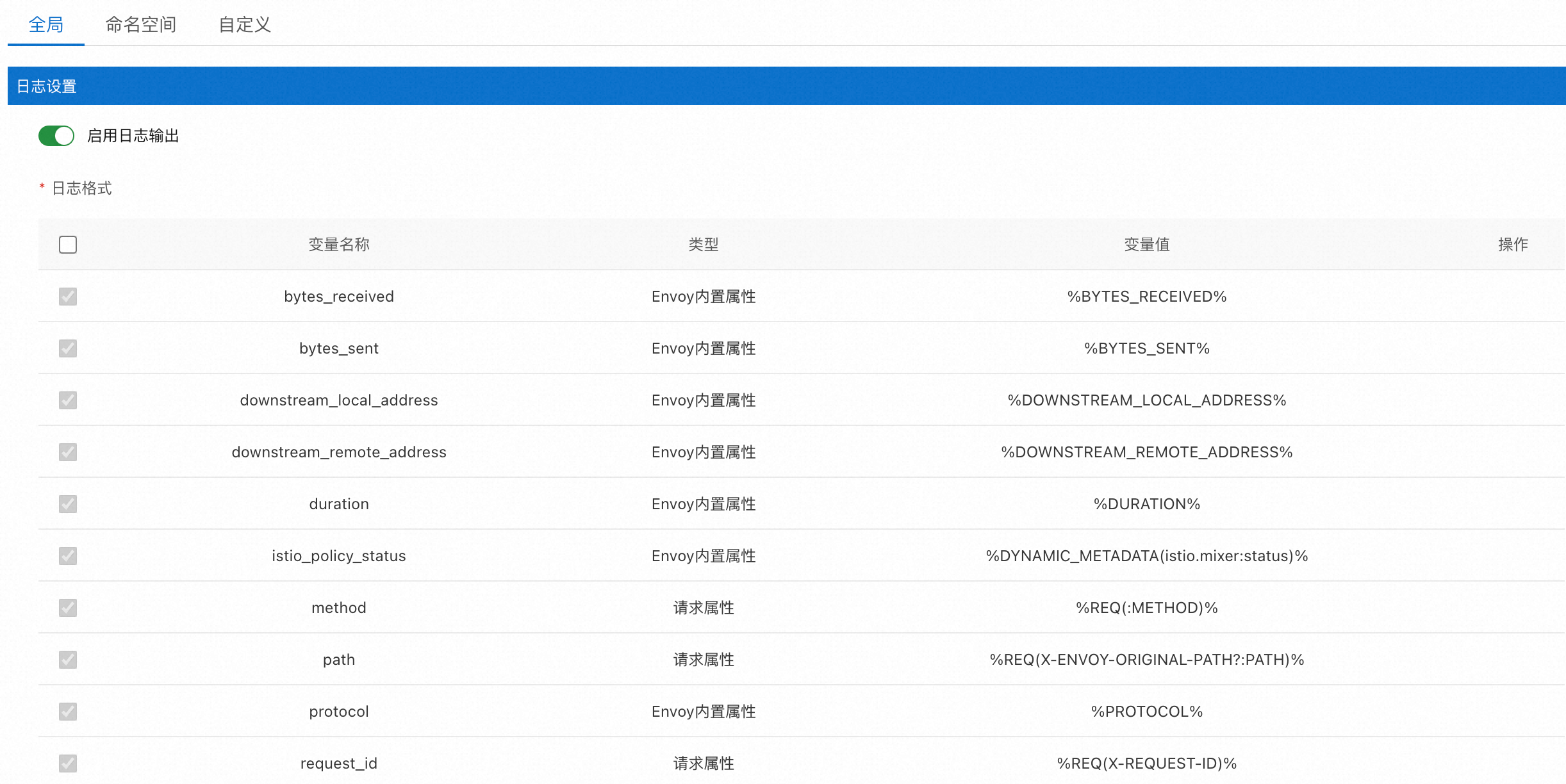
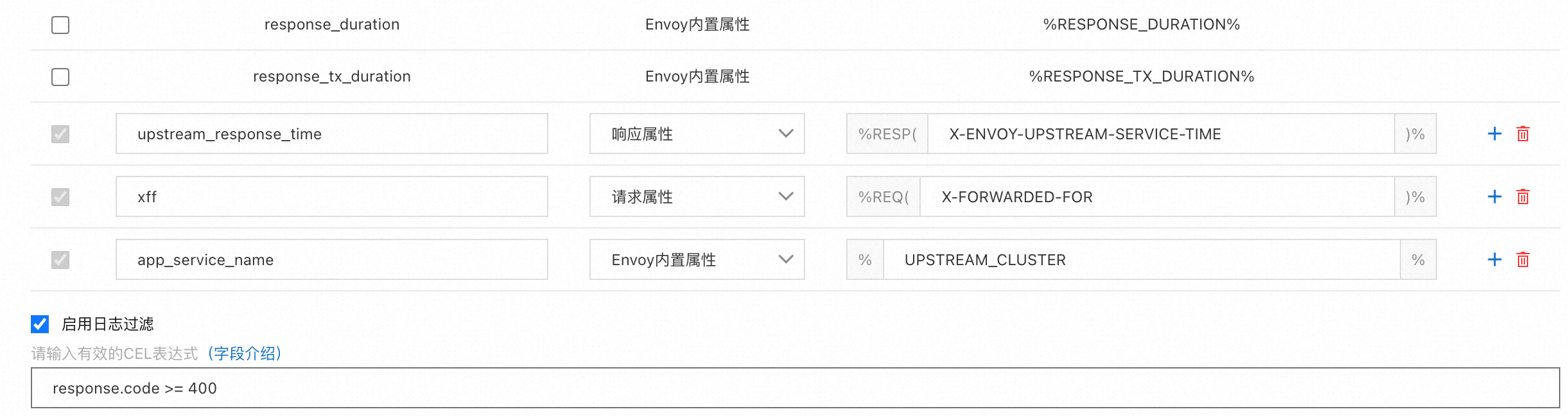
對應生成的定義內容如下:
envoyFileAccessLog:
logFormat:
text: '{"bytes_received":"%BYTES_RECEIVED%","bytes_sent":"%BYTES_SENT%","downstream_local_address":"%DOWNSTREAM_LOCAL_ADDRESS%","downstream_remote_address":"%DOWNSTREAM_REMOTE_ADDRESS%","duration":"%DURATION%","istio_policy_status":"%DYNAMIC_METADATA(istio.mixer:status)%","method":"%REQ(:METHOD)%","path":"%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%","protocol":"%PROTOCOL%","request_id":"%REQ(X-REQUEST-ID)%","requested_server_name":"%REQUESTED_SERVER_NAME%","response_code":"%RESPONSE_CODE%","response_flags":"%RESPONSE_FLAGS%","route_name":"%ROUTE_NAME%","start_time":"%START_TIME%","trace_id":"%REQ(X-B3-TRACEID)%","upstream_cluster":"%UPSTREAM_CLUSTER%","upstream_host":"%UPSTREAM_HOST%","upstream_local_address":"%UPSTREAM_LOCAL_ADDRESS%","upstream_service_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","upstream_transport_failure_reason":"%UPSTREAM_TRANSPORT_FAILURE_REASON%","user_agent":"%REQ(USER-AGENT)%","x_forwarded_for":"%REQ(X-FORWARDED-FOR)%","authority_for":"%REQ(:AUTHORITY)%","upstream_response_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","xff":"%REQ(X-FORWARDED-FOR)%","app_service_name":"%UPSTREAM_CLUSTER%"}'
path: /dev/stdout對應的過濾條件內容如下:
accessLogging:
- disabled: false
filter:
expression: response.code >= 400
providers:
- name: envoy數據面日志采集設置
將數據平面日志采集到阿里云日志服務SLS時,需要設置采集規則來控制日志的采集方式和儲存有效期。容器服務ACK集成了日志服務功能,可對服務網格數據平面集群的AccessLog進行采集。具體操作,請參見使用日志服務采集數據平面的AccessLog。
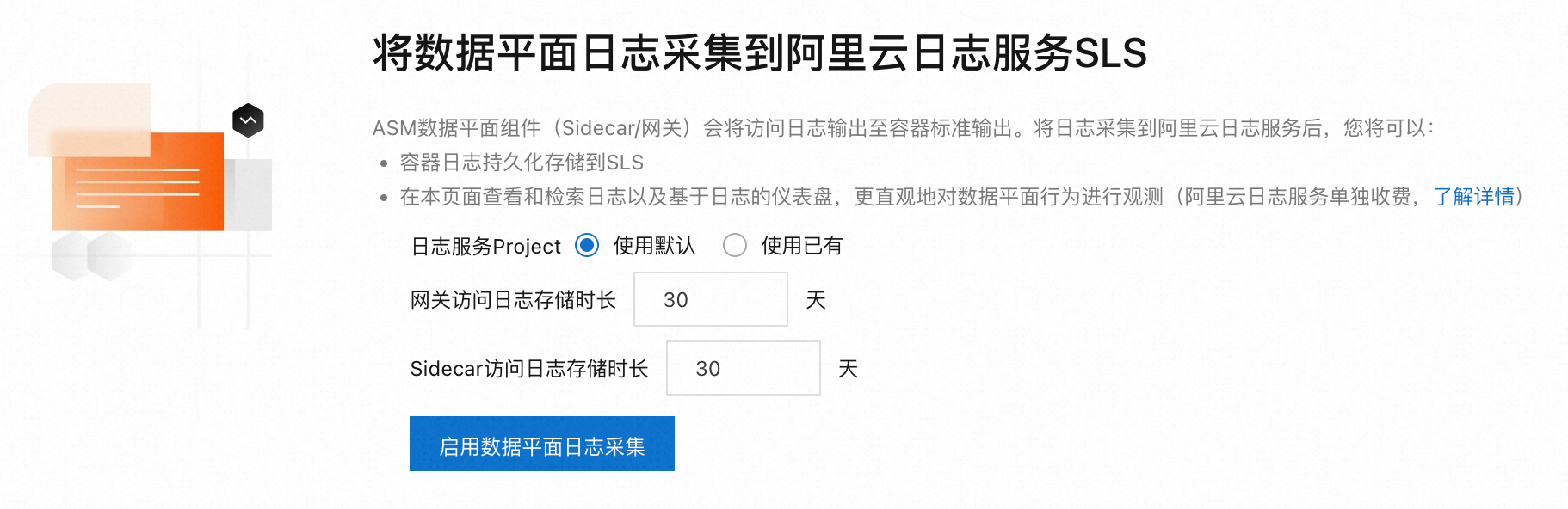
采集控制平面日志及設置告警
ASM支持采集控制平面日志和日志告警,例如采集ASM控制平面向數據平面Sidecar推送配置的相關日志。ASM控制面組件的主要功能之一是推送網格的規則配置到數據面的Sidecar代理或者網關中。如果您配置的網格規則內容存在一些沖突導致推送失敗,Sidecar代理或者網關將接收不到最新的配置內容。雖然Sidecar代理或網關在不重啟的情況下,可以使用已經接收到的配置繼續運行,但是一旦這些Pod重啟,很有可能導致Sidecar代理或網關啟動失敗。在很多實際場景中,經常出現用戶誤配置引發的網關或代理不可用的問題,因此啟用控制面的日志告警,及時發現并解決問題十分必要。具體操作,請參見啟用控制平面日志采集和日志告警(舊版)或啟用控制平面日志采集和日志告警(新版)。
監控指標
監控指標是Service Mesh中的另一個重要可觀測性維度,用于描述請求的處理情況、服務之間的通信狀況等。Istio采用Prometheus進行監控指標的采集和存儲,每個服務的代理(Envoy)會生成大量的監控指標。這些指標可以用于實時監控服務的運行情況和性能指標,還可以用于異常檢測和自動伸縮等場景。
指標數據生成規則配置
啟用服務網格數據平面監控指標可以使服務網格數據平面(網關和Sidecar代理)生成與其運行狀態相關的指標數據。您可以通過將指標采集到阿里云ARMS Prometheus來直接查看監控報表(采集指標可能產生費用),或是自建Prometheus并從ASM數據平面抓取監控指標。
基于Telemetry CRD,ASM提供了如下圖所示的圖形化界面,簡化自定義指標配置。具體操作,請參見在ASM中自定義監控指標。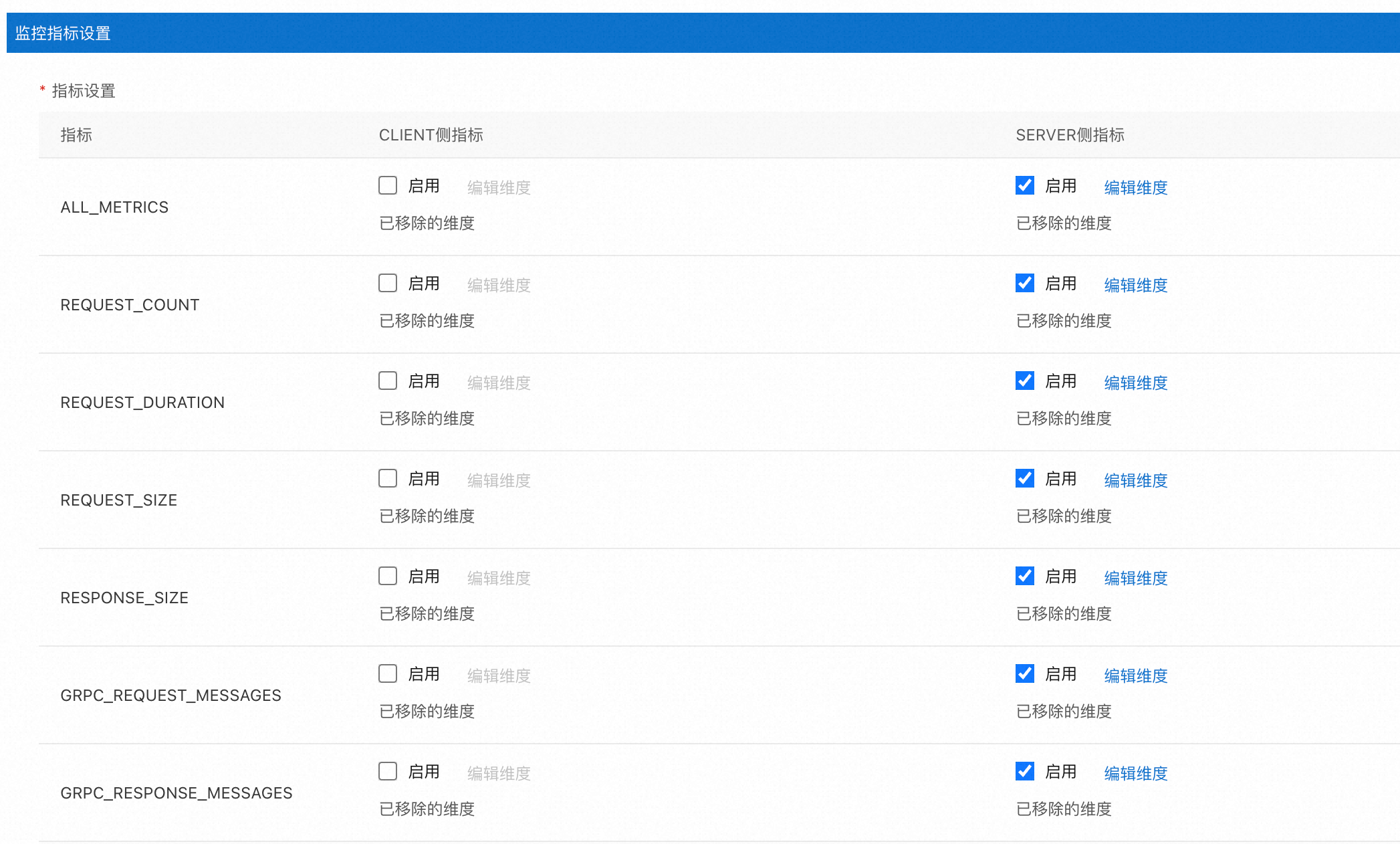
對應生成的定義內容如下:
metrics:
- overrides:
- disabled: true
match:
metric: ALL_METRICS
mode: CLIENT
- disabled: false
match:
metric: ALL_METRICS
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: REQUEST_COUNT
mode: CLIENT
- disabled: false
match:
metric: REQUEST_COUNT
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: REQUEST_DURATION
mode: CLIENT
- disabled: false
match:
metric: REQUEST_DURATION
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: REQUEST_SIZE
mode: CLIENT
- disabled: false
match:
metric: REQUEST_SIZE
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: RESPONSE_SIZE
mode: CLIENT
- disabled: false
match:
metric: RESPONSE_SIZE
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: GRPC_REQUEST_MESSAGES
mode: CLIENT
- disabled: false
match:
metric: GRPC_REQUEST_MESSAGES
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: GRPC_RESPONSE_MESSAGES
mode: CLIENT
- disabled: false
match:
metric: GRPC_RESPONSE_MESSAGES
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: TCP_SENT_BYTES
mode: CLIENT
- disabled: false
match:
metric: TCP_SENT_BYTES
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: TCP_RECEIVED_BYTES
mode: CLIENT
- disabled: false
match:
metric: TCP_RECEIVED_BYTES
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: TCP_OPENED_CONNECTIONS
mode: CLIENT
- disabled: false
match:
metric: TCP_OPENED_CONNECTIONS
mode: SERVER
tagOverrides: {}
- disabled: true
match:
metric: TCP_CLOSED_CONNECTIONS
mode: CLIENT
- disabled: false
match:
metric: TCP_CLOSED_CONNECTIONS
mode: SERVER
tagOverrides: {}
providers:
- name: prometheus監控指標注意事項
第一次開啟:阿里云可觀測監控Prometheus版是收費服務,請您根據實際情況自行決定指標生成范圍,以免指標量過大,產生過高費用。例如,若需要針對網關進行監控,則需要開啟CLIENT側指標。對于已開啟過的指標,重新開啟之后的指標設置將保留使用上一次的設置規則。
ASM網格拓撲功能相關的指標設置:ASM網格拓撲功能依賴于Sidecar上報的監控指標,若您開啟了網格拓撲,關閉部分監控指標會對網格拓撲功能造成影響甚至不可用。
如果不啟用REQUEST_COUNT的SERVER側指標,將無法生成HTTP或gRPC服務的拓撲圖。
如果不啟用TCP_SENT_BYTES的SERVER側指標,將無法生成TCP服務的拓撲圖。
關閉REQUEST_SIZE和REQUEST_DURATION的SERVER側,REQUEST_SIZE的CLIENT側指標會導致部分拓撲圖節點的監控信息無法展示。
指標采集配置
開啟Prometheus的統計數據收集功能,將采集到的監控指標發送到Prometheus中,以便進行存儲和分析。ASM集成了ARMS Prometheus功能,可以實現對服務網格的監控。具體操作,請參見集成可觀測監控Prometheus版實現網格監控。
Prometheus采集間隔會對指標收集開銷產生重大影響。間隔越長,抓取的數據點就越少,從而可以減少處理、存儲和計算開銷。當前的默認配置為15秒,對于生產場景來說可能過于頻繁。請根據實際需要在Prometheus側進行調整。如果使用的是ARMS Prometheus,請通過ARMS控制臺進行相關配置。具體操作,請參見配置采集規則。
直方圖關聯的指標(包括istio_request_duration_milliseconds_bucket、istio_request_bytes_bucket、istio_response_bytes_bucket)通常比較密集,開銷較大。為了避免這些自定義指標持續產生費用,您可以廢棄這些自定義指標。如果使用的是ARMS Prometheus,請通過ARMS控制臺進行配置。具體操作,請參見配置指標。
ASM集成自建Prometheus實現網格監控。具體操作,請參見集成自建Prometheus實現網格監控。
如下圖所示,您可以通過Grafana查看對應的儀表盤。
合并Istio與應用的監控指標
已有Prometheus監控端點的應用服務,通過啟用合并Istio與應用的監控指標功能,可以借助網格代理輸出原有業務指標。啟用合并Istio與應用的監控指標功能后,ASM會將應用程序指標合并到Istio指標中,相對應的prometheus.io注解會被加入到所有數據面Pod上,以啟用Prometheus的指標抓取能力。如果這些注解已經存在,就會被覆蓋。網格代理將應用指標和Istio指標進行合并,Prometheus可以從:15020/stats/prometheus端點拉取合并后的指標。具體操作,請參見合并Istio與應用的監控指標。
網格拓撲展示
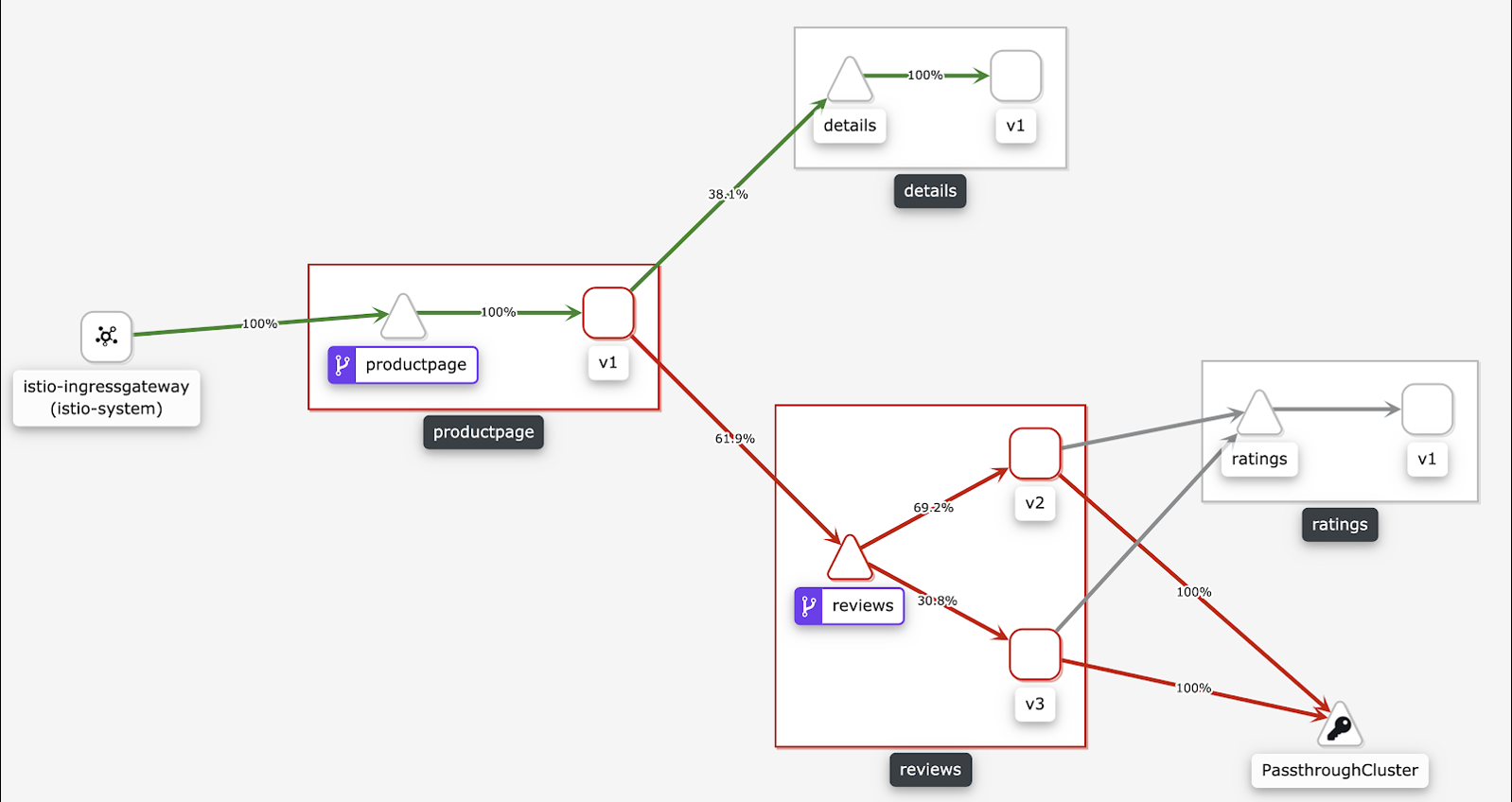
網格拓撲是一個服務網格可觀測性工具,提供查看相關服務與配置的可視化界面。如下圖所示,ASM支持內置網格拓撲。具體操作,請參見開啟網格拓撲提高可觀測性。
服務等級目標SLO
服務等級指標SLI(Service Level Indicator)是衡量服務健康狀況的指標。SLO是指服務等級的目標值或范圍值,由一個或多個服務等級指標SLI組成。
SLO提供了一種形式化的方式來描述、衡量和監控微服務應用程序的性能、質量和可靠性。SLO為應用開發和平臺團隊、運維團隊提供了一個共享的質量基準,可作為衡量服務水平質量以及持續改進的參考。使用SLI組合定義的SLO能夠幫助團隊以更精確的方式描述服務健康狀況。
SLO示例如下:
每分鐘平均QPS > 100,000/s
99%訪問延遲 < 500ms
99%每分鐘帶寬 > 200 MB/s
ASM提供了開箱即用的基于服務等級目標SLO(Service Level Objectives)的監控和告警能力,能夠監控應用服務之間調用的延遲和錯誤率特征等。
ASM支持的SLI類型如下:
服務可用性:服務成功響應的時間比例,對應的SLI插件類型為availability。HTTP響應碼為429或以5XX(以5開頭的狀態碼)會被判斷為不可用。
延遲時間:服務返回請求的響應所需的時間(單位為毫秒),對應的SLI插件類型為lantency。您可自定義延遲上限,高于上限的響應會被判斷為不合格。
ASM提供了定義SLO配置的UI界面如下。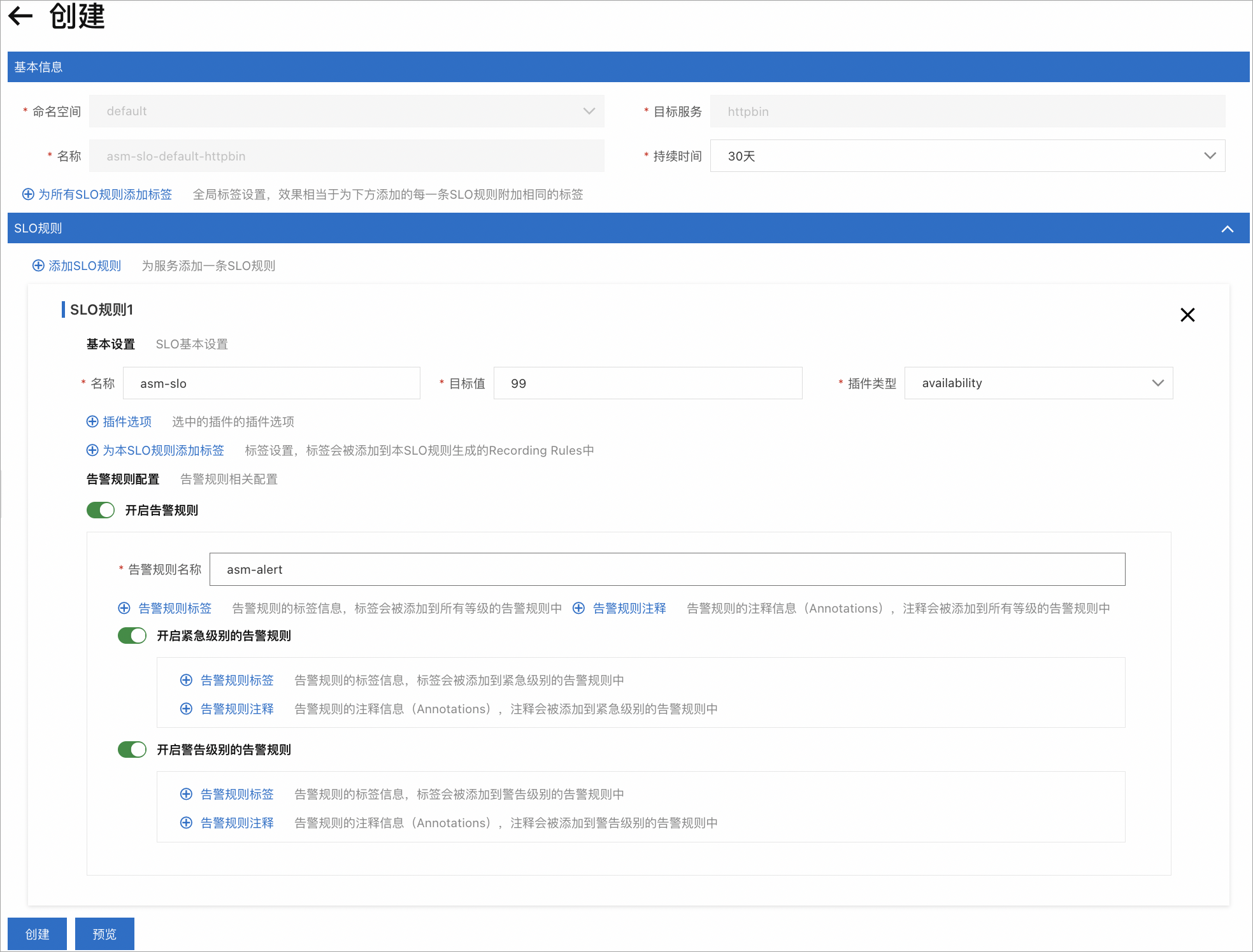
使用ASM定義應用服務級SLO,可以自動生成Prometheus規則。將生成的規則導入Prometheus中之后可以執行SLO。在Prometheus框架中,由AlertManager組件負責收集Prometheus Server產生的告警信息,并根據您的配置發送給各個接收者。如下圖所示,當觸發告警時,您可以在Alertmanager頁面看到自定義告警信息采集成功。關于SLO的更多信息,請參見SLO管理。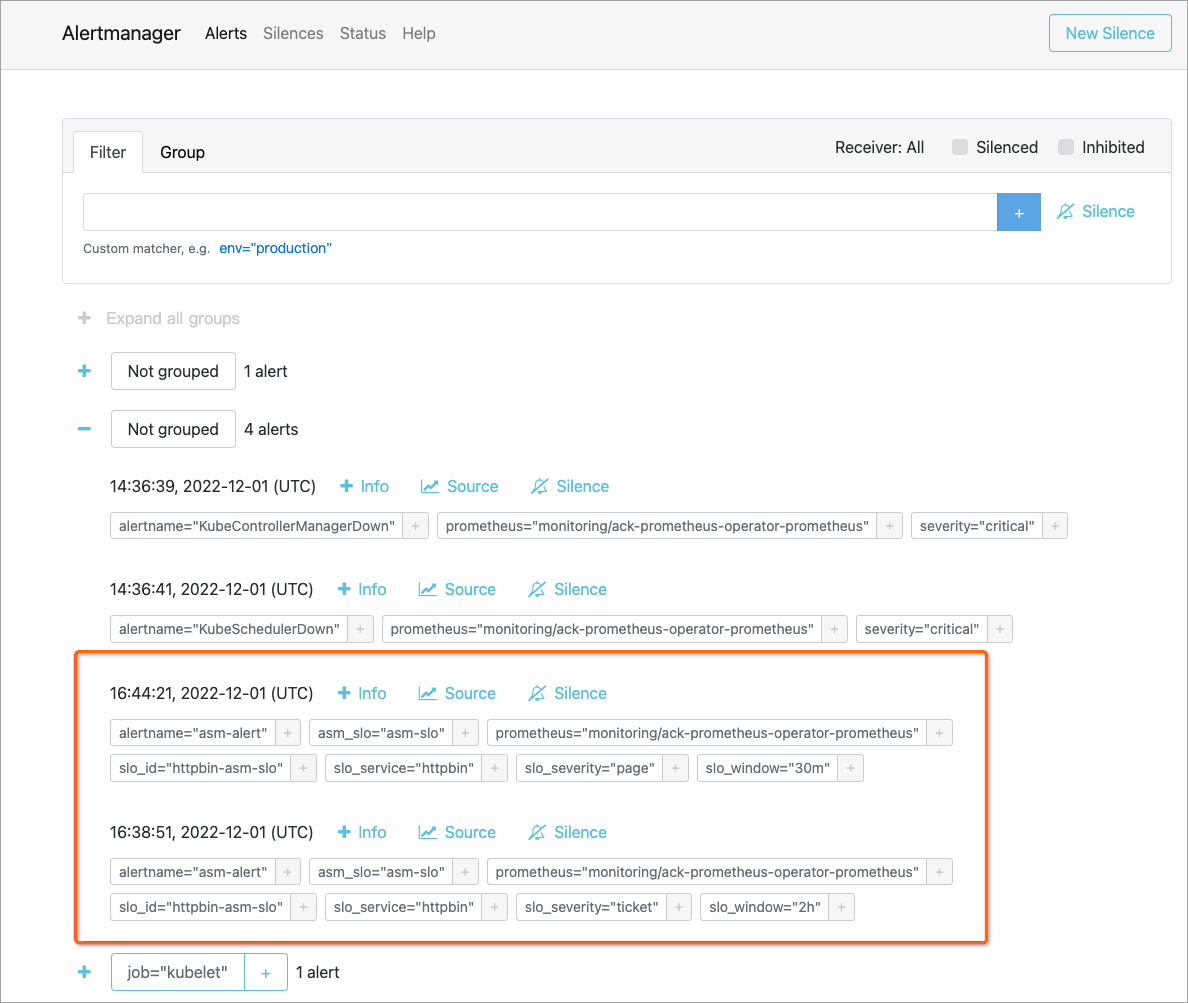
分布式追蹤
分布式追蹤是Service Mesh中實現可觀測性的重要組成部分之一,是一種用于對應用程序進行概要分析和監視的方法,尤其是針對使用微服務架構構建的應用程序。在微服務架構中,服務之間的通信通過網絡進行,因此需要采用分布式追蹤技術來對服務之間的調用關系進行跟蹤和監控。在Istio中,可以使用Jaeger、Zipkin等分布式追蹤工具來實現這個功能。在分布式追蹤里,存在Trace和Span兩個重要概念。
Span:分布式追蹤的基本組成單元,表示一個分布式系統中的單獨的工作單元,每一個Span可以包含其它Span的引用。多個Span在一起構成了Trace。
Trace:微服務中記錄的完整的請求執行過程,一個完整的Trace由一個或多個Span組成。
雖然Istio代理能夠自動發送Span信息,但是應用程序仍然需要傳播適當的HTTP標頭,以便在代理發送Span時,可以將Span正確地關聯到單個跟蹤中。因此,應用程序需要收集以下標頭并將其從傳入請求傳播到任何傳出請求:
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context
追蹤數據生成規則配置
基于Telemetry CRD,ASM提供了如下圖所示的圖形化界面,簡化定義分布式鏈路追蹤數據的生成規則配置。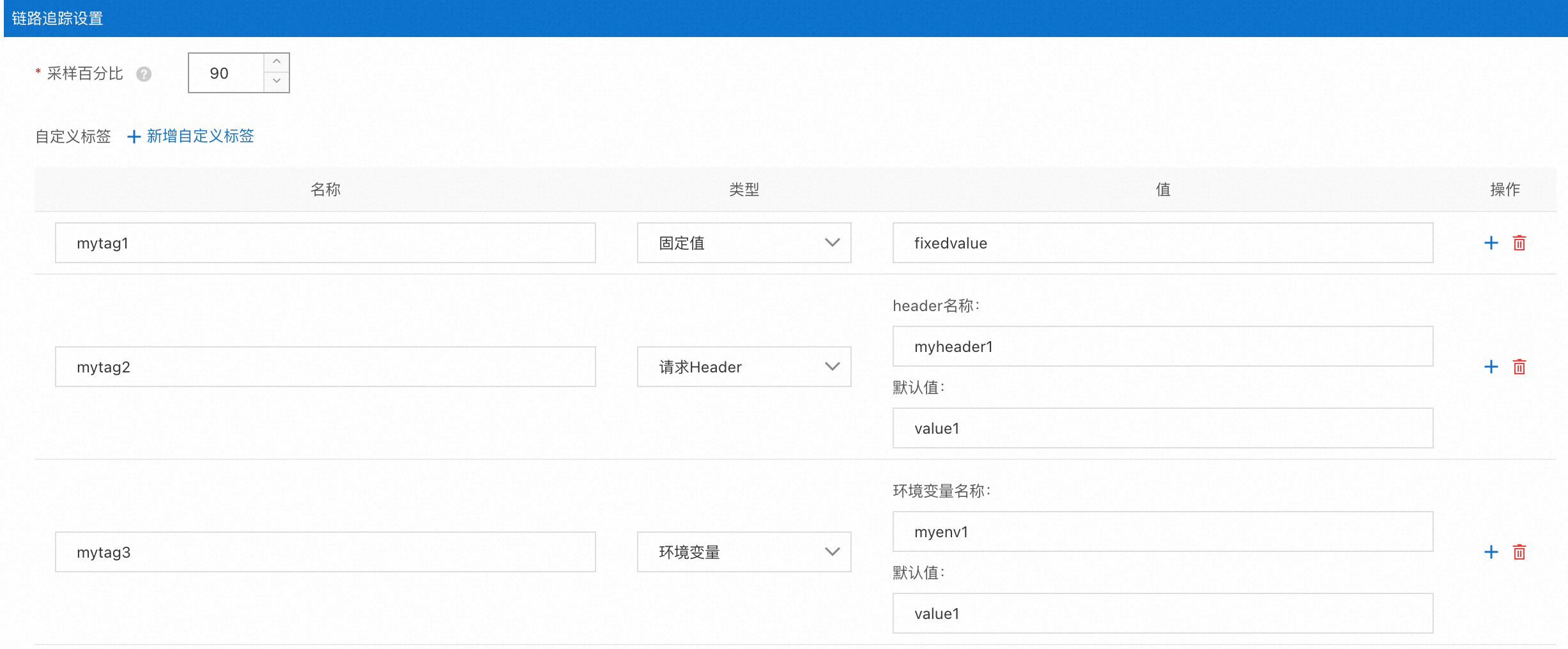
對應生成的定義內容如下:
tracing:
- customTags:
mytag1:
literal:
value: fixedvalue
mytag2:
header:
defaultValue: value1
name: myheader1
mytag3:
environment:
defaultValue: value1
name: myenv1
providers:
- name: zipkin
randomSamplingPercentage: 90追蹤采集配置
若您需要將采集到的數據發送到云托管服務或者自建服務中,可以使用以下方式:
在云托管服務中,可以使用云原生應用管理服務來實現數據的收集和分析。具體操作,請參見在ASM中實現分布式跟蹤。
在自建服務中,可以使用開源的數據收集和分析工具(例如Zipkin、Jaeger等)來實現數據的收集和分析。具體操作,請參見向自建系統導出ASM鏈路追蹤數據。